- The paper demonstrates an LLM-driven framework that integrates multi-agent summarization and graph-language fusion to robustly detect fraudulent accounts across heterogeneous blockchains.
- It introduces an alternating two-stage training protocol, combining RL fine-tuning for LLM summarization with dual-path GNN encoding to optimize detection performance and reduce manual feature engineering.
- Experimental results validate significant performance gains, effective zero-shot cross-chain generalization, and practical applicability to non-blockchain domains.
UniDetect: LLM-Based Universal Fraud Detection for Heterogeneous Blockchains
The increasing prevalence of cross-chain interoperability in decentralized finance (DeFi) ecosystems has enabled illicit actors to obfuscate fraudulent activities by seamlessly moving assets across multiple blockchains. Existing detection approaches are predominantly chain-specific, relying on domain-tailored feature engineering and constrained single-modality perspectives, resulting in poor generalization and scalability limits in the face of heterogeneous and multimodal transaction data. The authors of "UniDetect: LLM-Driven Universal Fraud Detection across Heterogeneous Blockchains" (2604.12329) address this challenge by proposing an LLM-driven universal fraud detection framework, UniDetect, capable of robustly identifying fraudulent accounts across diverse blockchain platforms with minimal reliance on manual feature crafting.
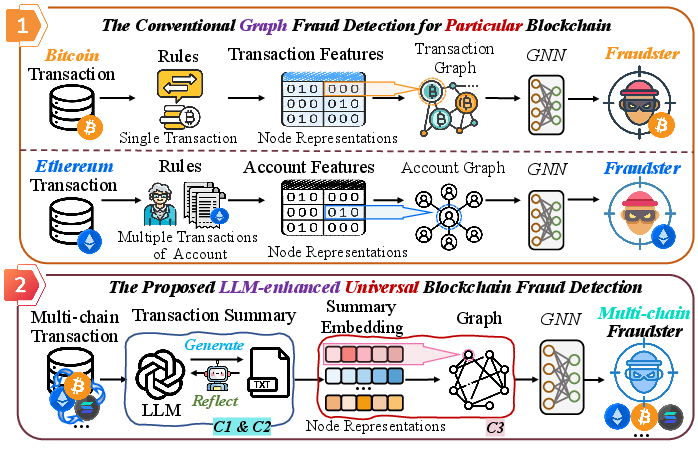
Figure 1: Comparison between chain-specific and LLM-based multi-chain fraud detection workflows, emphasizing the model’s universality and bypassing conventional feature engineering bottlenecks.
Methodology: Multi-Agent LLMs and Graph-Language Fusion
Subgraph Construction and Semantics-Preserving Compression
Scalability is achieved via account-centered subgraph construction using semantics-aware h-hop sampling based on transaction value, prioritizing transactionally relevant neighbors. Structural importance-guided graph compression (SIGC) prunes non-critical nodes by quantifying neighbor importance with a combined transactional and structural metric, striking a trade-off between informational sufficiency and computational feasibility.
LLM Transaction Summarization
Central to UniDetect is the deployment of an LLM-based forensics analysis agent, which receives as input transaction sequences and outputs generalizable account-level transaction summaries. Importantly, the agent is prompt-engineered to operate across heterogeneous blockchains, extracting cross-chain evidence and systematically eliminating data heterogeneity bottlenecks.
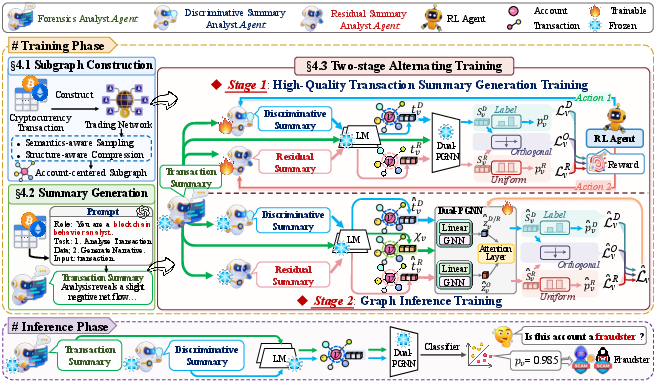
Figure 2: The end-to-end architecture, highlighting subgraph sampling, agent-driven transaction summary generation, and a two-stage graph-language training procedure.
