- The paper introduces a novel physics-guided pre-training framework combining PVSS, ABRC, and PTCM to efficiently filter and mask ultrasound data.
- It leverages dual-stage visual and semantic screening using low-frequency DCT and MedCLIP embeddings to dramatically reduce training redundancy.
- Experimental results demonstrate state-of-the-art performance in segmentation, detection, and classification with mDice up to 99.59 and a 2.41× pre-training speedup.
PolarMAE: A Physics-Guided Unsupervised Pre-training Framework for Fetal Ultrasound
Motivation and Framework Overview
PolarMAE addresses key deficiencies in adapting generic Masked Image Modeling (MIM) frameworks to the demands of fetal ultrasound (US) imagery. Conventional MIM methods expend significant computation modeling continuous temporal and semantic redundancy in US video streams, forcing reconstruction of large invalid background regions and neglecting the non-uniform, radial distribution imposed by acoustic beamforming. PolarMAE refines MAE via three interconnected modules: Progressive Visual-Semantic Screening (PVSS), Acoustic-Bounded Region Constraint (ABRC), and Polar-Texture Collaborative Masking (PTCM). The architecture eliminates redundancy, strictly focuses modeling on valid anatomical regions, and guides masking based on geometric priors and texture, ensuring efficient, high-density representation learning.
Figure 1: An overview of the PolarMAE framework: semantic de-duplication, effective region extraction, and polar-guided masking tailor masked autoencoding to US physics and anatomy.
Key Technical Contributions
Progressive Visual-Semantic Screening (PVSS)
PVSS systematically curates high-value samples from the continuous US scanning streams. Low-frequency DCT features are used for initial visual-level de-duplication, followed by semantic similarity filtering leveraging MedCLIP latent embeddings. This dual-stage approach produces a compact set of ~260,000 high-information frames from an initial pool of ~430,000, drastically raising information density and pre-training efficiency without model overfitting to repetitive, low-value patterns.
Acoustic-Bounded Region Constraint (ABRC)
US images are characterized by bounded, fan-shaped fields of view, leaving large areas void of diagnostic content. ABRC computes the ROI mask for each frame, filtering patches by coverage ratio. Only patches with adequate ROI coverage are selected for subsequent modeling, ensuring that masked reconstruction is restricted to valid anatomical regions.
Polar-Texture Collaborative Masking (PTCM)
Building on ABRC-filtered frames, PTCM generates patch masking probabilities via fusion of polar-coordinate geometric priors and local HOG texture responses. This joint probability ensures masked autoencoding prioritizes both radial depth and boundaries of critical tissue structures, aligning sampling with the inherent physics of US beamforming and maximizing structural representation.
Figure 1: The pre-training workflow efficiently targets valid anatomical regions and maximizes information density by integrating physics priors and texture responses in mask sampling.
Experimental Results
PolarMAE outperforms competing methods—MAE, LocalMIM, SelectiveMAE, CrossMAE, UltraFedFM—across classification, object detection, and semantic segmentation tasks, achieving strong results despite using substantially fewer training frames due to PVSS filtering. On private and public segmentation benchmarks, PolarMAE attains the highest mDice (up to 99.59), best mAP@50:95 for detection, and superior classification accuracy. These numbers highlight the synergistic effect of PVSS, ABRC, and PTCM.
