- The paper presents a novel diffusion-based framework that unifies multilingual conditioning and personal style for realistic speech-driven facial animation.
- The approach leverages pretrained modules (mHuBERT, Whisper, CLIP, and a style encoder) and a transformer-based diffusion decoder to generate temporally coherent 3D facial expressions.
- Quantitative evaluations on a 20-language dataset show lower LVE (0.199), MVE (0.041), and DTW (0.126) error rates compared to state-of-the-art methods.
Polyglot: Multilingual Style-Preserving Speech-Driven Facial Animation
Introduction and Motivation
The paper "Polyglot: Multilingual Style Preserving Speech-Driven Facial Animation" (2604.16108) introduces a unification of multilingual and personalized speech-driven facial animation (SDFA) via a diffusion-based generative framework. Prior SDFA architectures predominantly operate under monolingual assumptions and rarely jointly model both language and idiosyncratic speaker style, resulting in insufficient handling of expressive and linguistically appropriate face motion in realistic scenarios. This work posits that cross-lingual phonetics, prosody, rhythm, and expressive gestures impose significant nonlinearities on facial kinematics, which can only be addressed by explicit conditioning on high-dimensional language and speaker representations.
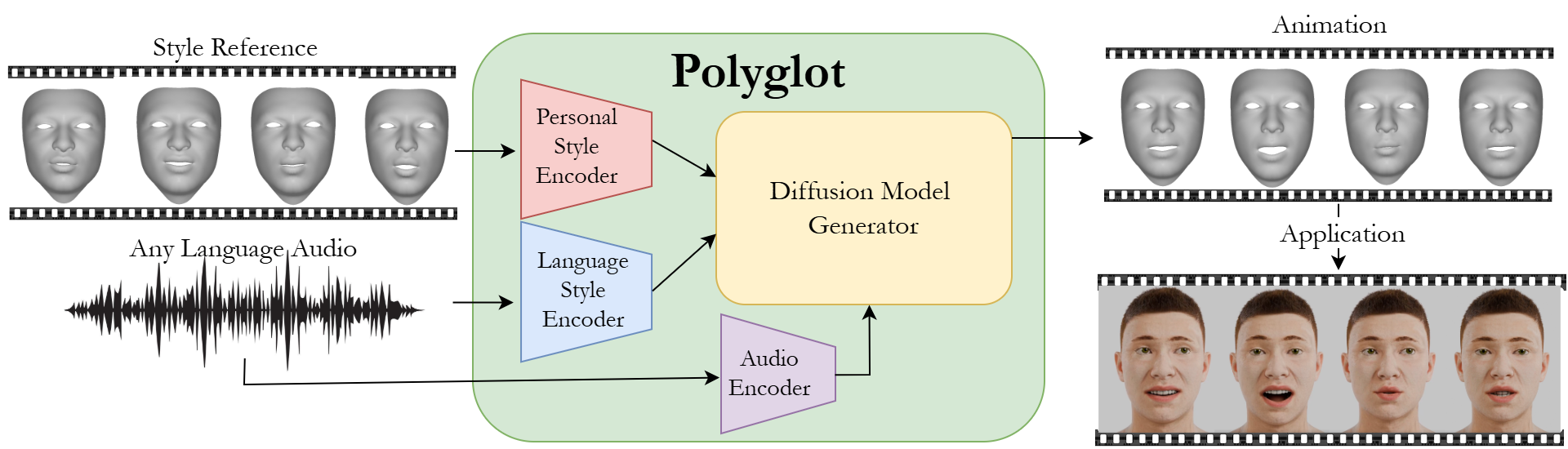
Figure 1: Polyglot, a deep learning architecture for speech-driven facial animation that preserves language and personal speaking styles during animation.
Polyglot Architecture
Polyglot implements a diffusion-based conditional generation pipeline leveraging both speech transcript (language) embeddings and personal style embeddings to generate 3D Morphable Model (3DMM) facial expression sequences. The system composes four pretrained submodules: mHuBERT (multilingual speech encoding), Whisper (ASR transcript extraction), CLIP (generic text encoder for semantic transcript embeddings), and a dedicated style encoder (trained to disentangle speaker-specific expressive patterns from facial motion). These features are aggregated and fed into a transformer-based diffusion decoder that generates temporally coherent sequences of 3DMM expression parameters.
