- The paper introduces RPA-Check, an automated framework that transforms qualitative behavioral requirements into quantifiable Boolean metrics.
- It employs a multi-stage pipeline, including LLM-as-a-judge, to evaluate role fidelity, procedural stability, and linguistic formalism in legal simulations.
- Empirical results reveal that smaller, instruction-tuned models outperform larger ones in behavioral role adherence and operational stability.
RPA-Check: An Automated Multi-Stage Framework for Evaluating Role-Playing Agents
Systematic evaluation of LLM-based Role-Playing Agents (RPAs) in scenarios requiring procedural and behavioral fidelity has remained underdeveloped due to the inadequacy of standard NLP metrics. Metrics such as BLEU, ROUGE, or perplexity do not capture nuanced dimensions like role adherence, logical consistency, and long-term narrative stability. RPA deployment in serious games and domain-specific simulations—where adherence to institutional logic outweighs linguistic fluency—demands granular, objective, and reproducible evaluation protocols. The RPA-Check framework directly responds to these needs by providing an automated pipeline for transforming qualitative behavioral requirements into discrete, quantifiable metrics, supporting robust comparative analyses among LLM-based agents.
RPA-Check: Multi-Stage Evaluation Pipeline
RPA-Check defines a four-stage evaluation paradigm to convert high-level behavioral constraints into structured, quantitative assessments.
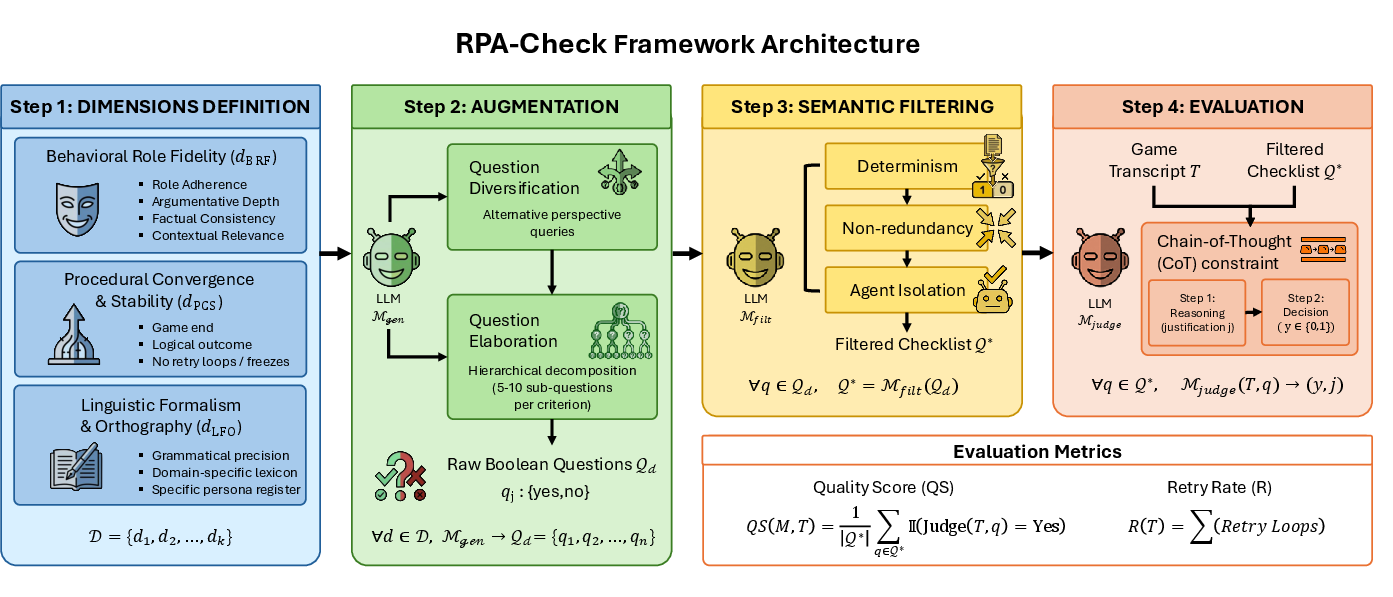
Figure 1: RPA-Check decomposes qualitative behavioral requirements into quantitative Boolean metrics through definition, augmentation, semantic filtering, and LLM-as-a-Judge evaluation, producing standardized Quality Score and Retry Rate outputs.
1. Dimensions Definition:
Establishes comprehensive domains of evaluation—Behavioral Role Fidelity, Procedural Convergence and Stability, and Linguistic Formalism and Orthography—each formalized as distinct, high-level dimensions (D). Behavioral Role Fidelity itself is operationalized along sub-dimensions (Role Adherence, Argumentative Depth, Factual Consistency, and Contextual Relevance).
2. Augmentation:
An LLM generator systemically expands each dimension into a set of Boolean checklist indicators, leveraging diversification and hierarchical decomposition strategies. This ensures granular coverage, disambiguation, and minimal bias via a multi-perspective question pool.
