- The paper demonstrates that compositional persona prompting combined with supervised fine-tuning enables LLMs to emulate fine-grained subgroup values and generalize to unseen intersectional identities.
- It introduces a Modal Diversity Score to quantify cultural divergence and exposes significant fairness trade-offs, with some subgroups benefiting more than others.
- Empirical results reveal that while overall accuracy improves post-fine-tuning, error-magnitude disparities persist and may amplify latent model biases.
Fine-Grained Value Alignment in Persona-Prompted LLMs: Generalisability, Fairness, and Cultural Nuance
Introduction
This paper presents a rigorous empirical analysis of fine-grained value alignment in LLMs, advancing the conversation from monolithic, often Western-centric "human value" alignment towards demographic subgroup-aware alignment. The focal research questions involve (i) mapping and quantifying intra-societal value heterogeneity, (ii) examining whether compositional persona prompting plus supervised fine-tuning (SFT) on structured preferences can induce generalisation to unseen intersectional identities, and (iii) auditing the fairness implications—specifically, whether alignment interventions distribute benefits equitably across subgroups. Singapore, with its complex multi-ethnic, multi-religious fabric, is leveraged as a testbed, operationalizing subgroup values from the World Values Survey (WVS).
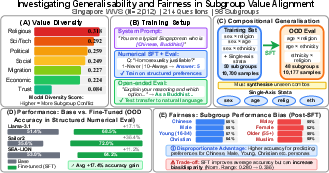
Figure 1: Overview of the experimental framework for value landscape mapping, compositional fine-tuning, OOD generalisation, and subgroup disparity analysis.
Societal Value Landscape and Modal Diversity
The authors introduce a normalized Shannon entropy-based Modal Diversity Score (MDS) to quantify value consensus versus conflict across demographic strata. Subgroup ground-truth preferences are defined as modal WVS responses for each (question, subgroup) pair. The Singaporean case substantiates pronounced heterogeneity: "Religious Values" emerge as maximally divisive, while dimensions such as Social Capital/Trust are most unifying. Ordinal Wasserstein analysis corroborates these divergences, and subgroup sample-size controls eliminate small-N artifact confounds.
Modal answers frequently diverge on high-conflict topics, e.g., wealth redistribution or religious ceremony attendance, stratified along intersecting axes of age and gender, reflecting substantive sociological cleavages. Conversely, for low-conflict items (e.g., views on crime victimization or street violence), modal consensus is robust. These empirical maps expose the theoretical illegitimacy of monolithic value alignment regimes when applied to multicultural polities.
Dataset and Evaluation Protocol
A balanced subpopulation-structured dataset of 20,877 (question, subgroup) pairs is assembled. Pairwise and single-factor strata are included in training; held-out evaluation sets feature OOD intersectional subgroups to rigorously test compositional generalisation (intersectionality per Crenshaw, 1989). Only subgroups N≥30 are retained, controlling for statistical power.
Models analyzed include state-of-the-art open and closed-source LLMs (e.g. Llama-3, SeaLLM, SEA-LION, Sailor2, Qwen2.5, Phi-4, GPT-4* series) up to ≈8B parameters. SFT is performed (1 epoch, conservative settings) using LoRA adapters on the structured preference data—models are prompted to "role-play" specific demographic identities. Evaluation encompasses both strict numerical prediction (modal agreement, NMAE) and open-ended generation, with outputs LLM-ranked for persona adherence and value alignment using a decorrelated Mistral-24B judge.
Fairness auditing computes both max-min Normalized Range and population Coefficient of Variation (CV), examining both accuracy (coarse) and NMAE (distance-aware) distributions across subgroups and strata.
Empirical Results
Baseline Generalisability and SFT Gains
Even top-tier baseline models (e.g., GPT-4.1) achieve only 57.4% OOD modal accuracy (Table results). Simple SFT yields strong generalisation: open-source models average +17.4 percentage points accuracy and −0.096 NMAE improvement for unseen intersectional subgroups, with robust bootstrap-supported significance. Several open-source models (SeaLLM-v3, Sailor2) surpass closed-source baselines post-SFT.
