Fame Fades, Nature Remains: Disentangling the Character Identity of Role-Playing Agents
Abstract: Despite the rapid proliferation of Role-Playing Agents (RPAs) based on LLMs, the structural dimensions defining a character's identity remain weakly formalized, often treating characters as arbitrary text inputs. In this paper, we propose the concept of \textbf{Character Identity}, a multidimensional construct that disentangles a character into two distinct layers: \textbf{(1) Parametric Identity}, referring to character-specific knowledge encoded from the LLM's pre-training, and \textbf{(2) Attributive Identity}, capturing fine-grained behavioral properties such as personality traits and moral values. To systematically investigate these layers, we construct a unified character profile schema and generate both Famous and Synthetic characters under identical structural constraints. Our evaluation across single-turn and multi-turn interactions reveals two critical phenomena. First, we identify \textit{"Fame Fades"}: while famous characters hold a significant advantage in initial turns due to parametric knowledge, this edge rapidly vanishes as models prioritize accumulating conversational context over pre-trained priors. Second, we find that \textit{"Nature Remains"}: while models robustly portray general personality traits regardless of polarity, RPA performance is highly sensitive to the valence of morality and interpersonal relationships. Our findings pinpoint negative social natures as the primary bottleneck in RPA fidelity, guiding future character construction and evaluation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper studies how AI chatbots that pretend to be characters (like a superhero, a book hero, or a brand‑new made‑up person) keep their “identity” during conversations. The authors split a character’s identity into two layers:
- Parametric identity: what the AI already “knows” from training about a famous character (like Harry Potter). Think of this as the model’s built‑in memory.
- Attributive identity: the character’s detailed traits, like personality, morals, relationships, habits, and skills. Think of this as how the character acts, decides, and treats others.
Their big message is captured in two phrases:
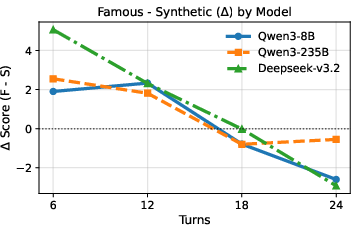
- Fame Fades: being famous helps at first, but that advantage quickly disappears in longer chats.
- Nature Remains: the character’s social and moral nature—especially negative or “mean” traits—matters a lot and is hard for the AI to stick to.
The main questions the paper asks
The authors focus on two questions, explained simply:
- RQ1: Does having built‑in knowledge of a famous character help the AI role‑play better than with a newly invented (synthetic) character?
- RQ2: Which specific character attributes (like morals, relationships, personality traits) make role‑playing easier or harder for the AI, especially when those attributes are positive or negative?
How they studied it (with easy analogies)
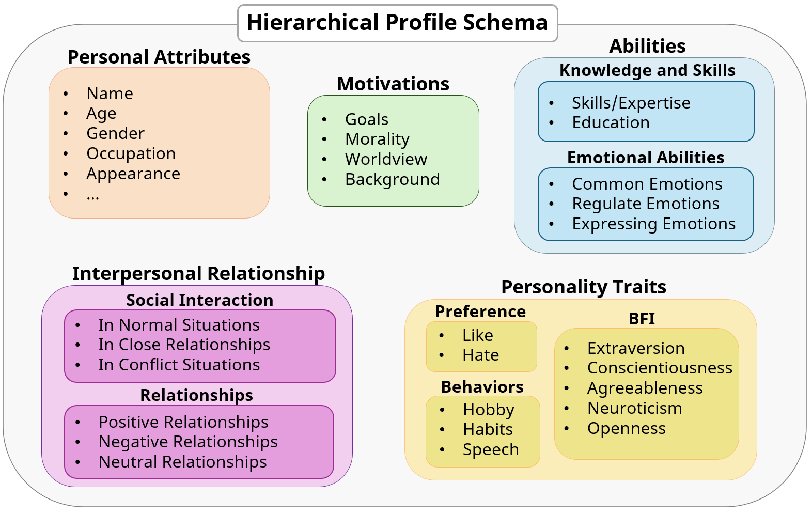
To make the test fair, they built a structured “character profile” template—like a character’s report card—covering 5 big areas and 38 details (fields):
- Personal attributes (bio)
- Personality traits (like Big Five)
- Interpersonal relationships (how they treat others)
- Motivations (values, goals, morality, worldview)
- Abilities (skills, emotion control, expression)
Then they made two kinds of characters under the same rules:
- Famous: summarized from reliable fan pages (like Fandom) into the template.
- Synthetic: brand‑new characters generated by AI, checked for coherence, given backstories, and summarized into the same template.