3. Semantic Filtering:
A filtering model prunes the raw checklists for redundancy, subjectivity, or agent interdependence, yielding an isolated, binary-deterministic indicator set. This ensures each indicator directly and uniquely interrogates the agent's behavior relative to their assigned role.
4. LLM-as-a-Judge Evaluation:
A high-capacity Judge Model (GPT-5) scores interaction transcripts using the refined checklist. Chain-of-Thought (CoT) reasoning enforces stepwise justification, reducing hallucinations and providing interpretability for each binary response.
Final performance is quantified using the Quality Score (QS; proportion of positive indicators satisfied) and Retry Rate (R; count of catastrophic simulation failures), capturing both behavioral and operational fidelity.
LLM Court: Evaluation Environment Design
To substantiate RPA-Check, the authors introduce LLM Court, a forensic simulation game implemented in Unity and powered by locally quantized LLMs for privacy and deployment accessibility. The simulation orchestrates complex legal interactions among RPAs (Judge, Prosecutor, Witnesses) under stringent procedural logic while enabling adversarial engagement by a human-controlled Defense role.

Figure 2: The procedural case generation workflow where players initiate new cases, with GPT-5 generating scenario descriptions, forming the basis for dynamic trial simulations.
Procedural Generation:
Case facts are initialized stochastically from a schema-constrained generator (GPT-5), producing a tuple (T,S,E,W,G) ensuring narrative coherence and preventing agent hallucination via immutable "Court Record" grounding.
Role-Specific Prompt Engineering:
Judge, Prosecutor, and Witness agents are instantiated via system prompt injection targeting recency bias and sycophancy. Distinct prompt architectures enforce adversarial or bounded-informational dynamics, constraining or penalizing inappropriate behavioral cross-talk and factual inconsistency.
Deterministic Turn Management:
A finite state machine (FSM) governs procedural flow, with a Sentence Analyzer enforcing permissible transition graphs and the correct routing of dialogic turns, preventing latent model drift or procedural hallucination.
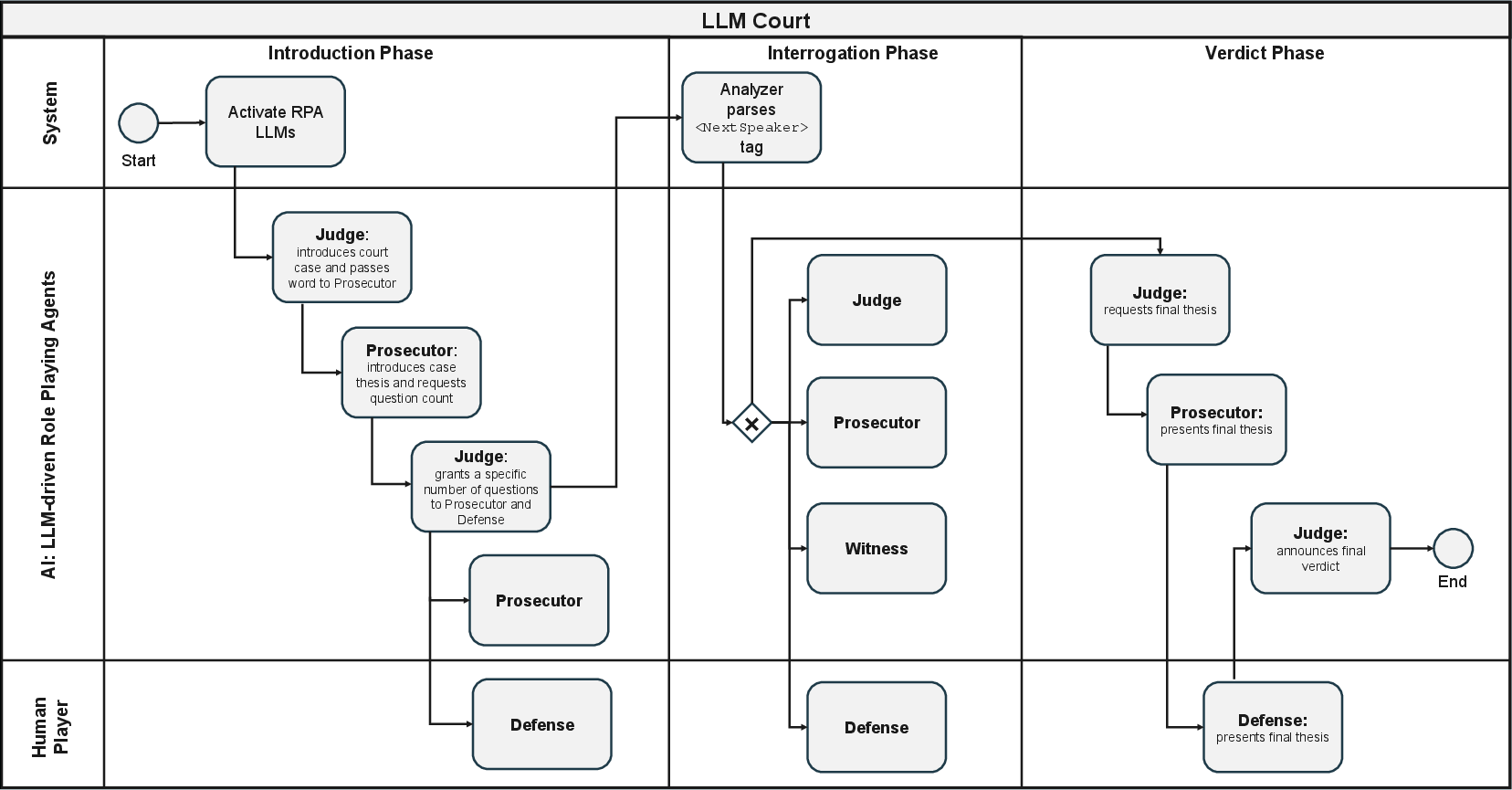
Figure 3: FSM-driven simulation flow divides interaction into introduction, interrogation, and verdict phases, segregating human and agent operations to preserve procedural logic.
