SCENIC: Stream Computation-Enhanced SmartNIC
Abstract: Although modern, AI-centric datacenters heavily rely on SmartNICs, existing devices impose a hard trade-off. Commercial SmartNICs provide high bandwidth and easy software integration, but offer limited support for customization and data processing offload. In contrast, research SmartNICs often suffer from low bandwidth, limited functionality, and poor software compatibility -- to the point that many are not actual NICs in a technical sense. This gap can be closed by treating the NIC datapath as a first-class stream computation substrate with shared hardware/software abstractions for a tight co-design of infrastructure and applications. To demonstrate this, we introduce SCENIC, an open-source datacenter SmartNIC. SCENIC implements a 200G network datapath over offloaded TCP/IP and RDMA stacks, as well as a fallback path for processing arbitrary network traffic. On top of the network logic, SCENIC combines on-datapath Stream Compute Units (SCUs) for data processing and embedded ARM cores for flexible control path manipulation with direct access to GPUs and SSDs. SCENIC is fully integrated with the OS, exposing native Linux network and RDMA verb interfaces, making the programmable datapath transparent to existing applications while enabling control of, e.g., user-defined offloads and programmable congestion control. SCENIC's performance matches commercial platforms, and we show its versatility through several use cases such as offloaded collective communication and network-to-GPU hash-based data partitioning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper introduces SCENIC, a new kind of network card for servers called a SmartNIC. Think of a normal network card (NIC) as the mailroom of a computer: it receives and sends data “packages.” A SmartNIC is like a mailroom with its own mini workshop inside—it can sort, check, and even reshape packages before passing them on.
SCENIC is an open-source SmartNIC that:
- Runs at very high speeds (up to 200 gigabits per second).
- Can process data “on the way” using small, programmable units.
- Talks directly to GPUs and SSDs without bothering the main CPU.
- Works with regular operating systems and software as if it were a normal NIC, so most apps don’t need changes.
The main questions the paper asks
In simple terms, the authors wanted to know:
- Can we build a fast (200G), flexible SmartNIC that is open-source and easy for researchers to customize?
- Can it handle common network jobs (like TCP/IP and RDMA) on its own, not just pass everything to the CPU?
- Can it process data while it travels through the network card (like filtering, hashing, or combining data), and still keep up with very fast network speeds?
- Can it connect directly to GPUs and SSDs to speed up AI and data tasks?
- Can it plug into Linux and standard tools so existing applications keep working?
How they built it (methods and approach)
The team built SCENIC using FPGAs—chips that can be “rewired” after they’re made, like a Lego set for hardware. That means you can change how the SmartNIC works without buying a new chip. They also used small ARM processor cores on the card for slower, flexible control tasks.
Here’s the design in everyday terms:
- Fast lane vs. slow lane: Incoming network traffic is sorted. Common protocols (TCP/IP and RDMA) go down a fast hardware lane. Anything else goes to a “slow path” that forwards it to the regular operating system networking code.
- On-the-way workers (SCUs): SCENIC adds “Stream Computation Units” (SCUs). Imagine workstations placed along the highway that can do tasks (like hashing, filtering, compression) while data flows by, without stopping traffic.
- Supervisors (ARM cores): Little ARM CPUs on the card act like supervisors that update rules, collect stats, and change settings, without blocking the fast lane.
- Direct connections to GPUs and SSDs: Instead of sending data into the CPU first, SCENIC can move data directly between the network and GPU/SSD, like a dedicated conveyor belt.
- Compatible drivers: The card looks like a normal NIC to Linux (netdev) and like a standard RDMA device (ibverbs), so existing software can use it right away.
- Programmable traffic rules: The card lets you change congestion control (the “traffic lights” of the network) by swapping hardware modules quickly (in about 8 milliseconds), so you can try new algorithms.
They tested SCENIC on several FPGA cards (from AMD Alveo families, including a 200G Versal V80), and they measured:
- Latency and throughput using standard tools (ping, iperf3, and RDMA perftest).
- GPU-to-NIC transfers with both AMD and NVIDIA GPUs.
- SSD performance by sending TCP data directly to NVMe storage on the card.
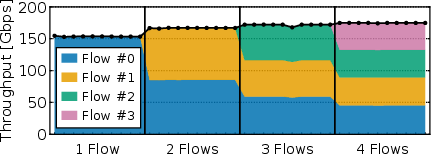
- Fair sharing when multiple network flows run at once.
What they found and why it matters
Their main results show that SCENIC performs like commercial high-end SmartNICs, but is open-source and much more customizable:
- High speed (200G) with common offloads:
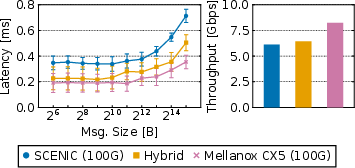
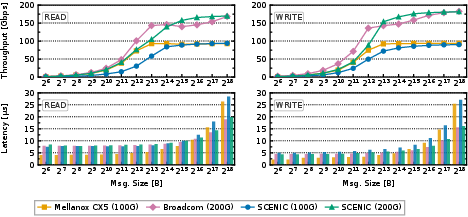
- RDMA (fast, direct memory-to-memory transfers) hits line-rate speeds similar to commercial NICs.
- TCP/IP offload works well, and there’s a fallback “slow path” for anything else.
- Works out of the box with Linux and RDMA tools:
- Appears as a normal network device and a normal RDMA device, so no need to rewrite your applications.
