LGTM: Training-Free Light-Guided Text-to-Image Diffusion Model via Initial Noise Manipulation
Abstract: Diffusion models have demonstrated high-quality performance in conditional text-to-image generation, particularly with structural cues such as edges, layouts, and depth. However, lighting conditions have received limited attention and remain difficult to control within the generative process. Existing methods handle lighting through a two-stage pipeline that relights images after generation, which is inefficient. Moreover, they rely on fine-tuning with large datasets and heavy computation, limiting their adaptability to new models and tasks. To address this, we propose a novel Training-Free Light-Guided Text-to-Image Diffusion Model via Initial Noise Manipulation (LGTM), which manipulates the initial latent noise of the diffusion process to guide image generation with text prompts and user-specified light directions. Through a channel-wise analysis of the latent space, we find that selectively manipulating latent channels enables fine-grained lighting control without fine-tuning or modifying the pre-trained model. Extensive experiments show that our method surpasses prompt-based baselines in lighting consistency, while preserving image quality and text alignment. This approach introduces new possibilities for dynamic, user-guided light control. Furthermore, it integrates seamlessly with models like ControlNet, demonstrating adaptability across diverse scenarios.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper is about teaching AI image generators how to follow simple lighting instructions—like “light coming from the left”—without needing any extra training. The authors built a method called LGTM that lets users choose where the light should come from while the image is being created, so the picture looks more realistic and matches the prompt better.
What the researchers wanted to find out
They focused on three simple questions:
- Can we control where the light in a generated image comes from using just the starting “random noise” (the static-like beginning) of the AI model?
- Is there a part of the model’s internal “compressed image” where lighting is stored that we can tweak?
- Can this be done without retraining the model, and can it work with other tools that control shapes or edges (like ControlNet)?
How they did it (in everyday terms)
AI image generators that use diffusion models start by turning TV-like static into a picture that fits your prompt. Think of it like sculpting: you start with a noisy block and gradually carve out the final image.
- Latent space: Before the model draws in full detail, it works in a “compact blueprint” of the image. This blueprint has a few layers (called channels) that each hold different kinds of information.
- Initial noise: The “static” at the start isn’t meaningless—how it’s arranged influences the final picture.
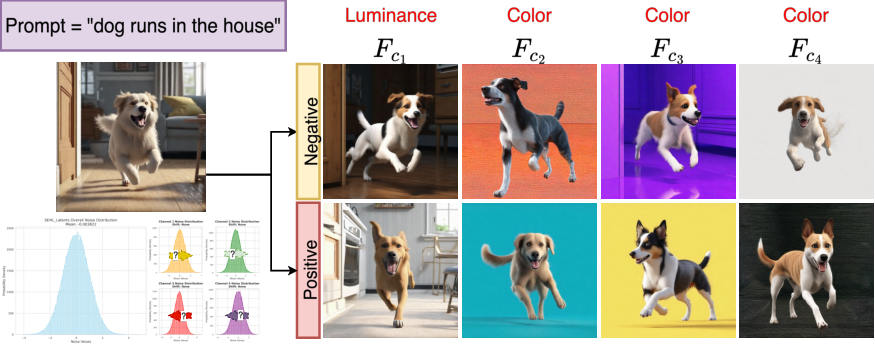
- Their discovery: By experimenting, the authors found that one specific layer (channel 1) in this compact blueprint strongly affects overall brightness and the direction the light seems to come from. Other channels mostly change colors.
- Their trick: They create a simple “light mask”—like a gentle brightness gradient—from the user’s chosen light direction (for example, brighter on the left, darker on the right). Then they apply this mask only to channel 1 of the starting noise. This nudges the model to grow shadows and highlights in the right places as it builds the image.
You can think of it like shading part of the clay before sculpting—so as the statue takes shape, it already has the right light and shadow.
They didn’t change the model or retrain it. They just adjusted how the process starts.
What they found and why it matters
- Lighting control worked much better: When asked for light from the left or right, their method made the shadows fall the correct way far more often (around 77–79% correct) than using normal text prompts alone (about 52%, which is basically random).