They evaluated the characters in two settings:
- Single‑turn interviews (like quick Q&A). This checks if the AI sounds like the character right away.
- Multi‑turn role‑play (like a group chat/story over many turns). This checks long‑term consistency.
They also peered “under the hood” of the AI using attention analysis. Imagine the AI’s “attention” as a spotlight over the input: it can shine on the character profile, past chat history, or its own ongoing writing. They measured:
- Which parts the AI pays attention to as the conversation grows.
- Whether the AI relies more on its built‑in memory (“parametric knowledge”) or on the actual conversation context it has seen.
Key idea: As chats get longer, models often start following their own previous messages (self‑conditioning) more than the original character description.
What they found and why it matters
Here are the most important results:
- Fame Fades:
- In quick interviews, famous characters do better. The AI’s built‑in knowledge gives a head start.
- In longer, multi‑turn conversations, that advantage mostly disappears—and sometimes the made‑up (synthetic) characters do just as well or better.
- Why? As the chat grows, the AI pays less attention to the original profile and more to the running conversation and its own previous outputs. For famous characters, the model also tends to “pull” from its pretraining memories, which can clash with the ongoing story or prompt.
- Nature Remains:
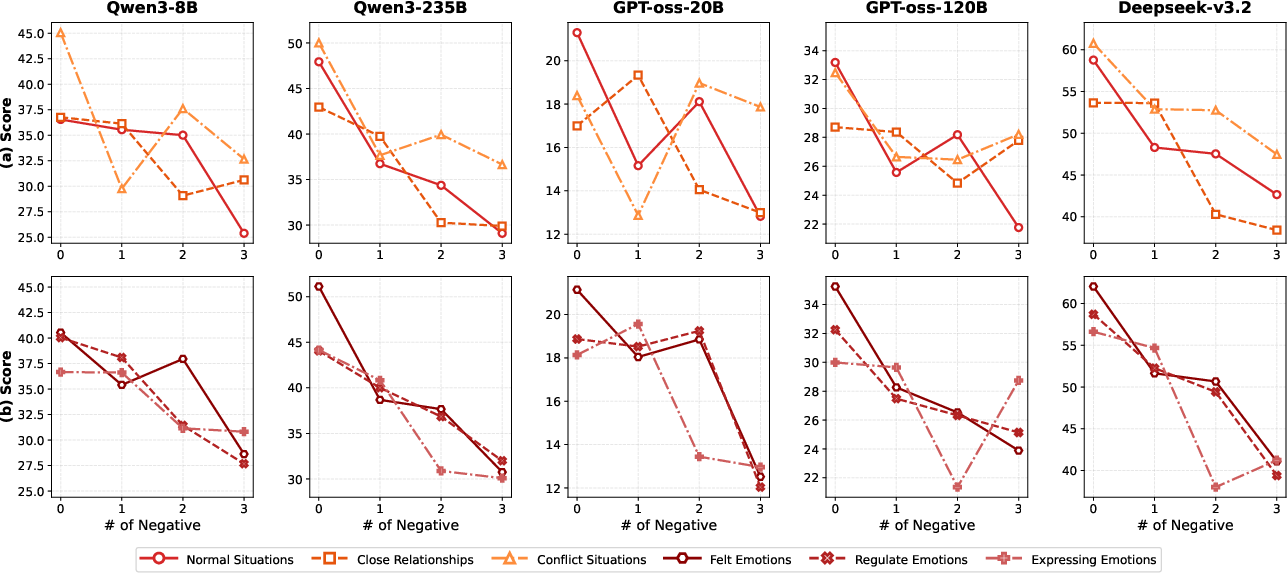
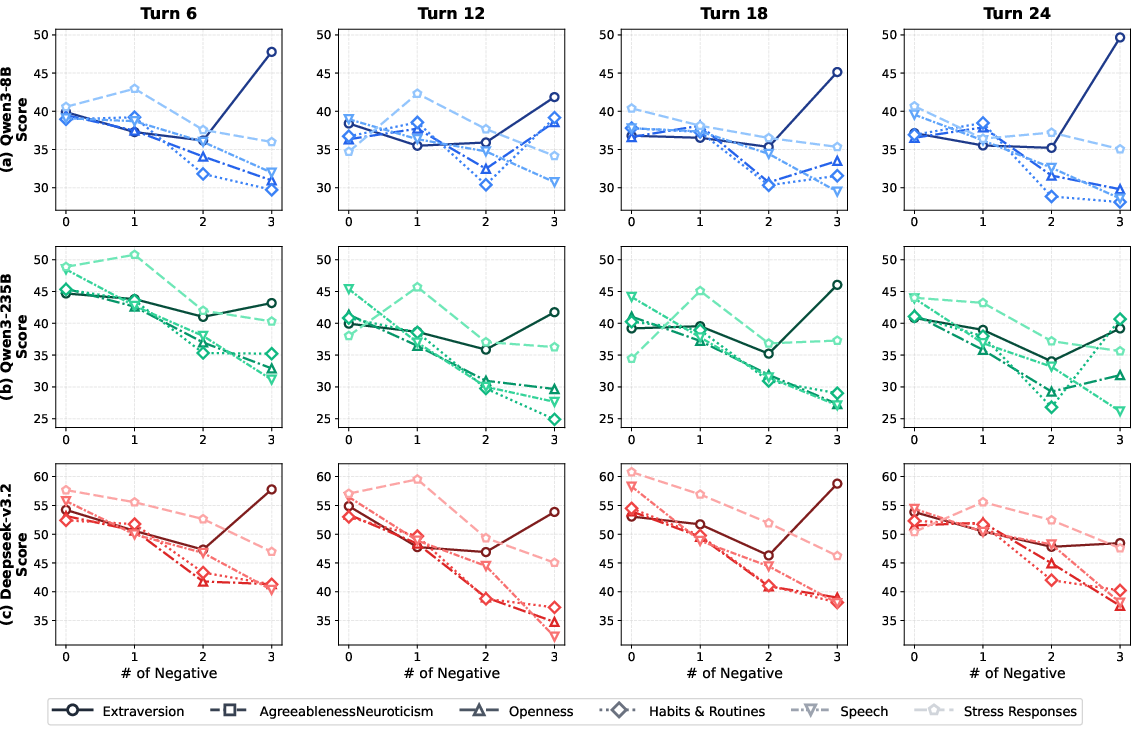
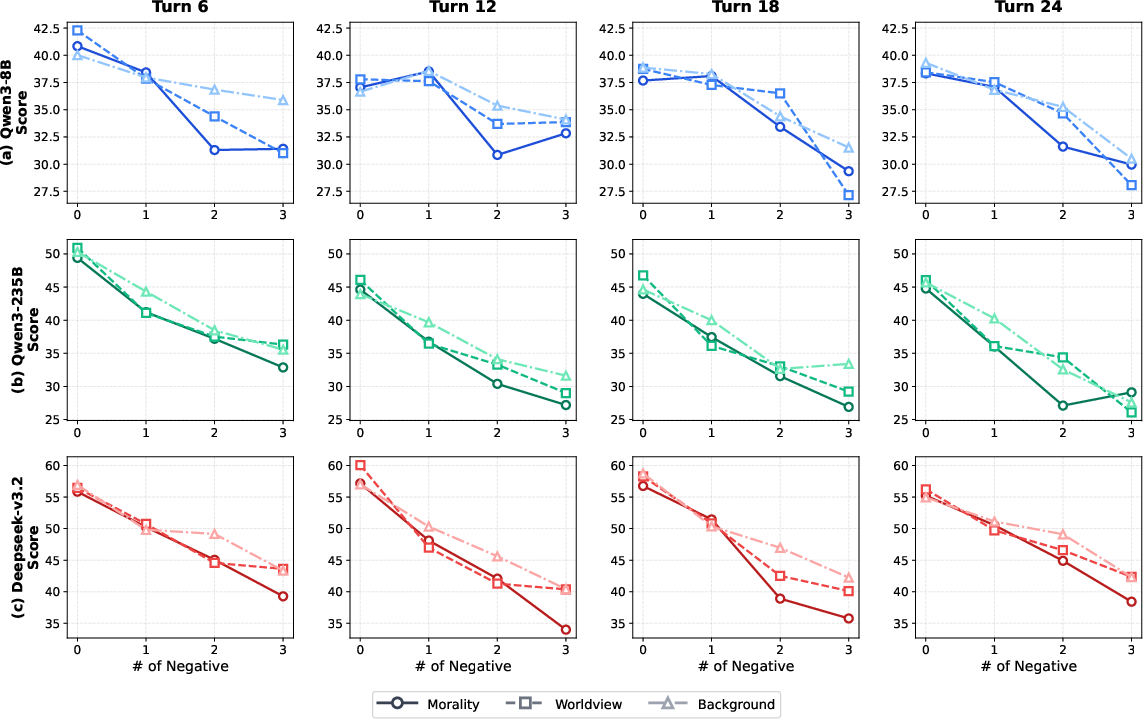
- Personality traits (like Extraversion or Openness) barely change performance whether they’re positive or negative. The AI is pretty good at sticking to these.
