ResBM: Residual Bottleneck Models for Low-Bandwidth Pipeline Parallelism
Abstract: Unlocking large-scale low-bandwidth decentralized training has the potential to utilize otherwise untapped compute resources. In centralized settings, large-scale multi-node training is primarily enabled by data and pipeline parallelism, two techniques that require ultra-high-bandwidth communication. While efficient methods now exist for decentralized data parallelism, pipeline parallelism remains the primary challenge. Recent efforts, such as Subspace Models (SM), have claimed up to 100x activation compression but rely on complex constrained optimization and diverge from true end-to-end training. In this paper, we propose a different approach, based on an architecture designed from the ground up to be native to low-bandwidth communication environments while still applicable to any standard transformer-based architecture. We call this architecture the Residual Bottleneck Model or ResBM, it introduces a residual encoder-decoder bottleneck module across pipeline boundaries that can be trained end-to-end as part of the model's parameters while preserving an explicit low-rank identity path. We show that ResBMs achieve state-of-the-art 128x activation compression without significant loss in convergence rates and without significant memory or compute overhead.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about a new way to train very large AI models (like chatbots) when computers are connected by slow internet. Normally, training these models across many machines needs super‑fast network cables because the machines pass lots of data back and forth. The authors propose a model design called a Residual Bottleneck Model (ResBM) that squeezes the data before sending it and then rebuilds it on the other side—without hurting learning. Think of it like zipping files before emailing them, but built directly into the model itself.
What questions are the researchers trying to answer?
The paper asks three simple questions:
- Can we shrink the data sent between machines by about 100–128 times and still train the model well?
- Can we do this with normal training tools, without complicated extra steps?
- Which training method (optimizer) makes this easier: AdamW or Muon?
How does their approach work?
First, some quick explanations in everyday language:
- Pipeline parallelism: Imagine a factory line. Each machine handles a few “layers” of the model and passes its work (called “activations”) to the next machine. Passing these activations needs lots of network bandwidth.
- Activations: These are the intermediate results a model creates while it thinks—like notes passed between steps in a recipe.
- Residual (identity) connection: This is a shortcut path that lets information flow straight through layers. It keeps training stable—like a safety lane on a highway.
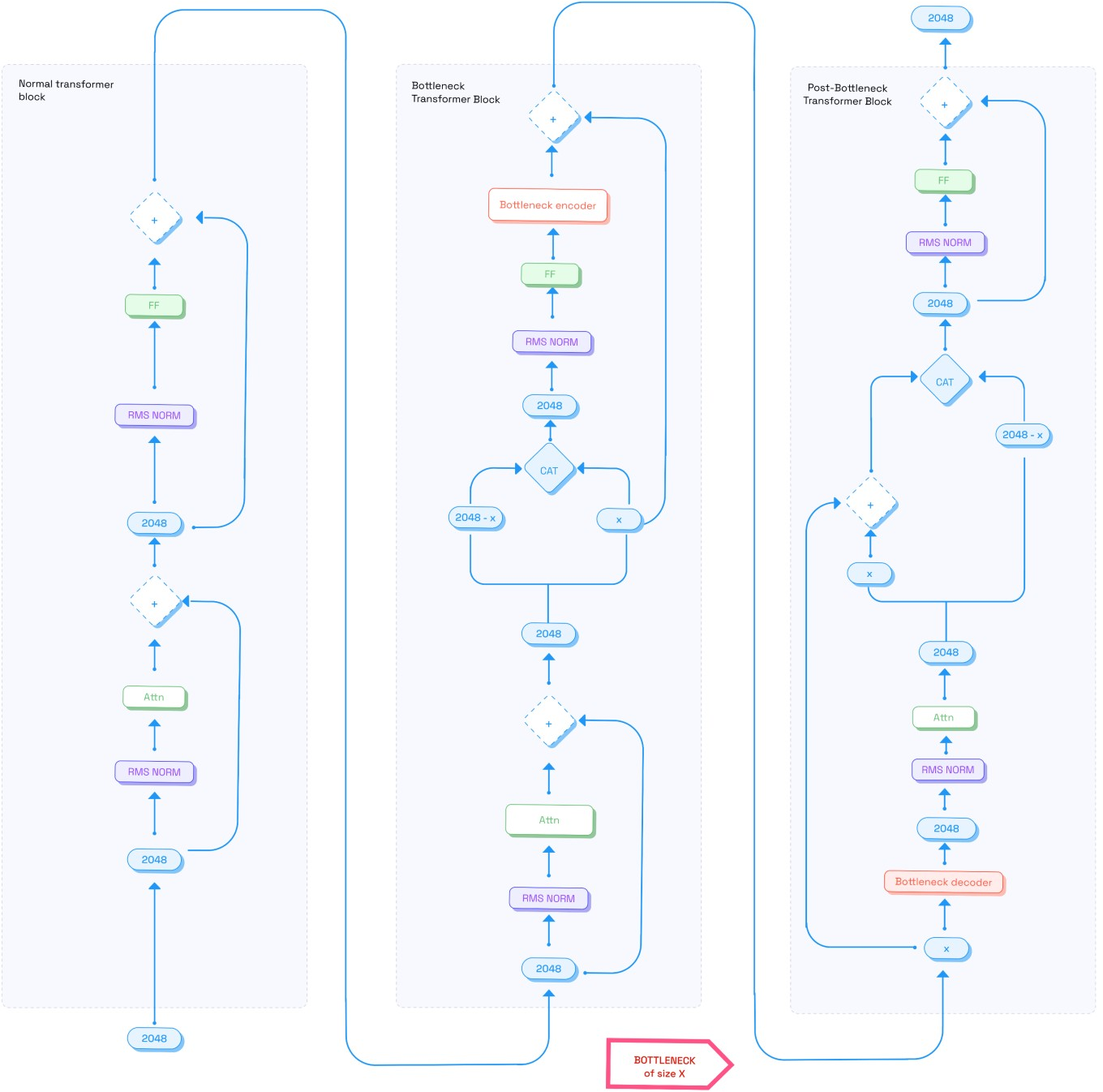
What ResBM does:
- A bottleneck “zipper” at the boundary: After a block finishes, the model runs the activations through an encoder that compresses them into a much smaller form. Only this tiny version is sent over the network. On the other side, a decoder rebuilds them for the next block.