- Image quality stayed good: Measures of how nice the images looked and how well they matched the text stayed similar to the baseline. One score (FID) got worse, but that’s expected because deliberately changing lighting makes images different from the average lighting in the dataset—it doesn’t mean the images look worse.
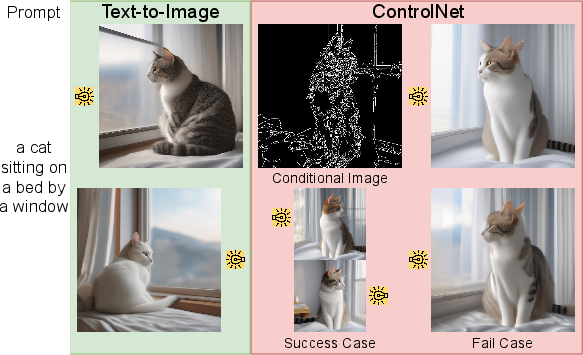
- Works with other tools: Their method can plug into systems like ControlNet, which control structure (like edges or layouts). That means you can control both where objects go and how they’re lit at the same time.
- No training needed: Because they only tweak the initial noise, this method is fast to adopt and easy to use with different models.
Why this matters: Lighting affects realism, mood, and storytelling. Giving users direct, reliable control over lighting makes AI-generated images more believable and more useful for art, design, and education.
What this could lead to (impact and limitations)
- Impact:
- Faster, easier lighting control: Artists and creators can quickly set the mood by steering light direction, without complicated prompts or expensive training.
- More flexible workflows: Because it’s “training-free,” it can be used with many existing text-to-image models and tools.
- Better multimodal control: You can combine lighting with other controls (like edge maps) for precise, creative results.
- Limitations and future work:
- Sometimes the subject turns to face the light: The model sometimes “rotates” the subject to match the lighting, even if you wanted a different pose. Future work will try to keep pose and lighting independent.
- Finer lighting effects: Expanding from simple light direction to more complex lighting (like multiple lights or soft indoor lighting) is a natural next step.
In short: The paper shows a clever, simple way to control lighting in AI-generated images by nudging the model at the very start. It’s practical, fast, and plays nicely with other tools—making it easier to get the look you want.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what the paper leaves missing, uncertain, or unexplored, with concrete directions for future work:
- Generality of “channel 1 encodes lighting”: no quantitative, causal, or information-theoretic analysis showing this holds across architectures, VAEs, or checkpoints beyond SDXL; unclear if channel indices are stable across different VAEs or re-initializations.
- Model family coverage: no experiments on SD 1.5/2.1, SDXL Turbo, DiT/pixel-space diffusion, or non-LDM models; unclear whether the approach transfers beyond SDXL’s VAE.
- Sensitivity to inference settings: no study of robustness to samplers (DDIM vs. Euler, DPM-Solver, etc.), step counts, and classifier-free guidance scales; effect of scheduler noise/variance not quantified.
- Strength control and stability: the method fixes a simple scaling z_T1 ← z_T1 * (1 + m_l); no systematic exploration of intensity hyperparameters (e.g., scaling factors > 1, clipping), their effect on fidelity/semantics, or failure modes at high control strength.
- Single-timestep injection: manipulation occurs only at the initial noise; no comparison against multi-timestep or schedule-aware injections that might improve control or stability.
- Mask design limitations: the light mask is a hand-crafted 2D linear gradient; it ignores scene geometry, occlusions, surface normals, material BRDFs, and camera pose, limiting physically plausible shadows and highlights.
- Limited light attributes: only direction (via a 2D mask) is controlled; no support for light color/temperature, softness/hardness, ambient fill, intensity calibration, environment maps, or multiple simultaneous light sources.
- UI–scene mismatch: mapping a 2D user click/line to plausible 3D scene illumination is under-specified; no mechanism for scene-aware falloff, area lights, or depth-conditioned light transport.
- Subject–light entanglement: the method biases subject pose/orientation to align with the light (documented limitation); no mechanism to disentangle pose from lighting or to enforce pose constraints concurrently.
