- The paper introduces WorldComposer, a pipeline that converts real-world panoramas into interactive, photorealistic 3D simulation environments.
- It generates systematic 'Digital Cousins' via prompt-based semantic and geometric editing, boosting domain randomization for robot learning.
- Quantitative results show significant improvements in policy success rates, underscoring the framework’s efficacy for robust sim-to-real applications.
Generative High-Fidelity Simulation with Digital Cousins for Generalizable Robot Learning
Framework Overview
The work introduces WorldComposer, an automated generative pipeline for high-fidelity, interactive robot simulation environments constructed directly from real-world panoramas. Unlike prior methods that rely on static digital twins or manual scene structuring, WorldComposer constructs editable, photorealistic 3D environments with minimal human intervention. It further synthesizes Digital Cousins—systematic variants of the original scene—through prompt-driven semantic and geometric editing. The environments feature multi-room stitching, interactive asset placement, and realistic physics for rigid, articulated, and deformable objects.
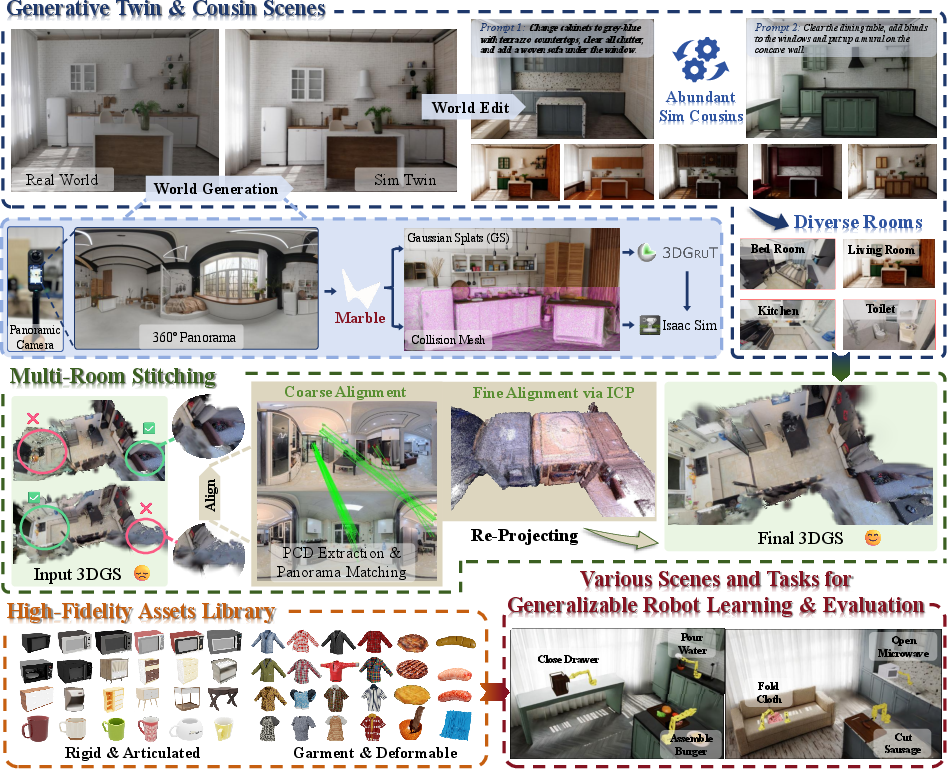
Figure 1: Overview of the WorldComposer framework, depicting generative real-to-sim construction, multi-room stitching, and high-fidelity asset integration for generalizable robot learning and evaluation.
This pipeline operates in three stages:
- Automated Real-to-Sim Scene Generation: Single-panorama captures are converted to 3D Gaussian Splatting representations using Marble, coupled with collsion meshes for interaction.
- Multi-Room Stitching: Disjoint rooms are aligned and merged via panoramic feature matching and ICP refinement to create house-scale environments amenable to navigation and multi-task reasoning.
- High-Fidelity Interactive Simulation: Scenes are populated with assets artistically and physically aligned, drawn from libraries for rigid, articulated, and deformable categories, supporting complex task domains.
Digital Twins and Cousins: Generative Scene and Object Variation
Traditional real-to-sim pipelines produce fixed digital twins, limiting policy generalizability due to the lack of environmental diversity. WorldComposer leverages prompt-based editing using Marble to generate Digital Cousins. These cousins preserve the semantic structural logic of the real scene but introduce systematic visual, geometric, and layout variations, achieving one-to-many augmentation required for robust domain randomization.

