- The paper proposes additive averaging kernels that combine a local baseline kernel (P) and a global Gibbs kernel (G) to accelerate convergence.
- It optimizes the trade-off parameter α and partition structure under Frobenius and KL divergence objectives using combinatorial and submodular methods.
- Empirical studies on the Curie–Weiss model show that tuning α in additive mixtures significantly improves worst-case total variation convergence.
Additive Averaging Kernels for Finite Markov Chains: Theory, Optimization, and Empirical Analysis
Introduction and Motivation
The paper "On additive averaging kernels for finite Markov chains" (2604.12334) investigates Markov kernel mixtures of the form Aα=αP+(1−α)G. Here, P is a π-stationary "baseline" kernel, and G is a Gibbs kernel induced by a partition of the finite state space. The parameter α∈[0,1] governs the trade-off between local (via P) and partition-based global (via G) dynamics. Motivated by the recent study of group-averaged and composition-based kernels, the authors seek to determine whether computationally leaner additive mixtures can achieve similar acceleration in convergence to stationarity.
The main results include the characterization of optimal partitions and α under Frobenius and Kullback-Leibler (KL) objectives, combinatorial and submodular optimization strategies, and decay bounds in terms of the spectral gap. Empirical investigation is provided on the Curie–Weiss model, showing nontrivial optimal α and partition structures leading to significant accelerations in worst-case total variation (TV) convergence.
Theoretical Framework and Kernel Construction