- But motivations and social behavior (morality, worldview, and how the character treats others) matter a lot—especially when they’re negative (e.g., unethical, hostile, adversarial).
- Models often struggle to faithfully act out “negative” social or moral traits. This may be because safety training pushes models toward agreeable and prosocial behavior, making it hard to portray characters like villains or difficult personalities without “softening” them.
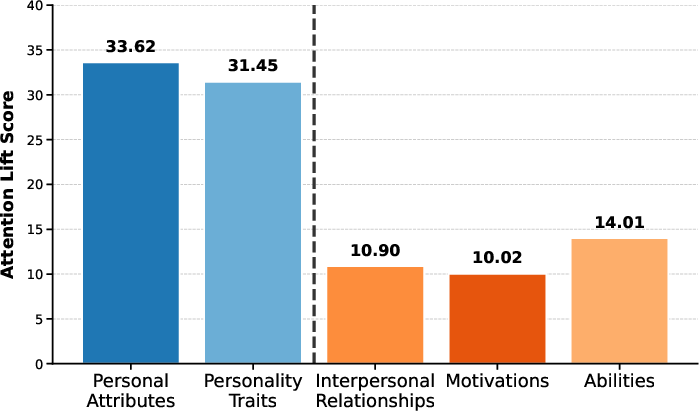
- Attention explains the difficulty:
- The AI gives more attention to easy/familiar sections (personal attributes, personality traits).
- It pays less attention to motivations, relationships, and abilities—the same areas where performance drops most for negative traits.
- So the parts that matter most for “acting like a difficult character” are precisely the parts the model looks at less, making mistakes more likely.
What this means going forward
For people building or evaluating role‑playing AIs:
- Don’t rely on fame: A famous character helps at the start, but that boost fades with longer chats. Good long‑term behavior needs strong, persistent grounding in the character’s profile and the ongoing story.
- Focus on “hard” natures: The real challenge is negative morality and adversarial relationships. If your character is a villain, a cynic, or socially difficult, the AI may sanitize the behavior. You’ll need better prompts, stronger reminders, or special training to keep these traits consistent without breaking safety rules.
- Go beyond personality tests: Metrics like MBTI or Big Five aren’t enough. Evaluations should target motivations, moral choices, and relationship dynamics, because that’s where models struggle most.
- Design prompts and systems that keep important traits “in view”: Since the AI’s attention can drift, highlight motivations and relationship rules repeatedly in long chats (e.g., brief reminders, structured turn prompts, or retrieval of key profile snippets).
In short: Being famous is a short‑term advantage, but a character’s deeper nature—especially moral stance and how they treat others—drives long‑term role‑playing quality. Improving RPAs means helping models consistently follow those deeper traits, even when they’re negative, across many turns.
Knowledge Gaps
Below is a single, consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each point is phrased to be concrete and actionable for follow-up research.
- Generalization of mechanistic findings: Attention lift/saturation analyses were only run on Qwen3-8B. Verify whether the “history-to-self-conditioning” shift and profile saturation patterns hold across larger and differently aligned models (e.g., 70B+, instruction vs. base, proprietary frontier LLMs).
- Causal evidence vs. correlational attention: Attention is used as an explanatory proxy. Employ causal methods (representation/activation patching, causal mediation analysis, logit lens interventions) to establish whether profile/history segments causally drive the observed behavior shifts.
- Isolating turn length from agent count: Multi-turn evaluations confound conversation length and multi-agent dynamics. Run multi-turn single-agent settings and fixed turn-length multi-agent settings to disentangle which factor drives the “Fame Fades” effect.
- Parametric exposure quantification: “Famous” is assumed to reflect pretraining exposure. Quantify exposure (e.g., via data contamination checks, memorization probes, or external fame proxies like pageviews) and test performance as a function of continuous “fame” rather than a binary famous/synthetic split.
- Control for prompt format effects: Prior work suggests behavioral guidelines can outperform descriptive personas. Compare guideline-style vs. descriptive profiles within the same schema to test whether “Fame Fades” depends on persona format.
- Safety alignment confound for negative attributes: Degradation on negative morality/interpersonal attributes may reflect guardrail refusals or sanitization. Systematically vary safety settings, refusal calibration, and policy prompts to disentangle capability limits from alignment constraints.
- Human vs. LLM-as-judge validity: Both PersonaGym and CoSER rely on LLM judges (GPT-4o). Quantify agreement with expert human raters, report inter-rater reliability, and assess bias (e.g., for moral valence) to validate judge reliability.