- Interaction with other conditions: integration is shown only with ControlNet–Canny; no analysis with depth/normal/segmentation/pose conditions, or with composition of multiple conditions and their conflicts.
- Prompt complexity: evaluation uses simple BLIP captions for cats/dogs; no study with complex, multi-object, or compositional prompts where lighting may conflict with semantic constraints.
- Dataset scope: experiments limited to cats and dogs; no testing on diverse categories (humans, indoor/outdoor scenes, glossy/metallic materials, crowded scenes, architecture), limiting generalization claims.
- Angle coverage in evaluation: light control is evaluated only for left/right; no validation for arbitrary azimuth/elevation (front/back/top/bottom, oblique angles) or for continuous angle accuracy.
- Metric validity: the proposed “light accuracy” depends on YOLOv8 and a shadow detector trained on real photos; no calibration/validation of this pipeline on generated images or synthetic data with known ground-truth lighting.
- Shadow realism: only direction is scored; no metrics for shadow softness, length, contact shadows, penumbra/umbra quality, or specular highlight consistency with the specified light.
- Perceptual studies: no human studies on perceived lighting realism or direction accuracy; FID/NIMA/CLIP may not reflect photometric plausibility.
- FID interpretation: the claim that FID worsens due to distribution shift is not validated (e.g., by computing FID against a dataset matched for lighting or via alternative quality metrics less lighting-sensitive).
- Seed robustness and diversity: no analysis of variance across seeds, or whether manipulation reduces sample diversity or introduces mode collapse in lighting/appearance.
- Color/chroma side effects: channels 2–4 affect chroma; no study of whether channel-1 manipulation inadvertently causes color shifts or hue artifacts across styles/backgrounds.
- Resolution dependence: no study of how performance scales with image resolution or latent resolution; potential aliasing when mapping masks from pixel to latent space is not analyzed.
- Computation and efficiency: no runtime comparison vs. two-stage relighting pipelines; overhead of mask construction and noise manipulation not quantified.
- Video/temporal consistency: no experiments on video generation; open question how to enforce consistent lighting across frames while preserving motion and identity.
- Multi-light and spatially localized control: no method for combining multiple masks/lights, per-object lighting, or spatially varying illumination profiles.
- Reproducibility: code, evaluation scripts (especially for light accuracy), and masks are not reported as released; parameter defaults and ablation details (e.g., mask radius r) lack systematic guidance.
- Theoretical underpinning: no explanation for why the VAE’s first latent channel captures lighting (e.g., frequency/content decomposition or architectural priors); open question whether learned disentanglement can be induced or exploited more generally.
Practical Applications
Immediate Applications
Below are concrete near-term uses that can be implemented with today’s Stable Diffusion/SDXL stacks and common UIs (e.g., Automatic1111, ComfyUI), leveraging LGTM’s training-free initial-noise manipulation and light masks.
- AIGC platform “Light Direction” control
- Sectors: software, creative industries, advertising/marketing
- What: Add a “light_direction” parameter and a simple UI widget (circle dial or on-canvas light picker) to existing text-to-image apps; expose an API flag for programmatic control.
- Tools/products/workflows:
- ComfyUI/Automatic1111 node: “LGTM Light Mask” + “Latent Channel-1 Modulator”
- SaaS/AIGC APIs: stable endpoint with {prompt, seed, light_direction, radius}
- Assumptions/dependencies: Requires LDM-style VAEs (e.g., SD/SDXL) where latent channel 1 correlates with illumination; GPU inference; best for scenes where the base model already learned plausible shadows.
- Edge- and layout-aware generation with lighting (ControlNet + LGTM)
- Sectors: e-commerce, product design, advertising
- What: Generate product shots from canny/edge maps with consistent, brand-defined lighting (left-lit, back-lit).
- Tools/products/workflows: ControlNet pipeline with an added LGTM pre-step; templates for each SKU lighting direction.
- Assumptions/dependencies: Structural conditions must not be overly incompatible with the chosen light; limitation noted that subject pose may drift toward lighting direction.