- Preserve the shortcut: Crucially, the shortcut (identity) path stays clean and reliable. The compression runs alongside it, not on top of it, so training doesn’t become unstable. You can think of it as adding a narrow tunnel for the main traffic while keeping a reliable footbridge open, so messages still get through safely.
- Train end‑to‑end: The encoder and decoder are trained together with the rest of the model—no special solvers or separate, tricky updates.
They compare ResBM to a previous idea called “Subspace Models (SM).” SM also tries to send smaller messages by forcing the model to use a shared low‑rank space, but it needs more complicated math and special optimization steps. ResBM avoids that, keeping everything simple and standard.
What did they find, and why does it matter?
Key results and why they’re important:
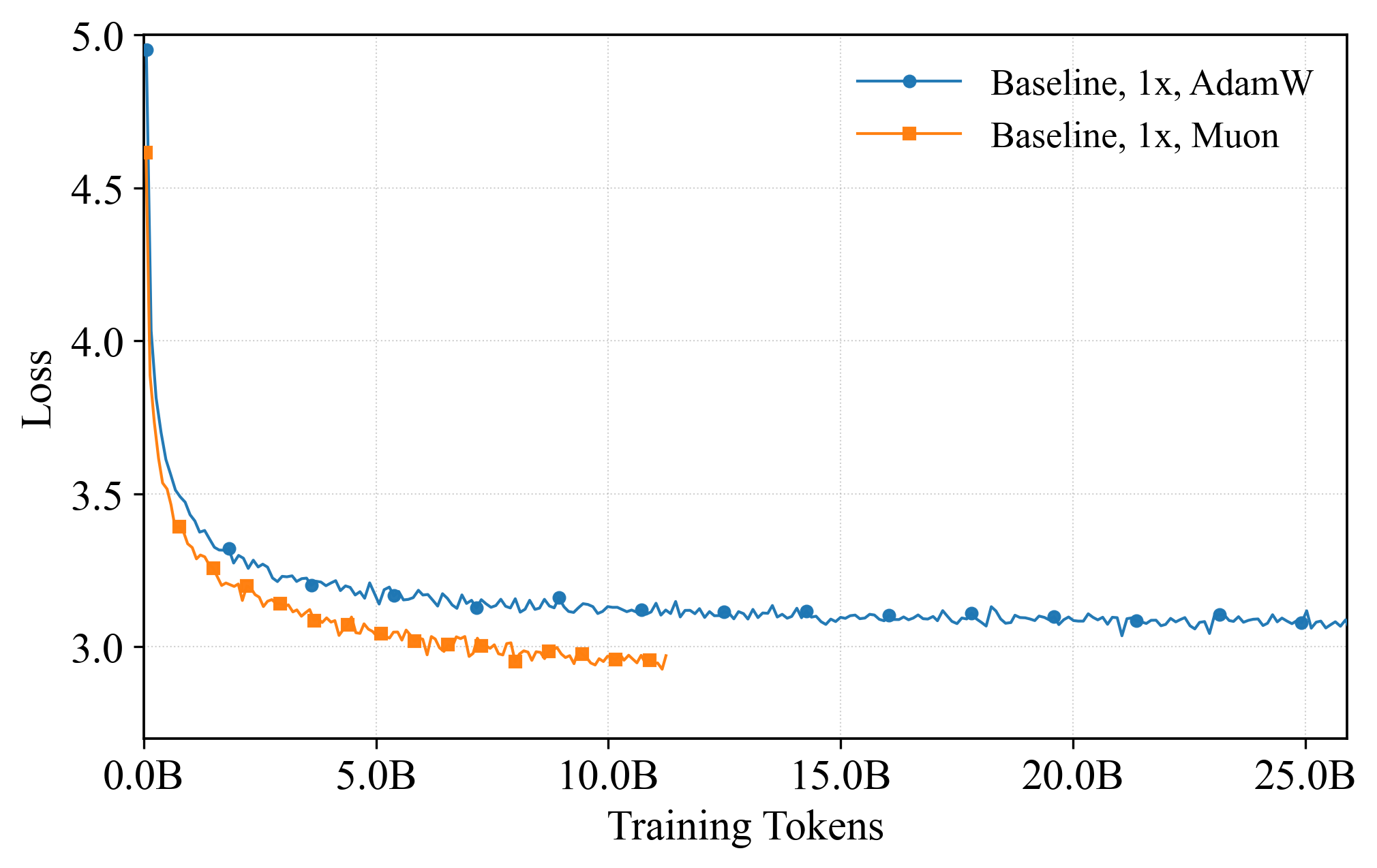
- Very high compression without hurting learning: ResBM reached about 128× compression of activations and still matched the training progress (convergence) of a normal, uncompressed model. This is a big deal because sending 128× less data can make slow internet good enough for large‑scale training.
