- The paper introduces explicit finite-time rates by linking subgradient descent iterates to Riemannian gradient flows on stratified smooth manifolds.
- It leverages geometric stratifications with global projection formulas and Lipschitz bounds to rigorously control subgradient errors.
- Dynamic stratum selection and quantified error bounds provide nonasymptotic stationarity certificates for nonsmooth optimization tasks.
Convergence Rates of Subgradient Descent for Semialgebraic Functions
Introduction and Problem Context
The paper develops a finite-time complexity analysis for subgradient descent (SubGD) when applied to broad classes of nonsmooth, nonconvex semialgebraic functions. This extends the theory significantly beyond previous results, which were typically asymptotic or limited to smooth/convex regimes. The analysis leverages the geometric structure of semialgebraic functions, specifically the existence of stratifications of the domain into smooth manifolds ("strata"), and develops new tools for tracking algorithmic progress across such stratifications.
Geometric Structure and Stratification
A central insight is that semialgebraic functions admit a partition of their domain (a stratification) into finitely many smooth manifolds, on each of which the function is smooth. More importantly, the Clarke subdifferential at a point on a stratum can be projected onto the stratum's tangent space to recover the Riemannian gradient of the function restricted to that stratum. The paper formalizes this via a global projection formula for Clarke subgradients, and provides quantitative, uniform Lipschitz bounds on the variation of tangent planes and the Riemannian gradients across each stratum.
The implications are twofold: (i) subgradient descent iterates, although evolving in a nonsmooth, nonconvex landscape, locally shadow Riemannian gradient flows on nearby strata; and (ii) finite-time error bounds can be quantified in terms of the geometry of the stratification and the stationarity property along these smooth manifolds.
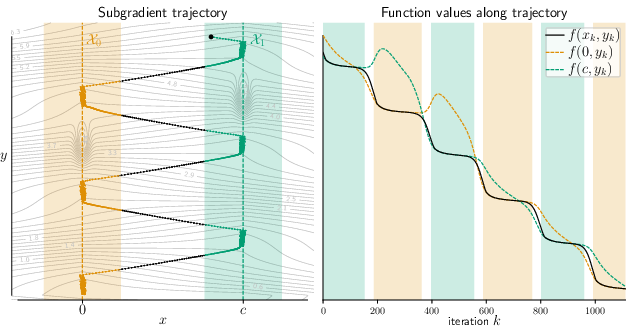
Figure 1: Visualization of piecewise smooth structure enabled by stratification; subgradient descent trajectory transitions between strata.
Technical Contributions: Error Bounds and Algorithmic Construction
Assumptions and Main Theorems
The main theorems operate under piecewise smoothness and quantitative geometric regularity of the stratification, conditions which are shown to hold automatically for any semialgebraic function (and more generally for any function definable in a polynomially bounded o-minimal structure) on a compact domain. Explicitly:
- Each stratum is a Cp submanifold and f restricted to it is Cp.
- The inner and Euclidean metrics on the stratum are equivalent.
- There is a Lipschitz bound on the tangent space variation and a global error bound for projecting Clarke subgradients onto stratum tangent spaces.
These geometric properties enable the establishment of explicit finite-time convergence rates. More precisely: for constant step size SubGD, for any sufficiently small step size γ and any number of steps K, there exists a sequence of active strata (Ψk)k=1K such that the iterates xk remain within O(γα+rank(Ψk)β) of the active stratum at each iteration, and:
K1k=1∑K∥∇gΨk(xk)∥2≤C(γKf(x1)−f(xK+1)+γβ−α+γ2α)
where gΨk=f∘πΨk and the rates depend on the hierarchical structure of the stratification via the so-called "rank" f0 (number of distinct stratum dimensions).
Notion of Stationarity
The convergence rate is measured in terms of the norm of the Riemannian gradient of f1 projected onto the current active stratum, which, via the global geometric error control, yields a non-asymptotic stationarity certificate. Importantly, this avoids the need to rely on surrogates such as the Moreau envelope or Goldstein stationarity—commonly used in prior work with weaker convergence proofs.
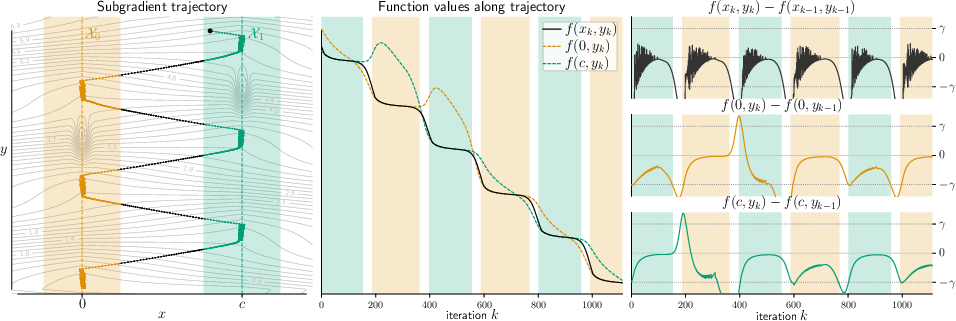
Figure 2: Subgradient descent trajectory with transitions between two strata; trajectory shadows Riemannian gradient flow along each stratum.
