- The paper demonstrates that rank fusion (RRF) achieves superior nDCG@10 scores, significantly outperforming single-method retrieval approaches.
- The paper introduces a B5 projection fusion method that reduces latency by 33% and increases result diversity (ILD@10) by over 2× compared to RRF.
- The paper reveals that MMR reranking enhances diversity at the cost of relevance, highlighting a trade-off ideal for exploratory literature searches.
Hybrid Retrieval Strategies for COVID-19 Literature: Fusion, Projection, and Diversity
System Overview and Methodological Contributions
This paper evaluates hybrid retrieval strategies for COVID-19 scientific literature using the TREC-COVID benchmark. It implements six configurations based on sparse (SPLADE), dense (BGE), rank-level fusion (RRF), and projection-based vector fusion (B5) approaches. The methodologically distinct pipelines are: (1) sparse-only retrieval (B1), (2) dense-only retrieval (B2), (3) RRF fusion (B4), (4) RRF + MMR reranking (B3), (5) B5 projection fusion, and (6) B5 + MMR reranking. Query sets span expert-crafted, machine-generated, and three paraphrase styles to robustly assess retrieval efficacy and diversity.
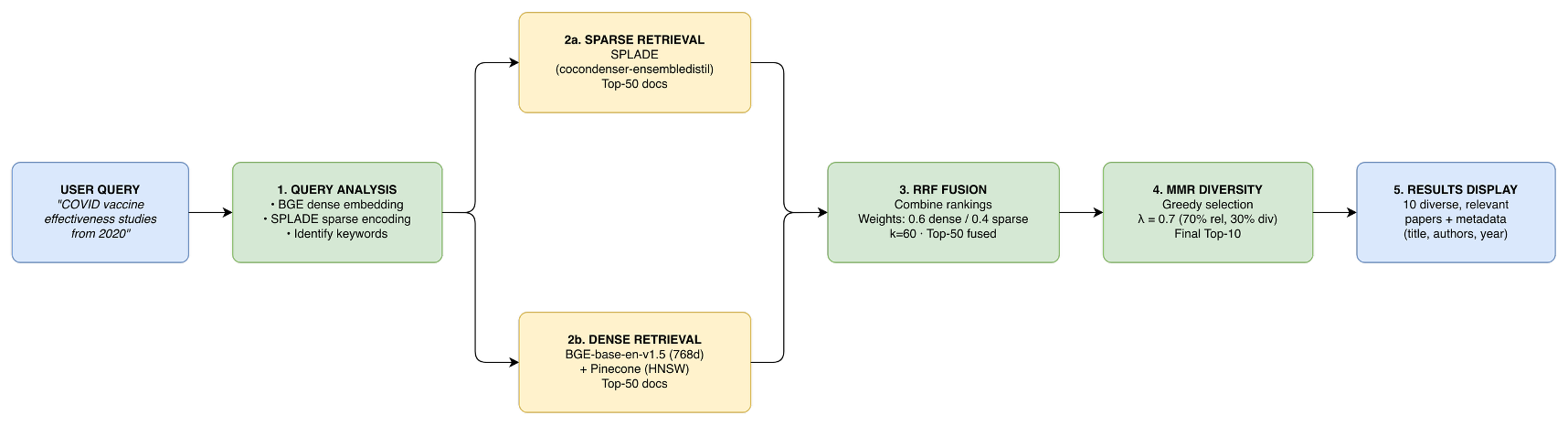
Figure 1: The RRF pipeline fuses ranked lists from SPLADE (sparse) and BGE (dense) encoders for COVID-19 literature queries, followed optionally by MMR reranking for diversity.
The B5 projection fusion applies Achlioptas sparse random projections to map SPLADE's high-dimensional sparse vectors into BGE's 768-dimensional dense space, enabling single-pass retrieval. This process does not depend on training data and leverages Johnson-Lindenstrauss-style guarantees for distance preservation, followed by L2 normalization and weighted vector fusion.
Experimental Evaluation and Numerical Results
Query Diversity and Benchmarking
The evaluation uses 400 queries across expert, generated, conversational, semi-technical, and keyword-heavy sets. Metrics include nDCG@10 (primary relevance), P@10, MRR@10, MAP@10, HitRate@10, and intra-list diversity (ILD@10).
Strong results are observed:
- RRF (B4) achieves nDCG@10 = 0.8282 on expert queries, outperforming dense-only by 6.1% and sparse-only by 14.9%.
- B5 projection fusion reaches nDCG@10 = 0.6779, with 33% reduction in latency (847 ms vs. 1271 ms) and 2.2× higher ILD@10 (0.389 vs. 0.176) compared to RRF.
- On keyword-heavy paraphrases, B5 achieves an 8.8% relative gain, although RRF maintains a higher absolute score.
- MMR reranking increases diversity (ILD@10) by 23.8–24.5% at a cost of 20.4–25.4% loss in nDCG@10, evidencing the relevance-diversity trade-off.
Latency, Fusion Tuning, and Generalization
B5 delivers consistent speedups in all query sets, and both pipelines remain under 2s latency. Mixing parameter αquery tuning in B5 shows optimal performance at 0.95 in the mixed-document setting, and further increases do not translate to a pure-dense baseline without document-side ablation.
On machine-generated queries, SPLADE sparse retrieval outperforms all fusion methods (nDCG@10 = 0.4272), confirming superior keyword-matching for terse inputs and demonstrating the sensitivity of retrieval methods to query formulation and qrel labeling.
Theoretical and Practical Implications
Hybrid Fusion Efficacy and Trade-offs
Hybrid fusion methods consistently outperform single-method retrieval for expert-formulated and reformulated queries. RRF's rank-level fusion leverages both exact token matches and semantic similarity, reinforcing its efficacy in high-relevance scenarios.
Projection fusion (B5) offers a practical alternative for latency-sensitive or diversity-focused applications. The inherent diversity in projected representations—substantially higher ILD@10—occurs even before explicit diversification via MMR, suggesting projection-based fusion as a mechanism for increasing information breadth.
MMR Reranking: Diversity-Relevance Dilemma
Empirical results establish MMR as a non-trivial relevance-diversity trade-off tool, increasing intra-list dissimilarity at the cost of nDCG@10. This mechanism is best reserved for contexts where diversity supersedes absolute relevance, such as exploratory retrieval or literature surveys.
Dense, sparse, and fusion pipelines all show varying degrees of robustness across conversational, semi-technical, and keyword-focused paraphrases. Notably, B5 projection fusion is most stable in semi-technical settings, and exhibits the highest relative improvement for keyword-heavy queries. This underscores the value of hybrid and projection-based methods for resilience against query formulation shifts.
Limitations and Future Directions
The primary limitations are: reliance on a single benchmark (TREC-COVID), bottlenecks in sparse encoding throughput, absence of learned projection matrices, and no document-side fusion ablation. The authors identify several prospects for future research: supervised projection training, scaling to the full CORD-19 corpus, alpha tuning at the document level, integration of ColBERT rerankers, and contradiction detection in scientific claims.
Conclusion
This study formally demonstrates that hybrid retrieval, especially RRF fusion, substantially improves relevance for COVID-19 literature queries compared to single-method approaches. Projection-based vector fusion (B5) sacrifices some relevance for notable gains in latency and result diversity, providing a distinct operational profile for retrieval systems. MMR reranking reliably increases diversity, confirming its role as a relevance-diversity negotiation instrument. The findings clarify retrieval method suitability based on query characteristics and operational requirements, and suggest projection fusion as a promising direction for scalable, diversity-enhanced scientific search in future IR systems.