Prism: Symbolic Superoptimization of Tensor Programs
Abstract: This paper presents Prism, the first symbolic superoptimizer for tensor programs. The key idea is sGraph, a symbolic, hierarchical representation that compactly encodes large classes of tensor programs by symbolically representing some execution parameters. Prism organizes optimization as a two-level search: it constructs symbolic graphs that represent families of programs, and then instantiates them into concrete implementations. This formulation enables structured pruning of provably suboptimal regions of the search space using symbolic reasoning over operator semantics, algebraic identities, and hardware constraints. We develop techniques for efficient symbolic graph generation, equivalence verification via e-graph rewriting, and parameter instantiation through auto-tuning. Together, these components allow Prism to bridge the rigor of exhaustive search with the scalability required for modern ML workloads. Evaluation on five commonly used LLM workloads shows that Prism achieves up to $2.2\times$ speedup over best superoptimizers and $4.9\times$ over best compiler-based approaches, while reducing end-to-end optimization time by up to $3.4\times$.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “SIGMA: Symbolic Superoptimization of Tensor Programs”
Overview: What is this paper about?
The paper introduces SIGMA, a new tool that automatically makes machine learning programs run faster on GPUs. These programs are built from “tensors” (think of very big, multi‑dimensional tables of numbers) and “operators” (steps like add, multiply, or matrix multiply). Instead of relying on lots of hand‑written rules from experts, SIGMA searches for the fastest way to run a given program—while guaranteeing the result is still correct.
SIGMA’s big idea is to use symbols (like placeholders) to represent many program choices at once. This lets it explore huge numbers of possible implementations quickly and safely, then pick the best one for your computer.
Key questions the paper asks
- How can we search a gigantic space of possible program implementations without trying each one one‑by‑one?
- How can we rule out bad or impossible choices early, before spending time measuring them on hardware?
- How can we be sure that a “faster” version still computes exactly the same answer as the original?
- Can this approach beat strong existing systems on real workloads used in LLMs?
How SIGMA works (in everyday language)
Think of optimizing a program like planning a big group project:
- You have tasks (operators) and materials (tensors).
- You want to split work among many people (GPU threads) to finish fastest.
- There are many ways to divide tasks and people; some are great, some are bad, and some don’t work at all.
SIGMA’s approach has four main parts.
1) Symbolic plans (sGraphs): one plan that stands for many
- Most tools pick exact numbers early (like “use 64 groups” or “split rows here”), then try to optimize from there.
- SIGMA keeps many choices as symbols (like “let the number of groups be ”), so one “symbolic plan” actually represents a whole family of concrete plans.
- This is like sketching a blueprint with blanks to fill later, rather than locking in every measurement too soon.
2) Smart pruning: rule out bad choices early
SIGMA uses two quick checks to throw away non‑starters:
- Symbolic dimension matching:
- Operators like matrix multiply only work when dimensions line up (e.g., the inner sizes must match).
- SIGMA writes these size relationships as simple equations over the symbols and checks them. If they can’t possibly match, that plan is discarded.
- Expression-guided pruning:
- SIGMA asks: “Does this partial plan even compute something that could be part of the final answer?”
- It temporarily sets all parallel split sizes to 1 (a harmless simplification) to make a quick, low‑cost check. If the partial result can’t be part of the final expression under this simplification, it won’t work in general—so it’s pruned.
These steps save time by skipping huge numbers of impossible or useless options.
3) Proving correctness with math rules (e-graphs)
- After pruning, SIGMA needs to make sure a planned optimization still computes exactly the same result as the original.
- It turns the program into a math‑like expression (using rules like “” or properties of sums/products) and uses a data structure called an “e‑graph” to check if two expressions are mathematically equivalent.
- Importantly, this proof works even while some choices are still symbolic—so SIGMA doesn’t have to fix everything before proving correctness.
This is like proving two different algebraic formulas always give the same answer, no matter the specific numbers you plug in.
