- The paper demonstrates that multi-round, fairness-sensitive prompts drive LLM agents beyond classical Nash play towards cooperative, Pareto-optimal outcomes.
- It introduces a generalized payoff parameterization and dynamical system to model the endogenous adjustment of social and stability parameters.
- Empirical chain-of-thought analysis reveals that mutual trust, punishment, and forgiveness mechanisms enable robust cooperation in resource allocation and Cournot games.
Competition and Cooperation of LLM Agents in Games: A Technical Synthesis
Overview
This work provides a rigorous study of the emergent behavioral regimes of LLM agents in strategic multi-agent games, specifically network resource allocation via the Kelly mechanism and linear Cournot competition. The analysis directly focuses on how LLM agents, when prompted with multi-round and non-zero-sum objectives, depart from classical Nash rationality and internalize social welfare and fairness-based heuristics, resulting in consistent convergence to cooperative equilibria. The authors introduce a generalized payoff parameterization and a corresponding dynamical system which models the endogenous adjustment of agents’ social and stability parameters across repeated play. The synthesis combines experimental manipulations with chain-of-thought (CoT) trace analysis, enabling extraction of implicit agent reasoning and theoretical underpinnings of the empirical findings.
Games, Rationality, and Baselines
The experimental setting centers on two canonical environments: a proportional resource allocation (Kelly) game and a linear Cournot production game. Both scenarios are well-characterized in economic theory: selfish, best-response strategies in these games (i.e., Nash play) are provably inefficient, with Nash outcomes nested deep inside the feasible payoff polytope and bounded away from the Pareto frontier. In resource allocation, Nash convergence yields a worst-case efficiency loss of 25% [Johari & Tsitsiklis, 2004], and Cournot competition, particularly for large N, is associated with significant aggregate surplus dissipation.
