- The paper introduces a novel log-augmented EPS representation that unifies structural and semantic signals for enhanced microservice diagnostics.
- It leverages an alarm-driven quota system and DPP-based diversity sampling to boost rare, diagnostically salient trace capture and improve root cause analysis.
- Empirical results show up to 3.5× better rare trace capture and sub-millisecond trace processing, outperforming state-of-the-art sampling methods.
Gleaner: A Semantically-Rich and Efficient Online Sampler for Microservice Diagnostics
Introduction and Motivation
Gleaner addresses a fundamental bottleneck in microservice observability pipelines: the inability of existing trace samplers to efficiently capture both structural and semantic (log-driven) signals critical for diagnostics. State-of-the-art tail-based samplers leverage post-mortem trace analysis, often using call graphs, but remain impuissant in discriminating between traces that are structurally normal but semantically anomalous—a limitation acutely problematic as modern RCA pipelines increasingly depend on intra-span events and trace-log correlation.
Random (head-based) sampling misrepresents the underlying long-tail distribution by overwhelmingly favoring frequent, healthy paths and excising diagnostically salient (rare or anomalous) executions. Meanwhile, recent advanced samplers incorporating logs (e.g., iTCRL) are prohibitively slow in online settings, relying on offline-trainable GNNs. This landscape reveals a clear fidelity-performance trade-off: practical methods lose semantic richness, while sophisticated ones are inapplicable at scale.
Gleaner dismantles this dichotomy by introducing a computationally lightweight, log-augmented event-pair set (EPS) representation for traces. It supplements this with an alarm-driven adaptive budgeting strategy and a DPP-based diversity sampling module, resulting in an online framework that is both semantically aware and deployment-feasible.
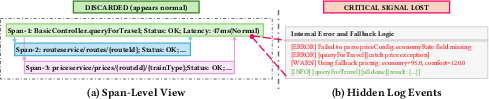
Figure 1: Example trace illustrating the semantic blind spot of span-centric samplers. Despite normal span-level attributes, an ERROR log reveals a critical failure, undetectable by traditional samplers.
System Architecture and Key Mechanisms
Gleaner is organized as a three-stage pipeline: Trace Encoder, Quota Allocator, and DPP Selector.
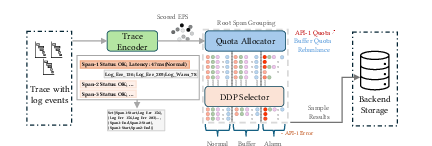
Figure 2: The three-stage pipeline architecture of Gleaner. Trace Encoder embeds semantic features, Quota Allocator adapts sampling budgets, DPP Selector greedily chooses a diverse and anomaly-rich trace subset.
EPS-Based Trace Representation
The Trace Encoder eschews explicit graph construction for an event-centric, bi-gram encoding over span lifecycle events and log templates. Logs are deduplicated and normalized via Drain, permitting robust ID assignment and stability across high-cardinality content. Inter-span parent-child relations are mapped as event pairs, preserving inter-service context, while intra-span ordering ensures resilience to asynchrony and timing noise. This enables a highly efficient set-based similarity computation (i.e., Jaccard), which dominates traditional graph kernel approaches both in expressiveness and runtime.
Gleaner computes per-trace anomaly scores as weighted sums of status errors, log frequencies, and latency indicators; these weights are SRE-configurable, not empirically brittle, ensuring decision resilience across failures modalities.
Alarm-Driven Quota Allocation
Recognizing the centrality of operational incidents, Gleaner integrates alarm hooks and API endpoint grouping (root span grouping) to adapt both global and per-group sampling quotas in real time. When traffic drops or alarm storms occur, quotas are adaptively increased or capped, preventing myopic allocation collapse and aligning trace selection with criticality in incident periods. The grouping validation demonstrates high intra-group semantico-structural homogeneity, justifying the use of DPP for within-group diversity maximization.
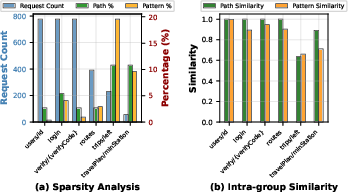
Figure 3: Root span grouping validation: high intra-group Jaccard similarity enables tractable DPP optimization for diversity.
Diversity-Preserving DPP Sampling
The determinantal point process (DPP) is adapted for the trace selection phase, with the kernel matrix encoding anomaly scores and EPS similarities. This encourages selection of mutually diverse, anomaly-rich traces. Two critical optimizations are introduced: (i) early termination, leveraging the high homogeneity within root span groups, and (ii) persistent cross-batch similarity caching, exploiting the recurrence of EPS fingerprints over time. The result is sub-millisecond trace processing, rendering DPP—usually intractable in such environments—production-viable.
Empirical Evaluation
Gleaner is comprehensively empirically evaluated on large-scale fault-injection microservice trace datasets (1.4M+ traces, 161 fault cases; 517 unique call paths), as well as public multi-system benchmarks.