4) Fill in the blanks and test (auto‑tuning)
- Once a plan is proven correct, SIGMA fills in the remaining symbols (like exact block sizes or loop sizes) by trying several options on the actual GPU and measuring speed.
- This step picks the best concrete values for the specific hardware and input sizes you care about.
What the researchers found and why it matters
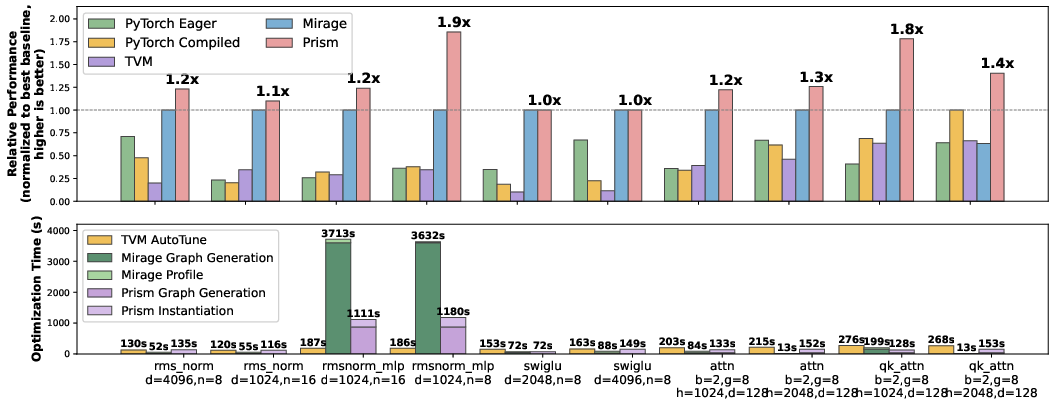
- On five common LLM building blocks (like fused normalization‑linear layers, gated MLPs, and group‑query attention), SIGMA:
- Ran up to 2.2× faster than the best previous superoptimizers.
- Ran up to 4.9× faster than strong compiler‑based systems.
- Finished its entire optimization process up to 3.4× faster (so you get better results sooner).
- SIGMA could find high‑quality implementations that earlier tools missed, because it can safely and efficiently explore a much larger space of possibilities.
Why this matters:
- Faster kernels mean faster training and inference, lower costs, and less energy use—especially important for large models.
- SIGMA reduces the need for months of manual tuning when moving to new GPUs or adding new operators.
Big picture: What could this change?
- Less manual engineering: Developers won’t need to hand‑craft as many rules or re‑tune everything when hardware changes.
- Stable and dependable: SIGMA’s pruning is “safe”—it doesn’t throw away the best solution—and its correctness proofs keep answers trustworthy.
- Scales with modern AI: By grouping many choices into one symbolic plan, SIGMA can handle the complexity of today’s large models.
- Future directions: This symbolic approach could be combined with learning‑based methods (like LLMs that suggest ideas) to guide the search even more intelligently.
In short, SIGMA shows a practical way to blend math proofs and smart search to make ML programs on GPUs both fast and reliable—without expecting humans to guess all the best tricks by hand.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces a promising symbolic superoptimization framework, but several aspects remain underspecified or unexplored. The following concrete gaps can guide future work:
- Single loop-dimension assumption: The framework assumes . Extending sGraphs, constraints, and axioms to multiple nested loop/reduction dimensions (e.g., multi-axis tiling and multi-stage reductions) is left open.
- Divisibility and remainder handling: Shape formulas use , but the paper does not state constraints ensuring integrality (e.g., ) or how to handle non-divisible tiles (padding, remainder kernels). Formalizing and verifying param-guarded correctness conditions is needed.
- “Correct for all ” requirement: Requiring mappings to be correct for all parallelization parameters may rule out correct implementations that need guarded constraints (e.g., divisibility, capacity limits). Support for parameter-conditional correctness (e.g., via SMT with guards) is unaddressed.
