- The paper introduces CoopEval, the first comprehensive benchmark suite that evaluates game-theoretic mechanisms—repetition, reputation, mediation, and contracting—to sustain cooperation among LLM agents.
- Empirical results show that mediation and contracting consistently yield higher cooperation and welfare, validated by metrics such as mean payoff, fitness, and deviation rating.
- The study demonstrates that explicit incentive design is critical for overcoming LLMs' natural defection tendencies, emphasizing the need for structured mechanisms in multiagent scenarios.
Benchmarking LLM Cooperation Mechanisms in Social Dilemmas: An In-Depth Analysis of CoopEval
Introduction and Motivation
Cooperative behavior among agents with divergent incentives is a foundational challenge in both theoretical and practical multiagent systems. With the deployment of LLM agents in critical decision-making domains, there is a rapidly growing imperative to understand, benchmark, and design mechanisms that enable robust cooperation, particularly in the context of mixed-motive social dilemmas such as the Prisoner’s Dilemma, Public Goods, Trust Game, and Traveler’s Dilemma. While prior research has demonstrated that LLMs typically default to defection in single-shot dilemmas—even as reasoning and capability increase—there remains a gap in systematic, comparative benchmarks that evaluate concrete game-theoretic mechanisms for fostering cooperation across diverse LLM agents.
The "CoopEval" framework directly addresses this by introducing the first comprehensive benchmark suite that evaluates multiple, theoretically grounded cooperation mechanisms applied to LLM societies interacting in a range of canonical social dilemmas (2604.15267). The framework both extends evaluative coverage novelly to mechanisms such as mediation and contracting, and enables cross-play among heterogeneous LLMs under uniform experimental scaffolding.
Mechanism Design and Theoretical Guarantees
The core mechanisms evaluated are (1) repetition, (2) reputation, (3) third-party mediation, and (4) contracting, each concretely motivated by extensive game-theoretic literature. Their incentives and information structures are depicted schematically:
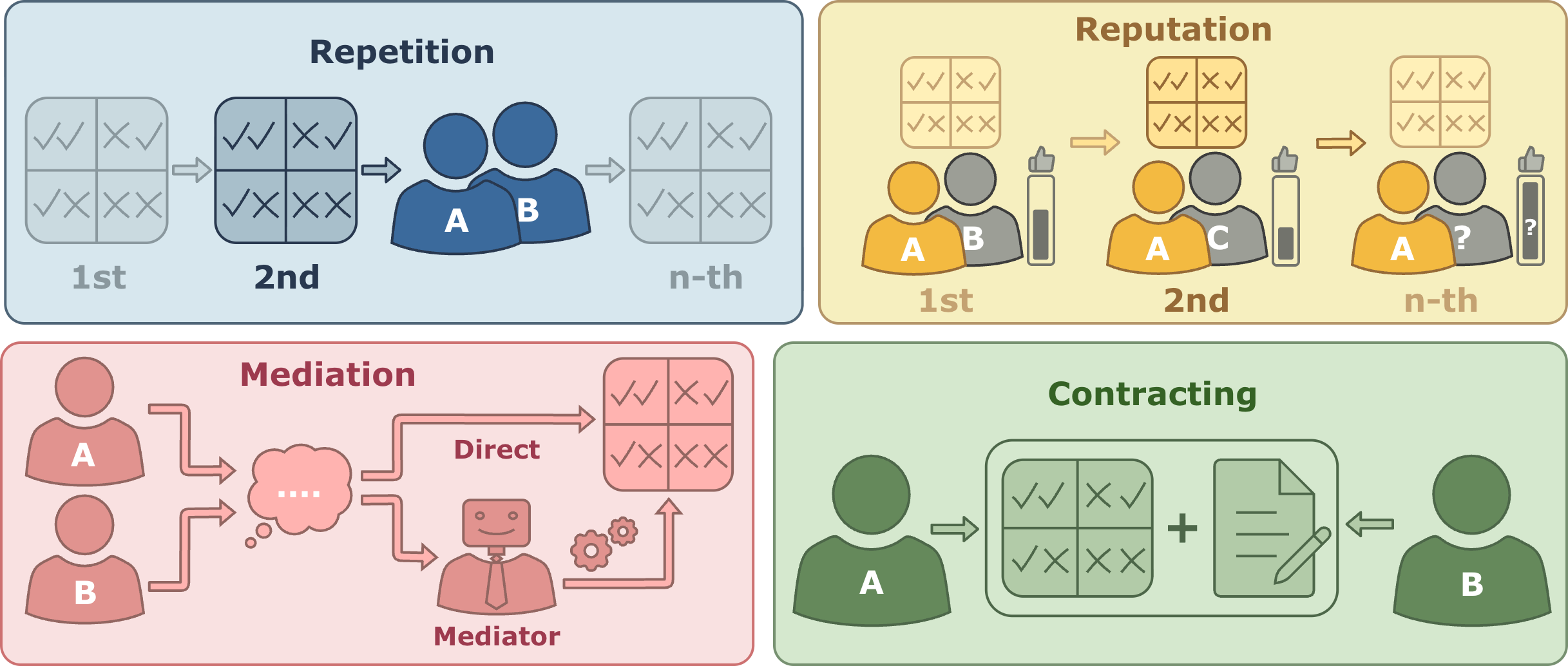
Figure 1: The four mechanisms evaluated—repetition (iterated play with memory), reputation (rematching with observed histories), mediation (delegation to third-party), and contracting (conditional utility transfers).
