- The paper presents 3DiFACE, a diffusion-based framework that integrates viseme-level training, speaking-style personalization, and SGDiff for precise 3D facial and head motion synthesis.
- It decomposes animation into facial and head motion, utilizing dual 1D U-Net generators with a shared Wav2Vec2.0 encoder to ensure robust synthesis and editing.
- Experimental results and ablation studies demonstrate superior lip-sync accuracy, style adaptation, and efficient inference, outperforming state-of-the-art methods.
3DiFACE: Synthesizing and Editing Holistic 3D Facial Animation
Introduction
The paper introduces 3DiFACE, a diffusion-based framework for holistic 3D facial animation synthesis and editing from speech. The method addresses key limitations in prior speech-driven animation systems, including lack of precise editing capabilities, insufficient modeling of head motion, and poor handling of viseme-level diversity. 3DiFACE leverages a fully convolutional 1D U-Net architecture, viseme-level training, speaking-style personalization, and a novel sparsely-guided diffusion (SGDiff) mechanism to enable both diverse generation and fine-grained editing of facial and head motion.
Methodology
Holistic Motion Modeling
3DiFACE decomposes holistic facial animation into two components: facial motion and head motion, each modeled by a separate diffusion-based generator sharing a pretrained Wav2Vec2.0 audio encoder. The facial motion generator predicts 3D vertex displacements of a template mesh, while the head motion generator outputs neck joint rotations in the FLAME model space.
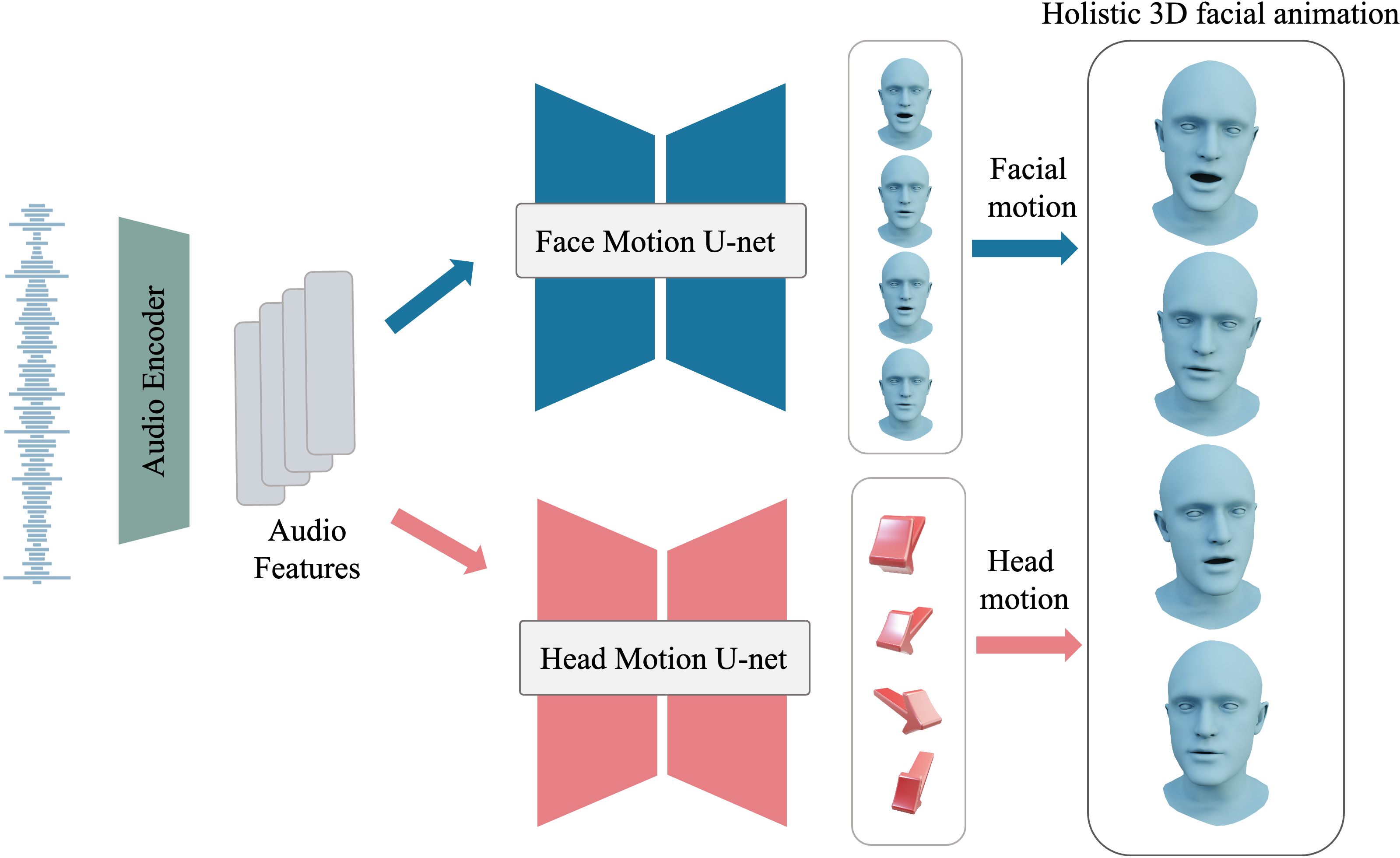
Figure 1: Overview of the dual diffusion-based motion generators with shared audio encoder for separate modeling of facial and head motion.
Facial Motion Generator
The facial motion generator employs a 1D convolutional U-Net, eschewing attention mechanisms in favor of feature concatenation. This design enables training on short viseme-level segments (e.g., 30 frames) and generalization to arbitrary sequence lengths at inference. The model is trained to directly predict ground truth displacements, with an auxiliary velocity loss to