Open-ended persona emulation and value alignment also improve, but transfer is partial and effect sizes modest (average value WR +2.2% vs. GPT-4.1). Alignment produces a negligible trade-off on stylistic persona adherence scores (possible mild alignment tax) with low inter-annotator reliability.
Subgroup Disparities and Alignment Fairness
Pre-alignment, LLMs exhibit substantial demographic bias: higher fidelity to young, male, Chinese, Christian-aligned subgroups, with performance deficits for Malays, Indians, older cohorts, and other minorities—consistent with prior Singapore-specific and international studies.
SFT reduces max-min accuracy gap (avg. Normalized Range .240 → .179), implying more subgroups reach nominal accuracy. However, it exacerbates error-magnitude disparity (NMAE Normalized Range increases by .056), i.e., improvements are not equitably distributed—"easy-to-learn" subgroups (closer to LLM pretraining/cultural biases) accrue disproportionately greater benefit, reflecting alignment schema's inability to neutralize foundation model structural bias.
Granular per-stratum tables show the most disadvantaged subgroups pre-SFT often see the smallest benefit, contradicting naive fairness assumptions with balanced training. Refusals to answer ethically sensitive queries (e.g., on homosexuality or domestic violence) are eliminated by SFT, resolving a separate axis of safe but unrepresentative coverage.
Human Validation
Human-LMM judge agreement is strong for value alignment (w-Kappa = .631) and overall winner (w-Kappa = .568), but weak for persona adherence (w-Kappa = .318), further indicating the limits of automating nuanced cultural style evaluations.
Theoretical and Practical Implications
This study establishes that:
- Compositional persona emulation is feasible with only SFT on structured value labels, generalising to OOD intersectional identities even with relatively small-scale data.
- Alignment effect is only partially transferable to unconstrained natural language generation.
- Subgroup-balanced fine-tuning does not guarantee equitable post-alignment performance, and may in fact amplify latent model/class bias.
- Refusal reduction via SFT foregrounds a safety-fairness trade-off: naive alignment to "real" subgroup values can conflict with universalistic safety norms by reinforcing majority or even harmful preferences (cf. (Choi et al., 6 Jun 2025)).
The results call for interventions at both fine-tuning and foundation stages: e.g., loss reweighting, pretraining data diversification for underrepresented groups, and distribution-matching rather than modal matching supervision.
Limitations and Robustness
Study context is limited to Singapore; the approach is methodologically generalizable but numerical effects are expected to be context-specific. Demographic metadata proxies for identity, which may not capture the full complexity (intra-subgroup distribution not modeled). The use of modal answers silences minority or antagonistic voices. SFT is a baseline—distribution-matching, DPO, or targeted debiasing strategies could yield stronger fairness. Data contamination is unlikely given task difficulty and scale.
Future Research Directions
Extensions should include:
- Cross-national replication (other multicultural societies with available survey data),
- Distributional alignment (moving beyond modal supervision),
- More sophisticated alignment and debiasing objectives (fairness-constrained, adversarial, or distribution-matching fine-tuning),
- Direct intervention at pretraining (via data augmentation or debiasing),
- Expansion to cultural knowledge, affect, and event-level preferences.
Conclusion
This work provides a robust framework for subgroup-aware value alignment, demonstrating both feasibility and risk. Compositional SFT can induce LLMs to emulate fine-grained, intersectional values, but fairness is not achieved "for free." In fact, average improvements can mask growing subgroup disparities, and naive deployment could reinforce dominant perspectives while marginalizing minorities. Practically, the results recommend rigorous, holistic evaluation of alignment strategies, and foreground the need for systemic representativeness in both data and optimization.
As LLMs mediate social interaction across the globe, this study forms a foundation for future research on culturally intelligent and fair AI systems, and highlights the open theoretical challenges of intersectionally robust value alignment.