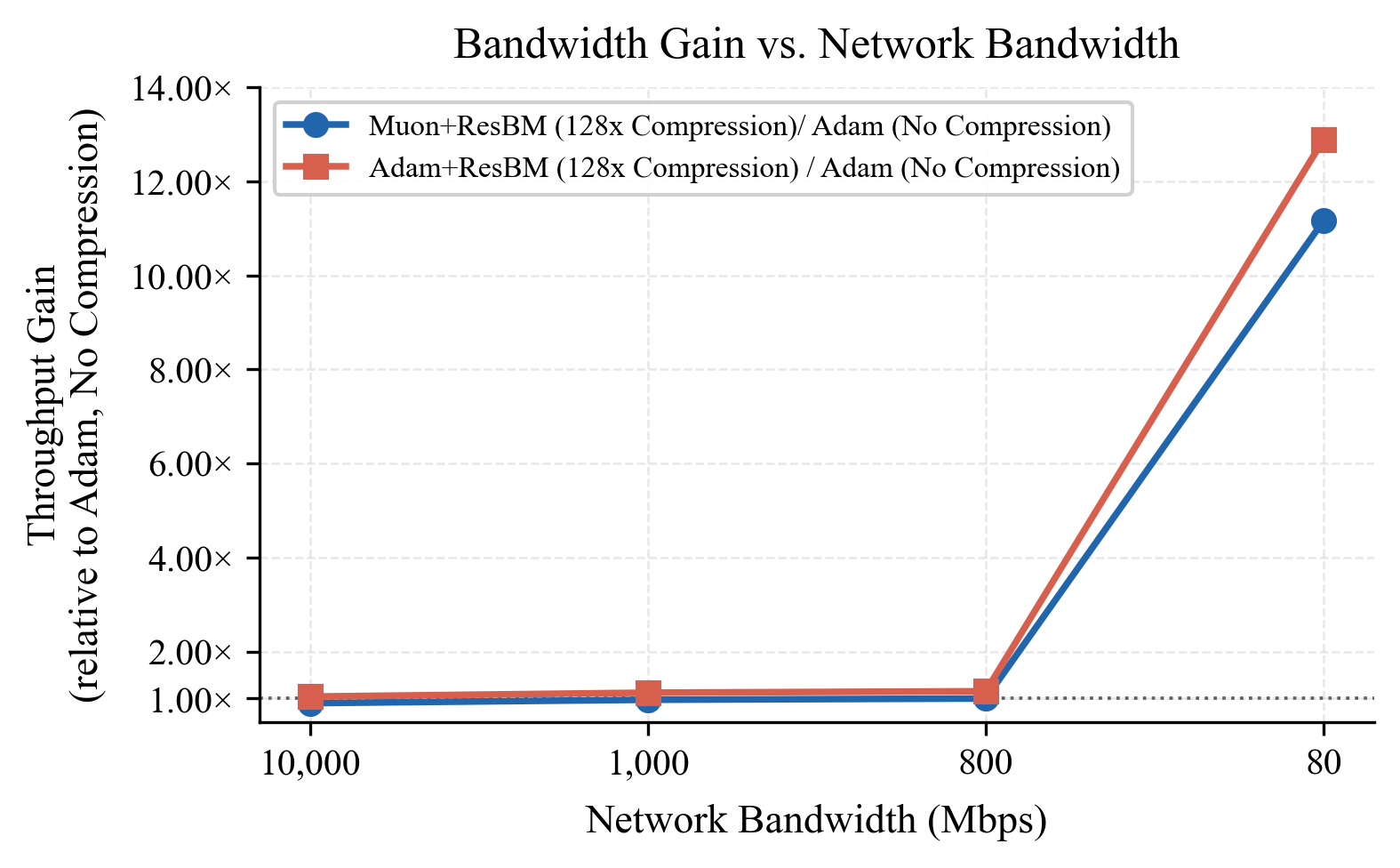
- Faster training over slow links: On an 80 Mbps internet link (much slower than datacenter networks), ResBM recovered almost the same training speed as a 10 Gbps datacenter run. In other words, the “zip it, send it, rebuild it” plan works in practice.
- Small overhead: Adding the bottlenecks increased the number of model parameters by only about 3.3% and added little extra compute, but it slashed communication per step from about 112 MiB to about 0.9 MiB at 128× compression.
- Outperformed the previous best (SM): Under similar conditions, ResBM did better than Subspace Models while being simpler to train.
- Optimizer choice matters:
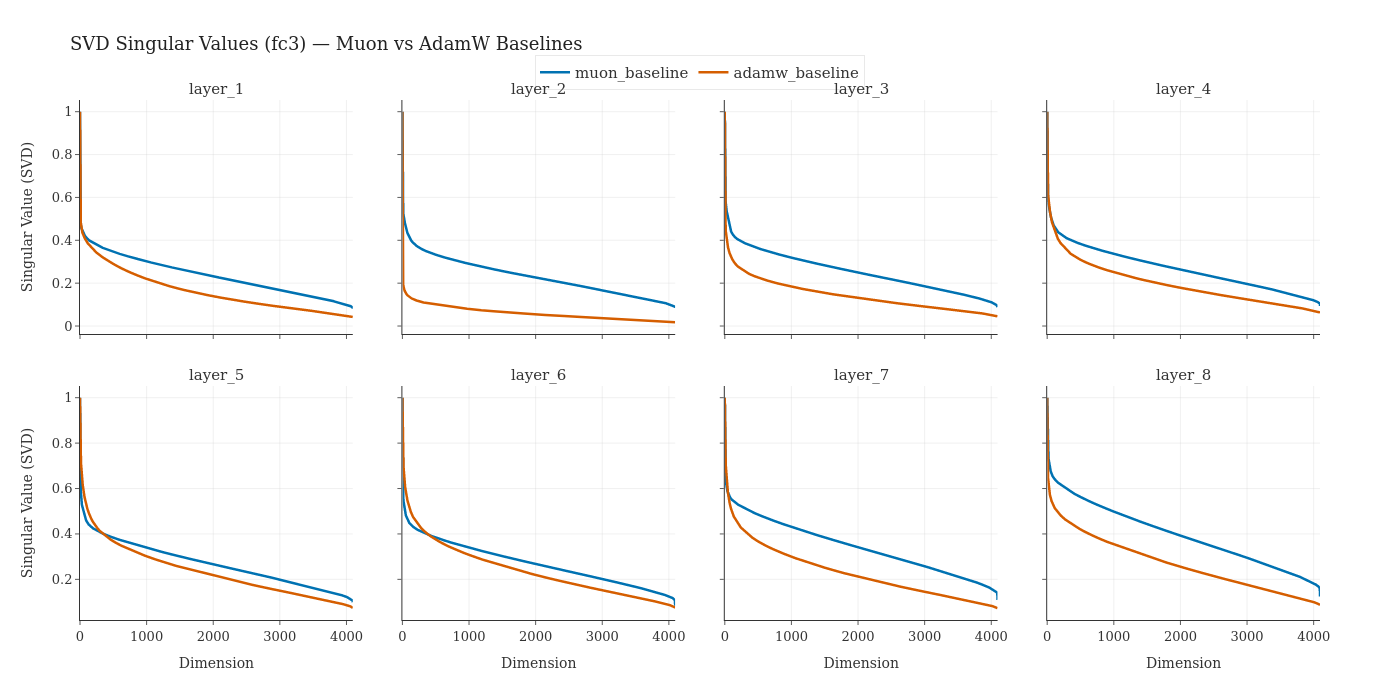
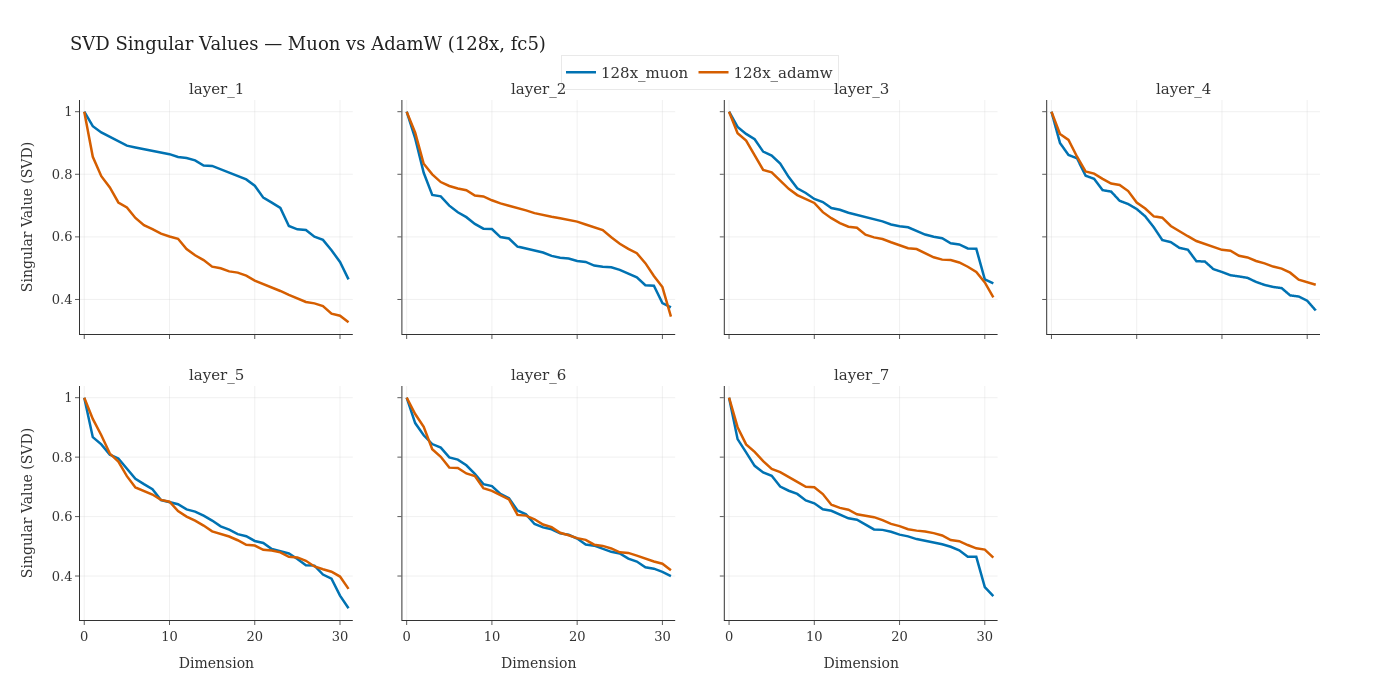
- AdamW (a common training method) naturally makes model signals more low‑rank (roughly: more compressible), which helps compression.
- Muon (another optimizer) keeps representations higher‑rank (richer), which can slow compression, but in compressed models it helped keep more information through the tiny bottleneck. In their tests, compressed ResBM often did best when trained with Muon.
Why this matters: If models can communicate far less data between machines without losing quality, we can train huge models on cheaper, widely spread computers over the public internet—not just in expensive datacenters.
What are the bigger implications?
- Wider access to AI training: Teams without supercomputers could still train big models by connecting regular machines over normal internet connections.
- Simpler engineering: Because ResBM uses standard, end‑to‑end training with off‑the‑shelf optimizers, it’s easier to adopt than methods that need special math and custom training loops.
- Scales with model size: As models get bigger, the amount of useful computation grows faster than the communication needed (the authors mention a “square‑cube law” intuition), which makes this kind of compression even more helpful.
- Next steps: Test ResBM on larger models and more tasks, and keep refining how optimizers interact with compression so we preserve as much information as possible through the bottleneck.
In short, the paper shows a practical, model‑design fix—ResBM—that cuts communication by around 128× while keeping training stable and effective. That could make decentralized, low‑cost training of big AI models much more realistic.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain, missing, or unexplored in the paper, phrased to guide concrete follow-up work.
- Scaling beyond 2B parameters and 8 pipeline stages
- No evidence that ResBM maintains convergence/throughput gains at larger scales (e.g., 7B–70B+), deeper pipelines, or wider hidden dimensions where compression and identity-path interactions may differ.