- Data-on-the-way processing:
- SCUs can compute on streaming data (e.g., hashing for partitioning to GPUs, or collective communication for AI training), without slowing down the stream.
- Direct-to-GPU and direct-to-SSD:
- The card can send and receive data straight to GPU memory or SSDs, cutting out the CPU middleman.
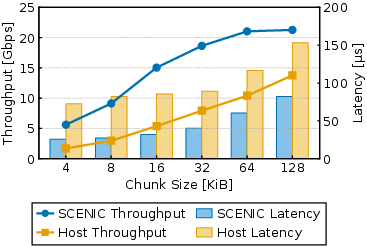
- For TCP-to-SSD, SCENIC reduced latency by 2–3× and increased throughput by about 1.3–1.5× compared to a standard software path.
- Fairness and isolation:
- Multiple flows mapped to different SCUs share bandwidth fairly and don’t interfere with each other.
- Programmable congestion control:
- New “traffic light” algorithms can run at full speed on the hardware pipeline and be swapped fast, which is hard to do on closed commercial devices.
- Real use cases:
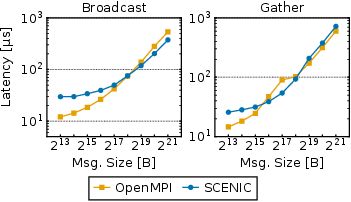
- Offloaded collective communication (used in AI training) matched normal MPI performance.
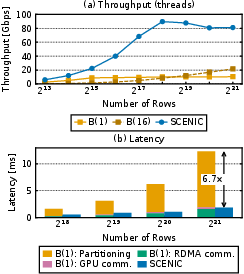
- Network-to-GPU hash-based data partitioning sped up a database scenario by 6.7× over a CPU baseline.
A few notes:
- Latency on the fallback path is slightly higher than commercial NICs (ASICs), but still fine for control/management traffic.
- NVIDIA GPU reads were slower than ideal in their setup; they plan to improve this.
Why this work matters (impact and future possibilities)
- Faster, cheaper datacenters: By moving more work from CPUs to the SmartNIC, SCENIC reduces the “datacenter tax” (CPU time spent on overhead) and speeds up AI and data jobs.
- Better AI training and data analytics: Direct links to GPUs and SSDs, plus in-flight data processing, help large-scale training and big data pipelines run faster.
- Research and innovation: Because SCENIC is open-source and programmable, researchers can quickly test new ideas—like new congestion control, new protocols, or new on-the-way processing—on real hardware, not just in simulations.
- Flexibility without lock-in: Unlike many commercial SmartNICs, SCENIC doesn’t tie you to a proprietary toolkit. You can code offloads in hardware languages (RTL), high-level synthesis (HLS), SpinalHDL, or P4, then integrate them easily.
- A platform to build on: SCENIC shows it’s possible to have the best of both worlds—commercial-level performance and full customizability—making it a strong base for future data center networking research and development.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of unresolved issues and open questions left by the paper that future researchers could address.
- Coverage of RDMA semantics and compliance: Only READ/WRITE are benchmarked; support and performance for SEND/RECV, SRQ, UD/UC/RC QPs, RDMA atomics, memory windows, inline data, and IBTA/RoCEv2 compliance testing are not reported, nor is cross-vendor interoperability beyond simple throughput.
- Programmable congestion control (PCC) evaluation depth: The paper describes DCQCN and an ACK-clocked controller with 8 ms partial reconfiguration but does not quantify line-rate per-packet PCC performance under ECN marking, incast, or mixed short/long flows, nor validate stability/fairness across many QPs/tenants.
- PCC state continuity and correctness during reconfiguration: Beyond a “dual-CC” sketch, there is no mechanism or evaluation for state transfer, losslessness, and correctness when swapping CC modules or recovering from misconfiguration/failures.
- TCP/IP offload completeness and interoperability: TCP/IP offload is only evaluated in a storage pipeline; feature coverage (e.g., options, RFC conformance, SACK/Timestamps), stress under loss/reorder, and interop with Linux TCP stacks at scale are not assessed.
- Slow-path NIC features and 200G operation: The fallback netdev path is measured at 100G with ping/iperf and no TSO/GRO; small-packet PPS, 200G operation, RSS/multi-queue scalability, ethtool offload toggles, and XDP/AF_XDP/DPDK compatibility are not evaluated.
- Netdev offload gaps: Only L2 checksum is offloaded; lack of TSO/GSO/GRO/LRO and IP/TCP/UDP checksum offloads likely caps host networking performance—impact and roadmap for adding them are unclear.
- Multi-tenancy and virtualization: SR-IOV/vDPA, virtio-net, and VM/container integration (Kubernetes/CNI plugins) are not described; per-tenant QoS (e.g., weighted fair queuing), admission control, and bandwidth guarantees beyond round-robin fairness are missing.
- Memory/DMA isolation and security: The device-side TLBs and dma-buf approach are introduced, but enforcement across tenants, IOMMU integration, access control to host/GPU/SSD memory, and attack surfaces (e.g., DMA abuse, side channels) are not analyzed.
- GPU integration depth and root-cause analysis: NVIDIA underperformance (especially READs) is noted but not fully diagnosed; latency, small-transfer behavior, multi-GPU via PCIe switches, MIG/virtualization, page migration/pinning costs, and TLB miss/pathological cases are not measured.
- NVMe host controller scope: Only write path is evaluated; read path performance, random I/O, mixed workloads, scaling to multiple SSDs/queues, admin commands/namespaces/multipath, error handling (timeouts, resets), and data integrity semantics (e.g., power-loss protection) are not covered.