The authors present a unified theorem of cooperation, proving that for any normal-form game with a Nash equilibrium that is Pareto-dominated by a more cooperative outcome, each mechanism (under suitable parameters) allows rational, equilibrium-seeking agents to achieve the cooperative outcome in subgame perfect equilibrium. This result formalizes the theoretical sufficiency of these mechanisms for sustaining mutual cooperation and underpins the benchmarking focus: in principle, every mechanism enables rational LLM agents to escape the defective equilibria endemic to social dilemmas.
Experimental Setup
CoopEval benchmarks six frontier and widely-used LLMs (Claude 4.5 Sonnet, GPT-5.2, Gemini 3 Flash—both base and with reasoning, GPT-4o, and Qwen-30B), assessing both cross-play and population-level cooperation via three complementary performance metrics:
- Mean: cross-play average payoff, emulating diverse agent populations.
- Fitness: equilibrium outcomes post-replicator dynamics, modeling competitive adaptation.
- Deviation rating (DR): modern, clone-invariant agent ranking for general-sum settings.
Crucially, LLMs are prompted to maximize their own utility and are evaluated using both direct action choice and chain-of-thought (CoT) rationales, with systematic justification annotation via a powerful LLM-as-judge analysis.
Main Empirical Findings
Baseline (No Mechanism)
All contemporary LLMs, regardless of reasoning ability or size, default to defection in single-shot dilemmas, corroborating but also amplifying previous findings that increased LLM rationality and chain-of-thought prompting, counterintuitively, often reduce prosociality without explicit incentives. Chain-of-thought traces reveal a near-ubiquitous focus on self-interested utility maximization and equilibrium play, with little reference to trust, social welfare, or prosocial considerations, except among minority legacy models (e.g., GPT-4o occasionally cooperates).
Mechanism Effectiveness Across Social Dilemmas
When cooperation-sustaining mechanisms are introduced, pronounced heterogeneity in effectiveness emerges despite theoretical equivalence. Aggregated quantitative results show:
- Repetition (direct reciprocity): Increases welfare but only achieves moderate cooperative rates overall. Its efficacy collapses when agents are rematched (i.e., population mixing).
- Reputation (indirect reciprocity): Consistently less effective than repetition for LLMs, in contrast to some human behavioral studies. Increased history granularity or higher-order information (Reputation+) did not yield better cooperation—indeed, simpler first-order reputation performed better.
- Mediation: Robustly achieves high cooperation and welfare when agents can correctly design and delegate to strong mediators via decentralized proposal and voting. High game-theoretic stability observed, particularly in simpler dilemmas.
- Contracting: Most effective in achieving socially optimal outcomes (average collective welfare >80% of the optimum in aggregate), with contracting often producing dominant-strategy implementability.
Certain LLMs, notably Gemini 3, outperform others by more effectively proposing and adopting strong mediators/contracts, as measured by both mean and fitness metrics.