- Quality/Diversity: At 10% sampling rate, Gleaner improves Trace Pattern Coverage by 11.6–128.7% and Shannon Entropy by 2.8–32.9% versus SOTA. At 1% rate, it achieves up to 3.5× better rare trace capture than TracePicker.
- Diagnostic Signal Amplification: At a 1% sampling rate, RCA (ShapleyIQ, Nezha) run on Gleaner-selected samples outperforms the same tools using entire (unsampled) trace sets, yielding +36.6% (AC@1) for ShapleyIQ and +72.7% for Nezha. Gleaner thus reframes sampling as signal amplification rather than merely data reduction.
- Efficiency: Trace processing throughput is 0.74ms/trace (26.5% faster than TracePicker and >90× faster than metric-correlated samplers). The benefit-cost ratio (unique pattern discovery per trace) is maximal among all considered methods, while precise budget compliance is maintained.
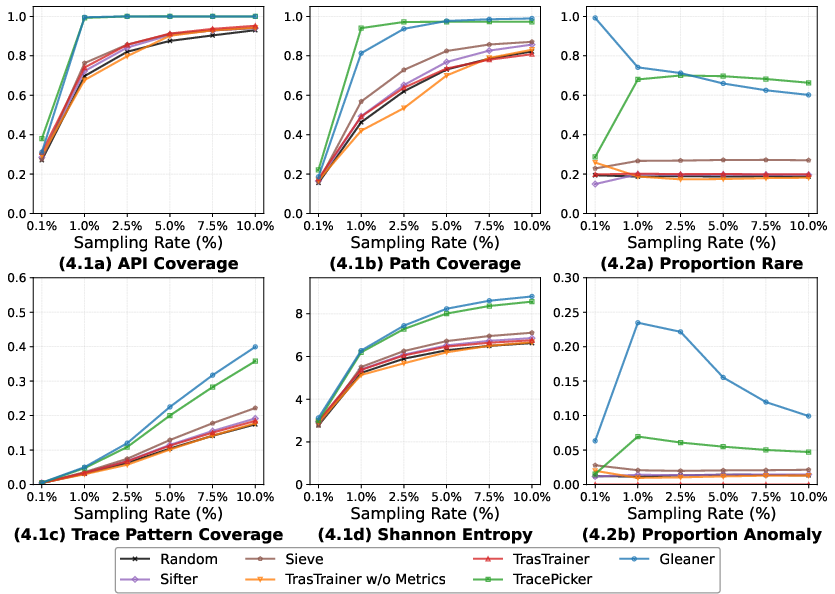
Figure 4: Sampling quality evaluation on Dataset A—Gleaner achieves superior coverage, entropy, and anomaly capture compared to all baselines.
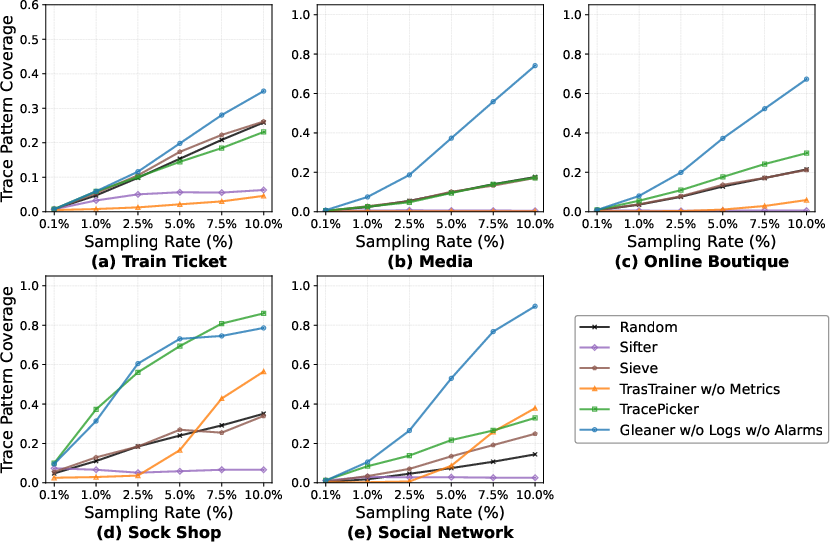
Figure 5: Cross-system evaluation (Dataset B): Gleaner generalizes and maintains superior pattern coverage and diversity robustness across diverse microservice architectures.
Ablation confirms the necessity of each architectural component: removing logs or alarm integration causes significant anomaly detection and RCA accuracy loss; replacing EPS with a graph kernel degrades both coverage and efficiency.