- Operator and axiom coverage: The set of algebraic axioms enabling e-graph equivalence is not fully specified. It is unclear how broadly the approach covers convolutions, batched/broadcasted ops, complex reductions, non-elementwise nonlinearities, and attention variants.
- Floating-point semantics and soundness: Equivalence rules appear mathematical (real-valued), but GPUs use finite-precision arithmetic (e.g., TF32, BF16) where associativity/distributivity do not strictly hold. The paper does not state whether axioms are sound for floating-point or how to bound numerical error when applying rewrites.
- Numerically stable variants: Transformations for stability (e.g., max-subtraction in Softmax, Kahan/online reductions, streaming softmax as in FlashAttention) are not discussed. How to axiomatize and verify such algorithmic changes remains open.
- Parallelization operators and rewrite rules: The expression language (e.g., , , ) is only partially described. Formal semantics and the full set of rewrite rules needed for equivalence checking are not fully presented.
- Scalability of e-graph verification: E-graph reasoning can suffer e-class explosion. The paper does not analyze verifier complexity, pruning heuristics, or completeness guarantees (risk of false negatives) at larger graph sizes.
- Hardware-constraint modeling: While “hardware constraints” are cited for pruning, explicit symbolic models for registers, shared memory, occupancy, warp-level constraints, bank conflicts, memory coalescing, and tensor-core eligibility are not specified.
- Memory/layout transformations: The representation focuses on partition/replication but does not address layout choices (e.g., NHWC vs NCHW), transposes, vectorization widths, alignment, and stride/packing transformations that heavily affect performance and correctness.
- Auto-tuning strategy: Parameter instantiation relies on random sampling with profiling. There is no learned or analytical cost model, nor use of Bayesian or bandit methods to reduce sample complexity, nor transfer of tuning results across shapes/devices.
- Search completeness: The paper does not characterize the completeness of the sGraph space (i.e., which families of programs/schedules it can represent) relative to known optimal or near-optimal transformations, or how pruning may exclude valid-but-hard-to-prove candidates.
- Mapping instantiation scalability: Enumerating concrete mappings (even with symmetry breaking) can remain combinatorial as and tensor-rank increase. Solver-based enumeration (ILP/SMT) or constraint-guided generation is not explored.
- Expression-guided pruning at : The under-pruning heuristic may retain many infeasible candidates and misses symbolic contradictions that only appear for realistic . Stronger yet cheap symbolic pruning (e.g., interval/SMT checks) is an open direction.
- Dynamic shapes and broadcasting: Examples use fixed sizes (e.g., [4096, …]). Support for symbolic tensor extents, broadcasting semantics, and runtime-dynamic shapes (with associated guards) is not described.
- In-place updates, atomics, and non-commutative ops: Correctness and verification for operations requiring atomics, reductions with non-commutative/ordered semantics, or in-place mutations are not addressed.
- Thread-/warp-level micro-optimizations: Decisions like unrolling, vector widths, warp shuffles, asynchronous copies, MMA/tensor-core tiling, and register allocation are not modeled symbolically; integrating these into sGraphs and axioms is open.
- Inter-kernel/global scheduling: The approach focuses on kernel/block/thread hierarchies within a fused region. Global optimization across kernels (e.g., stream scheduling, overlap of compute/memory, cross-kernel memory reuse) is not covered.
- Multi-GPU/distributed settings: Extensions to pipeline/tensor parallelism, collective communication, and cross-device partitioning with correctness and performance guarantees are not discussed.
- Precision/quantization and approximate equivalence: Support for mixed precision, quantization (int8), and approximate transformations with error bounds is not described; axioms to reason about such transformations are missing.
- Portability and retuning cost: Correct mappings are hardware-agnostic by construction, but parameter tuning is device-specific. Strategies for transfer learning across GPUs or amortizing tuning cost are not explored.
- Integration with libraries and compilers: How SIGMA composes with vendor libraries (cuBLAS/cuDNN) and existing compiler passes (e.g., when to call into libraries vs synthesize kernels) is left unspecified.