Figure 2: Transitions from sparse real-world captures to high-fidelity digital twins, and further to multiple digital cousin variations across diverse simulation tasks.
This includes changes to materials, spatial configuration, lighting, and scene style, as defined by language prompts. The process extends also to object instances: assets are varied via geometric and physical property perturbations, broadening the interactive space for manipulation and generalization.
Multi-Room Stitching and Large-Scale Navigation
To generate physically and semantically coherent environments at the scale of real homes, a multi-room stitching pipeline is implemented. Room panoramas are first coarsely aligned by matching SuperPoint-extracted local features, followed by metric scale resolution using ground-plane geometry. Fine alignment is performed via ICP between overlapping pointclouds from adjacent rooms. The merged environment is exported in USD format for direct integration with Isaac Sim.

Figure 3: Top: Multi-room navigation trajectory in a stitched environment; Bottom: First-person views during navigation.
Stitched environments enable zero-shot, long-horizon tasks such as object-goal navigation across distant locations, robust to both geometric artifacts and scene complexity. Asset placement leverages LLM-based reasoning to preserve usability and semantic affordance.
High-Fidelity Interactive Simulation: Asset and Physics Integration
The simulation platform supports asset injection at three tiers:
- Rigid: Accurate convex-decomposed meshes for stable grasping and collision.
- Articulated: Explicit kinematic chains and joint limits for mechanisms such as microwaves and drawers.
- Deformable/Fluid: Position-based dynamics for cloth, FEM for soft solids, and grid-based methods for fluid behaviors.
This versatility enables the evaluation of policies on manipulation tasks with diverse physical and semantic complexity.

Figure 4: Digital Twin (left) and Digital Cousin (right) environments illustrating high-fidelity variants across tasks.
Generalizable Robot Policy Learning and Evaluation
Policies are trained and evaluated not on static environments, but across a combinatorial set of digital cousins ranging over scene, object, and lighting variability. This allows for rigorous assessment of zero-shot generalization to unseen configuration distributions. The evaluation employs four policy architectures—ACT, Diffusion Policy, SmolVLA, and π0 (large-scale VLA foundation model)—across tasks spanning rigid, articulated, and deformable interactions.
Quantitative Results
Simulation and real-world experiments validate that:
- Training with augmented digital cousin data substantially improves policy robustness and success rate in both scene and object generalization regimes. For example, co-training with 200 additional cousin simulations increased average success rate (unseen objects) from 0.46 to 0.63 for Diffusion Policy.
- Success rates rise monotonically with scale-up in cousin data, with a representative task (“Set Tableware”) improving from 10% to 85% as synthetic cousin trajectories increase from 0 to 1,000.
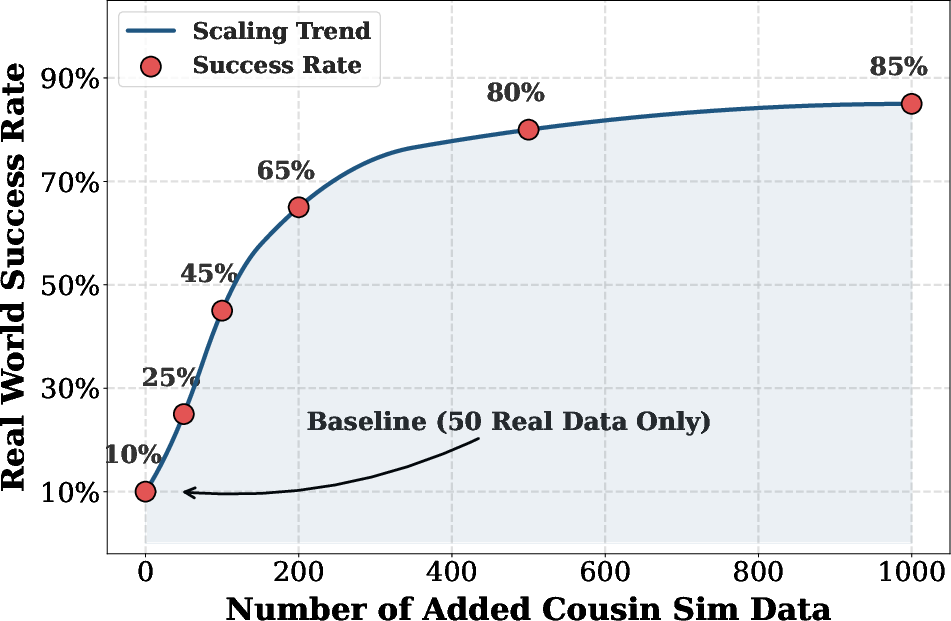
Figure 5: Real-world success rate on Set Tableware task with increasing cousin simulation data under unseen variations.