The kernel Aα is constructed as a convex combination, blending P0 and P1. The P2 kernel averages within blocks ("orbits") of a partition, while P3 provides standard local exploration. Analysis proceeds by interpreting P4 as a marginal of a lifted chain P5 on an augmented space P6, where the auxiliary variable selects between P7 and P8. This formalism justifies the randomization inherent in P9 without sacrificing reversibility when π0 is reversible.
Frobenius Norm and Combinatorial Partition Optimization
The authors target both the squared Frobenius norm π1 (with π2 the rank-one stationary kernel) and KL divergence from stationarity. For the Frobenius setting, they derive explicit trace formulas. The core result is that minimization over two-block partitions reduces to maximizing a Cheeger-type functional π3 with respect to the stationary flow between blocks, normalized by π4:
π5
This functional appears in both combinatorial optimization and spectral theory, connecting to edge expansion (Cheeger's constant). The optimization of π6 over partitions thus becomes a difference-of-submodular problem, which is intractable in general but is amenable to majorization-minimization (MM) heuristics.
Furthermore, the authors prove geometric decay rates for the Frobenius distance in terms of the absolute spectral gap π7, yielding decay of the form π8 per step.
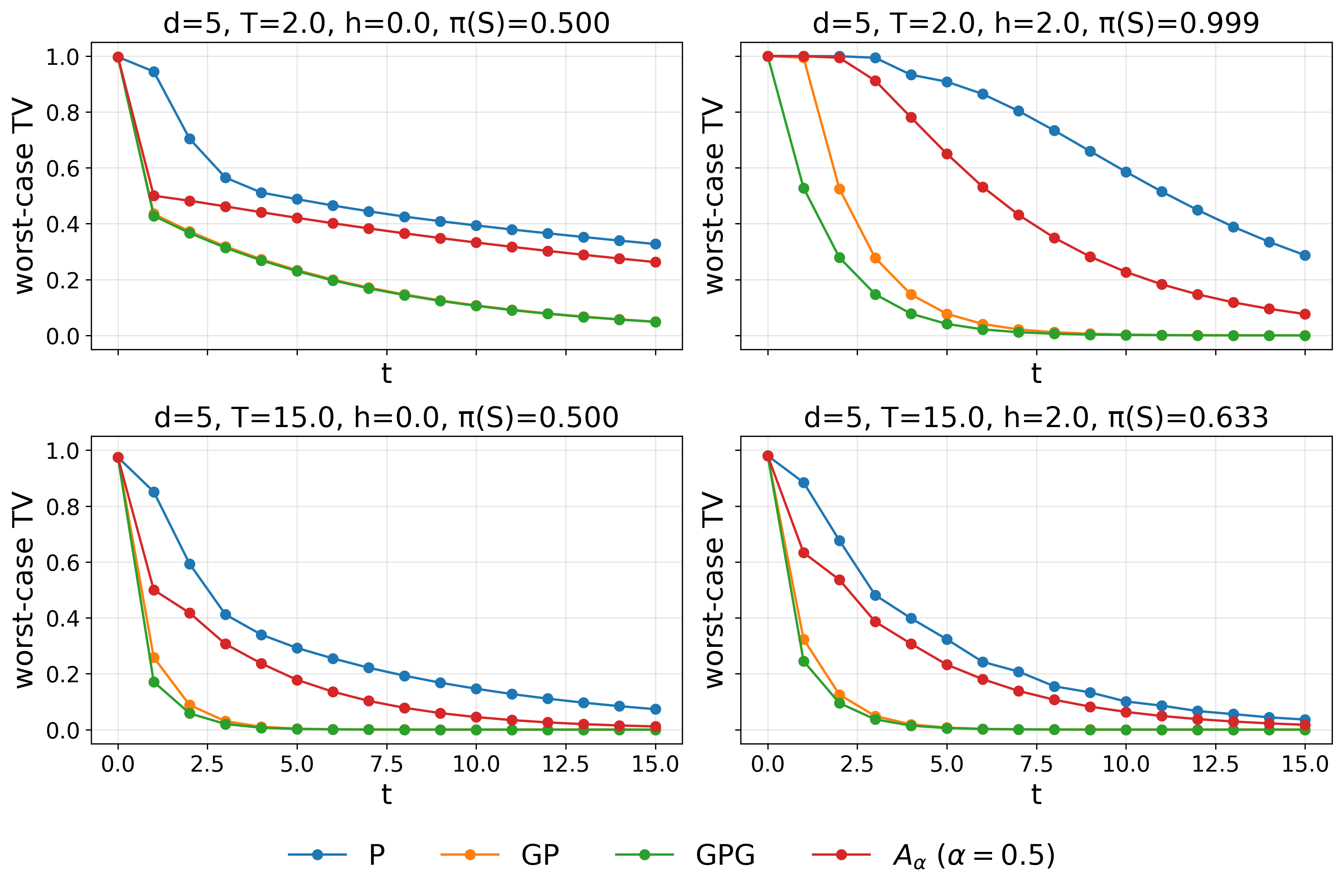
Figure 1: Worst-case total variation distance for different samplers, demonstrating the impact of group-averaging and additive mixtures over the baseline.
KL Divergence: Convexity-Based Bounds and Optimal Partitions
For the KL objective, convexity yields that the KL divergence of π9 to stationarity is upper bounded by a convex combination of the divergences for G0 and G1:
G2
Critically, G3 coincides with the Shannon entropy of the block structure. Thus, optimal partition selection for KL minimization reduces to entropy minimization, and the optimal partition collects least probable states into singleton or small blocks, with the remainder forming a large block.