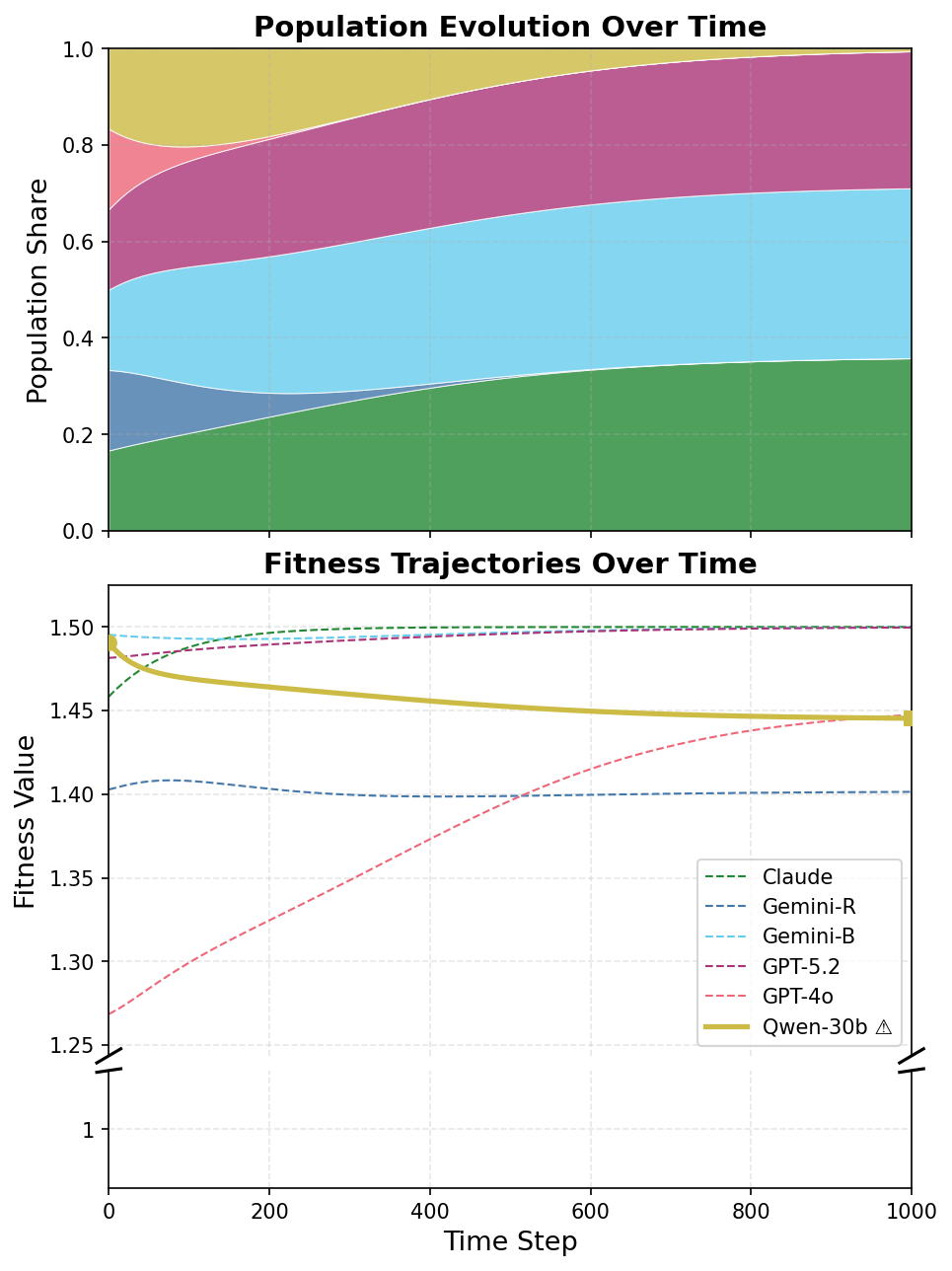
Figure 2: Replicator dynamics on Public Goods under contracting—Gemini-R, GPT-4o, and Qwen-30B are outcompeted by agents negotiating stronger contracts; fitness values degrade for defective strategies under selection.
Evolutionary Dynamics
Applying replicator dynamics, simulating agent population adaptation, reveals that defective strategies (and exploitative LLMs) are rapidly purged, further increasing cooperative rates under mechanisms that make cooperation evolutionarily robust. This is especially striking under mediation and contracting, where evolved populations approach or saturate full cooperation.