- Multiple comparison control: Numerous significance tests across models, metrics, and fields lack correction. Re-run with FDR or family-wise error controls to ensure reported effects are robust.
- Cross-model consistency of RQ2 effects: Positive/Negative sensitivity is reported across five models for single-turn, but multi-turn polarity effects are shown on limited settings. Test RQ2 across more backbones and turns to establish stability.
- Fine-grained moral/interpersonal taxonomies: “Positive vs. Negative” is coarse. Break morality and interpersonal relations into subdimensions (e.g., deontic vs. consequentialist, aggression vs. deceit, dominance vs. coldness) and measure which subtypes drive failures.
- Continuous valence and intensity: Replace binary polarity with continuous or multidimensional scales (e.g., Likert, PAD emotion space) to capture graded effects of negative attributes on role fidelity.
- Cultural and contextual grounding of valence: GPT-4o labeled valence; moral and relational norms are culture-dependent. Include cross-cultural human annotations and test whether performance gaps persist across cultures or contexts.
- Field coverage adequacy: The 38-field schema may omit identity facets (e.g., ideology nuance, mental models, temporal goal dynamics, social norms, role obligations). Audit and expand fields; test how additions alter attention allocation and fidelity.
- Attention allocation as a mechanism: Motivation and Interpersonal fields get lower attention than Personality/Personal attributes. Test interventions (profile chunk ordering, salience markers, retrieval hooks, memory pinning) to raise attention and reduce the negative-attribute gap.
- Scenario generation confounds: CoSER scenarios were LLM-generated (Gemini 2.5). Measure and control scenario difficulty/style (e.g., conflict density, genre, cooperation vs. competition) to rule out scenario bias in multi-turn outcomes.
- Long-horizon persistence: Experiments stop at 24 turns. Evaluate at much longer horizons (50–200+ turns) to characterize when and how self-conditioning overwhelms persona grounding and whether mitigation holds over time.
- Memory and retrieval interventions: The paper diagnoses context drift but does not test mitigations. Evaluate episodic memory, persona “pinning,” retrieval augmentation, and recurrent slot constraints to sustain attributive fidelity over turns.
- Specialized RPA models: Only general-purpose LLMs were role-players. Test character-specialized models (e.g., CharacterGLM, fine-tuned RPAs) to see whether “Fame Fades” and “Nature Remains” generalize.
- Role of instruction-tuning and RLHF: Compare base vs. instruction-tuned vs. RLHF-tuned variants to quantify how alignment training modulates (i) reliance on parametric knowledge and (ii) resistance to negative attribute portrayal.
- Profiling length and granularity: Profiles average ~700 words; Positive profiles are longer than Negative ones. Run controlled ablations on profile length, density, and field weighting to remove confounds and assess minimal persona specifications.
- Judge robustness and reproducibility: Single-judge configuration (GPT-4o) may be brittle. Use judge ensembles, multiple seeds, and rubric randomization; release judge prompts and scoring scripts for reproducibility.
- Language and domain generalization: All data appear English and focused on movies/anime/drama. Extend to other languages, domains (games, literature, historical figures), and modalities to test identity effects broadly.
- Validation of “synthetic” unseen status: Ensure synthetic personas are truly out-of-distribution (e.g., check that generated names/backgrounds do not overlap with known IPs or training corpora) to avoid inadvertent parametric leakage.
- Character identity drift vs. story progression: Decompose fidelity loss into persona drift (identity forgetting) vs. narrative adaptation (identity-consistent evolution). Introduce gold narrative trajectories to distinguish the two.
- Quantifying guardrail side effects: Measure toxicity/refusal/sanitization rates alongside fidelity to detect when safety policies cause off-target failure in negative-character portrayals.
- Multi-agent composition effects: Beyond counting negative characters (0–3), vary network topology (ally-vs-ally, adversary triads), power asymmetries, and social roles to map when negative attributes most disrupt coherence.
- Dataset transparency and release: Clarify and release the full schema, generation prompts, filtering criteria, and mechanistic-analysis code to enable replication and independent auditing of identity effects.
- Temporal/canonical ambiguity in famous characters: Different canons/eras (reboots, alternate universes) can alter parametric identity. Control for canon version and test whether inconsistency contributes to early-turn boosts and later drift.
- Persona prompt style and placement: Test instruction-order effects (system vs. user vs. tool prompts), reiteration frequency, and field ordering to determine how prompt engineering modulates attention and fidelity.
- Evaluation beyond PersonaGym/CoSER: Add complementary tasks (e.g., goal-directed planning in character, moral dilemma resolution in character, safety-constrained RP) to validate that findings are not benchmark-specific.