- Creative A/B testing of lighting for campaign assets
- Sectors: marketing, media, publishing
- What: Produce fast lighting variants (e.g., left/right/top lighting) of the same concept to test click-through or brand feel.
- Tools/products/workflows: Batch prompt + seed control; iterate light masks programmatically.
- Assumptions/dependencies: Consistency across variants benefits from fixed seeds; FID may shift as lighting deviates from dataset norms (no quality loss implied).
- Storyboarding and previsualization with controlled mood lighting
- Sectors: film/TV, animation, photography
- What: Rapidly explore narrative lighting setups (e.g., rim light vs. side light) for storyboards and shot planning.
- Tools/products/workflows: Shot list + prompt book; per-shot “light_direction” settings; assemble boards.
- Assumptions/dependencies: Not physically accurate relighting; serves conceptual pre-vis.
- Game/art concept ideation with light studies
- Sectors: gaming, visual design
- What: Generate 2D concept art variants under different directional lights to guide later 3D/engine lighting.
- Tools/products/workflows: Prompt packs + LGTM presets for morning/evening key light directions.
- Assumptions/dependencies: Does not replace PBR lighting; used for visual ideation.
- Educational tools for teaching light and shadow
- Sectors: education (art/design schools, online courses)
- What: Interactive exercises that vary light direction to demonstrate shadow casting, model form, and mood.
- Tools/products/workflows: Web classroom modules exposing a dial for light direction; auto-generate comparison grids.
- Assumptions/dependencies: Demonstrative rather than physics-grade correctness; complements rather than replaces traditional lighting curricula.
- Social media content styling with consistent lighting
- Sectors: consumer/daily life, creator economy
- What: Influencers and hobbyists generate thumbnails or banners with signature lighting styles.
- Tools/products/workflows: Preset packs (“brand light: 45° left”) in mobile/desktop AIGC apps.
- Assumptions/dependencies: Requires accessible UIs and moderate compute; output realism depends on base model capability.
- Synthetic data augmentation with controlled illumination
- Sectors: robotics, manufacturing, autonomous systems, retail analytics
- What: Create image sets with systematic light variations (left/right/front) for robustness testing of vision models (e.g., detector resilience to shadows).
- Tools/products/workflows: Data generation scripts looping over light masks; downstream evaluation harness.
- Assumptions/dependencies: Not domain-physical; suitable for diagnostic robustness testing, not for training production models without careful validation.
- Light-consistency QA for AIGC pipelines
- Sectors: software tooling, creative ops
- What: Package the paper’s light-accuracy metric (object detection + shadow direction analysis) to check that outputs match specified light directions in batch pipelines.
- Tools/products/workflows: CI checks for creative pipelines using YOLO + shadow detector as in the paper; alerts when lighting deviates.
- Assumptions/dependencies: Depends on reliable object/shadow detectors; works best for scenes with clear shadows.
- Architectural/interior mood boards with directional lighting
- Sectors: architecture, real estate, interior design
- What: Generate conceptual visuals of rooms/facades under specified incoming light direction for mood boards and client discussions.
- Tools/products/workflows: Prompt templates for spaces + LGTM light presets.
- Assumptions/dependencies: Non-physical; good for aesthetic exploration, not engineering-grade daylighting analysis.
- Brand styleguides for lighting in generated imagery
- Sectors: enterprise design systems, marketing ops
- What: Codify a “brand light” (direction, radius/intensity) and enforce it in generated assets for consistency across channels.
- Tools/products/workflows: Locked light parameters in content generation services; audit via light-consistency QA.
- Assumptions/dependencies: Relies on stable base models; edge cases where subjects rotate toward light may need manual curation.
Long-Term Applications
These opportunities require further research, scaling, or integration beyond the current paper (e.g., tackling pose–light disentanglement, multi-light setups, or video consistency).
- Temporally consistent light control for text-to-video
- Sectors: media, advertising, education
- What: Extend noise manipulation across frames for consistent key-light direction in generated videos and cinemagraphs.