- OS/storage integration and safety: Bypassing the host for NVMe control (queues in HBM/DDR) raises questions about coherence with host filesystems, permissions, and lifecycle management (hotplug, resets); mechanisms to prevent inconsistent state are not described.
- Resource utilization and timing closure: There is no breakdown of LUT/BRAM/URAM/HBM usage, critical path frequencies, and timing margins at 100G/200G, nor the incremental cost of enabling TCP/IP, multiple SCUs, PCC, and NVMe.
- Power and thermals: No measurements of power draw and thermal headroom compared to commercial NICs/DPUs under typical and worst-case workloads; TCO implications and perf/Watt trade-offs are not discussed.
- Scalability beyond 200G: The design’s path to 400G/800G (pipeline depth, clock targets, MAC/PHY feasibility, NoC limits) and the impact on per-packet budgets for PCC and SCUs are not explored.
- Buffering/backpressure and PFC risk: The MACs do not accept backpressure and rely on PFC; buffering strategies, head-of-line blocking, and deadlock risks (and mitigation) are not analyzed under incast or microbursts.
- Reliability and fault handling: Watchdogs, error detection/recovery for SCUs/CC modules, PCIe errors, and safe rollback on configuration failures are not specified; impact of faults on host/tenants is unknown.
- Observability and debugging: There is no description of telemetry (counters, events), programmable INT, tracing, or integration with common observability stacks (e.g., perf, eBPF, Prometheus), nor on-card debug tooling.
- Partial reconfiguration (PR) at scale: Beyond an 8 ms PCC PR time, reconfiguration of full SCUs (bitstream sizes, downtime), state snapshot/restore, scheduling PR among tenants, and security of PR flows are open.
- Programmability limits and toolchain maturity: Practical limitations of HLS/P4/SpinalHDL (e.g., pipeline control, loops/state, memory access patterns), compile times, verification coverage, and portability across FPGA families are not characterized.
- Scheduling and isolation across SCUs: The arbiter enforces round-robin fairness, but weighted policies, latency SLAs, burst policing, and protection against misbehaving SCUs are not evaluated.
- Large-scale and tail behavior: Experiments are limited to a single cluster; tail latency under congestion, multi-switch paths, incast at scale, and fair sharing with dozens to hundreds of flows/QPs are not reported.
- Standards conformance and ecosystem integration: Upstream readiness of Linux/rdma-core drivers, acceptance path, and maintenance burden are unclear; support for evolving protocols (e.g., UltraEthernet, INT, HPCC) is not demonstrated.
- Interoperability breadth: Beyond Mellanox and Broadcom datapoints, protocol edge cases (ECN mis-marking, reordering, PMTU changes), heterogeneous vendor interop, and mixed-topology deployments are not tested.
- Application-level evaluations: Aside from brief mentions (collectives, hash partitioning), there is no detailed end-to-end evaluation of SCU compute kernels (e.g., encryption/compression/hashing) with throughput/latency/resource usage, or comparisons against CPU/GPU/ASIC baselines.
- Portability and vendor dependence: The design relies on AMD IP (DCMAC/QDMA, Vitis P4); portability to other FPGA vendors or ASIC NICs, and the effort needed to retarget primitives (MAC/PCIe/NoC) are not assessed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage SCENIC’s open-source 200G SmartNIC with offloaded TCP/IP and RDMA, on-datapath Stream Compute Units (SCUs), programmable congestion control, and direct-to-GPU/SSD integration. Each lists the sector, probable tools/workflows, and feasibility assumptions.
- AI/ML distributed training: offloaded collectives and shuffles
- Sector: AI/ML, HPC
- Tools/Workflow: Use SCENIC as an
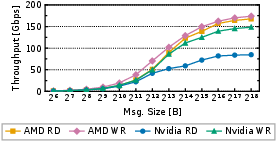
ibv_devicewith rdma-core; offload collectives via ACCL+; map per-job Queue Pairs (QPs) to dedicated SCUs for isolation and scheduling; configure via Python/C++ runtime; integrate with PyTorch/DeepSpeed/Horovod by replacing the NIC driver without changing model code. - Assumptions/Dependencies: RDMA-enabled fabric; supported AMD/NVIDIA GPUs with dma-buf GPUDirect; cluster admins can deploy kernel driver and rdma-core provider; availability of Alveo V80/U55C boards.
- Network-to-GPU hash partitioning for multi-GPU data processing
- Sector: Data analytics, Databases, AI/ML
- Tools/Workflow: Implement a hashing SCU (HLS/RTL) to partition incoming RDMA/TCP flows and DMA chunks directly into multiple GPUs; orchestrate partitions via Python runtime; couple with RAPIDS/cuDF or custom GPU operators; reuse provided libstf building blocks.
- Assumptions/Dependencies: Stable GPUDirect RDMA (dma-buf) support; sufficient GPU/PCIe bandwidth; HLS/RTL development effort to tailor the partitioner; existing operators to consume partitioned data.
- Storage ingestion offload: TCP-to-NVMe path on NIC
- Sector: Cloud storage, Data ingestion pipelines, Content delivery
- Tools/Workflow: Route TCP/IP segments to the NIC-resident NVMe controller; store submission/completion queues in FPGA memory; deliver line-rate writes to SSDs with reduced CPU load; use standard Linux netdev for control-plane traffic.