- Benchmark breadth and scale: Evaluation is on five LLM-related workloads; it is unclear how the approach generalizes to full end-to-end models, larger graphs, or diverse domains (CV, speech), and how compile time scales there.
- Formal guarantees: The claim that pruning is sound (does not eliminate optimal solutions) hinges on axiom sets and pruning logic. A formal statement and proof of conditions under which this guarantee holds are not provided.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the paper’s methods (sGraphs, symbolic pruning, e-graph verification, and parameter auto-tuning) today.
- Optimizer pass for mainstream ML compilers (software; AI/ML)
- What: Integrate SIGMA as a pass in TVM, TensorRT, PyTorch Inductor, OpenXLA, or Triton to synthesize and verify fused kernels (e.g., LayerNorm+Linear, Gated MLPs, Group-Query Attention), reducing latency and cost for LLM inference/training.
- Potential tools/workflows: “SIGMA Pass” with e-graph-backed equivalence check, symbolic mapping generator, auto-tuner for grid/block/loop parameters; per-model, per-hardware caching of best instantiations.
- Assumptions/dependencies: Operator axioms and rewrite rules exist for target ops; GPU backend supported (initially NVIDIA); numerical tolerance policies (floating-point associativity); integration effort into compiler IR.
- Rapid kernel porting for chip vendors and platform teams (semiconductors; cloud)
- What: Use symbolic superoptimization to re-synthesize high-performance kernels (e.g., FlashAttention-style) on new GPU generations or micro-architectures, compressing months of manual tuning to days.
- Potential tools/workflows: Internal “kernel foundry” pipeline that feeds operator semantics + hardware constraints into SIGMA; regression/perf dashboards; artifact caching across SKUs.
- Assumptions/dependencies: Detailed hardware constraints (shared memory, warp size, instruction availability) expressed as symbolic constraints; robust cost/profiling harness.
- Per-deployment model-serving optimization (cloud SaaS; finance; e-commerce)
- What: SIGMA-as-a-service that auto-optimizes model subgraphs at deployment time for a specific instance type (A100/H100/L4), improving throughput/latency (reported up to 2.2× vs best superoptimizers; 4.9× vs compilers).
- Potential tools/workflows: AOT compile step in CI/CD; canary profiling; caching of tuned sGraph instantiations per hardware/shape; rollback if performance regresses.
- Assumptions/dependencies: Sufficient warmup/profiling budget; stable runtime shapes; compatibility with serving stack (TensorRT-LLM, vLLM, Triton Inference Server).
- Edge and embedded acceleration (mobile/robotics/automotive)
- What: Apply sGraph-based fusion and scheduling to on-device LLM/VLM/vision workloads to reduce DRAM traffic and kernel launches, improving real-time responsiveness and battery life.
- Potential tools/workflows: Integration with TFLite/NNAPI, Core ML, or ONNX Runtime EPs; hardware-specific axiom sets (e.g., ROCm, Metal) as they become available.
- Assumptions/dependencies: Backend coverage beyond CUDA; tight memory constraints modeled symbolically; limited tuning time on device.
- MLOps performance regression guardrails (software; DevOps)
- What: Add a performance gate in CI that attempts sGraph re-synthesis on changed subgraphs; fails builds if performance degrades or if equivalence checks fail.
- Potential tools/workflows: GitHub Actions plugin invoking SIGMA on hot paths; e-graph proof artifacts stored for auditing; perf baselines per model/version.
- Assumptions/dependencies: Deterministic profiling harness; reproducible inputs/shapes; timeboxed optimization.
- Formal verification layer for kernel transformations (healthcare; finance; safety-critical)
- What: Use e-graph proofs to assert equivalence across parameter ranges, reducing risk of silent correctness regressions in hand-optimized kernels.
- Potential tools/workflows: “Proof-carrying kernels” attached to binaries; static analyzers validating axioms/assumptions.