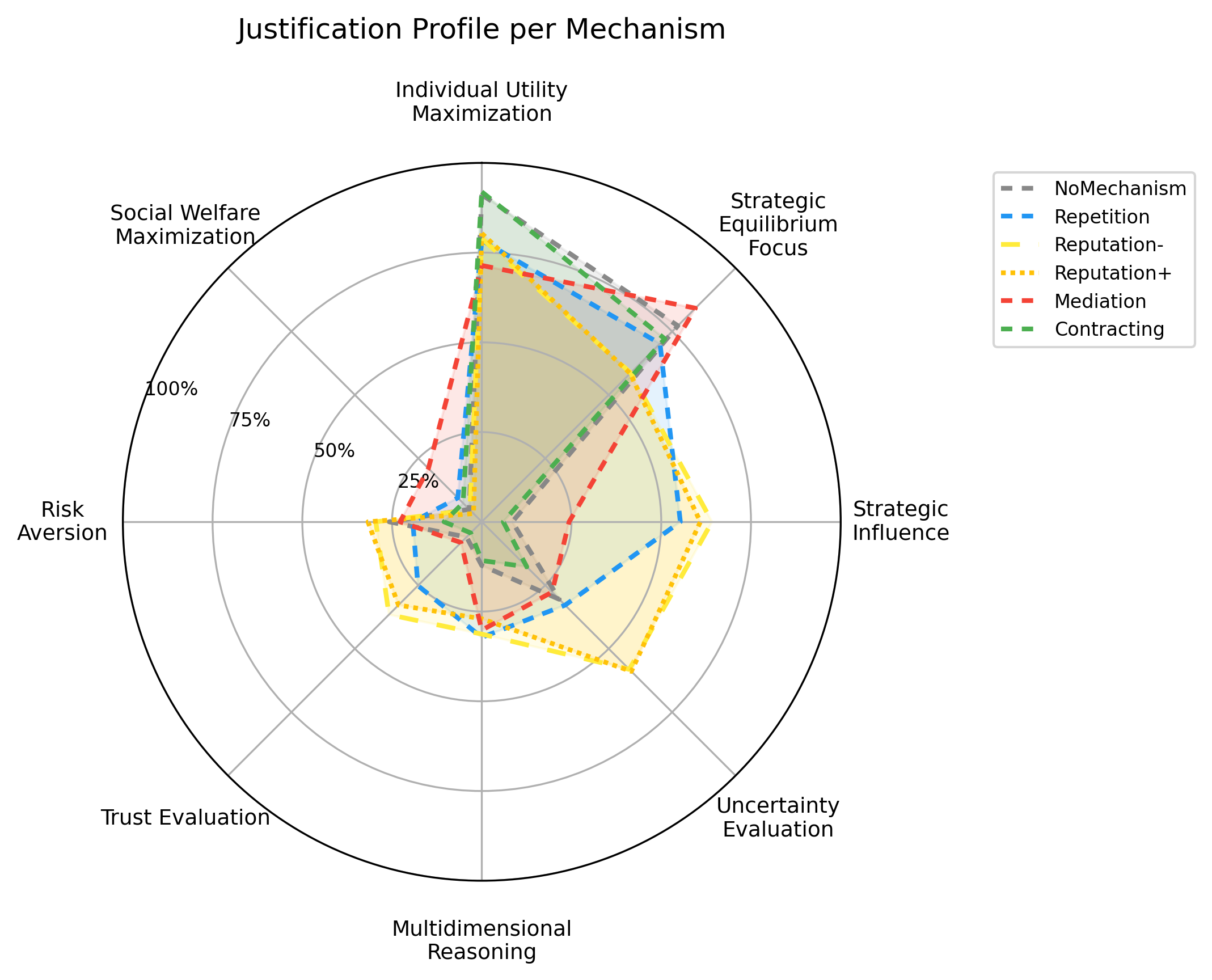
Figure 3: Prevalence of key justification categories in LLM decision rationales, with individual utility maximization and strategic equilibrium dominance—particularly under mediation and contract.
Agent and Game-Level Dissection
Detailed analysis exposes clear stratification among LLM capabilities, with certain models (Gemini 3, Claude, GPT-5.2) exhibiting nuanced, context-conditional reasoning about strategic influence and equilibrium selection. In contrast, models such as GPT-4o display stochastic or uncertainty-centered justifications, and Qwen-30B underperforms across mechanisms and games.
Notably, performance is strongly game-dependent (e.g., high in Prisoner’s Dilemma, lower in Traveler’s Dilemma/Public Goods, where multi-player reasoning is required and first-round cooperation is rare).