- Assumptions/Dependencies: Local NVMe devices and available PCIe lanes; sustained SSD bandwidth; integration with storage service control software; driver deployment in production.
- Programmable congestion control (PCC) experimentation and deployment
- Sector: Networking vendors, Cloud/Datacenter ops, Academia
- Tools/Workflow: Swap congestion-control modules on the NIC via partial reconfiguration (~8 ms); A/B test DCQCN replacements or telemetry-driven schemes; keep a dual-CC pipeline preloaded for hitless switchover.
- Assumptions/Dependencies: Operational acceptance and safeguards for CC changes; packet telemetry availability; FPGA partial reconfiguration toolchain; production change-control processes.
- Incast-aware stateful firewall and telemetry on NIC
- Sector: Enterprise/cloud networking, Security
- Tools/Workflow: Offload line-rate flow tracking and rate limiting in an SCU; run dynamic policy logic on embedded ARM cores; exchange statistics via AXI and interrupts; manage rules and counters in standard software.
- Assumptions/Dependencies: Policy logic ported to ARM cores; P4/HLS/RTL for parsing/flow tracking; audited rule paths for correctness; ops integration for updates and observability.
- Drop-in replacement for RDMA NICs in performance-critical microservices
- Sector: Software infrastructure, Microservices platforms
- Tools/Workflow: Deploy SCENIC as a standard NIC (
netdev,ibv_device) to run existing applications unchanged; optionally enable per-flow processing by assigning QPs to SCUs for selective acceleration (e.g., compression, encryption, checksums). - Assumptions/Dependencies: Compatibility with existing kernels/toolchains; tested interoperability with peers (e.g., ConnectX, Broadcom); stable driver provider in CI/CD.
- Multi-tenant traffic isolation and fairness at the NIC
- Sector: Cloud service providers, Multi-tenant HPC
- Tools/Workflow: Map tenants or jobs to distinct SCUs; rely on hardware arbitration for fair bandwidth sharing; enforce per-tenant limits and avoid cross-flow interference; integrate with Kubernetes/Slurm schedulers via driver hooks.
- Assumptions/Dependencies: Tenant-to-QP mapping and policy management; monitoring/telemetry integration for metering and SLA enforcement.
- Accelerated streaming ETL primitives in-network
- Sector: Data engineering, Stream processing
- Tools/Workflow: Implement line-rate SCU pipelines for filtering, hashing, (de)compression, dedup; steer RDMA/TCP payloads through SCUs and DMA results into CPU/GPU memory; orchestrate via Python runtime (NumPy/Pandas interop) for quick iteration.
- Assumptions/Dependencies: Availability of suitable HLS/RTL IP and FPGA memory (HBM/DDR/URAM) for state; correctness validation using simulation harness.
- Reproducible research and teaching platform for networks/systems
- Sector: Academia
- Tools/Workflow: Use the open-source SCENIC stack (hardware, drivers, rdma-core provider) in labs/courses for RDMA, congestion control, in-NIC compute, GPU/SSD-direct; teach P4/HLS/RTL programming with provided build/sim flows.
- Assumptions/Dependencies: Access to Alveo boards and AMD IP (DCMAC/QDMA/P4); lab cluster with 100G/200G switching; instructor familiarity with HDL/HLS toolchains.
- Interop testbed for next-gen transports (e.g., UltraEthernet)
- Sector: Standards bodies, Network vendors, Research labs
- Tools/Workflow: Prototype packet formats, NIC-side behavior, and protocol semantics on the open datapath; compare to simulators; publish reproducible artifacts and traces.
- Assumptions/Dependencies: Early specifications and trace generators; community collaboration for cross-vendor testing; willingness to share artifacts.
Long-Term Applications
These opportunities require additional engineering, scaling, or standardization before production deployment.
- Open 400G/800G SmartNIC platform with on-datapath compute
- Sector: Hardware vendors, Hyperscalers
- Tools/Workflow: Extend SCENIC design to higher-rate PAM4 MACs and deeper pipelines; scale SCUs and HBM capacity; evolve DMA engines and PCIe Gen5/Gen6.
- Assumptions/Dependencies: Next-gen FPGA availability/licensing; thermal/power budgets; verification and timing closure at higher clocks.
- Production-grade, workload-adaptive congestion control at scale
- Sector: Cloud/Datacenter networking
- Tools/Workflow: Deploy per-tenant/per-application CC modules with live telemetry feedback; centrally orchestrate CC swaps fleet-wide; integrate control loops with SDN and observability stacks.
- Assumptions/Dependencies: Robust failure modes and rollback; safety and fairness proofs; operational guardrails and certification.
- NIC-managed disaggregated storage and NVMe-oF offloads
- Sector: Storage systems, Disaggregated infrastructure
- Tools/Workflow: Extend NIC-resident NVMe host controller to multi-SSD topologies; offload NVMe/TCP and NVMe/RDMA data paths; combine with inline encryption/compression SCUs.
- Assumptions/Dependencies: Firmware maturity, multipath support, error handling; security/compliance (FIPS, KMIP); data services integration.
- In-network database operators (joins, group-by, sketches) at line rate
- Sector: Databases, Analytics platforms
- Tools/Workflow: Design SCUs for approximate/streaming operators (e.g., HyperLogLog, sketches), packetized joins/aggregations, consistent hashing for distributed shuffles; feed GPU/CPU operators directly.
- Assumptions/Dependencies: Memory footprint/state management on FPGA (HBM/URAM); operator correctness/consistency semantics; scheduler cooperation across compute/storage.