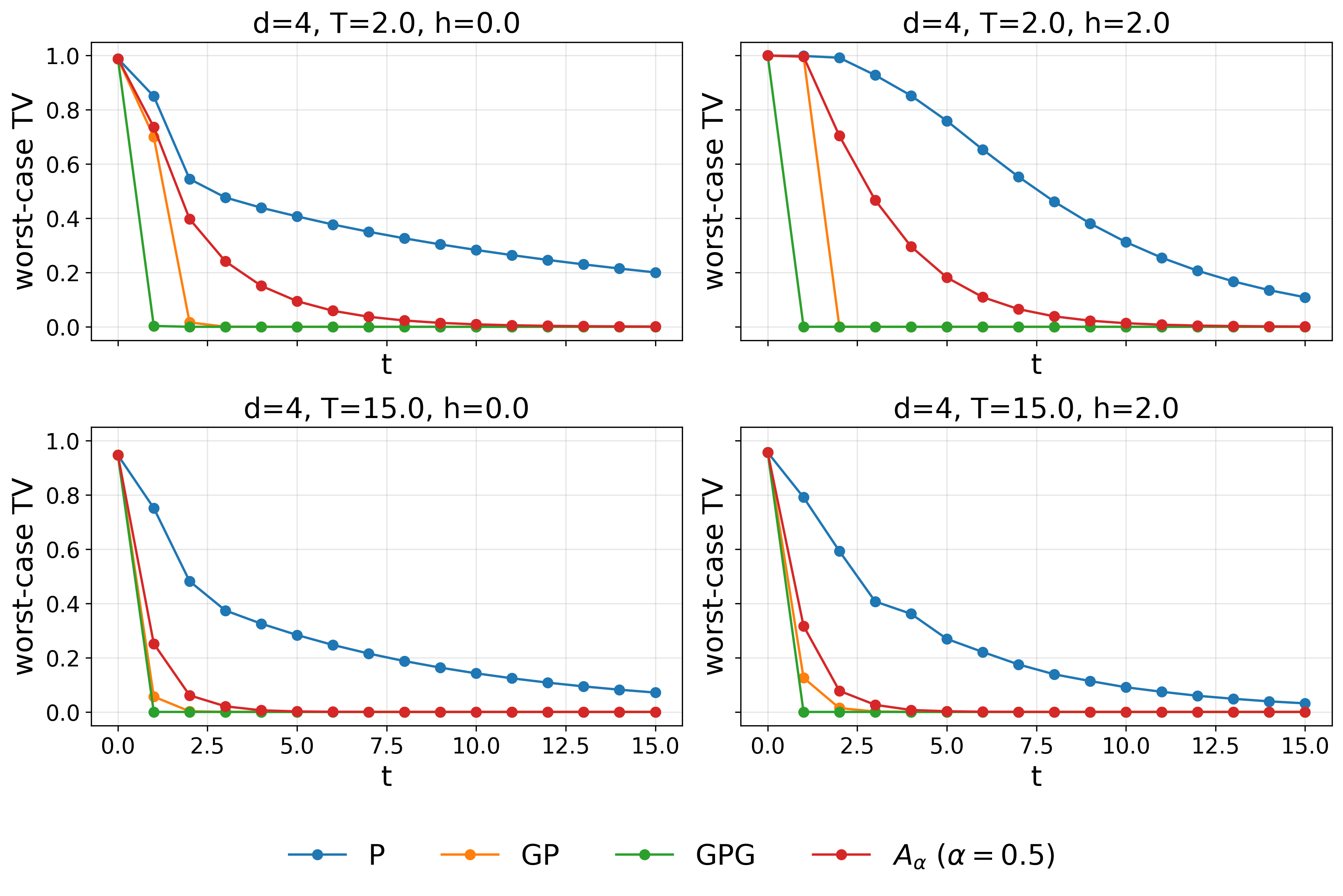
Figure 2: Worst-case total variation distance for different samplers, each optimized over its own Frobenius-optimal partition.
Submodular Optimization and MM Algorithm
The combinatorial optimization of G4 can be decomposed into a difference-of-supermodular functions. Building on recent methods for minimizing differences of submodular functions, the authors present MM surrogates, which iteratively majorize the non-convex objective by easier-to-optimize supermodular functions. This yields practical approximations to the partition optimization problem when the state space is large.
Single-site ("singleton") approximations are also considered. In this regime, the optimal subset is shown to be a singleton associated with the maximal G5, with an additive approximation guarantee for the Frobenius objective.
Spectral and Cheeger Analyses
Explicit formulas relate the structure of G6 and its convergence to the projection chain G7 on the orbit space, Cheeger-type inequalities for expansion, and spectral properties of G8. The analysis reveals that group-averaged and additive kernels perform best when their partitions cut bottlenecks, in some cases selecting highly unbalanced cuts for the (multiplicative) group-averaged kernels and more balanced cuts for additive mixtures.