Figure 2: Detailed architecture: audio is processed by mHuBERT, Whisper, and CLIP for features and language embeddings, while personal style is extracted from reference motion via an autoencoder; the diffusion decoder is conditioned on all signals.
The model is trained to denoise the facial expression parameters in the diffusion framework, using cross-modal conditioning vectors formed by concatenating transcript embedding, shape identity, and style embedding. Polyglot does not require predefined categorical language or speaker labels; speaker style extraction and language encoding are both fully data-driven and context-sensitive, maximizing generalization and scalability.
Language and Style Representation Analysis
The language embeddings are computed by passing transcripts (from Whisper) through CLIP's text encoder. Despite CLIP being primarily trained in English, Polyglot demonstrates that CLIP embeddings retain meaningful structure for unseen scripts and correlate with linguistic distance.
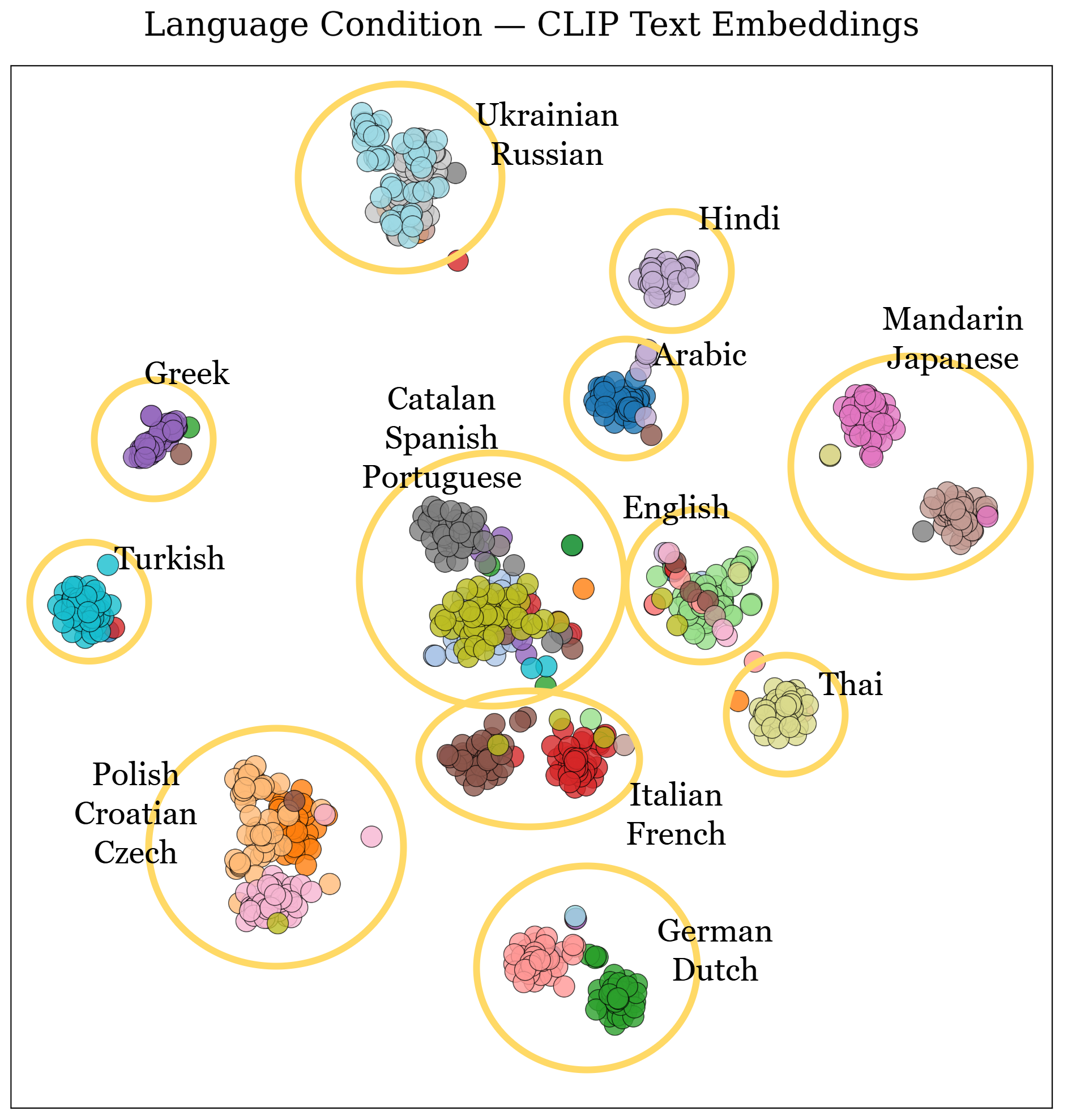
Figure 3: t-SNE plot of transcript-based embeddings for 20 languages, showing clustering of related languages and proper separation in the semantic latent space.