Justification Analysis
Across mechanisms, decision rationales are overwhelming governed by self-interested maximization and Nash equilibrium logic—social welfare, reciprocity, or norm-conformity are exceedingly rare, and only surface under explicit mechanism structure.
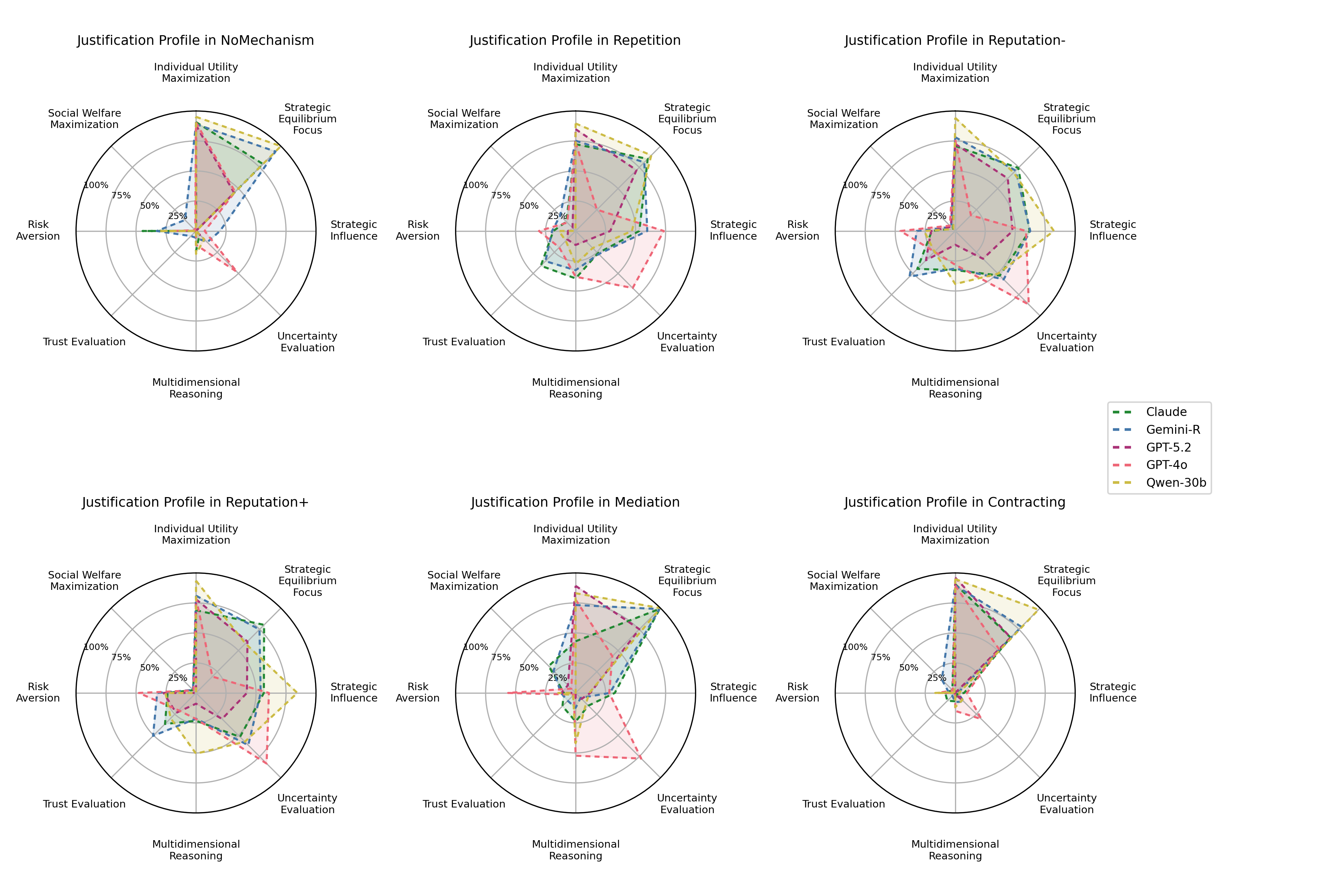
Figure 4: Mechanism-wise distribution of decision justifications—mechanisms that align individual utility with collective welfare see predominant references to equilibrium reasoning.