- GPU-centric orchestration: NIC-driven collectives and data staging
- Sector: AI/ML, HPC
- Tools/Workflow: Move collective orchestration entirely onto the NIC (ACCL+ + SCUs), minimizing CPU involvement; NIC coordinates multi-GPU pipelines and topology-aware routing; integrate with framework graph schedulers.
- Assumptions/Dependencies: Tight integration with frameworks (PyTorch, NCCL interop); robust error handling/timeouts; cross-vendor GPU DMA stability.
- Secure-by-design NIC pipelines (inline crypto/compliance)
- Sector: Finance, Healthcare, Public sector
- Tools/Workflow: Add SCU-based AES/GCM/IPsec/TLS termination with hardware key management; enforce per-tenant isolation; offload DLP/tokenization on NIC paths.
- Assumptions/Dependencies: Availability/licensing of validated crypto IP; certification (FIPS 140-3) and audits; key lifecycle integration with HSMs/KMS.
- Dynamic multi-tenant service chains on the NIC
- Sector: Cloud NFV, Telco
- Tools/Workflow: Schedule chains of SCUs (e.g., parse → ACL → telemetry → compression) per tenant; apply dynamic partial reconfiguration for hot-swapping functions; export per-chain SLAs.
- Assumptions/Dependencies: Fast, reliable partial reconfiguration in production; service chain orchestration/placement algorithms; state migration strategies.
- Edge/5G/RAN acceleration with tight timing
- Sector: Telco, Edge computing
- Tools/Workflow: Extend SCUs for fronthaul parsing, timestamping, and compression; integrate time-sync (PTP), eCPRI handling; offload user-plane tasks close to radios.
- Assumptions/Dependencies: Deterministic timing guarantees; industry-specific protocol IP and conformance; ruggedized deployments and power constraints.
- Policy and standards impact via open, reproducible NIC designs
- Sector: Policy, Standards bodies (e.g., UltraEthernet, IETF)
- Tools/Workflow: Use SCENIC to validate congestion control fairness/safety, transport extensions, and GPU/SSD-direct best practices; inform standard updates with empirical results.
- Assumptions/Dependencies: Broad community participation; sustained maintenance and governance; reference test suites and artifacts.
- Low-latency feed handling and pre-trade checks in HFT environments
- Sector: Finance
- Tools/Workflow: Implement FPGA SCUs for parsing, normalization, risk checks at ingress; route decisions to co-located trading engines; exploit deterministic pipelines.
- Assumptions/Dependencies: Ultra-low-latency design/placement; venue-specific protocol support; strict compliance and audit trails.
Notes on feasibility across applications:
- Hardware availability and licensing: Some AMD IP (e.g., DCMAC, QDMA, Vitis P4) requires licenses; availability of Alveo boards is assumed.