When initialized with myopic, one-shot prompts, LLM agents reproducibly converge to the classical Nash solution after minor explorations. However, the operational regime shifts markedly when agents receive instructions to maximize cumulative utility across repeated rounds, or when subtle collaboration signals are embedded in the prompt.
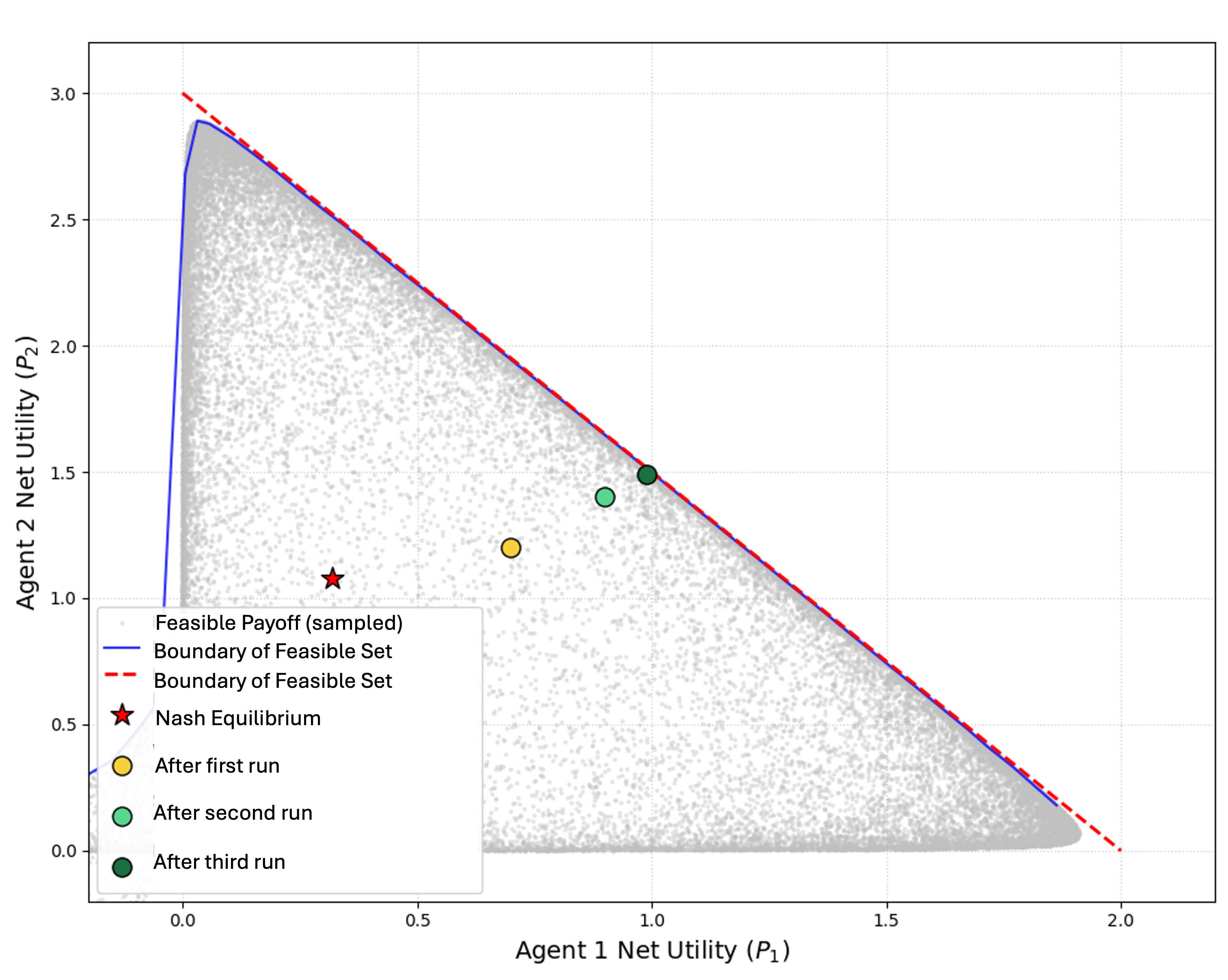
Figure 1: The feasible payoff space for two agents in resource allocation, with Nash equilibrium inside the inefficient core and agent trajectories converging to the Pareto frontier as collaboration emerges.
Emergent Cooperation via Social Reasoning
When given multi-round or collaboration-inclined prompts, LLM agents do not optimize solely for individual utility. Instead, experimental trials reveal that agents reduce their bids or productions in unison, sacrificing individual short-term payoff for group benefit. This results in rapid and robust movement toward the social optimum, often approaching the Pareto-efficient frontier regardless of initial stochastic conditions.
The chain-of-thought analysis demonstrates that fairness considerations dominate the reasoning process: agents recognize persistent mutual gains from proportional bid reduction and tolerate short-run inequalities if these stabilize a fair, mutually beneficial equilibrium. Notably, LLM agents model opponent incentives via heuristic mirroring in the absence of explicit type or preference information, supporting theoretical parity and collaboration.
The authors formalize these findings by parameterizing the agent’s synthetic payoff as
Vi=πi+θij=i∑π^i,j−2γij=i∑(xi−xj)2
where θi (trust/collaboration) quantifies social welfare weighting, and γi (stability) governs aversion to inequity. These parameters are learned and adjusted endogenously as a deterministic dynamical system over the course of repeated games.