For style representation, the style encoder autoregressively encodes temporal facial motion sequences to an identity-specific embedding. Qualitative and quantitative analyses demonstrate robust inter-speaker disentanglement and intra-speaker consistency, substantiating the architecture's capability to generalize style within and across languages. Intra-style consistency is visualized by t-SNE alignment between reference and generated sequences with controlled input variation.

Figure 4: t-SNE plot of personal style embeddings—distinct clusters for each identity validate capture and separation of idiosyncratic expressive traits.
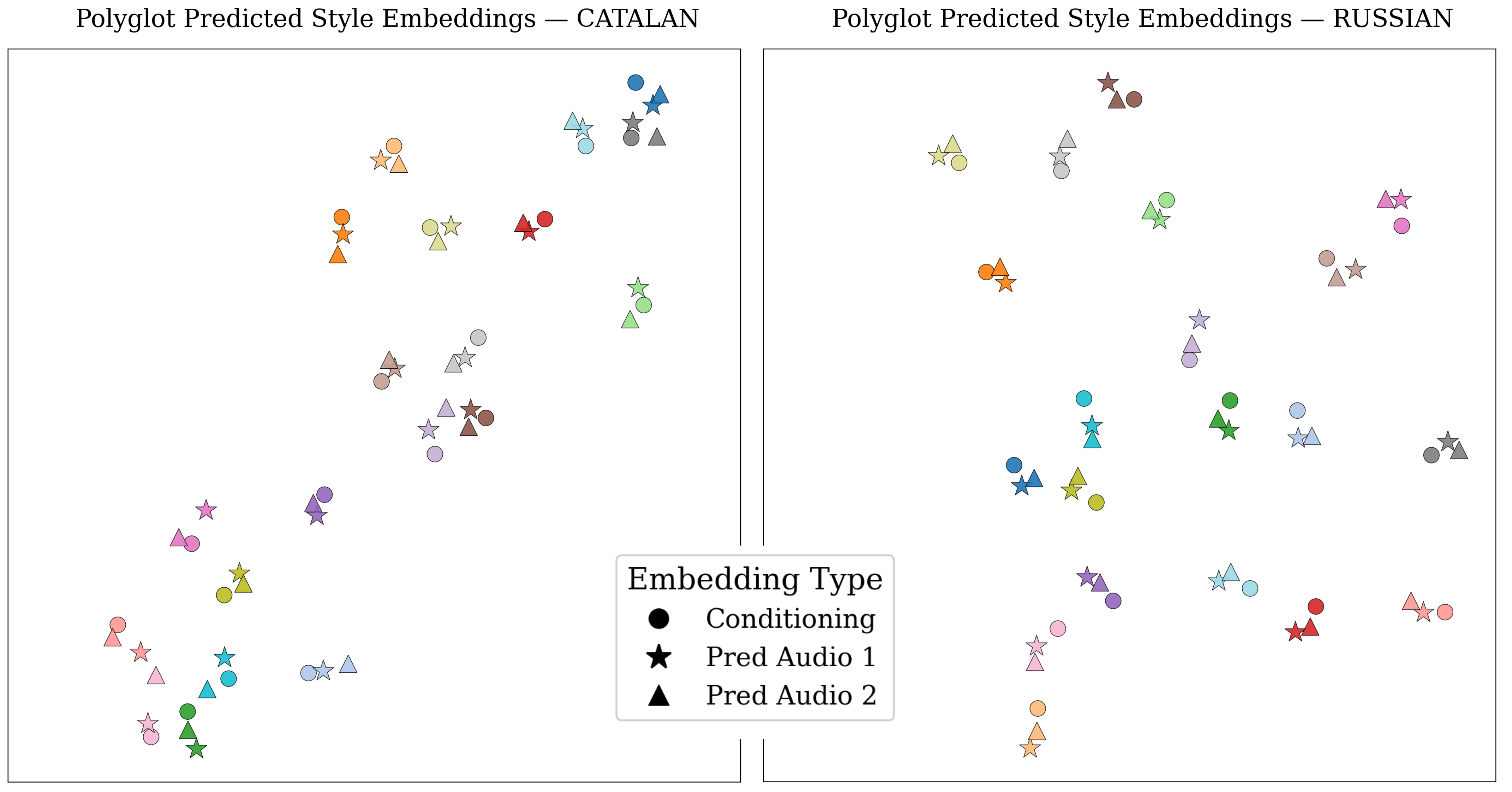
Figure 5: Personal style embeddings from Polyglot generations (with varying audio but fixed style) overlap with original style clusters, indicating faithful preservation during generation.