- Software stack: Linux kernel compatibility, rdma-core provider installation, and CI/CD integration are required.
- Environment: 100G/200G switching fabric, GPUDirect RDMA (dma-buf) support for AMD and NVIDIA GPUs, and sufficient PCIe bandwidth are prerequisites.
- Operational readiness: For production, fault handling, observability, security hardening, and change-control processes must be established.
Glossary
- ACCL+: An FPGA collective communication offload engine/library for high-performance collectives comparable to MPI. "SCENIC additionally integrates with ACCL+~\cite{accl+}, a collective offload engine for FPGAs with performance comparable to MPI."
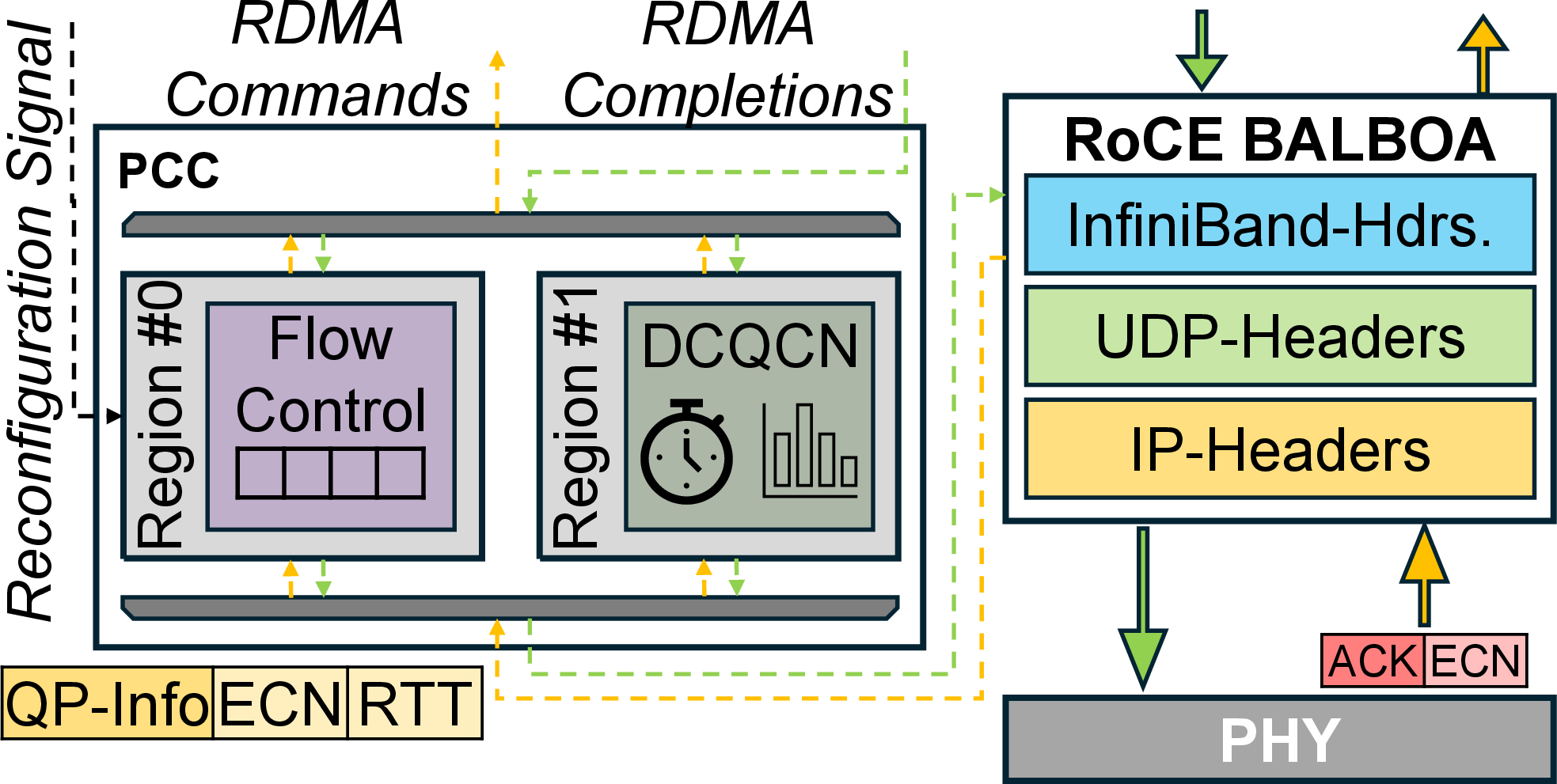
- ACK-clocked: A flow-control strategy where the sender’s sending rate is paced by received acknowledgments. "As reference implementations, SCENIC provides a simple ACK-clocked window-based flow controller and a full DCQCN implementation."
- Actor-based programming model: A concurrency model where state and behavior are encapsulated in actors that communicate via message passing. "iPipe~\cite{iPipe} further extends this approach and relocates distributed application logic directly onto the NIC using an actor-based programming model."
- AXI bus: A memory-mapped on-chip bus interface (part of ARM AMBA) used for low-latency control and data movement. "Data transfer between the SCUs and the Arm cores is handled via a memory-mapped AXI bus, providing access to either control registers for lightweight command exchange or a dedicated memory unit for higher-capacity data buffering."
- AXI Stream: A streaming, lightweight AXI protocol for high-throughput dataflow between modules. "exposing L2-stripped, network-layer packets on an AXI Stream bus."
- BAR (PCIe Base Address Register): A PCIe-mapped address range exposing device memory or registers to the host or peers. "To bypass host CPU intervention, all NVMe control structures, including submission/completion queues and PRP lists, as well as data buffers are hosted in FPGA HBM/DDR and are mapped to a PCIe BAR."
- BRAM/URAM: On-chip FPGA memories (Block RAM and Ultra RAM) offering low-latency storage. "while all supported FPGAs include tens of megabytes of on-chip Block- and Ultra-RAM (BRAM/URAM) with single-cycle access latency."
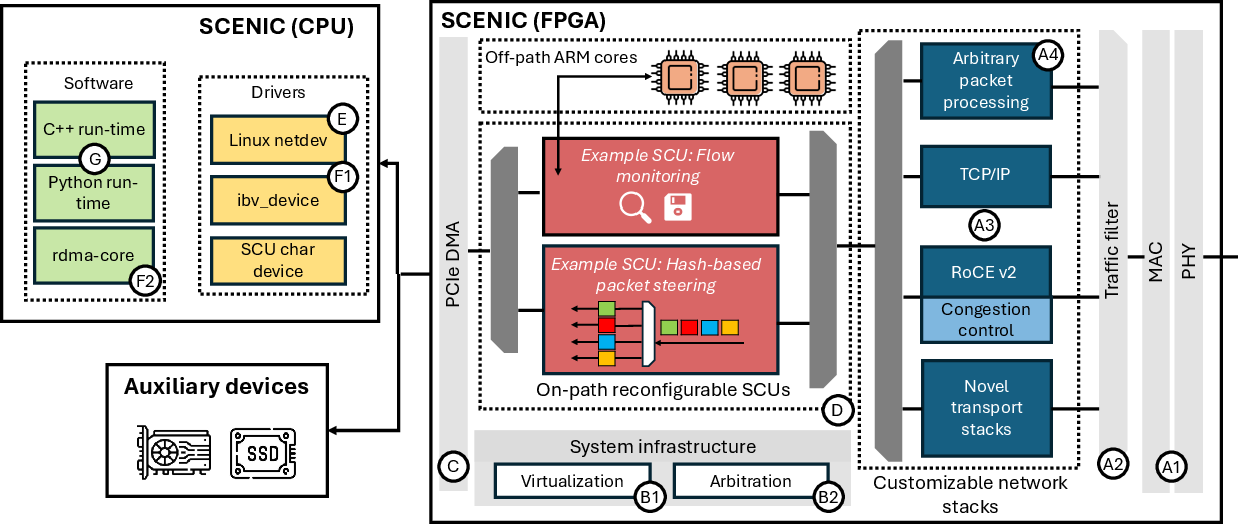
- CMAC: A Xilinx 100G Ethernet MAC/PCS IP core used to implement the physical Ethernet layer. "To sustain line-rate performance (R1), SCENIC implements the physical layer on top of the Xilinx CMAC (UltraScale+ platforms, 100G) or DCMAC (Versal platforms, 200G) IP cores."