- Assumptions/dependencies: Soundness of axioms; explicit handling of floating-point non-associativity and datatype-specific semantics (FP16/BF16/INT8).
- Academic research and teaching baseline (academia)
- What: Use SIGMA to study superoptimization at multiple hierarchy levels, e-graph rewriting, and algebraic scheduling; reproduce speedups on LLM kernels.
- Potential tools/workflows: Open datasets of verified equivalences; teaching notebooks that visualize search/pruning and e-graph saturation.
- Assumptions/dependencies: Open-source code and benchmarks; documentation of operator semantics/axioms.
- Energy and cost reporting for sustainability programs (policy; enterprise IT/energy)
- What: Convert 2×–5× speedups into power and carbon savings for sustainability dashboards and procurement KPIs.
- Potential tools/workflows: Integrate runtime–to–energy models or power meters; automated “green delta” reporting per model release.
- Assumptions/dependencies: Access to reliable power telemetry; stable measurement protocols; acceptance of performance–to–energy attribution methods.
- Custom operator synthesis for novel architectures (startups; AI labs)
- What: Quickly design and validate new fused operators (e.g., MoE gating, RoPE + matmul fusions) with guaranteed equivalence and tuned schedules.
- Potential tools/workflows: “Kernel studio” where researchers declare math and constraints, get verified code; catalog of reusable sGraphs.
- Assumptions/dependencies: Extension of axiom set to new ops; high-quality profiling on target hardware.
Long-Term Applications
These use cases are enabled by the paper’s innovations but require additional research, broader hardware coverage, or ecosystem alignment.
- Cross-accelerator and NPU backends (hardware vendors; cloud)
- What: Generalize sGraph semantics and axioms to AMD ROCm, Intel GPUs, Apple Metal, NPUs (Core ML, Hexagon), and TPUs; unify multi-backend superoptimization.
- Potential tools/workflows: Backend adapters translating device memory models and parallel hierarchies; per-device cost models.
- Assumptions/dependencies: Mature toolchains and profiling; formalization of device-specific semantics (tiling, vector units, async copies).
- Distributed/multi-GPU symbolic optimization (HPC; hyperscale AI)
- What: Extend sGraphs to include collectives (all-reduce, all-to-all), pipeline/tensor parallelism, and memory sharding; jointly optimize compute–communication.
- Potential tools/workflows: Communication-aware pruning using topology; axioms for collective algebra; end-to-end auto-tuning of micro-batches and chunk sizes.
- Assumptions/dependencies: Accurate network and overlap models; correctness axioms for collectives; scalable verification.
- Hardware–software co-design loops (semiconductor; EDA)
- What: Use symbolic search to explore Pareto-optimal mappings under hypothetical hardware parameters (SMEM size, warp width), guiding architecture decisions.
- Potential tools/workflows: Co-simulation where SIGMA provides optimal kernels for candidate hardware; constraint-solving feedback to RTL design.
- Assumptions/dependencies: Trustworthy cost models bridging micro-architecture and kernel performance; vendor NDAs and design flows.
- Runtime-adaptive optimization (mobile; cloud)
- What: Online re-instantiation of symbolic parameters to adapt to thermal throttling, contention, or changing sequence lengths; hot-swappable kernels.
- Potential tools/workflows: Low-overhead telemetry; policy engine selecting sGraph variants; safe JIT/AOT fusion.
- Assumptions/dependencies: Low-latency profiling; stability safeguards; safe fallbacks; JIT permissions in production.
- Standardization of operator axioms and equivalence registries (policy; standards)
- What: Establish open registries of math identities and parallelization axioms used across compilers; conformance suites and certification of “verified kernels.”
- Potential tools/workflows: Public e-graph axiom libraries; interop tests; governance by ML/standards bodies.
- Assumptions/dependencies: Community consensus; IP/licensing clarity; regulator engagement.