- Open: Run controlled scale-up studies measuring loss, gradient norms, and communication overlap for deeper/larger models and more pipeline stages.
- Generalization beyond C4 and pretraining perplexity
- Evaluation is limited to language modeling on C4 and final perplexity; no downstream task performance (e.g., GLUE, MMLU, code, instruction-following) or domain shift tests.
- Open: Assess transfer and robustness on diverse corpora and standard downstream benchmarks to confirm that extreme bottlenecks preserve task-relevant information.
- Long-context behavior and sequence-length scaling
- All experiments use context length 1024; effects of compression on long-context attention dynamics (e.g., 8K–128K) and KV-cache behavior are not tested.
- Open: Measure perplexity and retrieval/long-range reasoning performance as sequence length increases, and study whether bottlenecks degrade long-range dependencies.
- Fairness and confounding in optimizer comparisons
- Core claims compare a ResBM+Muon model to an uncompressed AdamW baseline; optimizer choice is a major confounder. While some cross-optimizer comparisons are shown, the longest training runs switch optimizers between baseline and compressed models.
- Open: Provide apples-to-apples comparisons (ResBM vs. baseline under the same optimizer and hyperparameters) and quantify Muon’s compute overhead vs. its convergence benefits.
- Limited analysis of backward-pass fidelity
- While forward activations are compressed and reconstructable via the decoder, the paper does not quantify backward-pass gradient distortion or error accumulation at pipeline boundaries.
- Open: Directly measure gradient mismatch (e.g., cosine similarity/L2) across boundaries, its depth-wise accumulation, and its correlation with optimization stability.
- Theoretical guarantees for identity path and stability
- The rectangular identity projection is argued to preserve “identity” along k dimensions, but no formal analysis (e.g., Lipschitz bounds, gradient norms, stability conditions) is provided for the composed encoder/decoder and identity projection in deep stacks.
- Open: Develop theory and diagnostics (e.g., layerwise Jacobians, singular values) to prove or falsify stability guarantees under dimension-changing identity paths.
- Design choices of the bottleneck module remain underexplored
- Encoder/decoder architecture (two-layer MLP with a nonlinearity) is fixed without ablations: hidden widths, nonlinearity type, normalization, residual scaling, placement (after FFN only), and number of bottlenecks per block are not varied.
- Open: Systematic ablations on bottleneck design, placement (after attention vs. after FFN), frequency (every N blocks), and regularization/initialization strategies.
- Fixed, uniform compression across layers and time
- All layers use the same static bottleneck dimension; there is no exploration of per-layer heterogeneity or adaptive schedules (e.g., curriculum compression, dynamic token-/layer-wise h).
- Open: Learn or schedule per-layer bottleneck sizes conditioned on activations/gradients or training phase to optimize accuracy vs. bandwidth.
- Identity projection choice and subspace alignment
- The identity path uses truncation/zero-padding via a rectangular identity matrix, implicitly privileging the first c coordinates; no mechanism aligns learned features to the retained subspace.
- Open: Explore learned or orthonormal identity projections, permutations, or rotation layers to align the preserved subspace with salient features; measure benefits vs. simple truncation.
- Interaction with other efficiency methods
- The paper does not evaluate synergy with activation/weight quantization, sparsity, PowerSGD/GaLore-like gradient projections, activation checkpointing, KV-cache compression, or MoE.
- Open: Compose ResBM with these methods to push beyond 128× and quantify trade-offs in accuracy, FLOPs, memory, and bandwidth.
- Upper limits and regimes for compression
- Target bandwidth gaps of ~300× are discussed, but experiments cap at 128×; the practical/accuracy limits and failure modes of 200–300× compression are unknown.
- Open: Stress-test higher compression factors, map out accuracy–compression Pareto frontiers, and identify architecture/optimizer modifications needed beyond 128×.
- Realistic decentralized conditions and fault tolerance
- Throughput tests use NCCL over controlled links (10 Gbps, 80 Mbps); real-world internet conditions (latency, jitter, packet loss, heterogeneity, churn) and compatibility with SWARM-like schedulers are untested.
- Open: Evaluate ResBM across real WANs and with fault-tolerant decentralized schedulers, profiling pipeline bubbles, straggler sensitivity, and robustness to node failures.
- Compute and energy accounting
- Parameter overhead is reported (~3.3%), but added FLOPs, memory bandwidth pressure, latency of encoder/decoder, and energy costs (especially with Muon) are not quantified.
- Open: Provide full-system profiles (FLOPs, memory, latency, energy) and identify when ResBM becomes compute-bound vs. network-bound across bandwidth regimes.
- Inference-time implications
- The work focuses on training; it is unclear how bottlenecks affect inference latency, memory, and multi-node serving when activations must traverse stages forward-only.
- Open: Benchmark multi-node inference with ResBM (e.g., token latency, throughput, memory) and assess whether encoder/decoder overhead is amortized in deployment.
- Robustness across architectures and modalities
- Claims of applicability are not substantiated beyond a Llama-3-like 2B model; no tests on decoder-only vs. encoder–decoder, MoE, multimodal, or vision transformers.
- Open: Port ResBM to varied architectures (e.g., MoE, ViT, speech/multimodal) to evaluate generality and modality-specific bottleneck behavior.
- Sensitivity to hyperparameters and training stability
- No multi-seed variability, hyperparameter sweeps, or stability metrics are reported (e.g., loss spikes, gradient clipping rates) under extreme compression.
- Open: Conduct robustness studies across seeds and hyperparameters (LR, warmup, weight decay, norm layers) to chart stable operating regions.
- Reproducibility and SM comparison fidelity
- SM results rely on an in-house implementation with unspecified choices; given the complexity (Grassmannian updates, constrained AdamW), discrepancies may arise.
- Open: Release code and reproducible configs for both ResBM and SM baselines; align optimizer constraints to verify relative performance.