- DCQCN: Data Center Quantized Congestion Notification, a hardware congestion control algorithm for RoCE. "As reference implementations, SCENIC provides a simple ACK-clocked window-based flow controller and a full DCQCN implementation."
- DCMAC: A Xilinx Versal 200G Ethernet MAC/PCS IP core for high-speed Ethernet. "To sustain line-rate performance (R1), SCENIC implements the physical layer on top of the Xilinx CMAC (UltraScale+ platforms, 100G) or DCMAC (Versal platforms, 200G) IP cores."
- dma-buf: A Linux mechanism for zero-copy buffer sharing across devices (e.g., GPU–FPGA). "Access to NVIDIA GPU memory follows the same approach as for AMD GPUs, using the Linux dma-buf mechanism."
- DOCA: NVIDIA’s proprietary SDK and framework for programming DPUs/SmartNICs. "Instead, SCENIC offers an open programming standard for offloads, supporting hardware description languages (HDLs), high-level synthesis (HLS), and network-specific languages such as P4."
- Doorbell registers: NVMe registers used to notify the device of new entries in submission queues. "By maintaining direct access to NVMe doorbell registers and processing completion entries in hardware, SCENIC enables a low-latency data path between storage and network stacks."
- DPDK: A user-space packet processing framework for high-performance networking. "we further require a NIC to provide a host driver compatible with standard networking frameworks (e.g., Linux netdev, ibv_device, or DPDK)."
- Dynamic partial reconfiguration: Reconfiguring a portion of FPGA fabric at runtime without stopping the entire design. "SCENIC leverages this property by implementing each congestion control algorithm as a dedicated hardware module, which can be swapped at runtime via dynamic partial reconfiguration of the FPGA fabric (R3)."
- eBPF: A Linux in-kernel programmable bytecode system for packet processing and tracing. "hXDP~\cite{hXDP} focuses on offloading Linux XDP/eBPF programs on FPGAs hardware"
- Fat Tree: A multirooted tree network topology common in datacenters for high bisection bandwidth. "classifying flows by source subnet to reflect pod-level positions in Fat Tree topologies~\cite{fat-tree},"
- FEC (Forward Error Correction): Error-correcting codes used on links to detect and correct bit errors. "These manage PAM2/PAM4 signal modulation~\cite{PAM2, PAM4}, forward error correction (FEC), and priority flow control (PFC) for lossless Ethernet~\cite{pfc}."
- GPUDirect RDMA: Direct NIC-to-GPU memory access bypassing the CPU for lower latency and overhead. "and has recently become the standard implementation for GPUDirect RDMA~\cite{gpu-rdma}."
- GRO (Generic Receive Offload): A host-side network optimization that coalesces incoming packets before protocol processing. "Further features such as TSO or GRO are not implemented in hardware to keep the design small and resource-efficient, but can be added in future work."
- HBM (High Bandwidth Memory): Stacked DRAM integrated with the device for very high memory bandwidth. "SCENIC supports HBM on platforms such as Alveo V80, U55C, and U280 with hundreds of GB/s of memory bandwidth."
- High Level Synthesis (HLS): Compiling C/C++-like code into hardware RTL with pragmas guiding micro-architecture. "High Level Synthesis (HLS), a programming language based on C++ with pragmas to guide the hardware behavior."
- ibv_create_qp_ex: An extended RDMA verbs API to create Queue Pairs with additional attributes. "Finally, we implement ibv_create_qp_ex with an SCU index as an additional parameter, allowing applications to explicitly map RDMA flows to specific SCU processing pipelines~(R3)."
- ibv_device: The RDMA-core abstraction representing an RDMA-capable device exposed to user space. "For data-intensive workloads, SCENIC includes a fully offloaded RoCEv2 stack and exposes itself as an ibv_device, ensuring compatibility with existing IB Verb applications (R2)."
- ibv_reg_mr: An RDMA verbs call that registers a memory region for remote access. "When calling ibv_reg_mr, the provider stores memory translations for the allocated user-space buffer directly in SCENIC's on-device Translation Lookaside Buffers (TLBs)."
- Incast: A many-to-one traffic pattern that can overwhelm a receiver or link buffers. "We demonstrate this SCUâCPU co-design with an incast traffic firewall."
- Interrupt coalescing: Grouping multiple events before raising an interrupt to reduce overhead. "while interrupt coalescing amortizes interrupt overhead under high load, improving throughput."
- io_uring: A Linux asynchronous I/O interface using ring buffers for low-overhead submission/completion. "written to the SSD via a single-threaded io_uring event loop with O_DIRECT."
- IRQ: Hardware interrupt request signal/line used to notify processors of events. "up to 16 IRQ connections can be dynamically assigned to individual SCUs providing low-latency event signaling from the data path to the Arm cores."
- Linux netdev: The Linux kernel’s network device interface used by NIC drivers. "SCENIC supports up to 200G bandwidth with native OS integration through Linux netdev and ibv_device."
- LRU replacement: A cache/TLB policy evicting the least recently used entry first. "an LRU replacement strategy implemented in hardware preserves low latency for frequently active QPs (R1)."