enforce temporal smoothness. Speaking-style personalization is achieved via fine-tuning on a short reference video, using monocular mesh reconstructions as pseudo ground truth.
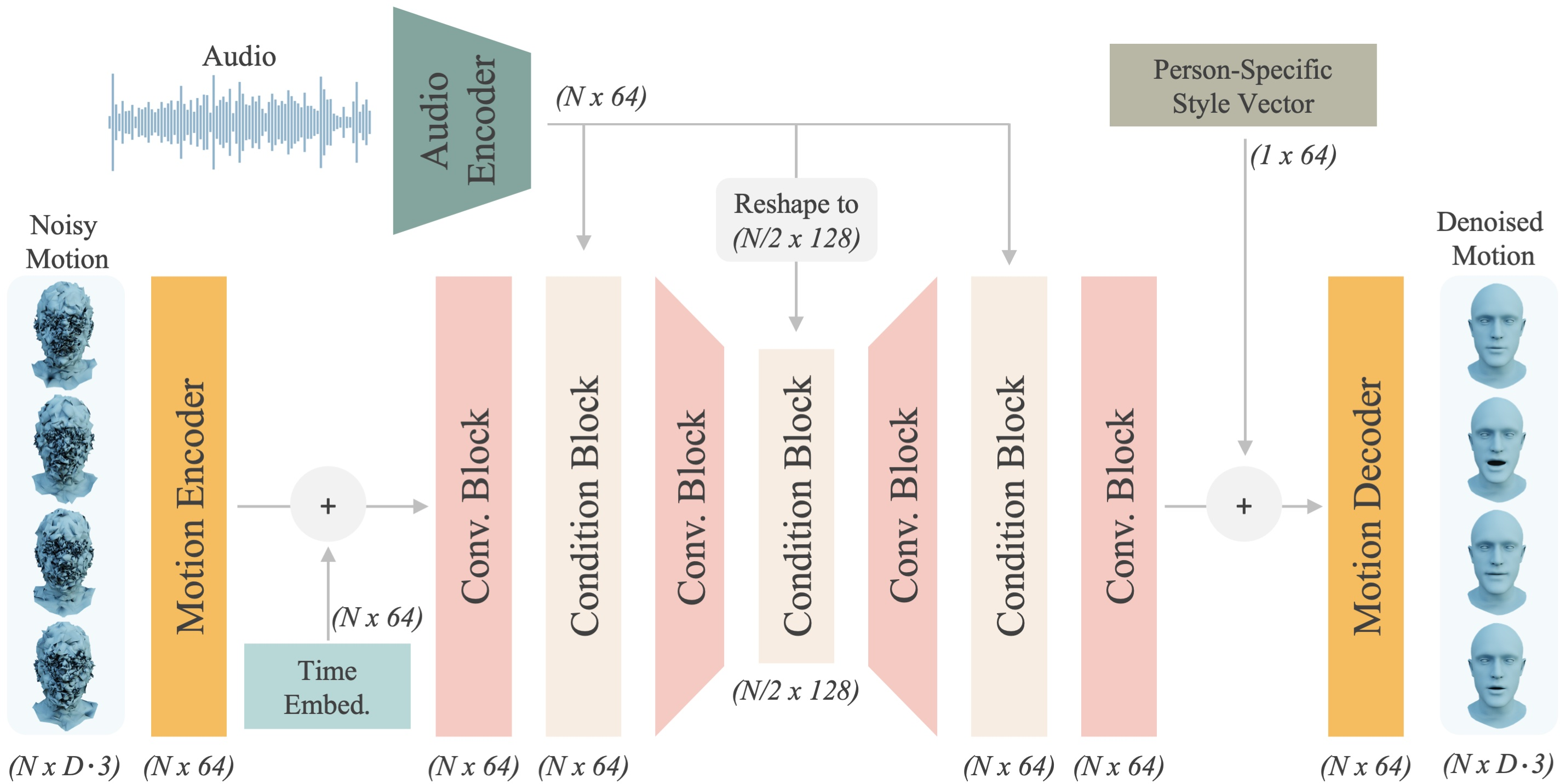
Figure 2: The facial motion generator denoises vertex displacements xt using audio features A^ and person-specific style vector Si.
Head Motion Generator and Sparsely-Guided Diffusion
Head motion is modeled with a convolutional U-Net and skip connections, conditioned on audio features. The SGDiff mechanism injects sparse ground truth signals (keyframes or inbetweening masks) into the noisy input during both training and inference, concatenated with a guidance flag. This enforces precise reproduction of the imputation signal and prevents the model from ignoring sparse editing cues, a common failure mode in standard diffusion-based editing.
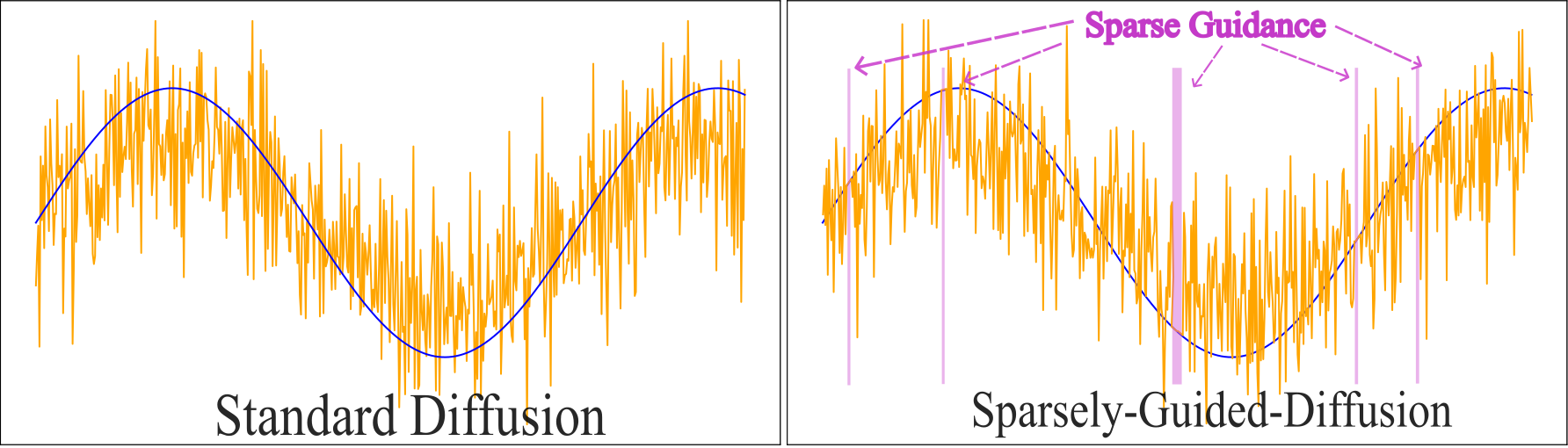
Figure 3: Comparison of standard diffusion (left) and sparsely-guided diffusion (right), illustrating the injection of ground truth signals and guidance flags for precise editing.