- Missing details and typos in mathematical formulation
- Some equations (e.g., generalized residual update, composition of identity projections) contain typos/missing brackets; formal definitions and proofs are incomplete.
- Open: Provide corrected, rigorous formulations and proofs (e.g., properties of composed rectangular identities in deep stacks and their effect on residual learning).
- Combined parallelism regimes
- Interaction of ResBM with data parallelism, optimizer/state sharding (ZeRO), and hybrid PP–DP strategies is not empirically evaluated.
- Open: Measure end-to-end throughput and convergence with hybrid DP/PP setups and optimizer sharding to ensure compatibility in practical large-scale training.
- Security and trust in untrusted environments
- Although motivated by decentralized training, the paper does not address correctness/robustness under adversarial or faulty participants, or integrity checks for compressed activations.
- Open: Investigate secure aggregation/verification for activation streams in trustless settings and the effect of adversarial noise on compressed pathways.
Practical Applications
Practical Applications of Residual Bottleneck Models (ResBM)
Below are actionable applications derived from the paper’s findings and methods. Each item notes sectors, potential tools/products/workflows, and assumptions or dependencies affecting feasibility.
Immediate Applications
These can be piloted or deployed now using existing frameworks and commodity networks.
- Decentralized LLM pretraining across internet-grade links
- Sectors: software, cloud, open-source AI
- What: Run pipeline-parallel LLM training over 80–1000 Mbps links by inserting ResBM encoder/decoder at stage boundaries to achieve ~128× activation/gradient compression with near-baseline convergence and throughput.
- Tools/Products/Workflows:
- PyTorch modules implementing ResBM blocks (encoder/decoder) for pipeline cuts
- Plugins for Megatron-LM, DeepSpeed, ColossalAI, or Hugging Face Accelerate to toggle compression ratios and stage placement
- Bandwidth-aware schedulers (e.g., SWARM-like) to route microbatches around slow nodes
- Assumptions/Dependencies:
- Pipeline parallelism already in use; internet latency variability manageable
- Best results with Muon for compressed models (preserves rank); AdamW baseline remains comparison standard
- Security (TLS), node reliability, and checkpointing addressed by orchestration layer
- Cost-optimized training on Ethernet-only or multi-AZ/region cloud clusters
- Sectors: cloud providers, enterprise AI, finance/retail tech
- What: Avoid NVLink/InfiniBand by using standard 1–10 Gbps Ethernet while maintaining throughput via 100–128× activation compression.
- Tools/Products/Workflows:
- “Low-bandwidth pipeline-parallel” training SKUs for cloud users
- Templates that auto-insert ResBM stages at model boundaries; auto-tune bottleneck dimension (e.g., 32–64)
- Integration with Ray Train or Kubernetes operators for distributed schedulers
- Assumptions/Dependencies:
- Modest ~3.3% parameter overhead acceptable; minor per-step compute overhead
- Accurate profiling to balance microbatching and stage depths
- University and SME training on commodity networks
- Sectors: academia, startups/SMEs
- What: Train ~2B-parameter LLMs across lab GPUs connected by 1 Gbps campus networks or VPNs; reduce inter-stage transfer from ~112 MiB to ~0.9 MiB per step at 128×.
- Tools/Products/Workflows:
- Campus-ready MLOps recipes (Ansible/Terraform + PyTorch/DeepSpeed) with ResBM blocks
- Compression-aware training dashboards to monitor TPS and loss vs time
- Assumptions/Dependencies:
- Institutional networking policies and NAT traversal (e.g., WireGuard) in place
- Stable availability of participating GPUs and basic fault tolerance
- Cross-site training with data locality for regulated domains
- Sectors: healthcare, finance, public sector
- What: Pipeline partitions across on-prem/data-center boundaries so sensitive data stays local while activations traverse compressed, encrypted links.
- Tools/Products/Workflows:
- Secure transport for compressed activations (mTLS), role-based access, audit trails
- Integration with policy engines for data sovereignty and access control
- Assumptions/Dependencies:
- Legal approval for cross-site activation sharing; trust or verification layer for partner nodes
- Additional privacy safeguards (DP, secure enclaves) may be required
- Integration into existing distributed training stacks
- Sectors: software tooling, MLOps
- What: Add ResBM as a first-class module in pipeline engines (DeepSpeed, PyTorch Distributed, ColossalAI).
- Tools/Products/Workflows:
- “ResBM-ready” pipeline wrappers, CLI flags to set compression (e.g., --resbm-compression 128)
- Auto-tuning utilities that choose bottleneck dimension per boundary based on activation spectra
- Assumptions/Dependencies:
- Minimal code changes at stage boundaries; correctness tests for gradient propagation via identity path
- Bandwidth-aware scheduling and monitoring
- Sectors: cloud ops, devops for ML
- What: Scheduling policies and dashboards that adapt microbatch routing and compression to measured link bandwidth/latency.
- Tools/Products/Workflows:
- Observability packages collecting per-stage transfer size, stall time, and effective TPS
- Policies to downgrade compression when training instability is detected
- Assumptions/Dependencies:
- Accurate network telemetry; small overhead from monitoring agents
- Community/volunteer compute for open LLMs
- Sectors: open-source AI, civic tech
- What: Allow contributors with consumer GPUs/links to host pipeline stages; compressed activations enable participation over ~80 Mbps.
- Tools/Products/Workflows:
- Trust/reputation scoring, checkpoint redundancy, payout/credit systems
- Containerized stage images with ResBM pre-wired, NAT-friendly networking
- Assumptions/Dependencies:
- Churn/fault tolerance (e.g., SWARM-like routing); content and data-use policies
Long-Term Applications
These require further R&D, scaling, standardization, or ecosystem maturation.