Combinatorial Construction: Strata Selection Mechanism
An essential component is the dynamic mechanism for "active stratum selection." The algorithm constructs, at each iteration, a stratum f2 such that the iterate f3 is sufficiently close to f4 (but separated from lower-dimensional strata), and only switches strata if the iterate traverses the "buffer zone"—the region outside of the thin tubular neighborhood of the current stratum.
The paper gives a constructive, combinatorial algorithm for this selection process (see Algorithm~1 in the paper), showing that the number of switches can be bounded and thus the potential switching-induced error in the finite-time bound remains controllable.
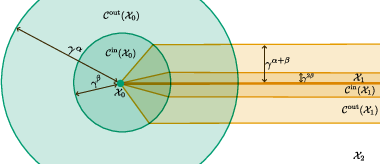
Figure 3: Schematic depiction of stratification of a set, along with inner (thin) and outer (thick) neighborhoods defining buffer zones for stratum selection.
Quantitative Rates and Dimensional Dependence
The rates depend polynomially on the step size f5, with the exponent determined by the number of distinct active stratum dimensions ("rank" f6). In the worst case (f7), this is exponential in dimension, but in practice the number of active stratum dimensions along actual trajectories can be much smaller. The analysis is resilient to arbitrary semialgebraic (or definable) nonsmoothness and recovers classical smooth rates as a special case.
Methodological Generalizations
Extensions to Decreasing Step Sizes
The framework extends to variable, decreasing step sizes. Using a standard doubling trick and adapting the combinatorial assignment of active strata to time-varying neighborhood scales, one obtains non-asymptotic complexity guarantees. For sufficiently fast step decay, the sequential convergence of the iterates is also obtained.
Sequential Convergence (Lojasiewicz Setting)
Notably, the developed machinery enables recovery of recent results on sequential convergence of SubGD under a f8 step-size schedule, matching and providing an alternative proof for Lai and Song (2025). This follows via the classical Kurdyka–Lojasiewicz inequality, now measured against the projected Riemannian gradients on strata, and the explicit control over the nonstationarity terms introduced by stratum switching.
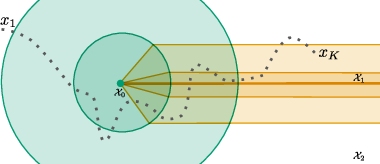
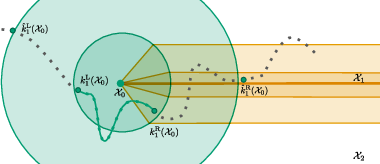
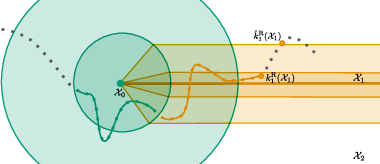
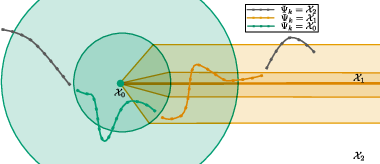
Figure 4: Illustration of a full subgradient trajectory, with buffer-structured transitions among strata.
Theoretical and Practical Implications
Theoretical Significance
This work provides the first explicit, finite-time rates for subgradient descent on broad (semialgebraic/definable) nonsmooth, nonconvex functions, replacing previous asymptotic-only results and connecting the complexity of the algorithm directly to geometric invariants of the objective via stratification. The construction of global Lipschitz stratifications and the derivations of global projection properties represent a significant technical expansion of the geometric analysis toolkit available for nonsmooth optimization.
Practical Consequences
While the worst-case rates have exponential dimension dependence, the authors note this is not intrinsic, and practical problem instances (including deep neural networks, whose loss landscapes are semialgebraic upon compact restriction) often traverse strata of higher rank and lower effective complexity. The analysis reveals fine structure in the trajectory of SubGD, especially in architectures with ReLU-type nonsmoothness, and points toward principled ways to quantify optimization error and stationarity regardless of whether the encountered nonsmoothness is "accidental" or structural.
Open Directions and Future Developments
The framework suggests several future lines of investigation:
- Dimension-free complexity: Whether geometric or algorithmic methods could yield dimension-independent rates (removing exponential dependence on f9) for broader function classes.
- Extension to stochastic algorithms: Generalizing the analysis to stochastic subgradient methods, which are the norm in large-scale learning.
- Sharpness via Lojasiewicz exponents: Incorporating path-dependent (trajectory-specific) Lojasiewicz exponents could yield sharper rates for certain regimes or networks.
- Algorithmic exploitation of strata structure: Dynamic bias toward higher-rank strata (or explicit stratification-aware algorithms) might improve convergence in practice.
Conclusion
The paper establishes a rich, geometric convergence theory for subgradient descent on semialgebraic functions, founded on explicit control of the interaction between nonsmooth dynamics and stratified smooth structure. The techniques offer a powerful platform for both further theoretical exploration and practical error certification in modern nonsmooth optimization contexts.