- Safety-aware negative RP protocols: Design and evaluate methods that allow faithful negative-character portrayal while preventing real-world harm (e.g., shadow-mode simulation, debriefed outputs, red-team-in-the-loop reviews).
- Statistical power and variance reporting: Provide power analyses, per-character variance, and ablations controlling for character popularity, complexity, and dialogue verbosity to ensure robust inference.
- Heterogeneity analysis: Identify which specific characters (or attribute combinations) buck the aggregate trends to uncover boundary conditions where fame does not fade or negative nature does not degrade performance.
- From diagnosis to intervention: The paper does not propose or test fixes. Develop and benchmark targeted interventions (fine-tuning on negative social natures, controllable decoding, structured memory, field-weighted prompting) to close the identified gaps.
Practical Applications
Immediate Applications
Below are practical use cases that can be implemented now, grounded in the paper’s findings (“Fame Fades,” “Nature Remains”), the 5×38 character profile schema, the famous/synthetic datasets, and the evaluation/diagnostics methods (PersonaGym, CoSER, attention-lift/saturation).
- Persona schema as a standard for RPA character cards — Sectors: software, gaming, education
- Use the 5-dimension, 38-field schema to design robust persona cards for chatbots, NPCs, tutors, and coaching agents, ensuring consistent grounding across products and teams.
- Tools/workflows: plug-in schema into existing persona card formats (e.g., JSON), add profile parsers and validators; seed interviews using PersonaGym-like prompts for quick profile checks.
- Assumptions/dependencies: access to LLMs with sufficient context windows; adoption by product teams; licensing clarity for any famous-character metadata.
- Prefer synthetic over famous IP for multi-turn RPAs — Sectors: software, gaming, policy/compliance
- Given “Fame Fades,” switch to synthetic characters in sustained interactions to reduce IP risk without losing fidelity.
- Tools/products: synthetic persona generators guided by the schema; internal policy to default to synthetic personas in persistent chat.
- Assumptions/dependencies: generation quality of synthetic personas meets brand tone; legal guidance on any residual references to famous characters.
- Multi-turn persona reinforcement in prompts — Sectors: software, gaming, customer support
- Counteract self-conditioning drift by periodically re-injecting key profile snippets (especially Motivation and Interpersonal fields) every N turns.
- Tools/workflows: “persona reinforcement middleware” that inserts dynamic reminders or retrieval-augmented snippets; A/B test reinforcement cadence.
- Assumptions/dependencies: prompt budget and latency; retrieval system or prompt budget for re-grounding.
- Targeted QA for negative social natures — Sectors: software QA, safety, gaming
- Build test suites stressing Negative valence in Morality and Interpersonal Relationships, where models degrade most.
- Tools/workflows: curated prompt sets; LLM-as-Judge rubrics aligned to PersonaGym dimensions; failure dashboards by field/valence.
- Assumptions/dependencies: judge-LM reliability; acceptance criteria for “faithful but safe” negative portrayals.
- Safety policy tuning for “villain” roles — Sectors: safety, content moderation, gaming
- Adjust moderation heuristics to allow safely constrained negative role-play (e.g., descriptive villainy without incitement).
- Tools/products: policy toggles for “portray vs promote” distinctions; refusal templates for unsafe requests; content classifiers tied to profile valence.
- Assumptions/dependencies: organizational risk tolerance; jurisdictional content rules; robust escalation/refusal behaviors.
- NPC and narrative design calibration — Sectors: gaming, interactive media
- Use the schema to author NPCs and calibrate dialogue managers to handle adversarial interpersonal dynamics and negative moral arcs, which are current bottlenecks.
- Tools/workflows: storyline seeds auto-generated from profiles; periodic persona reinforcement; conflict-scene QA.
- Assumptions/dependencies: narrative constraints; audience age ratings and safety policies.
- Customer service/de-escalation simulators — Sectors: enterprise training, finance, retail, telecom
- Simulate difficult customers and adversarial scenarios (negative interpersonal styles) to train agents in de-escalation.
- Tools/products: scenario packs derived from schema; in-house CoSER-like multi-agent trainers; performance rubrics by PersonaGym metrics.
- Assumptions/dependencies: safe handling of negative personas; privacy for transcripts and logs.
- Education role-play modules — Sectors: education, professional training
- Use synthetic personas with explicit motivations to run ethics debates, history reenactments, or patient interviews, knowing personality polarity will be robust but moral conflict needs scaffolding.
- Tools/workflows: classroom templates; instructor dashboards to monitor moral/conflict fidelity; guardrails to avoid harmful content.