Sampling and Editing
At inference, new animations are generated by iterative denoising from random noise. For editing, noisy samples are replaced with user-defined imputation signals (keyframes or partial sequences) at each diffusion step. The facial motion generator is personalized before editing, while the head motion generator uses SGDiff for robust editing.
Experimental Results
Qualitative and Quantitative Evaluation
3DiFACE is evaluated against state-of-the-art baselines (SadTalker, TalkSHOW, VOCA, Faceformer, CodeTalker, EMOTE, FaceDiffuser, Imitator) on holistic 3D facial animation and facial motion synthesis tasks. The method demonstrates superior lip-sync accuracy, beat alignment, and diversity metrics, with the ability to trade off fidelity and diversity via the classifier-free guidance scale.
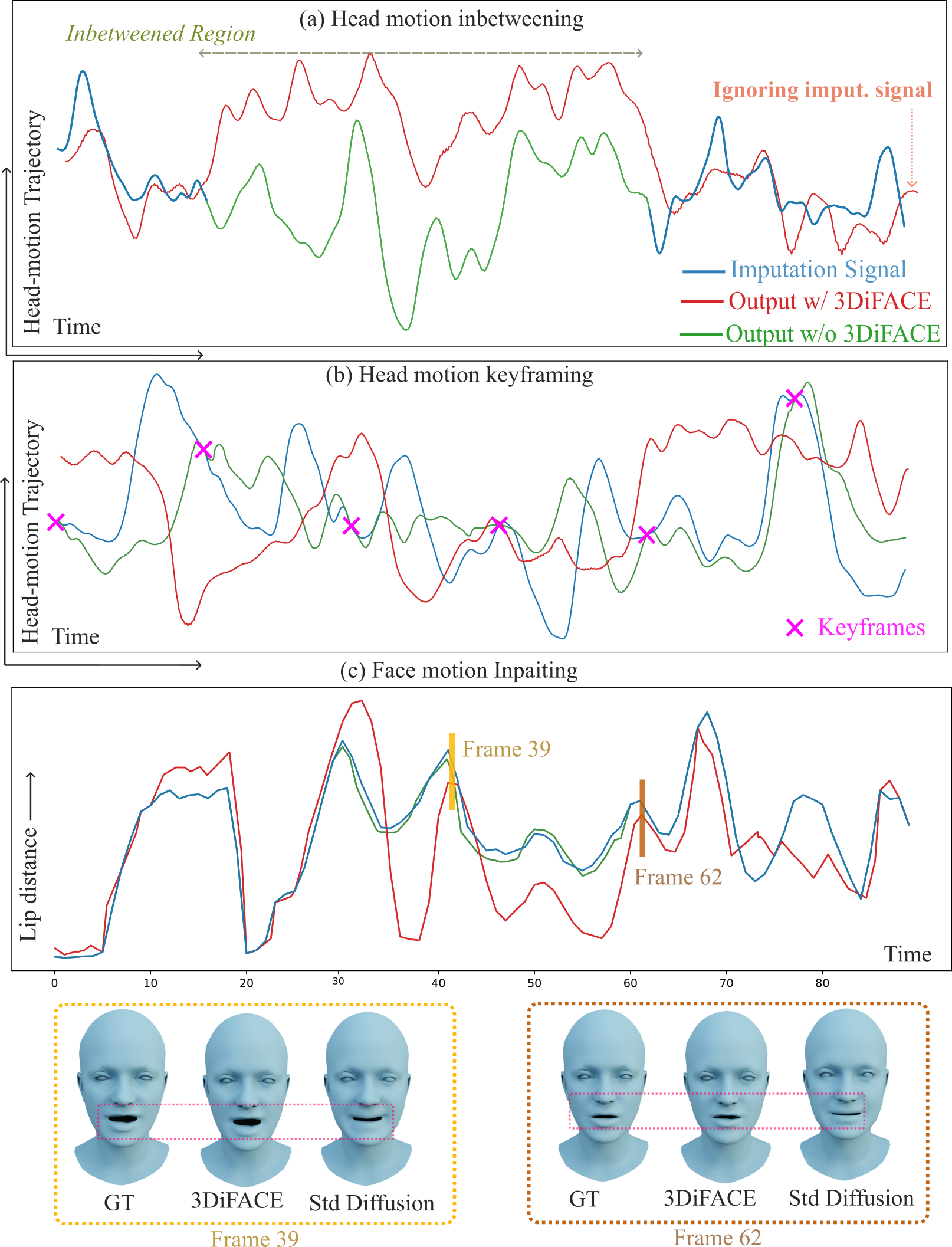
Figure 4: Holistic 3D facial motion editing with and without 3DiFACE, showing improved adherence to imputation signals and seamless style transitions.
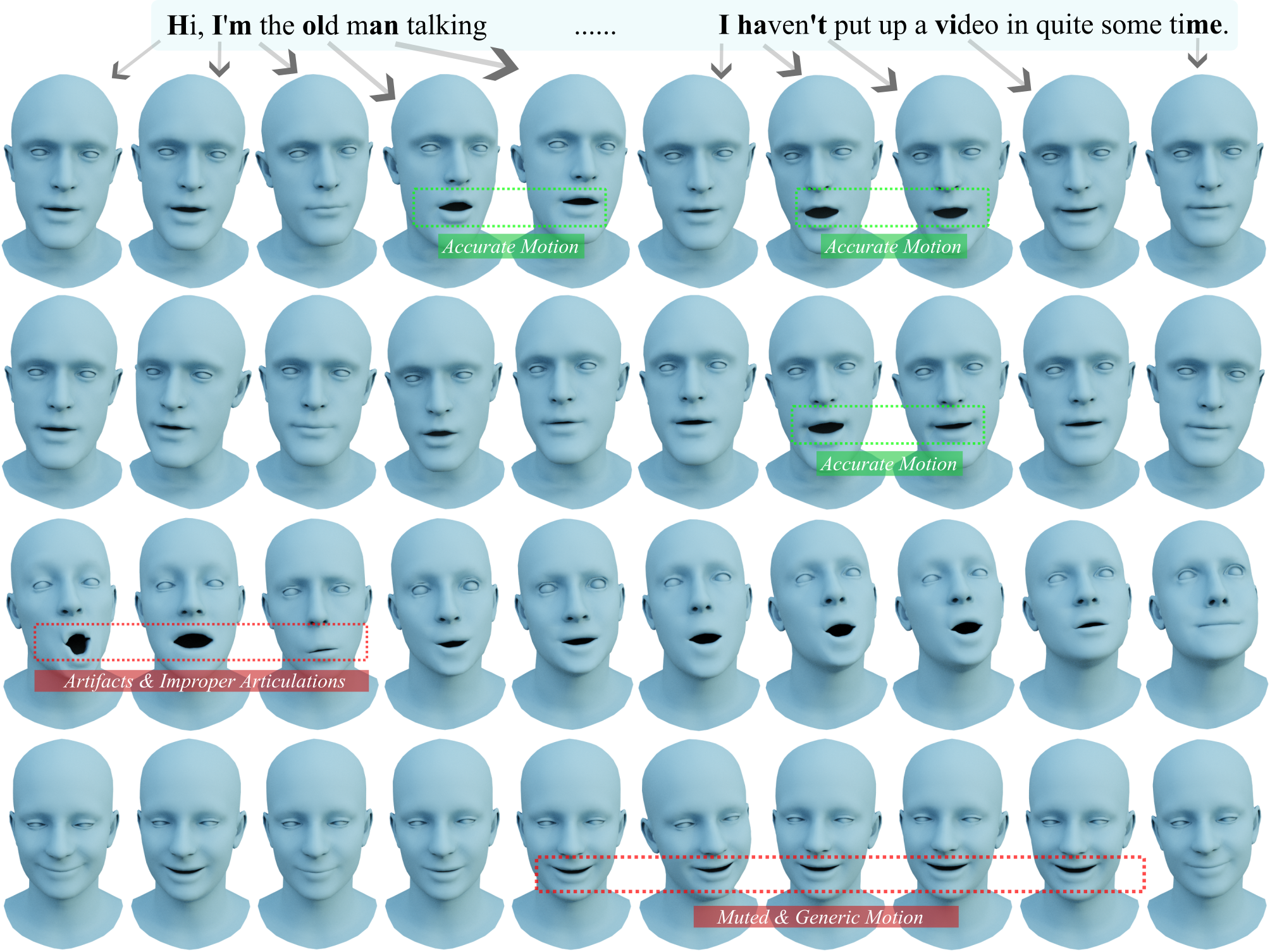
Figure 5: Qualitative comparison showing 3DiFACE's superior lip-synced facial animations and diverse head movements versus TalkSHOW and SadTalker.
User studies confirm perceptual improvements in both facial and head motion naturalness, as well as style similarity. 3DiFACE achieves high user preference rates over baselines in A/B tests.
