- The paper introduces Text2Arch, a comprehensive dataset of over 75,000 architecture diagrams with aligned text and DOT code, addressing limitations of prior diagram generation methods.
- It outlines a robust multi-step data curation process that includes filtering, GPT-4-refined annotations, and complexity stratification to ensure high-quality structure.
- Experimental results show fine-tuned models, especially DeepSeek-7B, achieve superior semantic and structural accuracy compared to few-shot and traditional approaches.
Text2Arch: A Large-Scale Resource for Scientific Architecture Diagram Generation from Text
The generation of scientific architecture diagrams from natural language input is a critical problem as technical communication shifts to increasingly complex, system-oriented, and multi-modal workflows. Manual diagram creation is labor-intensive and error-prone; existing vision-language generative models are insufficient for capturing the strict semantic and structural alignment required in architecture diagrams. The lack of an aligned, large-scale open-access dataset for this task further hinders progress.
Text2Arch directly addresses this gap by offering a comprehensive dataset of over 75,000 architecture diagrams, with each example containing: (i) a carefully curated and semantically rich textual description, (ii) an architecture image, and (iii) a corresponding DOT code representation. This allows systematic benchmarking of text-to-architecture diagram generation and provides the substrate for training and evaluating specialized models.
Dataset Creation and Characteristics
Text2Arch is curated via a multi-step pipeline: filtering scientific figures with a dedicated architecture diagram classifier (CLIP, ViT, BEiT, ResNet), extracting candidate diagrams from Paper2Fig and other sources, then annotating them with both automated and GPT-4o-refined DOT code and image descriptions. The dataset covers a range of scientific domains and includes easy/medium/hard partitions based on the number of nodes.
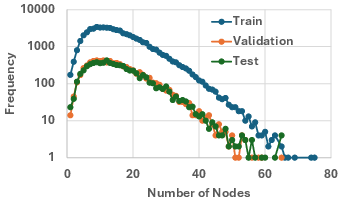
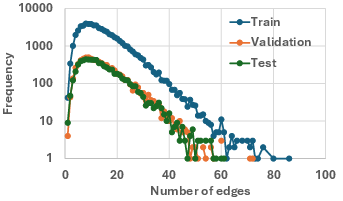
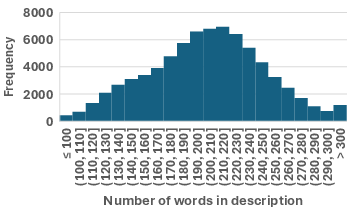
Figure 1: Distributions over node/edge counts and image description lengths in Text2Arch, indicating coverage of simple to highly complex architectures and broad variety in text complexity.
On average, diagrams have 15.24 nodes, 13.89 edges, and descriptions spanning ∼203 words. Data splits (train/valid/test: 60,519/7,565/7,043) are stratified by complexity. Text2Arch also provides 99 manually annotated samples for human evaluation and a rigorous graph-based analysis.
Limitations of Prior Art
Previous solutions for text-to-image or text-to-diagram generation (e.g., diffusion models, TikZ/Graphviz synthesis pipelines, generic diagram synthesis agents like DiagramAgent) are ill-suited for architecture diagram generation:
- Diffusion Models: Insensitive to explicit structure, limited context windows, poor handling of logical/semantic alignment, hard to edit outputs, and poor OCR/fine-grained text synthesis.
- TikZ/Graph Compilers: Generically applicable but lack fine semantic control and are often brittle for heterogeneous multi-domain diagrams.
- DiagramAgent: Multi-agent, multi-style but with loosely-aligned data, cross-domain noise, and reliance on less-precise text-code-image alignment.
Text2Arch remedies these by focusing exclusively on architecture diagrams with strong triplet alignment, well-created descriptions, and robust DOT code reference targets.
Model Benchmarking and Evaluation Metrics
The benchmark includes comprehensive evaluation of both few-shot and fine-tuned instruction-following LLMs (Meta-Llama-3-8B, Qwen2-7B, DeepSeek-7B) on DOT code generation from textual input, with comparisons against DiagramAgent and GPT-4o zero-shot. The pipeline favors DOT code as the target output, rendered by Graphviz, emphasizing editability, clarity, and explicit structure over pure image realism.
Evaluation uses a mixture of standard NLG metrics (ROUGE-L, CodeBLEU, Levenshtein distance, chrF) and task-specific graph-level metrics (node and edge precision/recall/F1 using string-similarity matched assignment, PR AUC, and Jaccard similarity). This joint axis of evaluation is critical for properly capturing both semantic and structural fidelity.
Experimental Results
Fine-tuned DeepSeek-7B models provide substantially improved syntactic and structural fidelity over both few-shot LLMs and the DiagramAgent baseline. For instance, on the manual annotation set:
- DeepSeek-7B achieves ROUGE-L 55.2, CodeBLEU 49.3, Node F1 69.4, Edge F1 49.1, and Jaccard 39.8.
- This represents a strong improvement over the best few-shot ICL (Llama-3-8B ROUGE-L 37.3) and DiagramAgent (ROUGE-L 49.1, Node F1 54.3, Edge F1 25.3).
- GPT-4o zero-shot is relatively competitive on graph F1, but fine-tuned open-weight models offer better accessibility and reproducibility.
Critically, these gains hold across easy/medium/hard partitions and for both text and structural accuracies.
Manual and GPT-based human evaluation confirm these improvements, with DeepSeek-7B preferred in subjective ratings and exhibiting high human-agreement for node/edge matching. Ablations demonstrate that the GPT-4o refined DOT code (DOT3) yields significant improvements over direct GPT extraction (DOT1) and pure visual extraction (DOT2).
Case Studies and Qualitative Assessment
Text2Arch's DeepSeek-7B consistently captures both high-level semantic flow (e.g., coarse pipelines, architecture connectivity) and low-level detail (fine node/edge labeling, skip connections, module hierarchy). Generated DOT code not only renders plausible, faithful diagrams but is also interpretable and modifiable by human experts, supporting workflow editing and iterative design that black-box generative systems cannot provide. Baseline models are prone to generic, misaligned, or underspecified output, especially in high-complexity settings.
Implications and Future Directions
Text2Arch’s dataset and models establish a new foundation for research in text-to-diagram generation, serving as a testbed for approaches in:
- Multimodal scientific knowledge grounding
- AI-assisted technical writing and visualization
- End-to-end AI-driven software design and code synthesis
- Educational technology and domain-adapted content generation
The results highlight the necessity and effectiveness of domain-specific fine-tuning over pure few-shot or zero-shot prompting for complex structure generation. Open-sourcing this resource enables robust benchmarking, fair comparison, and rapid iteration in diagram synthesis research.
Future directions include advanced multimodal alignment (e.g., DPO, RLHF), direct image synthesis with semantic parsability, multilingual/low-resource settings, and integration with CAD, program synthesis, or workflow automation pipelines.
Conclusion
Text2Arch delivers, for the first time, a large-scale, high-quality, semantically aligned triplet dataset for text-to-architecture diagram generation. Fine-tuned LLMs on this dataset robustly outperform alternatives in generating editably correct, semantically faithful DOT code—a prerequisite for practical workflow in scientific, enterprise, and educational domains. This enables new research into robust, structure-aware, and modifiable diagram generation, and positions Text2Arch as the reference benchmark for the community (2604.14941).