Experimental Results: Quantitative and Qualitative Outcomes
Polyglot's efficacy is established through controlled experiments on PolySet, a curated 20-language dataset with 3DMM annotations and high-quality audio. Four key metrics are evaluated: LVE/MVE (ℓ2 lip/mean vertex errors), DTW (temporal lip-syncing alignment), and MOD (mouth opening dynamics).
In cross-lingual and monolingual evaluations against SOTA baselines (FaceFormer, SelfTalk, DiffPoseTalk, MultiTalk, S-Faceformer, S-DiffPoseTalk), Polyglot yields lowest error rates on nearly all tasks. In the 20-language evaluation, the model achieves LVE of 0.199, MVE of 0.041, and DTW of 0.126, outperforming both language-aware (MultiTalk) and style-aware (S-Faceformer, S-DiffPoseTalk) competitors. This establishes a strong claim: joint style-language conditioning outperforms previous SOTA that only targets language or style in isolation.
Figure 6: Japanese—demonstrating qualitative accuracy in animation for non-Latin, rhythmically and phonetically distant language.

Figure 7: Greyman visualization against ground-truth—Polyglot aligns lip and facial motion more closely than leading benchmarks.
Ablation studies validate that omitting style or language conditioning or reducing training language diversity significantly degrades performance, particularly in multilingual inference. Conditioning via transcript embedding (rather than fixed lookup tables) is shown to produce finer, language-aware kinematic nuances. The style preservation loss further enhances retention of identity-specific expressiveness.
User Study and Human-Centric Evaluation
A user study with 30 participants was conducted to assess perceptual realism and lip-sync fidelity. Polyglot is preferred over FaceFormer, SelfTalk, and DiffPoseTalk in both naturalness (up to 81.3%) and lip-sync quality (up to 90.6%), and matches or exceeds MultiTalk, which only captures language conditioning.
Implications, Limitations, and Future Directions
Polyglot sets a new technical baseline for realistic speech-driven animation in globalized, linguistically and stylistically heterogeneous deployment scenarios. Its elimination of hard-coded language/speaker taxonomies enhances adaptability, making it highly viable for digital avatars, multi-language dubbing, cross-cultural creative production, and immersive conversational agents.
A key practical implication is the model's plug-and-play compatibility with new languages or speaker expressive domains, since neither retraining nor explicit labeling is required. Theoretically, the success of transcript-based language conditioning indicates the latent semantic alignment of multilingual encoders can be leveraged beyond their original PLM/CLIP domains for generative conditioning.
Potential limitations include reliance on ASR and transcript quality for highly under-resourced or noisy audio conditions, and scalability of style encoding for extreme speaker-idiosyncratic cohorts. Future work directions include integrating richer, explicitly multilingual text embeddings (e.g., E5, mBERT, xCLIP), incorporating emotional state disentanglement, and improving generative tractability via efficient sampling or distillation.
Conclusion
Polyglot delivers a unified, scalable, and high-fidelity framework for speech-driven facial animation that explicitly binds the dimensions of spoken language and personal expressive style in a diffusion generative paradigm. The framework's generalization, expressivity, and strong empirical performance on both structural and perceptual metrics mark a significant development for controllable, realistic digital avatars in truly global environments (2604.16108).