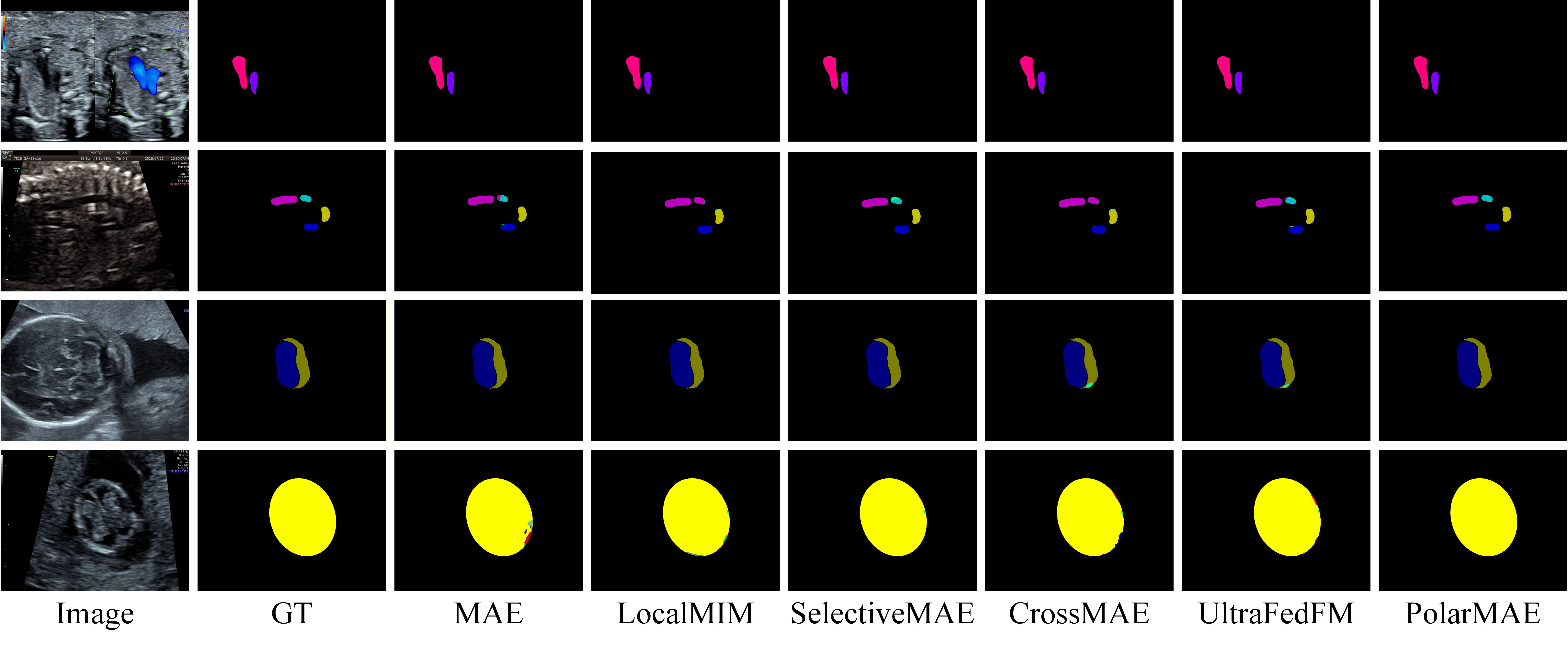
Figure 2: Qualitative segmentation results demonstrate sharp, anatomically consistent boundaries enabled by polar-guided masking.
Figure 3: Object detection output visualizations highlight robust anatomical localization in challenging regions.
Module Ablation and Masking Strategy Analysis
Ablation studies confirm the additive benefits of each module. PVSS alone preserves or enhances performance while reducing pre-training data volume. Successive integration of ABRC and PTCM yields further improvements, especially in segmentation tasks sensitive to structural boundaries. Comparative masking strategies indicate that combining HOG with polar-coordinate priors (PTCM) outperforms random masking or HOG+Gaussian approaches, underscoring the necessity of physics-aware design for US modality.
Computational Efficiency
PolarMAE attains optimal pre-training efficiency, requiring only 165 GPU hours—a 1.48× speedup over LocalMIM and an overall 2.41× acceleration relative to vanilla MAE. Module-wise, PVSS reduces baseline computation by 42%, and ABRC yields additional substantial savings.