Alternating Two-Stage Training and Multimodal Integration
A two-stage alternating training protocol is introduced to iteratively optimize both LLM summarization fidelity and graph-based discrimination:
- Stage 1 — High-Quality Summary Generation: The LLM backbone is fine-tuned via reinforcement learning (RL) (using LoRA for parameter efficiency), guided by an engineered tri-view loss comprising discriminative summary loss (supports fraud detection), residual summary loss (extracts non-task-relevant content), and orthogonality loss (separates latent factors). The discriminative summary analyst focuses on extracting actionable fraud cues, while the residual agent isolates noise and irrelevant factual statements.
- Stage 2 — Dual-Path GNN Training: With LLM parameters frozen, a Dual-PGNN encodes both discriminative and original summaries, fusing node features through an attention-weighted mechanism. This design ensures the injection of both self-features and contextual topological information into the final account embedding.
RL-Based Fine-Tuning Stability
Reward signals for LLM fine-tuning are derived from the negative exponential of the tri-view loss, with an EMA baseline stabilizing RL optimization and preventing catastrophic divergence.
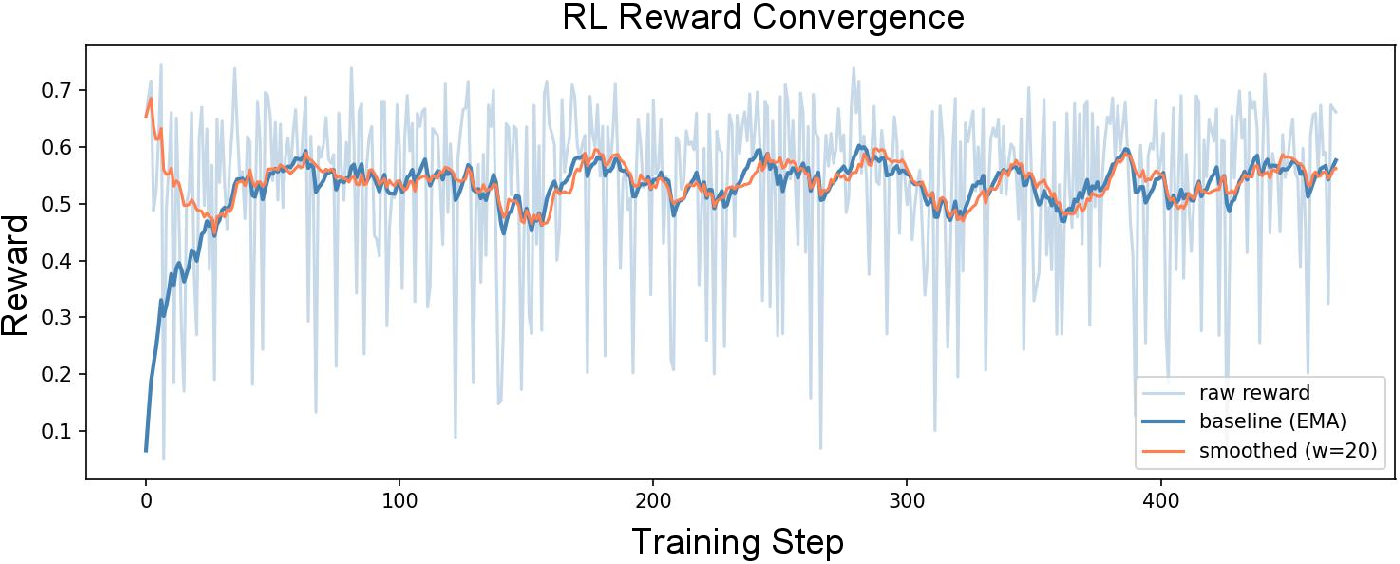
Figure 4: RL reward convergence during LLM fine-tuning stabilizes rapidly, confirming the robustness of the proposed optimization scheme.
Prompt Engineering
The forensic, discriminative, and residual summary agents operate atop chain-of-thought (CoT) prompts explicitly detailed for fraud-related semantic extraction, further reducing hallucination risk and ensuring agent outputs are both chain-agnostic and task-aligned.

Figure 5: CoT prompt template for the forensics analyst agent, structured to elicit actionable cross-chain transaction evidence.

Figure 6: Prompt templates for discriminative and residual summary agents enforce targeted content extraction and noise isolation, respectively.