- Certified compilers for safety-critical domains (healthcare; automotive; aerospace)
- What: Build compiler pipelines where every transformation is backed by machine-checkable equivalence proofs, enabling regulatory approval.
- Potential tools/workflows: Proof-carrying code artifacts; audit trails; domain-specific numeric stability policies.
- Assumptions/dependencies: Formal treatment of floating-point; updated certification standards; performance–proof tradeoff management.
- Low-code performance engineering and IDE integration (software; devtools)
- What: Developers specify high-level tensor intent; IDE generates verified, tuned kernels; LLM assistants guided by symbolic constraints and proofs.
- Potential tools/workflows: VS Code extensions; “explain my optimization” visualizers; LLM-in-the-loop candidate synthesis filtered by sGraph feasibility.
- Assumptions/dependencies: Reliable LLM tooling with guardrails; ergonomic visualization of symbolic mappings and e-graph proofs.
- Curriculum and interactive learning platforms (education)
- What: Interactive sandboxes for students to explore algebraic rewrites, parallel mappings, and performance trade-offs with correctness guarantees.
- Potential tools/workflows: Web-based e-graph explorers; side-by-side cost/proof views; challenges that mirror real LLM kernels.
- Assumptions/dependencies: Well-scoped UI abstractions; curated workloads and axioms.
- Green-AI procurement and incentives (policy; enterprise)
- What: Policies requiring verifiable optimization steps (like SIGMA) to qualify for funding or procurement; incentives tied to demonstrable energy reductions.
- Potential tools/workflows: RFP templates; third-party verification of optimization artifacts; standardized reporting.
- Assumptions/dependencies: Accepted benchmarks and auditing processes; clear privacy/IP boundaries for sharing artifacts.
Cross-cutting assumptions and dependencies
- Operator coverage and axioms: Feasibility hinges on well-specified algebraic identities and parallelization axioms for target ops (including numerics and datatypes).
- Hardware constraints modeling: Shared memory, register pressure, occupancy, and memory bandwidth need to be expressible as symbolic constraints or reflected in tuning.
- Numerical correctness: Floating-point non-associativity and mixed-precision behavior must be addressed via tolerated equivalence or refined axioms.
- Shapes and dynamics: Current assumption of a single for-loop dimension may need extension; dynamic shapes require either symbolic bounds or specialization.
- Integration cost: Realizing benefits requires integration into existing compiler IRs, profiling harnesses, and deployment pipelines.
- Tuning budget vs. SLOs: Auto-tuning time must fit within CI/CD or deployment constraints; caching and transfer learning can mitigate costs.
Glossary
- accumulator operators: Special operators that collect and combine intermediate results, typically along reduction axes. "as reductions along loop dimensions are handled explicitly by accumulator operators."
- abstract expression checking: A method for validating candidate programs by comparing abstracted computation expressions rather than concrete executions. "symbolic expression pruning extends the abstract expression checking from previous work~\cite{mirage} to the symbolic setting."
- algebraic axioms: Formal mathematical rules describing operator properties used to prove program equivalence. "under a set of algebraic axioms."
- auto-tuning: Empirical search over parameter configurations to find high-performance implementations. "parameter instantiation through auto-tuning."
- block graph: The thread-block-level subgraph in a hierarchical program representation. "a block graph (short for thread-block graph) that defines its computation at the block level,"
- coefficient matching: A technique that equates coefficients of symbolic parameters to derive equality constraints between mappings. "coefficient matching is effective."
- contracting dimensions: The dimensions multiplied and summed over in operations like matrix multiplication. "a matrix multiplication requires matching contracting dimensions."