Numerical Experiments: Trade-off of Exploration and Averaging
Comprehensive experiments are conducted on the Curie–Weiss model in both high- and low-temperature regimes, with and without external field bias. Baseline Glauber (G9), additive kernels α∈[0,1]0, and multiplicative kernels (α∈[0,1]1, α∈[0,1]2) are compared.
Key empirical findings:
- Group-averaged multiplicative samplers uniformly achieve fastest mixing, followed by α∈[0,1]3 (for moderate α∈[0,1]4), then baseline α∈[0,1]5.
- Partitions optimizing the group-averaged kernels tend to be highly unbalanced in low-temperature or metastable regimes, while those for α∈[0,1]6 are more balanced in nearly symmetric settings.
- Tuning α∈[0,1]7 is crucial; both endpoints (α∈[0,1]8 or α∈[0,1]9) result in suboptimal mixing, while intermediate P0 (often near P1) yields optimal TV contraction.
- Singleton approximations can provide efficient partition selection with provable guarantees and little sacrifice in mixing performance.
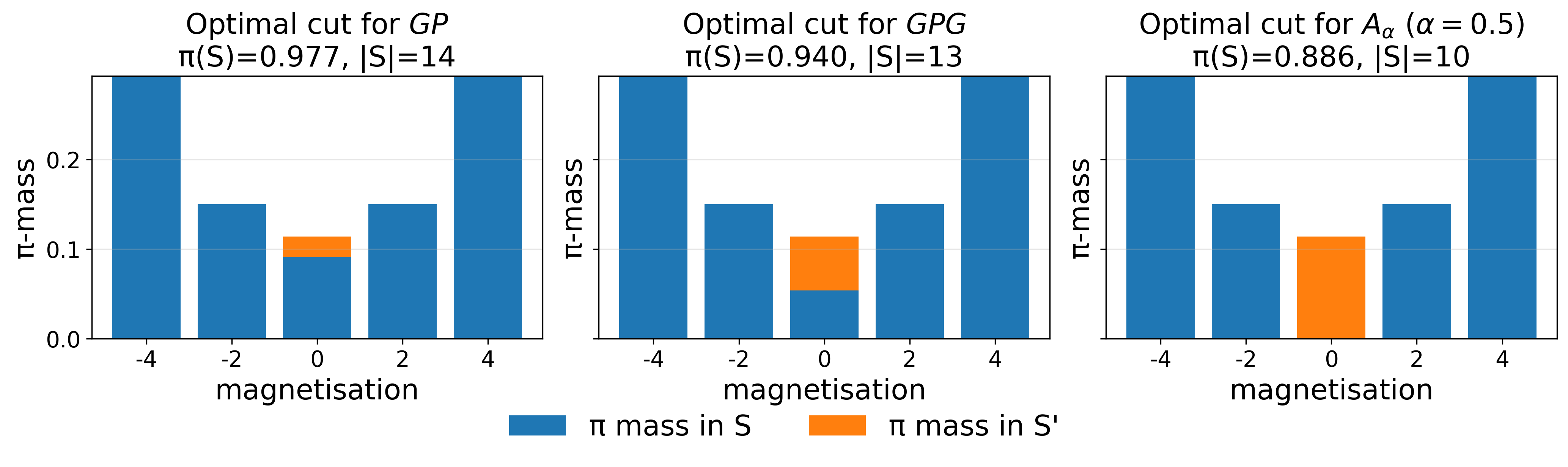
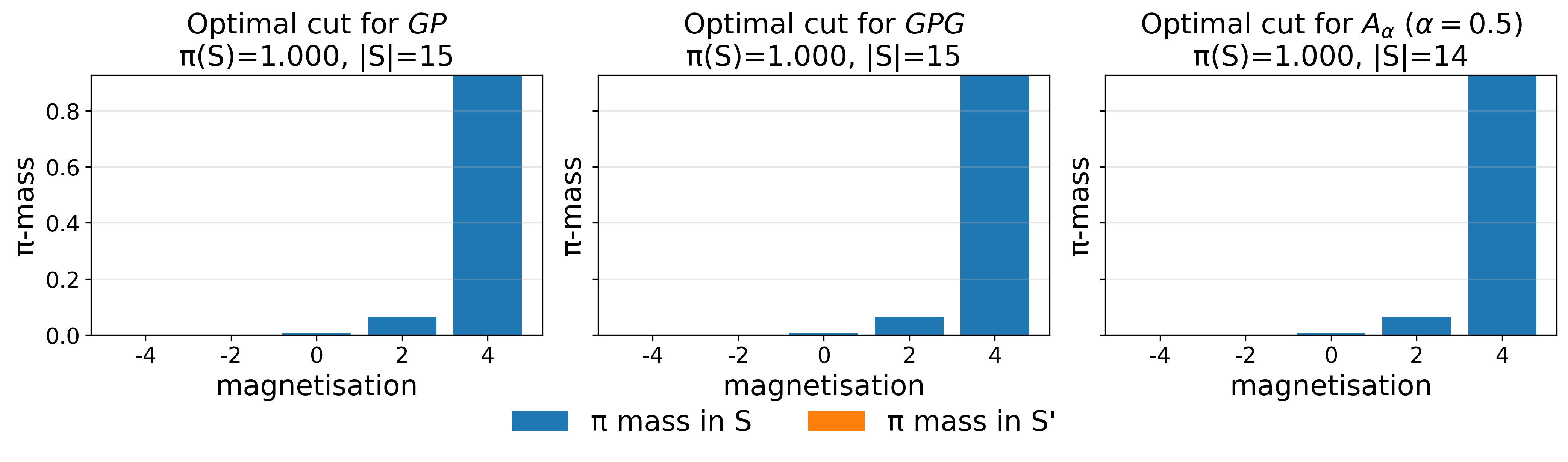
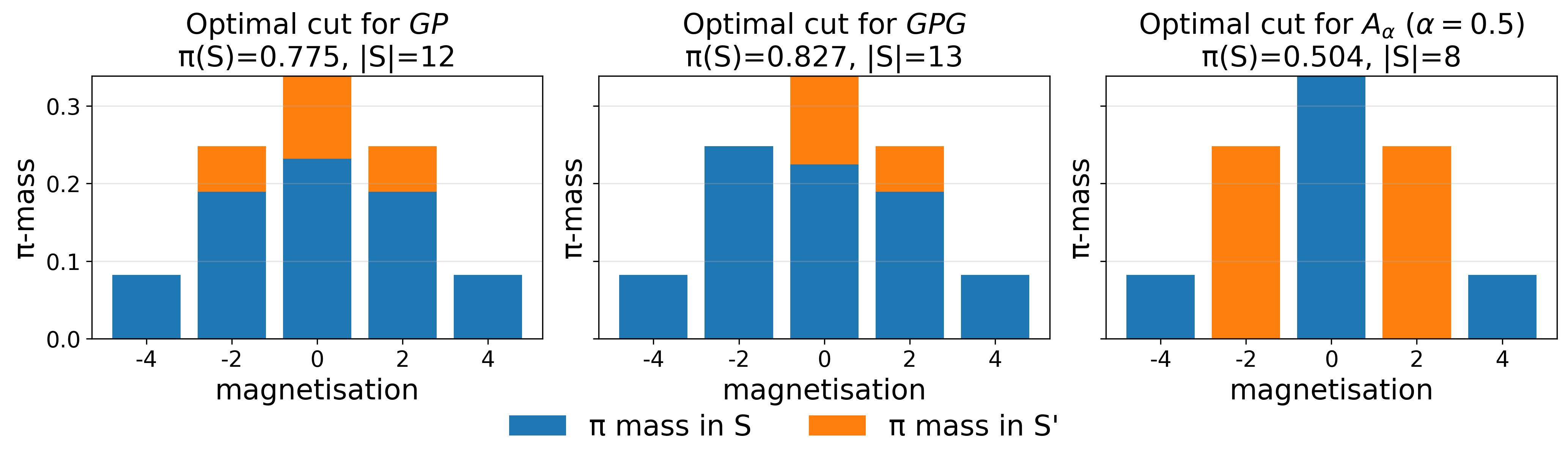
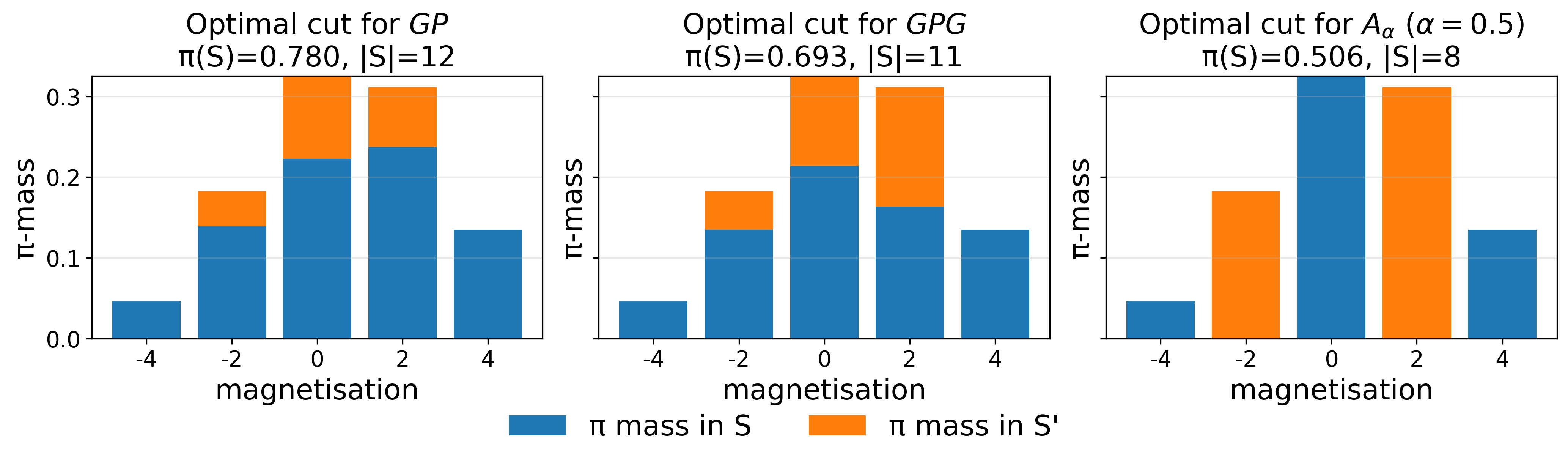
Figure 3: Magnetization profile of Frobenius-optimal cut for P2, P3 shows concentration on a small portion of the state space.
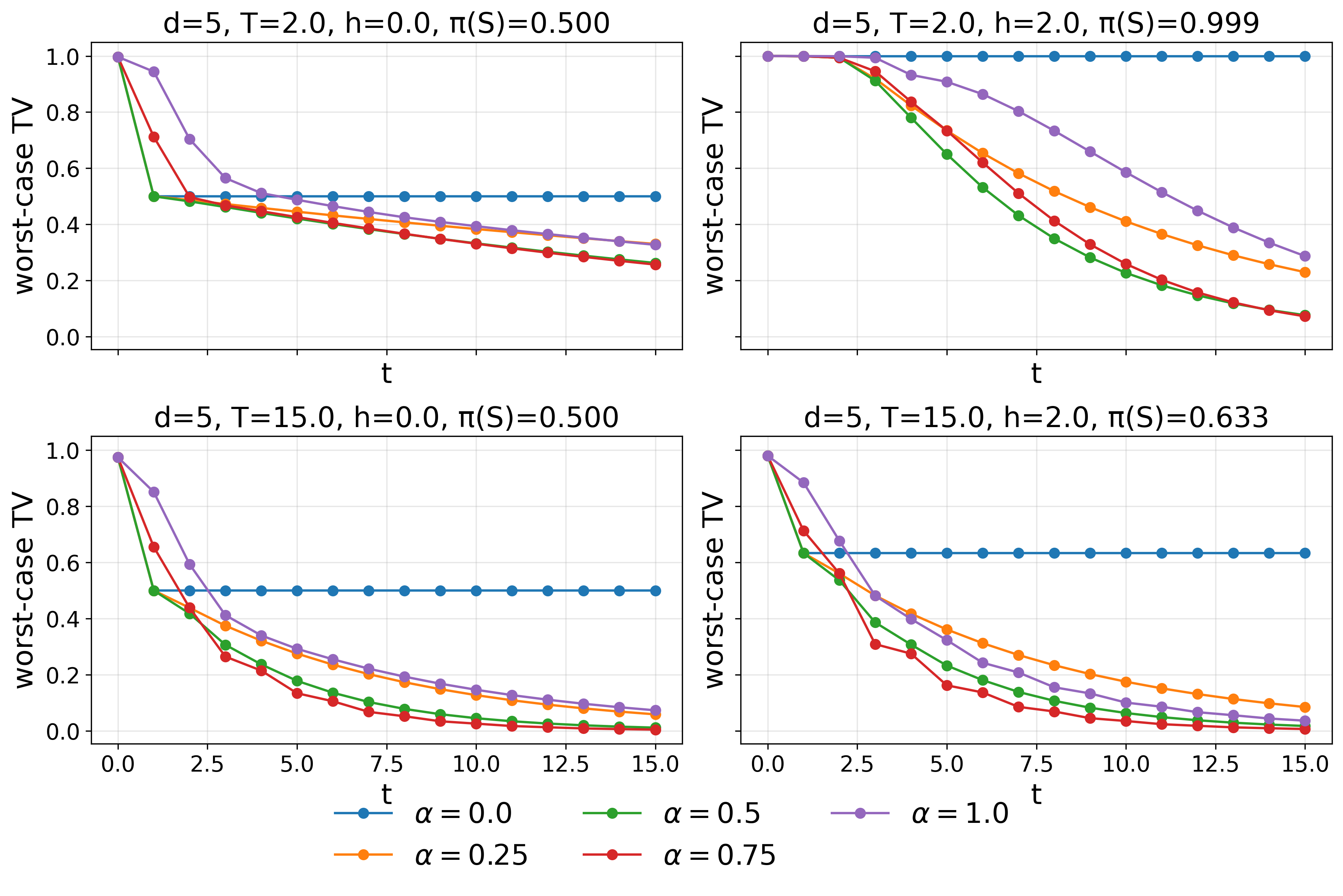