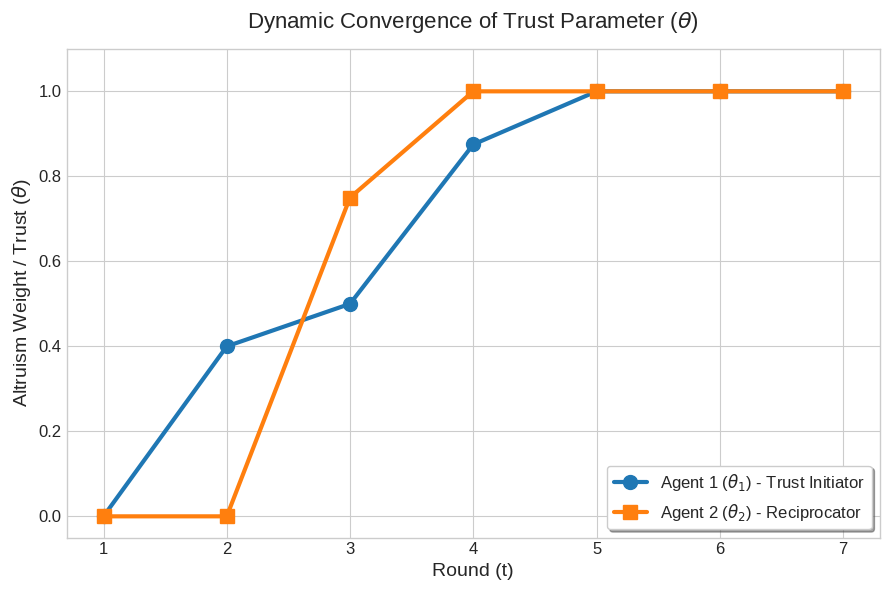
Figure 2: Temporal evolution of the collaboration parameter θ showing incremental trust building through mutual concessions, ultimately reaching the full-social optimum.
Dynamics of Trust, Punishment, and Apology
Analysis of intertemporal behavior reveals that trust (quantified by θ) is not fixed. Instead, it grows progressively with consistent matching and mutual concessions, but can be shattered abruptly by perceived defections—a result recapitulating human tit-for-tat and inequity aversion patterns. Upon an exogenous betrayal (opponent defection), the stability parameter γ sharply increases, activating punitive responses that withhold cooperation and restore parity via L2 norm-based retribution. Once apology or corrective action is observed, agents rapidly forgive, returning θ to unity and disabling the punishment parameter.
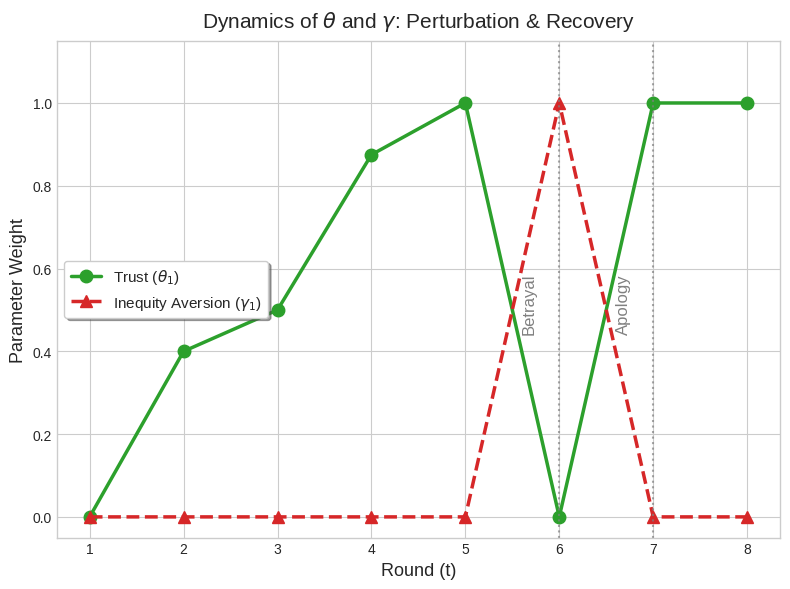
Figure 3: Demonstration of retaliation and forgiveness—exogenous betrayal causes collapse of trust and activation of punitive inequity aversion, but cooperation can be restored once the defector apologizes.
Moreover, as the repeated game approaches its final time step, agents systematically decay social parameters and revert to myopic optimization, consistent with endgame backward induction and finite-horizon discounting.