- Potential tools/products/workflows: Frame-wise correlated noise samplers; temporal light masks; video-aware ControlNet.
- Assumptions/dependencies: Requires temporal consistency mechanisms; careful handling of flicker and motion.
- 3D-/physics-aware lighting control (multi-source, HDRI)
- Sectors: VFX, gaming, AR/VR
- What: Map environment maps or multi-point lights to latent manipulations for plausible multi-shadow and bounce-light effects.
- Potential tools/products/workflows: Calibrate latent-channel responses to HDRI parameters; hybrid with 3D priors or normal/depth cues.
- Assumptions/dependencies: Needs learned or procedural mapping from HDRI to latent edits; may depend on 3D-aware diffusion or additional conditioning.
- Pose–light disentanglement and constraints
- Sectors: all visual content pipelines
- What: Overcome the paper’s limitation where subjects orient toward light; enable independent control of pose and illumination.
- Potential tools/products/workflows: Joint conditioning with stronger pose priors (keypoints/SMPL) and latent regularizers; per-step corrective signals.
- Assumptions/dependencies: Requires algorithmic advances in disentanglement and conflict resolution between conditions.
- “Light painting” interfaces for creatives
- Sectors: software, creative industries
- What: Interactive brush tools to paint light regions or gradients directly on a canvas to steer latent channel 1 spatially.
- Potential tools/products/workflows: Photoshop/ Krita/ Figma plugins; real-time previews with low-step samplers.
- Assumptions/dependencies: Efficient on-device inference or server-side streaming; fast feedback loops.
- Cross-model channel calibration tools
- Sectors: MLOps, AIGC platform engineering
- What: Automated discovery of illumination-correlated channels for different VAEs/models and packaging as model-specific LGTM profiles.
- Potential tools/products/workflows: Calibration suite that probes latent sensitivity and emits per-model config files.
- Assumptions/dependencies: Different VAEs may not share channel semantics; requires per-model analysis.
- Standardized benchmarks and metrics for light control
- Sectors: academia, industry R&D
- What: Curate datasets with controlled lighting references; evolve and validate metrics beyond the shadow-direction proxy.
- Potential tools/products/workflows: Public benchmark with relighting ground-truth; metric leaderboards.
- Assumptions/dependencies: Dataset collection and annotation complexity; consensus on evaluation protocols.
- Domain-specific simulators with controlled illumination
- Sectors: robotics, manufacturing QA, medical training
- What: Use controllable lighting for synthetic scenes to stress-test perception or train operators in variable lighting.
- Potential tools/products/workflows: Scenario banks with systematic light sweeps; integration with synthetic pipelines (e.g., NDDS, Omniverse) for hybrid 2D/3D.
- Assumptions/dependencies: For safety-critical domains, 2D T2I must be complemented with physically grounded simulators; risk of domain gap.
- AR try-on/virtual staging with environment-matched AI imagery
- Sectors: retail, real estate, AR/VR
- What: Adjust generated content’s light to match estimated real-world light from device sensors/camera.
- Potential tools/products/workflows: Mobile AR SDKs estimating light direction; feed estimated mask into LGTM; composite into scenes.
- Assumptions/dependencies: Accurate light estimation; consistent compositing; may require relighting modules for full realism.
- Content authenticity and policy tooling
- Sectors: policy/governance, platforms
- What: Given easier illumination manipulation, define disclosure policies and watermarking for light-directed AIGC; detectors for implausible light cues.
- Potential tools/products/workflows: Invisible watermarks flagged when “light_direction” is set; moderation heuristics for lighting inconsistencies.
- Assumptions/dependencies: Industry coordination on standards; adversarial robustness challenges.
- Enterprise-scale catalog automation with governance
- Sectors: e-commerce, marketplaces
- What: End-to-end pipelines generating on-brand product imagery with fixed lighting presets and audit trails.
- Potential tools/products/workflows: Workflow orchestration (e.g., Airflow) + LGTM nodes + QA metrics + human-in-the-loop review.
- Assumptions/dependencies: Legal/compliance review of synthetic imagery; integration with DAM/brand systems.