- Sim-to-real correlation is strong (r=0.91). Simulation success closely tracks real-world performance across models and generalization levels, preserving model rank-order and degradation patterns.
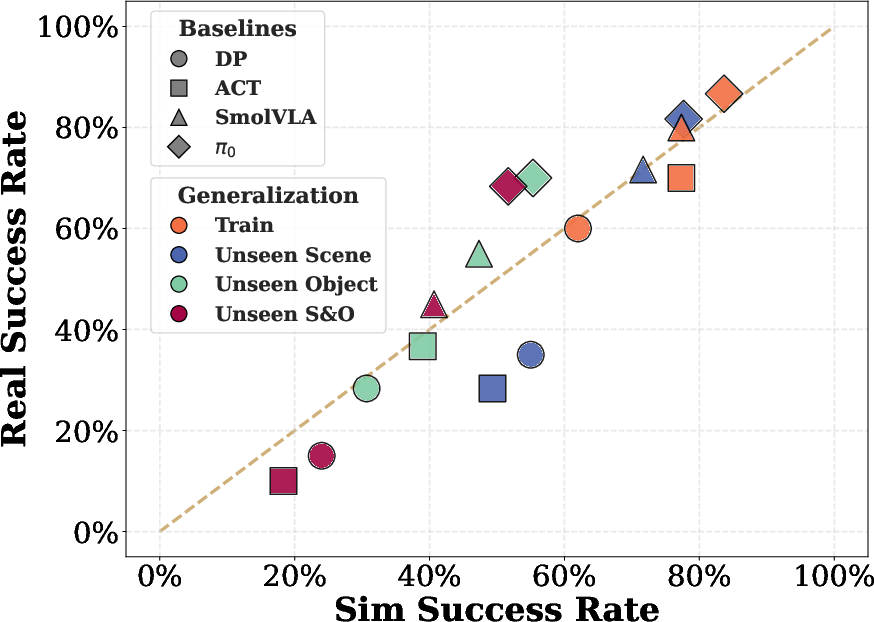
Figure 6: Scatter plots showing tight alignment between simulation and real-world success rates for various baselines across three tasks and four generalization scenarios.
- Navigation performance is strong with a demonstrated 68% average success rate on cross-room semantic goal reaching using VLFM, validating environment fidelity for tasks beyond tabletop manipulation.
The platform systematically advances over prior real-to-sim and simulation frameworks by combining:
- Automated real-to-sim mapping from panoramas to editable, interactive 3D environments;
- Systematic scene and object diversity generation (digital cousins);
- High-fidelity physical modeling (rigid, articulated, deformable, fluid);
- Multi-room scene composition supporting navigation and multi-task learning;
- Scalable, teleop-free data collection for large-batch policy training.
Implications and Future Prospects
Practically, this work demonstrates that high-quality generative simulation, when tightly coupled with real-scene data, bridges the sim-to-real gap for generalist robotic policy learning and evaluation. The direct, positive impact of cousin-driven augmentation on policy robustness, and the strong sim-real correlation, justify scaling such automated pipelines for reliable benchmarking and deployment across diverse robotics domains.
Theoretically, generative world models augmented by semantic editing and compositionality create a path towards scalable embodied intelligence, where policies can be stress-tested over unbounded environmental distributions. These findings motivate further research in:
- Instance-level reconstruption and object-centric editing for even finer data augmentation;
- Multi-modal generative integration (e.g., radiance field fusion for seamless texture and lighting at scene junctions);
- Self-supervised skill acquisition via unsupervised cousin generation;
- End-to-end closed-loop 3DGS optimization for enhanced real-to-sim fidelity.
Conclusion
WorldComposer sets a new benchmark for generative real-to-sim pipelines, enabling the creation of interactive, high-fidelity, and diverse digital environments with minimal manual intervention. Controlled environment augmentation via digital cousin generation demonstrably enhances generalist robot policy generalization and enables trustworthy simulation-based evaluation aligned to real-world performance. This approach will underpin scalable, rigorous development of robust embodied intelligence systems across unconstrained physical domains.