Experimental Results: Effectiveness and Generalizability
Comprehensive experiments on multiple blockchains (Ethereum, Bitcoin-M, Bitcoin-L) confirm UniDetect delivers consistently superior performance over 20 state-of-the-art baselines, spanning classic GNNs, anomaly detectors, and both single-chain and multi-chain fraud models. Notably, strong results are reported:
- Ethereum: F1=92.65%; AUC=94.82%; KS=68.94%
- Bitcoin-M: F1=92.98%; AUC=93.83%; KS=70.45%
- Cross-chain (zero-shot): Fraudulent account detection rate > 94.58%
- Generalizes to non-blockchain domains (Instagram) with a 6.06% F1 improvement over best existing methods
Performance gains over the strongest baselines are substantial, with up to F1=92.65%0 F1=92.65%1 and F1=92.65%2 KS uplift, particularly in highly imbalanced settings. Ablation studies confirm the necessity of each architectural innovation: summary quality improvement, dual-path encoding, RL fine-tuning, and graph compression synergistically underpin the detection accuracy.
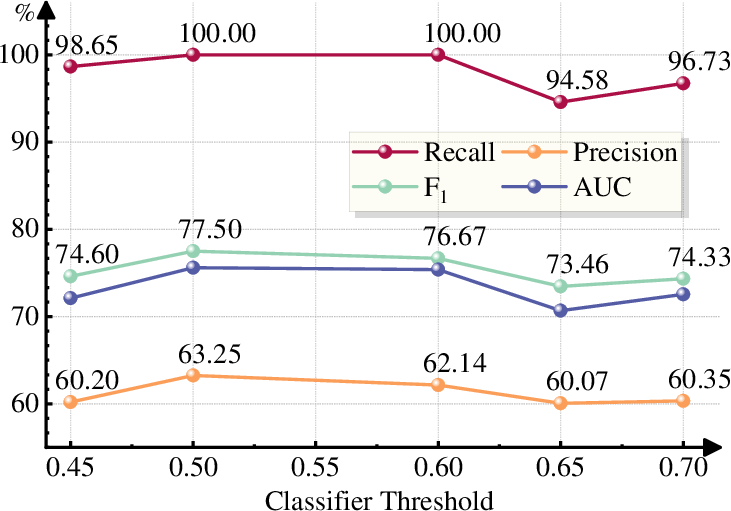
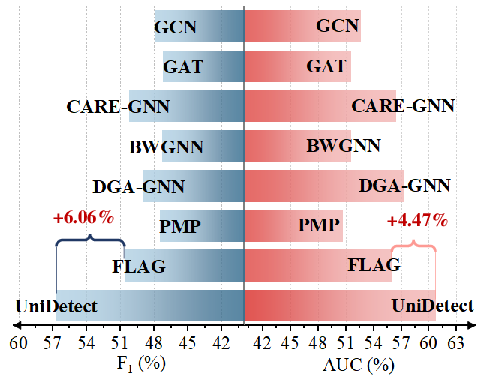
Figure 7: Cross-chain inference demonstrates UniDetect’s fraud detection robustness across chains with different structures, underscoring its universal fraud detection capability.
Generalization, Hyperparameter Robustness, and Efficiency
UniDetect’s zero-shot cross-chain transfer is empirically validated, with asymmetry reflecting sufficient fraud generalization and more modest precision in normal account detection, attributed to data-specific class priors and behavioral heterogeneity. Cross-domain experiments further verify the model’s adaptability beyond blockchain analytics.
Hyperparameter sensitivity analysis demonstrates stable F1=92.65%3 and KS results over a wide range of settings for subgraph size (F1=92.65%4), structural importance weighting (F1=92.65%5), and tri-view loss coefficients—indicating architectural robustness.