- MAC/PHY layers: Ethernet media access control and physical layer blocks implementing link-level functions. "SCENIC implements a network datapath with IP cores for the MAC and PHY layers~\RobustCircled[0.5pt]{\scriptsize A1},"
- Match-action pipeline: A programmable networking model that matches on packet headers and applies actions. "All three provide programmable datapath capabilities through P4-programmable ARM cores (E2000), multi-threaded RISC-V cores (BF3), and P4-programmable match-action pipelines (Pensando),"
- MSI-X: A PCIe mechanism allowing devices to generate many independent interrupts. "Throughout this paper, we adopt the definition of a NIC from~\cite{ocp_nic_definition}: a PCIe device with (i) a physical network interface (e.g., Ethernet or InfiniBand), (ii) a DMA engine for host-memory packet transfers, and (iii) an MSI-X interrupt interface for completions."
- MTU (Maximum Transmission Unit): The largest packet size that can be sent over a link without fragmentation. "At 200\,G with MTU-sized RoCE packets, this budget is approximately:"
- Network-on-Chip (NoC): An on-chip interconnect fabric used to connect IP blocks within an SoC/FPGA. "features a Network-on-Chip (NoC), making it a significantly more powerful platform."
- NVMe host controller: Logic implementing the NVMe interface from the host side to control SSDs. "SCENIC therefore integrates a dedicated NVMe host controller within the FPGA fabric to handle both submission and completion logic."
- Off-path Arm cores: Processor cores not on the main data path, used for control or slow-path tasks. "off-path ARM/RISC-V cores, which are unsuitable for latency-sensitive, high-throughput offloads~\cite{off_path_compute_1, off_path_compute_2}."
- P4: A domain-specific language for programmable packet processing pipelines. "P4, a language for packet processing pipelines, enabling rapid development of parsing, classification, and header manipulation."
- PAM2/PAM4: Two- and four-level pulse amplitude modulation schemes for high-speed serial links. "These manage PAM2/PAM4 signal modulation~\cite{PAM2, PAM4}, forward error correction (FEC), and priority flow control (PFC) for lossless Ethernet~\cite{pfc}."
- PCIe relaxed ordering: Allowing out-of-order completion of read requests to improve performance. "we explicitly enable relaxed ordering for reads, reducing latency and preventing head-of-line transfer stalls."
- PFC (Priority Flow Control): Link-layer flow control for lossless Ethernet on a per-priority basis. "These manage PAM2/PAM4 signal modulation~\cite{PAM2, PAM4}, forward error correction (FEC), and priority flow control (PFC) for lossless Ethernet~\cite{pfc}."
- PRP lists (Physical Region Page lists): NVMe structures describing scatter/gather lists of data buffers. "To bypass host CPU intervention, all NVMe control structures, including submission/completion queues and PRP lists, as well as data buffers are hosted in FPGA HBM/DDR and are mapped to a PCIe BAR."
- Programmable congestion control (PCC): A framework/approach that enables swapping or tuning congestion control algorithms in hardware. "Programmable congestion control (PCC), with scenario-adaptive algorithm selection, addresses this challenge but requires direct modification of the transport logic, which is restricted on commercial NICs."
- QDMA: A Xilinx hardened PCIe DMA IP optimized for high-performance, multi-queue transfers. "On 200G Versal platforms, we use the hardened QDMA IP~\cite{qdma-ip}, which can be configured in PCIe Gen4x16 or Gen5x8 mode."
- Queue Pair (QP): An RDMA construct consisting of send and receive queues used for reliable connections. "ensures scalability across hundreds of QPs through automated translation lookups on TLB misses,"
- QPN (Queue Pair Number): The identifier of an RDMA Queue Pair used for steering and demultiplexing. "such as the RoCE Queue Pair Number (QPN) or TCP Flow ID."
- RDMA (Remote Direct Memory Access): Networked memory access that bypasses the host CPU/kernel for low-latency data movement. "SCENIC implements a 200G network datapath over offloaded TCP/IP and RDMA stacks, as well as a fallback path for processing arbitrary network traffic."
- Ring buffer: A circular buffer structure used for efficient producer–consumer queues. "into a unified ring buffer, halving the number of required DMA operations compared to a naive two-transfer design and resulting in improved performance (R1)."
- RoCEv2 (RDMA over Converged Ethernet v2): RDMA over routable Ethernet using UDP/IP encapsulation. "For data-intensive workloads, SCENIC includes a fully offloaded RoCEv2 stack and exposes itself as an ibv_device, ensuring compatibility with existing IB Verb applications (R2)."
- RTL (Register-Transfer Level): A hardware design abstraction level describing registers and logic transfers per clock. "Register-transfer level (RTL), through languages such as SystemVerilog and VHDL."
- TLB (Translation Lookaside Buffer): A cache of virtual-to-physical address translations to accelerate memory access. "When calling ibv_reg_mr, the provider stores memory translations for the allocated user-space buffer directly in SCENIC's on-device Translation Lookaside Buffers (TLBs)."
- TSO (TCP Segmentation Offload): NIC offload that segments large TCP packets into MTU-sized frames. "Further features such as TSO or GRO are not implemented in hardware to keep the design small and resource-efficient, but can be added in future work."
- XDMA: A Xilinx PCIe DMA IP core for data movement between host and FPGA. "On 100G UltraScale+ platforms, DMA is realized through the XDMA IP~\cite{xdma-ip} supporting PCIe Gen3x16."
Collections
Sign up for free to add this paper to one or more collections.