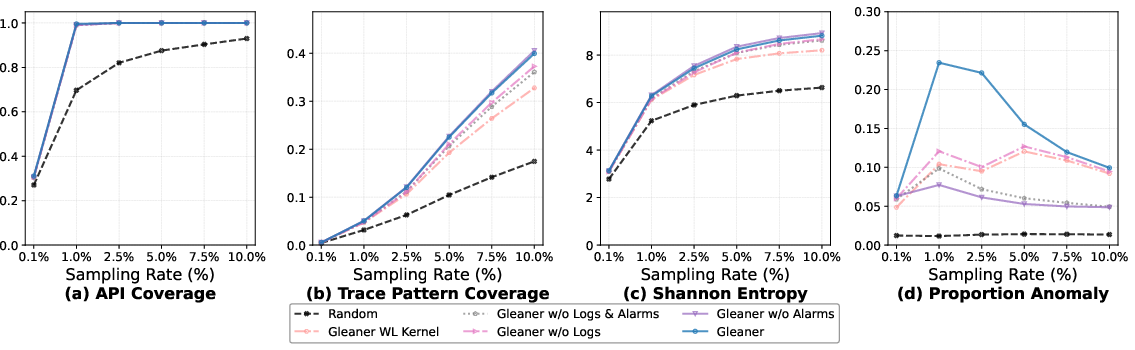
Figure 6: Ablation Study Group 1—structural and log-based components, and representations (EPS vs. WL Kernel) on Dataset A.
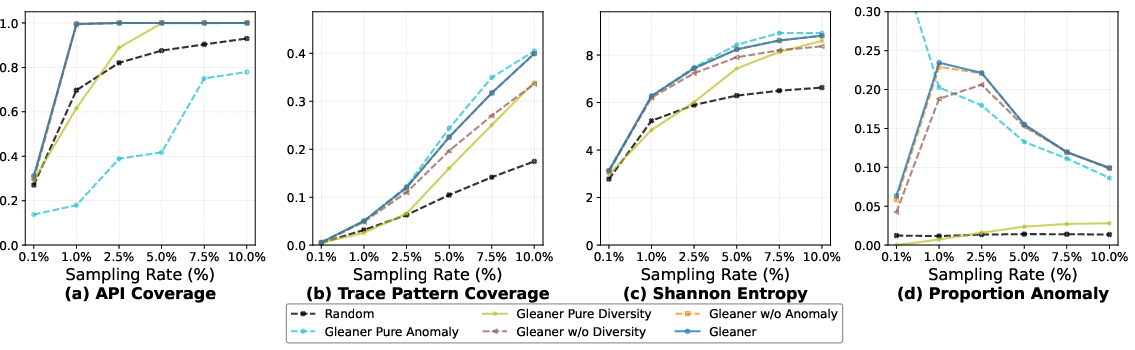
Figure 7: Ablation Study Group 2—sampling strategies. The synergy of anomaly bias, endpoint grouping, and diversity optimization is required for peak RCA accuracy.
Practical and Theoretical Implications
Gleaner operationalizes a paradigm shift in observability practices: intelligent sampling is not simply subsampling noise but is a signal transformation and curation stage—actively boosting the diagnostic utility of downstream toolchains by synthesizing both structural and semantic diversity at scale. The EPS formalism demonstrates that semantically augmented, set-based representations are not only tractable, but outperform exact graph models in production-grade environments—a finding of consequence for future multi-modal RCA system design, real-time analysis, and data-efficient learning. Additionally, incident-aware adaptive budgeting aligns sampling with SRE workflows, making Gleaner directly integrable with incident management playbooks.
The capacity of Gleaner-sampled subsets to outperform full datasets in RCA accuracy has nontrivial implications for AIOps pipelines: properly curated observability data not only mitigates storage and analysis costs but can surpass brute-force raw data accumulation in fault localization efficacy, fundamentally challenging the principle that "more data is always better."
This approach is most impactful in systems with heterogeneous entry points and rich event instrumentation. In single-entry, structurally-dominant workloads, Gleaner's behavior gracefully regresses to coverage-driven selection, losing but not negating its distinctions over naive alternatives.
Future Directions
Future developments should consider extending Gleaner to omnidata settings (beyond traces/logs to metrics and alarms), integrating further with retroactive sampling/aggregation architectures such as Mint or Hindsight, and evaluating representations robust to partial and lossy instrumentation prevalent in large-scale production clouds. More broadly, this paradigm can facilitate data-efficient online learning, causality inference for RCA, and self-adaptive sampling policies in the context of autonomous incident response.
Conclusion
Gleaner delivers an efficient, semantically-rich, and practically deployable sampler for microservice trace diagnostics, achieving high-dimensional pattern coverage, anomaly prioritization, and significant downstream RCA accuracy improvement—all within stringent real-world runtime and memory constraints (2604.16810). By bridging inter-span structure with intra-span semantics using EPS encoding and diverse, alarm-driven budgeting, Gleaner supersedes both structurally naive and computationally prohibitive alternatives, setting a new operational standard for trace sampling in observability pipelines.