Mechanism Design Process: Proposal, Voting, and Adoption
Mediator and contract mechanisms were implemented as two-stage processes: LLMs first propose a design, then vote via approval balloting, with adoption conditional on approval and universal agent acceptance. Surprisingly, a single competent proposal sufficed in most social dilemmas for stable cooperation, although some models (notably Qwen-30B, GPT-4o) struggled to recognize or accept optimal designs, limiting mechanism payout until evolutionary dynamics refined the population.
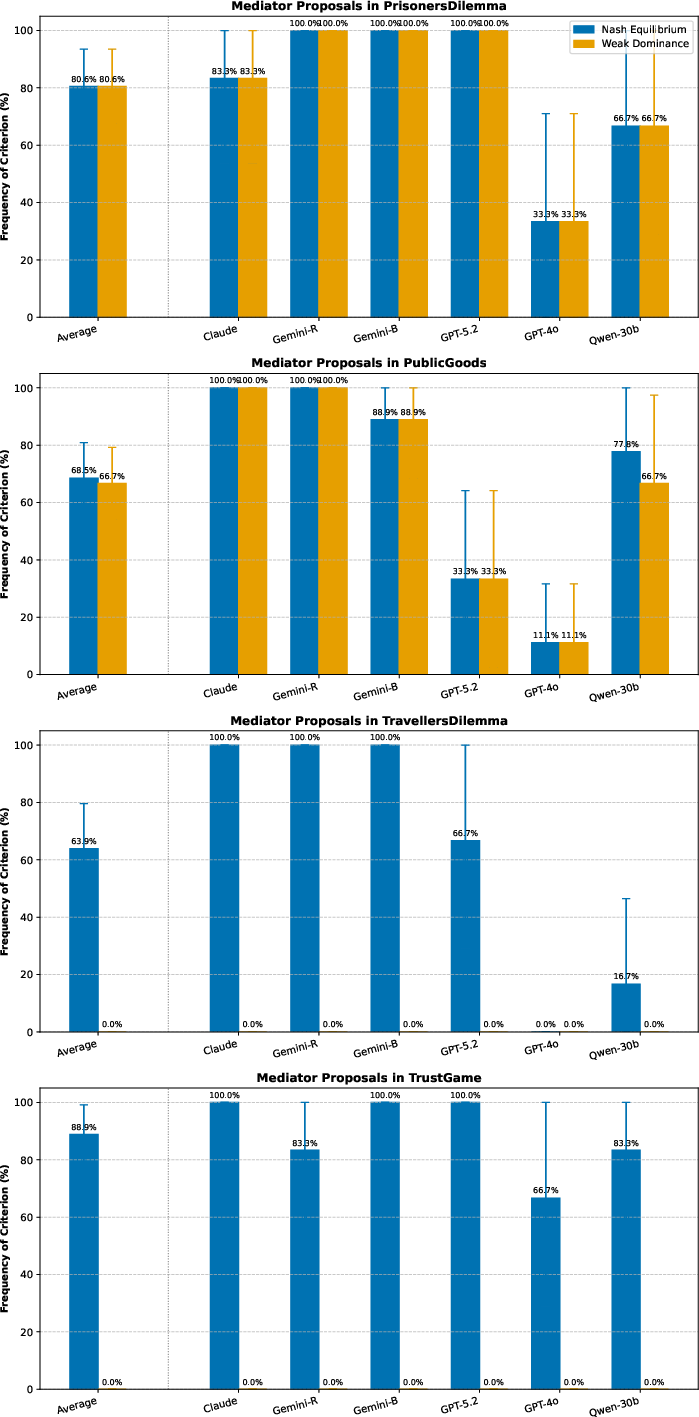
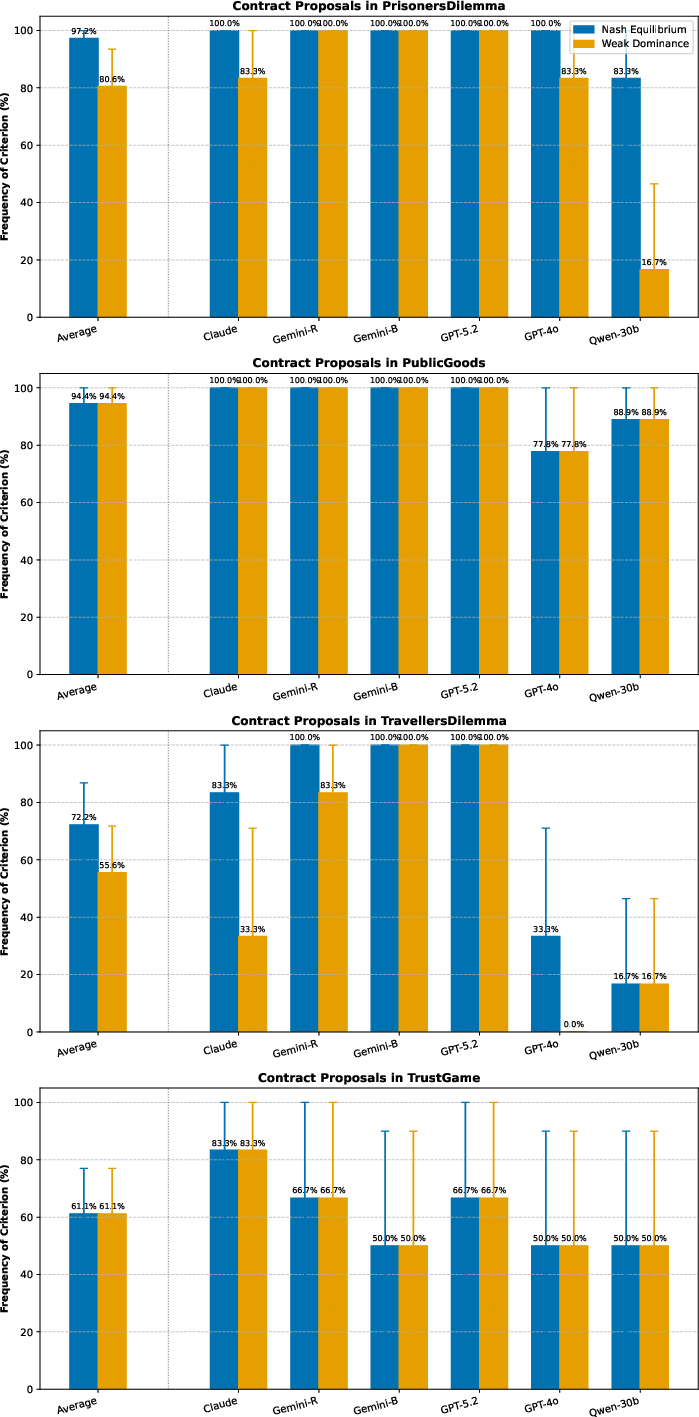
Figure 5: Stability rates of cooperative outcome under LLM-proposed mediators/contracts by game class—most proposals in mediation/contracting settings yield Nash/stable equilibrium in simplified dilemmas.
Implications and Future Directions
Practical Implications
The findings have direct implications for AI alignment, agent protocol design, and decentralized LLM agent deployment. The results indicate that:
- Robust cooperation among LLM agents cannot be expected to emerge “naturally” from scale or reasoning improvements; explicit incentive design remains essential.
- Contracting and mediation, though more centralized/mechanism-dependent, consistently achieve higher welfare in LLM populations, validating their adoption in agent-mediated markets, governance, and consensus protocols.
- Fine-grained analysis and evolutionary benchmarks, as instantiated in CoopEval, are crucial for ranking agents’ capability for robust, rational collective action.
Theoretical and Research Implications
The experimental divergence from theoretical guarantees—especially the underperformance of indirect reciprocity/reputation relative to repetition—highlights limits in current LLMs’ capacity for conditional reasoning over complex histories and norm emergence. This points to future research in:
- Improving LLM social reasoning via architecture design or meta-training, especially for mixed-motive, large-population scenarios.
- Extending benchmarks to sequential, open-ended tasks, or mechanisms such as gifting, open-source program equilibrium, and preplay negotiation.
- Exploring minimum-sufficiency mechanisms and their robustness in adversarial or misaligned settings, including collusion and emergent subgroup coordination.
Conclusion
CoopEval marks a substantial advance in systematic, mechanism-grounded benchmarking of cooperative behavior in LLM multiagent systems. By demonstrating both the necessity and variability of mechanism effectiveness in realizing robust cooperation—and revealing the critical role of explicit institutional structure even among highly capable, rational agents—this work provides a foundational empirical and theoretical resource for designers and evaluators of future sociotechnical AI ecosystems.