Editing Capabilities
The SGDiff mechanism enables robust keyframing and inbetweening for head motion, with quantitative metrics showing improved fidelity as the strength of the imputation signal increases. For facial motion, style personalization is critical for seamless editing, preventing unrealistic style shifts.
Ablation Studies
Ablations demonstrate the necessity of the 1D convolutional architecture and viseme-level training for data efficiency and generalization. Fine-tuning with as little as 30–60 seconds of reference video suffices for effective speaking-style adaptation. SGDiff improves head motion diversity and editing flexibility with minimal quality loss.
Implementation Details
The system is trained on VOCAset for facial motion and HDTF for head motion, with in-the-wild videos used for personalization. Training employs ADAM with moderate compute requirements (single GPU, <32GB VRAM). Inference is efficient, outperforming concurrent methods in runtime per frame. Metrics include Dynamic Time Warping for lip-sync, diversity scores for lip/head motion, and beat alignment for head movement.
Discussion and Implications
3DiFACE bridges the gap between procedural animation (precise control, labor-intensive) and learning-based methods (diversity, speed), offering both high-fidelity synthesis and explicit editing via keyframes. The SGDiff mechanism generalizes to other domains requiring sparse control in diffusion models. The architecture is robust to limited training data and noise, and supports unconditional synthesis for background character animation.
Potential future directions include extending keyframe control to natural language conditions, improving tracker robustness for style adaptation, and integrating the framework into real-time avatar systems for AR/VR. The method's ability to generate and edit lifelike facial animations has direct applications in film, gaming, and virtual communication, but also raises ethical concerns regarding misuse in deepfake generation.
Conclusion
3DiFACE presents a comprehensive solution for speech-driven holistic 3D facial animation synthesis and editing, combining viseme-level diversity, speaking-style personalization, and sparsely-guided diffusion for precise control. The framework achieves state-of-the-art performance in both quantitative and perceptual evaluations, with efficient training and inference. Its modular design and editing capabilities make it a practical tool for professional animation pipelines and interactive avatar systems.