- Internet-scale training of frontier models across heterogeneous nodes
- Sectors: cloud hyperscalers, open research consortia
- What: Combine ResBM with quantization, sparsity, and scheduling to approach ~300× effective compression across larger models and deeper pipelines.
- Tools/Products/Workflows:
- Multi-tenant, geo-distributed training platforms with dynamic stage placement
- Co-optimizers that adapt compression per layer and training phase
- Assumptions/Dependencies:
- Validation at >10B–100B+ parameter scales; robustness under highly variable links and failure rates
- Hardware and interconnect co-design for compressed activation streams
- Sectors: semiconductors, networking, systems
- What: NICs/accelerators with on-die ResBM encoder/decoder blocks; DMA paths optimized for small compressed tensors.
- Tools/Products/Workflows:
- Firmware and kernel drivers exposing “compressed activation channels”
- Compiler support to place pipeline cuts aligned with hardware blocks
- Assumptions/Dependencies:
- Vendor adoption; standard APIs for compressed activation formats
- Standards for compressed activation protocols and interoperability
- Sectors: standards bodies, ML frameworks
- What: Open specs for activation-stream formats, metadata, and integrity checking to interoperate across frameworks and vendors.
- Tools/Products/Workflows:
- Reference implementations in PyTorch/JAX/TF
- Compliance test suites and fuzzers for correctness under packet loss
- Assumptions/Dependencies:
- Broad community participation; backward compatibility with existing pipelines
- Optimizer/architecture co-design for compression-aware training
- Sectors: ML research, software
- What: New optimizers that maximize information flow through bottlenecks (e.g., Muon variants), adaptive bottleneck scheduling, layerwise rank targets.
- Tools/Products/Workflows:
- AutoML agents that tune per-boundary h values based on spectral feedback
- Curriculum strategies: start wide, increase compression as training stabilizes
- Assumptions/Dependencies:
- The interplay between optimizer-induced rank dynamics and task-specific generalization remains an active research area
- Edge-to-cloud collaborative pretraining for robotics and IoT
- Sectors: robotics, manufacturing, smart devices
- What: Continuous pretraining/fine-tuning where fleets (drones, robots, vehicles) serve as pipeline stages or data sources; compressed activations reduce backhaul.
- Tools/Products/Workflows:
- MLOps for intermittent connectivity, delayed gradients, and on-device partial stages
- Safety layers for actuation models under compression constraints
- Assumptions/Dependencies:
- Reliability/security at the edge; trading off latency vs training throughput
- Privacy-preserving compressed activation sharing
- Sectors: healthcare, finance, public sector
- What: Combine ResBM with differential privacy, secure enclaves, or partially homomorphic encryption to share compressed activations with formal guarantees.
- Tools/Products/Workflows:
- Noise-addition schedulers tuned to bottleneck dimension
- Secure enclaves for decoder stages with attestation
- Assumptions/Dependencies:
- Overhead from cryptography/DP; impact on convergence must be re-evaluated
- Cross-organization foundation-model consortia
- Sectors: policy, academia–industry partnerships
- What: Multi-institution training with governance and incentive mechanisms where compressed activations reduce bandwidth and costs for members.
- Tools/Products/Workflows:
- Legal frameworks for model IP, auditing of contributions, and benefit-sharing
- Federated pipeline agreements and compliance tooling
- Assumptions/Dependencies:
- Clear liability and data-sharing agreements; measurement and attribution mechanisms
- Applying ResBM beyond transformers
- Sectors: vision, speech, science/engineering
- What: Extend identity-preserving bottlenecks to diffusion models, GNNs, and large scientific models (climate, protein, CFD).
- Tools/Products/Workflows:
- Architecture templates showing safe placement of bottlenecks that respect “identity path” constraints in non-transformers
- Assumptions/Dependencies:
- Empirical validation of convergence and accuracy per domain; new projection operators for non-residual topologies
- Green AI and sustainability policy levers
- Sectors: policy, sustainability
- What: Encourage compressed-communication training to reduce energy use and dependence on specialized interconnects.
- Tools/Products/Workflows:
- Reporting standards for “communication intensity” and energy per trained token
- Incentive programs for low-bandwidth training in research grants
- Assumptions/Dependencies:
- Credible measurement frameworks; alignment with broader carbon accounting methods
- Productized “ResBM-ready” training-as-a-service
- Sectors: cloud, MLOps SaaS
- What: Managed platforms that expose sliders for compression ratio, automatic optimizer selection, and resilience out of the box.
- Tools/Products/Workflows:
- One-click deployment across multi-region commodity instances
- SLAs that include bandwidth adaptation and fault tolerance
- Assumptions/Dependencies:
- Demand for large-scale training without premium interconnects; support contracts and observability maturity
Notes on feasibility and dependencies across applications:
- Empirical evidence is strongest at ~2B parameters on C4 with pipeline-parallel GPipe and shows near-baseline convergence at 100–128× compression; generalization to larger scales and other tasks is a stated future direction.
- Compressed models benefit from Muon due to higher-rank activations; using AdamW for compressed models risks underutilizing bottlenecks.
- Network variance, security, and fault tolerance remain key practical concerns for decentralized deployments.
- Identity-path preservation is central to stability; correct placement and projection operators are required to avoid optimization degradation.
Glossary
- Activation compression: Reducing the size (dimensionality or precision) of activations communicated between pipeline stages to save bandwidth. "ResBMs achieve state-of-the-art 128× activation compression without significant loss in convergence rates"
- AdamW: An adaptive optimizer with decoupled weight decay commonly used for training large neural networks. "AdamW remains the primary target for activation compression in theis paper."
- Autoencoder: A neural architecture with an encoder-decoder pair that compresses and reconstructs representations. "It follows an autoencoder architecture composed of an encoder and a decoder."
- Bottleneck layer: A learnable compression module that reduces activation dimensionality before communication and reconstructs it afterward. "The bottleneck layer is introduced after the feed-forward layer within each Transformer block."