Figure 4: Worst-case total variation distance for P4 at varying P5 and fixed time P6, illustrating trade-offs in convergence speed.
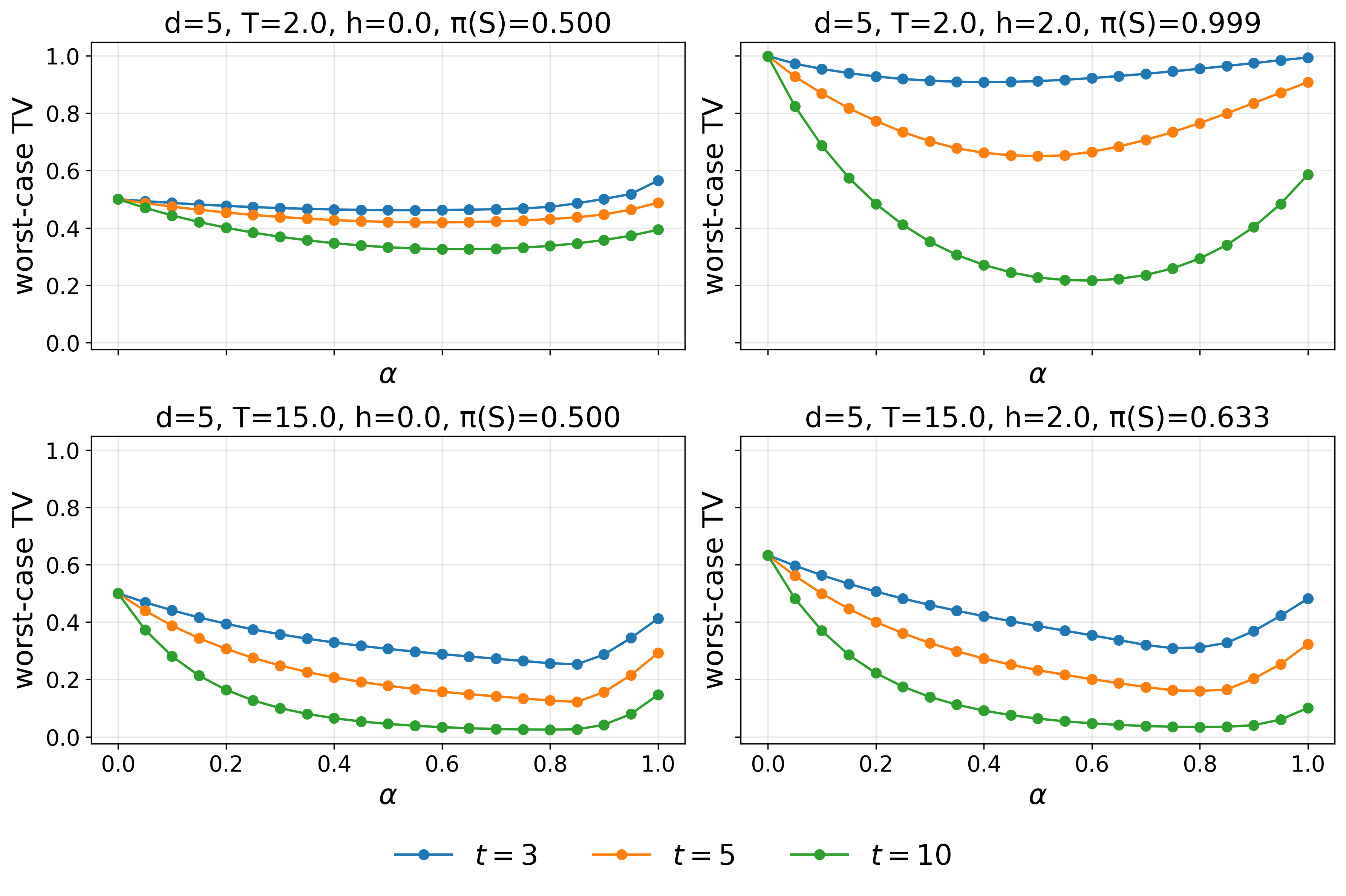
Figure 5: Dependence of worst-case total variation distance of P7 on P8 for selected time horizons, typifying the U-shaped effect of trade-off parameter.
Implications and Future Directions
The investigation substantiates the utility of additive mixtures for MCMC acceleration with strong theoretical underpinnings. The construction enables efficient, structure-informed randomization, avoids the cost of full composition-based group averages, and leverages aggressive partitioning without compromising reversibility.
Practical implications:
- The methodology is particularly germane for models with known bottlenecks or group symmetries, where block-structured partitions can be chosen efficiently.
- Trade-off tuning of P9 is central, and the theory provides explicit decay rates and guidance for practical parameter selection.
- Submodular techniques offer scalable heuristics even for combinatorially large state spaces.
Theoretical extensions:
- The lifted Markov chain construction admits further generalization, potentially facilitating non-reversible or higher-order additive mixtures.
- Difference-of-submodular optimization for other objectives or over larger partition classes remains an open direction, as do connections to advanced isoperimetric and spectral techniques in Markov chain geometry.
Conclusion
This work rigorously describes, analyzes, and empirically validates additive averaging kernel methods for finite-state Markov chains, bridging gaps between theory and computation. The partition optimization problem, formerly a combinatorial challenge, is rendered tractable via structural and submodular insights, and the explicit trade-offs between local exploration and global averaging are both characterized and exploited. The findings inform both principled MCMC design and broader inquiries into state space geometry and functional optimization in stochastic processes.