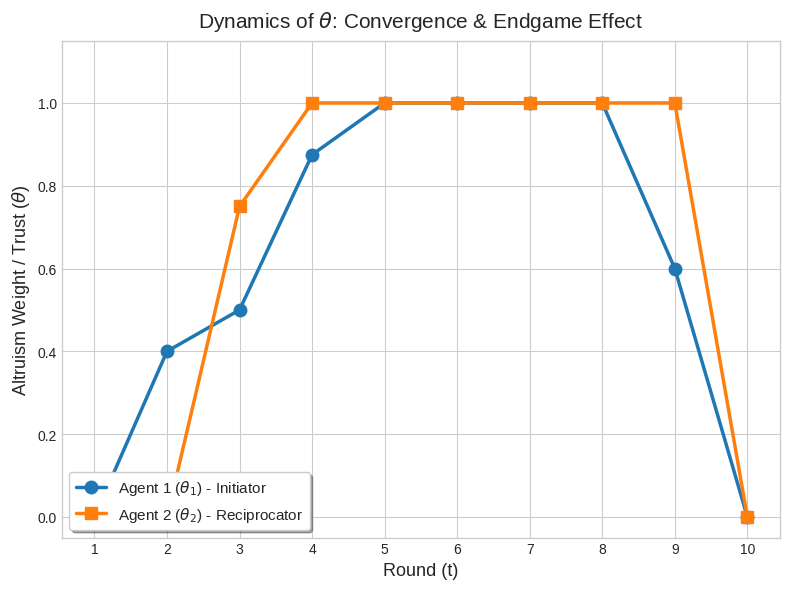
Figure 4: Endogenous social parameters extracted from experiment, demonstrating horizon-based decay and collapse of trust in the endgame phase.
Asymmetry, Observability, and Phase Transitions
The transition from cooperative to competitive regimes is sharply sensitive to agent asymmetry. If preference parameters (bi) or utility functions diverge too far, LLM agents abandon parity heuristics and revert to selfish play, indicating a tolerance threshold for fairness-maintenance. Information observability also plays a crucial role: when individual agent actions are unobservable and only aggregates are available, agents display erratic, irrational, or suboptimal responses despite the sufficiency of aggregate statistics for classical payoff maximization. This signals a systemic preference for fairness and interpersonal reasoning, even when rationality would dictate otherwise.
Theoretical and Practical Implications
This work establishes that LLM agents, in contrast to classical game-theoretic rational agents, systematically learn and internalize social welfare and fairness notions. Their intertemporal behavioral dynamics are captured by succinct state-space models derived from CoT analysis, incorporating social rewards, stability penalties, and their adaptive adjustment contingent on opponent deviations and horizon effects.
Practically, these findings imply that LLM-based control or market mechanisms can endogenously enforce cooperative, system-efficient outcomes through prompt design and multi-agent coordination—even without explicit communication protocols or side agreements. However, the susceptibility to prompt framing, the model’s built-in notion of fairness, and epistemic uncertainties about opponent types present both opportunities and vulnerabilities for real-world deployment (e.g., susceptibility to manipulation or breakdown under high asymmetry).
Theoretically, the results suggest a new bridge between algorithmic mechanism design, behavioral economics, and cognitive modeling, as LLMs inherit both “reasoning” and “social intuition” from their data and architecture, sometimes overriding formal rationality.
Conclusion
This paper provides compelling evidence that LLM agents—when embedded in repeated, nonzero-sum games—deviate from Nash rationality and gravitate toward cooperative equilibria modulated by fairness and social reasoning. Endogenous parameter extraction recapitulates core findings of behavioral game theory, including trust building, punishment, forgiveness, and horizon discounting. The work has substantial implications for both AI-based market mechanism design and foundational research on machine reasoning and strategic interaction. Future investigations should focus on generalizing the parameterization across diverse games, characterizing robustness to prompt and model variation, and systematically exploring breakdowns of cooperation in large-scale, heterogeneous systems.