- Cosine decay: A learning-rate schedule that decays the rate following a cosine curve after warmup. "followed by cosine decay."
- Data parallelism (DP): Training strategy that replicates the model across workers which process different data shards and aggregate gradients. "data parallelism (DP), which replicates the model across workers that process different data shards"
- Decoder: The part of a bottleneck/autoencoder that reconstructs compressed activations back to the target dimensionality. "The decoder is placed at the beginning of layer , reconstructing the activation before it enters the subsequent attention block."
- Encoder: The part of a bottleneck/autoencoder that maps activations into a lower-dimensional space. "The encoder maps the hidden representation to a lower-dimensional bottleneck space"
- End-to-end training: Training all model components jointly with standard optimizers without specialized separate procedures. "can be trained end-to-end as part of the model's parameters"
- Feed-forward network (FFN): The MLP sublayer inside a Transformer block, often analyzed via its output projection matrices. "output projection tensors of each feed-forward network (FFN)"
- GPipe: A pipeline-parallel training framework that partitions a model into stages across devices. "GPipe-style pipeline parallelism implemented via PyTorch distributed over NCCL."
- Grassmann manifold: The space of all k-dimensional subspaces in n-dimensional space; used for subspace-constrained optimization. "the shared subspace itself must be periodically updated via optimization on the Grassmann manifold."
- Hidden dimension: The width of model representations (e.g., Transformer hidden size) that governs compute and communication scaling. "scales as with the hidden dimension "
- Identity path: The residual (skip) connection pathway that preserves unimpeded gradient flow; here maintained explicitly in low rank. "preserving an explicit low-rank identity path."
- Identity projection operator: A projection on the residual branch that aligns dimensions across layers while preserving the identity property. "We define the identity projection operator as"
- InfiniBand: A high-bandwidth, low-latency interconnect commonly used for inter-node GPU communication. "InfiniBand for inter-node transfers"
- Low-rank subspace: A subspace of much lower dimension than the ambient space capturing most of the signal’s energy. "shared low-rank subspace"
- Muon (optimizer): An optimizer that preserves higher-rank structure via orthogonalized updates, aiding information flow through bottlenecks. "Muon induces higher-rank activation subspaces, reducing the headroom available to any compression method that relies on low-rank structure."
- Newton–Schulz iteration: An iterative matrix method used here to orthogonalize gradient momentum in Muon updates. "using Newton-Schulz iteration"
- NVLink: NVIDIA’s high-bandwidth interconnect for intra-node GPU communication. "NVLink for intra-node communication"
- Orthogonalized gradient momentum: A technique to maintain orthogonality in momentum updates, promoting rank preservation. "updates matrix parameters with orthogonalized gradient momentum"
- Pipeline parallelism (PP): Training strategy that splits a model across devices and streams activations forward and gradients backward. "pipeline parallelism (PP), which partitions the model's layers across devices and streams activations forward and gradients backward"
- Projection operator: A mapping used to align tensor dimensions across residual additions or communication boundaries. "We introduce a projection operator $\mathcal{P}^{\mathrm{id}_l : \mathbb{R}^{L \times h} \rightarrow \mathbb{R}^{L \times H}$"
- qk-norm: A normalization applied to query/key projections in attention to stabilize training. "with qk-norm applied to the attention heads."
- Rank collapse: The phenomenon where representations concentrate into a lower-dimensional subspace during training. "AdamW exhibits a progressive rank collapse in the column space of output projection matrices."
- Rectangular identity matrix: A padded/truncated identity-like matrix used to project between different dimensionalities. "denote the rectangular identity matrix defined elementwise as"
- Residual Bottleneck Model (ResBM): The proposed architecture that adds an identity-preserving encoder–decoder bottleneck across pipeline boundaries. "We call this architecture the Residual Bottleneck Model or ResBM"
- Residual connection: A skip pathway that adds inputs to outputs of layers, stabilizing optimization and gradient flow. "The residual connection, introduced by \citep{he2015deepresiduallearningimage}, is a cornerstone of modern deep network design."
- Residual stream: The running signal carried through all Transformer layers via residual connections. "the residual stream carries information across all layers and is essential for stable optimization."
- Riemannian gradient descent: Optimization constrained to a manifold (e.g., Grassmann), used to update shared subspaces. "periodic subspace updates via Riemannian gradient descent on the Grassmann manifold"
- Self-attention mechanism: The Transformer component that computes attention-weighted combinations of tokens. "Two fundamental components of the Transformer block are the residual connection and the self-attention mechanism."
- Singular value spectrum: The distribution of singular values of a matrix, used to assess effective rank. "We compute the singular value spectrum of FFN output projection layers"
- Square-cube law (of distributed training): The observation that compute scales as O(n3) but inter-stage communication as O(n2) with hidden size. "a relationship they term the square-cube law of distributed training."
- Subspace Models (SM): Prior approach constraining layer projections to a shared low-rank subspace to enable activation compression. "Subspace Models (SM), have claimed up to activation compression"
- SWARM parallelism: A decentralized scheduling approach that stochastically routes pipeline stages across unreliable nodes. "SWARM parallelism \citep{ryabinin2023swarm} addresses the scheduling and fault-tolerance challenges of decentralized pipeline parallelism"
- Tasklets: A decentralized training abstraction focusing on scheduling in heterogeneous environments. "Tasklets \citep{yuan2022tasklets} similarly treat decentralized training as a scheduling problem in heterogeneous environments"
- Top-k sparsification: A compression technique that retains only the largest k elements of a tensor. "applying standard techniques such as top- sparsification, low-rank SVD projection, or quantization."
- Transformer block: The core stacked module of Transformer-based LLMs comprising attention and feed-forward sublayers. "Modern LLMs are typically implemented as a stack of Transformer blocks"
Collections
Sign up for free to add this paper to one or more collections.