Notes on feasibility across applications:
- Core dependency: A latent-diffusion model with VAE channel semantics similar to SD/SDXL; channel-1/lighting correlation may vary across models and require calibration.
- Lighting masks are simple directional gradients; they approximate global directional light, not complex indoor/multi-source/occlusion-heavy setups.
- Compute: Typical SDXL inference (e.g., 50 steps) requires GPU; real-time or mobile use may need low-step samplers or server-side rendering.
- Quality trade-off: As shown, controllability can shift FID due to distribution changes; perceptual quality and text alignment remain comparable but should be monitored for specific deployments.
Glossary
- Canny edges: Edge maps produced by the Canny detector, often used as structural conditioning for diffusion models. "While ControlNet successfully generates images conditioned on text prompts and canny edges, it fails to account for specified lighting directions."
- Channel-wise sensitivity analysis: An ablation procedure that perturbs individual latent channels to measure their specific influence on generated attributes (e.g., lighting). "We first conduct a channel-wise sensitivity analysis of the VAE latent noise in Latent Diffusion Models (LDMs), and find that channel 1 is strongly correlated with global brightness and perceived light direction."
- CLIP (Contrastive Language–Image Pretraining): A pretrained model that aligns images and text in a joint embedding space; used here as a frozen text encoder. "However, Stable Diffusion adopts a frozen CLIP text encoder instead of a trainable text encoder ."
- CLIP-I: A CLIP-based image-level alignment metric used to assess similarity/consistency in image space. "Text-image alignment is assessed using CLIP-I and CLIP-T~\cite{hessel2021clipscore}."
- CLIP-T: A CLIP-based text–image alignment metric used to assess how well generated images match textual prompts. "Text-image alignment is assessed using CLIP-I and CLIP-T~\cite{hessel2021clipscore}."
- ControlNet: An auxiliary network that adds conditional controls (e.g., edges, poses) to diffusion models without retraining the base model. "In addition, by modifying only the initial noise, our method can be seamlessly applied to conditional modules such as ControlNet~\cite{zhang2023adding}, enabling simultaneous control over structural cues (e.g., edges) and illumination"
- DDIMSampler: A sampling algorithm based on Denoising Diffusion Implicit Models that accelerates inference in diffusion models. "For inference, we utilize the DDIMSampler with a guidance scale of 7.5 and 50 time steps."
- Denoising Diffusion Probabilistic Model (DDPM): A generative framework that learns to reverse a noising process to synthesize data from Gaussian noise. "Stable Diffusion employs a Denoising Diffusion Probabilistic Model (DDPM)~\cite{ho2020denoising} operating in the latent space of LDM."
- Fréchet Inception Distance (FID): A distributional distance between real and generated images used to evaluate realism and diversity. "To assess visual realism and aesthetics, we employ Fréchet Inception Distance (FID)~\cite{heusel2017gans} and Neural Image Assessment (NIMA)~\cite{talebi2018nima}."
- Guidance scale: The weight controlling classifier-free guidance strength during sampling to trade off fidelity and prompt adherence. "For inference, we utilize the DDIMSampler with a guidance scale of 7.5 and 50 time steps."
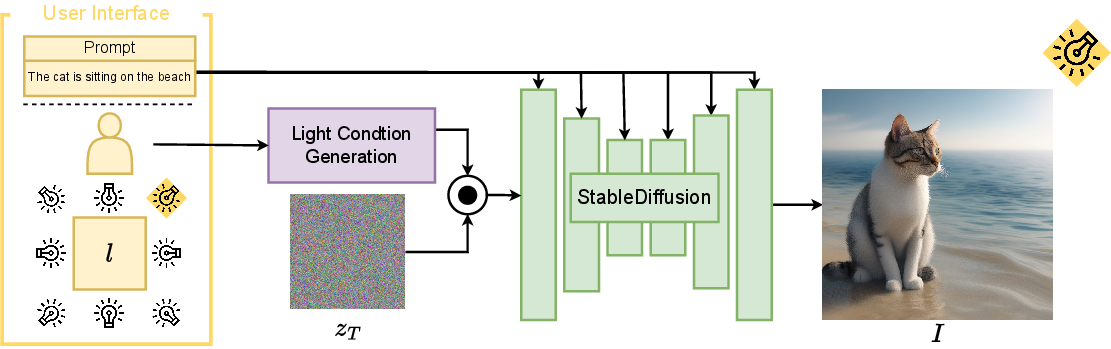
- Initial latent noise: The starting random latent tensor that the diffusion process denoises into an image; its structure can influence semantics and lighting. "we propose a novel Training-Free Light-Guided Text-to-Image Diffusion Model via Initial Noise Manipulation (LGTM), which manipulates the initial latent noise of the diffusion process to guide image generation with text prompts and user-specified light directions."