- Assumptions/dependencies: institutional content guidelines; teacher oversight.
- Turn-wise monitoring for drift — Sectors: software analytics, ops
- Instrument chat systems to track turn-level fidelity (e.g., via PersonaGym-like scoring) and detect when performance drops as turns increase.
- Tools/workflows: telemetry pipeline; alerts when Character Fidelity dips or when attention to Motivation/Interpersonal fields falls.
- Assumptions/dependencies: compute budget for evaluation; proxy metrics if attention is not accessible.
- LLM-as-Judge valence classifier for persona intake — Sectors: tooling, content ops
- Automatically score new persona attributes on a 1–10 valence scale to label Positive/Negative fields and trigger differential safeguards.
- Tools/workflows: intake pipeline using judge LLM; routing to stricter safety paths when negative morality/interpersonal flags appear.
- Assumptions/dependencies: judge model bias; manual review for edge cases.
- Research reporting controls — Sectors: academia, industrial research
- Control for parametric identity in studies by pairing famous/synthetic profiles under the same schema and reporting performance by attribute valence.
- Tools/workflows: experiment templates including CoSER/PersonaGym; matched-pair dataset construction method from the paper.
- Assumptions/dependencies: reproducibility across LLMs; disclosure of judge models and prompts.
Long-Term Applications
These depend on further research, scaling, or development to address the identified bottlenecks (negative social natures; multi-turn drift; attention allocation).
- Attention-aware decoding/controllers — Sectors: software, ML tooling
- Develop decoding strategies that up-weight underattended fields (Motivation, Interpersonal) during generation to maintain fidelity over long turns.
- Tools/products: plug-in attention controllers; context partitioning APIs; “field-aware” re-ranking.
- Dependencies: access to model internals or controllable adapters; validation across model families.
- Safety-constrained fidelity training for negative attributes — Sectors: model development, safety
- Fine-tune or align models to faithfully portray negative morality/interpersonal traits while staying within safety constraints (“portrayal without promotion”).
- Tools/workflows: contrastive preference optimization; refusal scaffolds; filtered negative-dialogue corpora; red-teaming protocols.
- Dependencies: curated datasets; ethics approval; generalization to out-of-distribution roles.
- Persona-grounded memory architectures — Sectors: agent platforms, software
- Build memory systems that regularly reconcile conversation history with profile constraints to counter self-conditioning drift observed in multi-turn chats.
- Tools/products: persona memory stores; constraint-checking at turn boundaries; automated “profile-to-memory sync.”
- Dependencies: latency/compute budgets; robust retrieval and summarization; privacy controls.
- Standardized benchmarks for negative social natures — Sectors: academia, evaluation vendors
- Establish public leaderboards emphasizing Negative valence in Motivation and Interpersonal fields, with multi-turn scenarios and turn-ablation analyses.
- Tools/workflows: open datasets built from the schema; judge protocols; confidence intervals and significance testing.
- Dependencies: community buy-in; legal review for any famous-character usage; sustained hosting.
- Persona IDEs and diagnostics — Sectors: developer tooling, product ops
- Create design-time tools that: (i) author profiles using the schema, (ii) simulate interview/multi-turn interactions, (iii) visualize attention-lift and saturation across fields, and (iv) suggest reinforcement strategies.
- Tools/products: “Persona Studio” with dashboards; one-click QA runs (PersonaGym/CoSER); repair suggestions for weak fields.
- Dependencies: support for multiple LLM backends; approximations if attention is not exposed; UX for policy teams.
- Regulator and platform policy guidance — Sectors: policy, platform governance
- Define guidelines for deploying role-play agents that portray negative traits (disclaimers, content boundaries, transparency on synthetic vs famous).
- Tools/workflows: compliance checklists; opt-in flags for role intensity; standardized refusal policies for illegal/harmful prompts.
- Dependencies: evolving regulations; cross-jurisdiction alignment; IP/licensing standards.
- Therapeutic/training applications with controlled adversity — Sectors: healthcare, public safety, HR
- Longitudinal agents for exposure therapy or crisis-response drills that safely simulate adversarial interactions without rewarding harmful behaviors.
- Tools/products: clinician/admin controls; safety harnesses; audit logs and kill-switches.
- Dependencies: clinical validation; strict safety oversight; data governance.
- Multi-agent social simulation platforms — Sectors: social science, market research, operations
- Simulate group dynamics by varying proportions of negative Motivation/Interpersonal attributes to stress-test workflows or narratives at scale.
- Tools/workflows: CoSER-like multi-agent generators; field-level “mixers” to configure valence distributions; outcome analytics.