- directed acyclic graph (DAG): A graph with directed edges and no cycles, commonly used to represent computation dependencies. "typically represented as directed acyclic graphs (DAGs)"
- e-graph rewriting: Transforming and saturating equivalence classes of expressions using rewrite rules within an e-graph structure. "equivalence verification via e-graph rewriting,"
- e-graphs: Data structures that compactly represent many equivalent expressions to enable efficient equivalence checking. "and performs equivalence checking using e-graphs~\cite{egg}"
- equivalence axioms: Formal rules defining when two expressions are considered semantically equivalent. "We define a set of equivalence axioms (Table~\ref{tab:rewriting_rules})"
- equivalence checking: Verifying that two program representations compute the same function. "and use e-graphs~\cite{egg} to check whether two expressions are equivalent under these axioms."
- expression-guided pruning: Early elimination of candidate graphs by checking whether current expressions can lead to the target output. "dimension matching and expression-guided pruning eliminate invalid branches."
- for-loop dimension: A symbolic or concrete loop extent that controls iteration over data or reductions within a block/thread. "for-loop dimensions (e.g., )"
- grid dimensions: Parameters specifying how many thread blocks are launched along each axis of the GPU grid. "grid dimensions (e.g., )"
- group-query attention: An attention variant used in modern LLMs that groups queries for efficiency. "and group-query attention."
- imap: The input mapping that partitions or replicates input tensor dimensions across parallelization axes. "how input tensors are partitioned via imap"
- lexicographically smallest assignment: A canonical representative chosen among equivalent mappings to avoid redundant verification. "SIGMA retains only the lexicographically smallest assignment within each equivalence class,"
- mapping instantiation: Enumerating concrete assignments for symbolic mapping variables that satisfy constraints. "Mapping Instantiation (\S\ref{sec:search:instantiation}): enumerates candidate concrete mapping assignments satisfying all constraints."
- μGraph: A hierarchical representation of tensor programs spanning kernel, block, and thread levels. "Mirage~\cite{mirage} introduces the Graph representation for tensor programs,"
- omap: The output mapping that reassembles per-parallel unit results into the final tensor layout. "how output tensors are assembled via omap"
- operator fusion: Combining multiple operations into a single kernel to reduce memory traffic and overhead. "operator fusion heuristics"
- operator semantics: The mathematical meaning and behavior of operators used for symbolic reasoning and equivalence. "over operator semantics, algebraic identities, and hardware constraints."
- parallelization dimensions: The axes (grid, block, or loop) along which computation and data are partitioned. "We collectively refer to these as parallelization dimensions."
- parallelization parameters: The symbolic or concrete sizes of parallelization dimensions that determine execution granularity. "the parallelization parameters can be tuned for performance without re-validating equivalence."
- SPMD: Single-program-multiple-data, a parallel model where the same program runs across many threads on different data. "following the single-program-multiple-data (SPMD) paradigm."
- streaming multiprocessor: A GPU hardware unit on which thread blocks are scheduled and executed. "with each block scheduled onto a streaming multiprocessor"
- superoptimization: Searching over many program variants to find the fastest one that preserves correctness. "Superoptimization has emerged as a promising paradigm for automatically discovering fast tensor programs"
- symbolic dimension matching: Enforcing equality of symbolic shape expressions to ensure operator dimension compatibility. "Symbolic dimension matching ensures compatibility of operator dimensions"
- symbolic graph (sGraph): A hierarchical program representation with symbolic mappings and dimensions that encodes families of tensor programs. "SIGMA uses sGraph to compactly encode large classes of tensor programs"
- symbolic shape matching: Verifying that symbolic tensor shapes align for operations like matmul without fixing parameter values. "performs symbolic shape matching to determine whether an operator can be validly added."
- symmetry breaking: Eliminating equivalent candidates by imposing canonical ordering to reduce redundant search. "Symmetry breaking."
- tensor programs: Computations expressed as graphs of tensor operators and tensors, optimized for ML workloads. "the first symbolic superoptimizer for tensor programs."
- thread graph: The per-thread-level subgraph in a hierarchical representation. "and block-level operators may further expand into thread graphs."
- thread-block graph: The intermediate hierarchical level describing computation within a CUDA thread block. "block graph (short for thread-block graph)"
Collections
Sign up for free to add this paper to one or more collections.