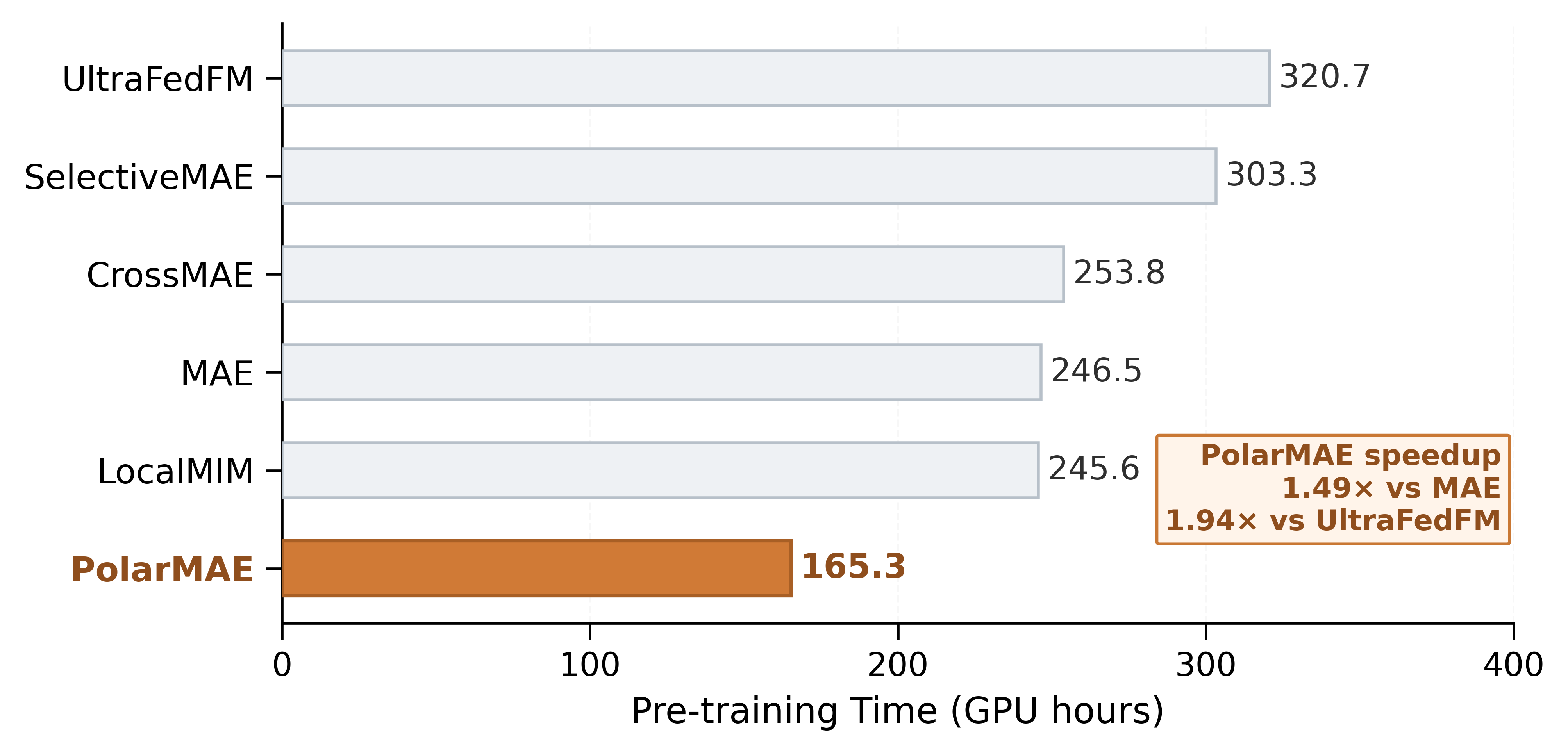
Figure 4: PolarMAE achieves best-in-class pre-training efficiency across evaluated methods.
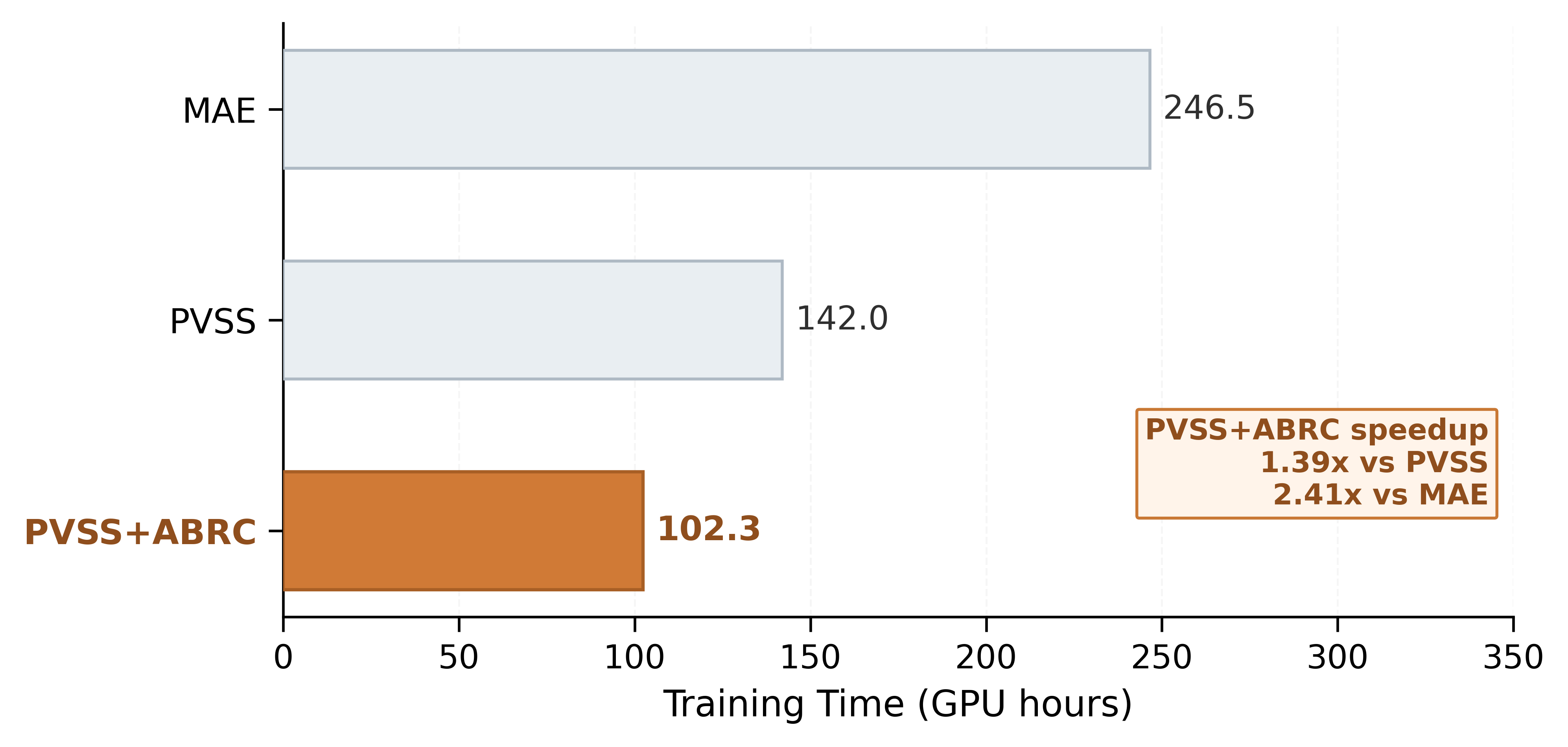
Figure 5: Progressive integration of PVSS and ABRC steadily and significantly reduces pre-training cost relative to baseline MAE.
Practical and Theoretical Implications
PolarMAE demonstrates that substantial improvements in both efficiency and downstream generalization derive not from increases in raw data scale, but from targeted, physics-aware curation and masking. The explicit modeling of US-specific characteristics—fan-shaped locality, polar-coordinate imaging geometry, structured redundancy—ensures that representations are robust, discriminative, and structurally consistent. Practically, this enables foundation models to be trained on compact, information-rich datasets, reducing annotation and computational requirements.
Theoretically, PolarMAE establishes a paradigm for domain-specific adaptation of self-supervised masking, highlighting the necessity of integrating acquisition geometry and physics. The methodology is extensible to other modalities with unique spatial priors, informing future adaptation of MIM frameworks to diverse clinical or scientific imaging domains.
Future Directions
PolarMAE's physics-informed pre-training is foundational for further advances in US analysis. Multi-modal integration (e.g., with clinical text or Doppler sequences) could leverage joint PVSS filters and masking strategies. Adaptive curriculum masking and generative modeling conditioned on polar priors may enable richer structural synthesis, segmentation, and diagnosis. Extending the approach to cross-institutional or multi-device settings will facilitate scalable, robust foundation models for prenatal diagnostics and beyond.
Conclusion
PolarMAE delivers efficient, high-fidelity unsupervised representation learning for fetal ultrasound via progressive semantic screening, acoustic region constraints, and polar-guided masking. Its architecture achieves state-of-the-art accuracy, structural consistency, and computational efficiency across diverse downstream interpretation tasks. Future work will extend its physics-aware pre-training to multi-modal and cross-domain foundation models, further elevating scalable AI in prenatal care.