- Latent Diffusion Models (LDM): Diffusion models that operate in a compressed latent space of a VAE, improving efficiency and resolution. "Our method extends Latent Diffusion Models (LDM)~\cite{rombach2022high}, operating in the latent space of a VAE"
- Latent space: The compressed representation space (e.g., from a VAE) where diffusion steps are performed instead of pixel space. "operating in the latent space of a VAE encoders and decoders ~\cite{kingma2013auto}."
- Latent Space Light Guidance (LSLG): The proposed technique that modulates specific latent channels (notably channel 1) based on a light mask to control illumination. "Building on the generated light mask , we propose a Latent Space Light Guidance (LSLG) technique to guide lighting in Stable Diffusionâs latent space."
- Light Conditional Generation (LCG): A module/interface for users to specify light direction, producing a spatial light mask to steer generation. "To simplify this, we introduce Light Conditional Generation (LCG), where users specify light direction via a graphical interface by selecting a point or line indicating the light source."
- Light direction mask: A spatial weighting map encoding the origin and spread of a user-specified light source for guiding latent manipulation. "The Light Conditional Generation module generates the light direction mask according to for manipulating the initial noise in Stable Diffusion."
- Light transport: The physical process of how light propagates and interacts with surfaces; modeled to achieve consistent illumination. "IC-Light~\cite{zhang2025scaling} further introduces a physically motivated light transport mechanism during training."
- Neural Image Assessment (NIMA): A learned metric that predicts aesthetic quality scores for images. "To assess visual realism and aesthetics, we employ Fréchet Inception Distance (FID)~\cite{heusel2017gans} and Neural Image Assessment (NIMA)~\cite{talebi2018nima}."
- Relighting: Post-processing that alters illumination of an existing image, as opposed to guiding lighting during generation. "address lighting control via two-stage workflows that first generate an image and then apply a separate relighting module to modify its illumination."
- Shadow detection model: A model used to detect shadows in images, enabling quantitative evaluation of light direction via shadow orientation. "Within these regions, we apply a shadow detection model~\cite{cong2023sddnet} to analyze shadow directions."
- Stable Diffusion XL (SDXL): A high-resolution latent diffusion variant used here as the base generator for experiments. "We conduct experiments using the Stable Diffusion XL (SDXL)~\cite{podell2023sdxl} to generate images at a resolution of ."
- Two-stage workflow: A pipeline that first generates an image and then applies a separate module (e.g., relighting), increasing complexity and compute. "Recent works~\cite{zhang2025scaling, zeng2024dilightnet} address lighting control via two-stage workflows that first generate an image and then apply a separate relighting module to modify its illumination."
- U-Net: An encoder–decoder CNN with skip connections widely used as the denoiser backbone in diffusion models. "It trains a U-Net model, , to predict noise added to an initial latent, denoted as "
- VAE (Variational Autoencoder): A generative encoder–decoder model that maps images to and from a latent distribution used by latent diffusion. "operating in the latent space of a VAE encoders and decoders ~\cite{kingma2013auto}."
- YOLOv8: A modern object detector used to localize subjects for shadow-direction evaluation. "First, we use YOLOv8~\cite{varghese2024yolov8} to detect the object and expand their bounding boxes by 1.25x to include surrounding areas."
Collections
Sign up for free to add this paper to one or more collections.