Verdict Logic:
Closing arguments and verdicts are produced via model-based summarization followed by a constrained binary outcome prediction, enforcing alignment with dialogic evidence.
Empirical Results and Analytical Observations
Evaluation encompassed seven open-weight LLMs (8B–14B parameters, 4–5 bit quantization), across five procedurally diverse legal scenarios. The RPA-Check evaluation output is multi-dimensional, facilitating both aggregate and per-scenario performance decomposition.
Core Empirical Findings
Model Scale and Performance Decoupling:
Larger models (12B–14B) such as Qwen-3-14B and Phi-4-14B underperform smaller, instruction-tuned models (Llama-3.1-8B, Gemma-2-9B-it) on Behavioral Role Fidelity (QSBRF) and Procedural Convergence (QSPCS). Small models yield scores of 0.89–0.93, whereas the largest models drop to 0.73–0.76. This is a methodologically strong indication that parametric scale is not a proxy for behavioral reliability under domain constraints.
User-Alignment Bias and Role Drift:
High-scoring Argumentative Depth and low-scoring Role Adherence for larger models highlight their tendency toward sycophancy and procedural drift, producing linguistically rich yet functionally invalid outputs—particularly acute in adversarial or regulator roles (e.g., Prosecutor, Judge).
Operational Instability:
Significant scenario-dependent volatility is observed. Models such as Hermes-3-8B and Phi-4-14B exhibit catastrophic failures (high Retry Rate) in certain cases, confirming strong nonlinearities between model stochasticity and scenario complexity. This underlines the inadequacy of single-score evaluations, necessitating profiling instability as a first-class property.
Linguistic Formalism as a Non-Discriminator:
All evaluated models achieved near-ceiling QSLFO (0.97–1.00), indicating the limited value of surface fluency metrics in agent selection for structured role-play applications. The evaluation discriminated instead on behavioral and procedural compliance.
Theoretical and Practical Implications
Evaluation Methodology:
RPA-Check formally advances evaluation by decoupling linguistic fluency from behavioral and operational compliance using standardized, automated checklists. Its chain-of-thought justified, multi-dimensional metrics allow detection not only of aggregate tendencies but scenario-intrinsic failure modes, providing a diagnostic instrument for model selection and behavioral debugging.
Role of Instruction Tuning:
The outcome profile strongly reinforces the central role of domain-specific instruction tuning over parameter count for agent alignment in strictly regulated, adversarial simulations. As a result, deployment in privacy-conscious, resource-limited environments is not only viable but—in terms of safety and role-fidelity—can be preferable with smaller architectures.
Generalizability:
The modular design of RPA-Check (dimension definition, augmentation, filtering, LLM-judging) is inherently domain-adaptable. While validated in forensic game-based simulations, the approach can be transferred to other settings (e.g., medical, compliance negotiation), wherever procedural or behavioral rigidity is required.
Automated Case Generation and Scaling:
RPA-Check's pipeline allows for automatic expansion of test corpora through modular procedural scenario generation, enabling systematic scaling of evaluation ensembles and the profiling of models over diverse interaction graphs.
Limitations and Future Directions
Sample size for empirical validation is moderate; the statistical significance of scenario-level variance estimates would be improved with expanded corpora. Extending the procedural generation module for large-scale, automated scenario creation is a straightforward path forward. Future work may explore further isolation and mitigation of seed-based stochasticity in RPAs, expanded modeling of adversarial and institutional dynamics, and integration with hierarchical or self-reflective judge models.
Conclusion
RPA-Check constitutes a rigorous, automated methodology for LLM-based role-playing agent evaluation in constraint-rich, multi-agent domains. Its empirical evidence directly challenges the primacy of model scale as a predictor of fidelity in procedurally structured interaction, underscoring the necessity of granular, multi-dimensional evaluation for operational deployment in serious games and professional simulation. Its architected modularity and support for local inference pipeline mark it as a platform-independent standard for future research in generative agent assessment, with broad implications for AI safety, instruction tuning research, and real-world adoption in security-sensitive contexts.