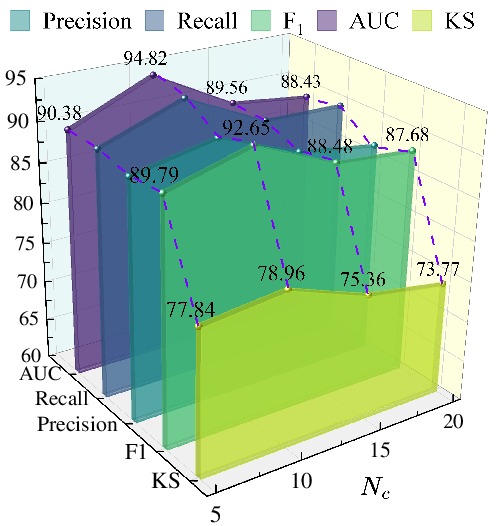
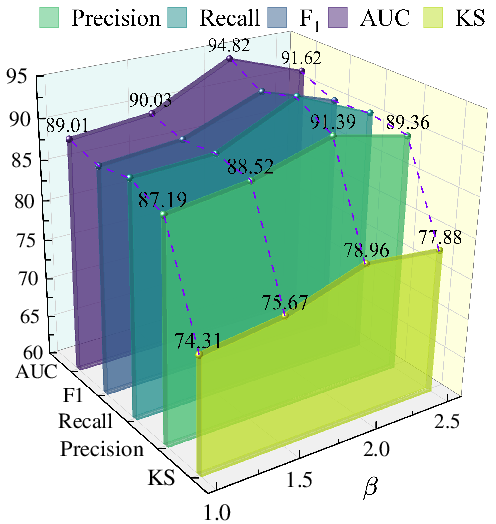
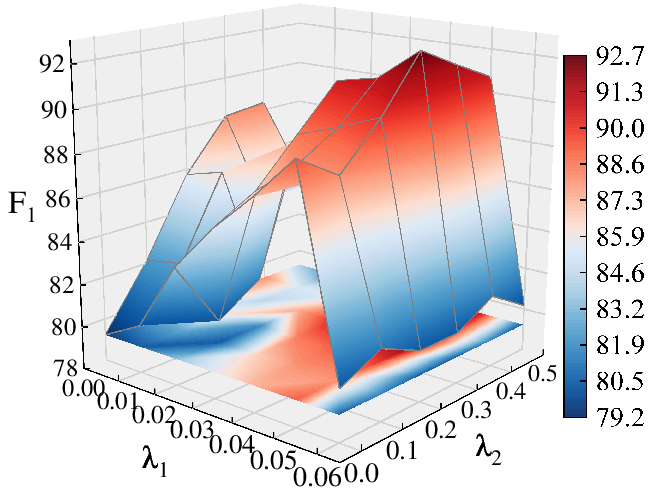
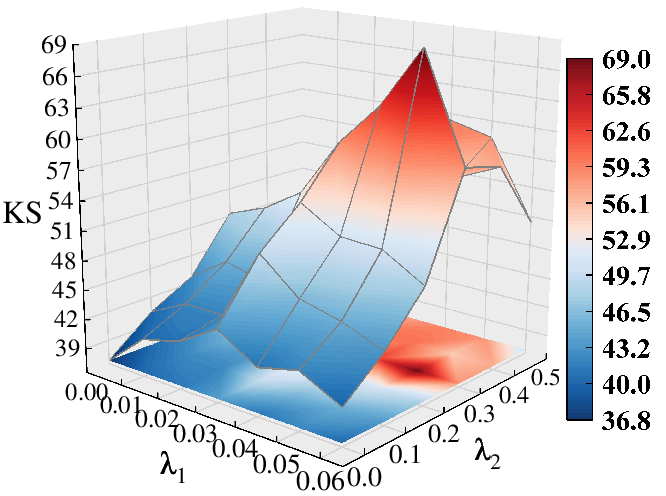
Figure 8: Hyperparameter sweep for F1=92.65%6 (subgraph size), showing a regime where stable, high performance is maintained.
From an engineering perspective, average per-account inference latency is 1.47 ms (680 samples/s), and LoRA-based low-rank adaptation slashes trainable parameters to 0.07% of the full LLM, confirming the practical deployability of the approach.
Case Study and Hallucination Mitigation
A qualitative case study on an Ethereum account illustrates the ability of UniDetect’s agents to extract discriminative, actionable fraud signals while filtering out over-inference and spurious LLM hallucinations—a critical property for high-stakes fraud detection and regulatory compliance.
Implications and Future Prospects
UniDetect demonstrates that LLM-powered, prompt-engineered multi-agent architectures can bridge the semantic, structural, and modal gaps inherent in multi-chain, real-world fraud detection. The universal feature abstraction and cross-modal integration represent a shift towards more generalized, adaptive AI agents in compliance-critical domains.
Theoretically, the fine-grained disentanglement of discriminative and residual summary channels points to avenues for interpretable graph-LLM fusion and robust out-of-distribution generalization. Practically, the autoscaling to large account graphs with minimal per-sample latency unlocks global, real-time fraud surveillance in rapidly evolving digital economies.
Anticipated future directions include tighter agent-level alignment with domain ontologies, adaptive graph-sampling strategies geographically or temporally informed by adversarial behaviors, and expansion to multi-modal, multi-task regimes beyond fraud (e.g., regulatory auditing, governance risk, or AML pipelines). Further reduction of RL sample inefficiency and hallucination risk at LLM scale remains an open challenge for both model developers and practitioners.
Conclusion
UniDetect establishes a generic, LLM-driven detection paradigm that achieves universal fraud detection across heterogeneous blockchain networks, combining agent-based summarization, modular graph encoding, and alternating multimodal optimization. Empirical results validate both its compelling accuracy and cross-domain generalizability, while its architectural modularity suggests extensibility for broader AI/graph-augmented reasoning in decentralized and dynamic transactional settings.