- Dependencies: validity of simulations versus real-world behavior; bias monitoring.
- IP-light entertainment pipelines — Sectors: media, gaming
- End-to-end pipelines for synthetic franchises (lore, characters, episodes) that retain multi-turn fidelity without famous IP reliance.
- Tools/products: story engines seeded from schema; lore-coherence retrieval; QA for long arcs focusing on moral conflict.
- Dependencies: creative quality; brand strategy; content rating compliance.
- HRI persona packs for robots — Sectors: robotics, consumer devices
- Robust, long-term personas for companion/service robots with stable interpersonal behavior and safe handling of adversarial situations.
- Tools/workflows: on-device persona reinforcement; conflict-mode policies; user-adjustable motivation sliders.
- Dependencies: on-device compute; safety certifications; multimodal integration.
Cross-cutting assumptions and dependencies
- Model behavior variability: attention analyses were run on a smaller model; replication on larger or different architectures may change optimal interventions.
- Safety alignment tensions: faithful negative portrayals can conflict with safety policies; requires careful design of guardrails and disclosures.
- Judge LLM bias: automatic scoring/classification depends on judge quality; human-in-the-loop review advised.
- Context/memory limits: re-grounding and persona-aware memory need context budgets and retrieval systems; latency/performance trade-offs apply.
- Licensing/IP: avoid direct reuse of copyrighted text; prefer synthetic personas to reduce legal risk.
- Monitoring and audit: deploy turn-wise fidelity monitoring and logs for accountability, especially in safety-sensitive sectors.
Glossary
- Anthropomorphism: The degree to which generated agents exhibit human-like qualities in interaction. "metrics like Anthropomorphism (An), Character Fidelity (CF), and Storyline Quality (SQ)."
- Attention lift: A measure of how much the model’s attention focuses on a specific context segment at generation time. "We quantify segment reliance using (i) attention lift at the final generated token (length-normalized attention preference)"
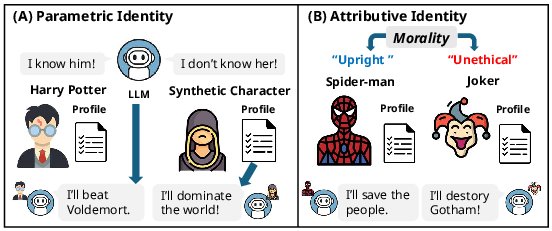
- Attributive Identity: Fine-grained behavioral properties of a character, such as personality, morals, and interpersonal style. "Attributive Identity, which captures fine-grained characteristic properties such as personality traits, moral values, and interpersonal styles of characters."
- BFI: The Big Five Inventory, a psychometric instrument for personality traits used to specify personas. "coarse-grained, personality-centric representations such as BFI or MBTI"
- Character Fidelity: How accurately an agent adheres to its specified character identity during interaction. "metrics like Anthropomorphism (An), Character Fidelity (CF), and Storyline Quality (SQ)."
- Character Identity: A structured, multidimensional definition of a role-playing character. "we propose the concept of Character Identity as a multidimensional construct comprising two distinct layers"
- Character hallucination: Model-generated, incorrect or fabricated character details arising from internal priors. "While it can cause ``character hallucination''"
- CoSER: A multi-turn, multi-party role-playing benchmark for narrative interactions. "CoSER assesses multi-party narratives expanded from seed scenarios"
- Fine-tuning: Adapting a pre-trained model’s parameters to a specific task or domain via additional training. "including reasoning \citep{chen2024agentverse}, retrieval-augmented generation \citep{huang2024emotional}, and fine-tuning \citep{sun2025identity}."
- Fame Fades: A phenomenon where famous characters’ initial advantage diminishes over longer interactions. "we term \"Fame Fades\": while famous characters hold a significant performance advantage in initial turns, this edge rapidly vanishes as interactions lengthen."
- LLMs: Transformer-based models trained on vast text corpora to perform language tasks. "Advancements in LLMs have catalyzed a surge of interest in Role-Playing Agents (RPAs)"
- LLM-as-Judge: Using an LLM to assess or score outputs in evaluation pipelines. "we employ Claude-4.5-sonnet \citep{anthropic_claude_sonnet_45_2025} as an LLM-as-Judge to evaluate whether the variables formed a coherent persona"
- Mann-Whitney U test: A nonparametric statistical test for comparing differences between two independent groups. "with only 5 of 20 configurations showing statistical significance under the Mann-Whitney U test \citep{mann1947test}."
- MBTI: The Myers–Briggs Type Indicator, a categorical personality framework used in persona design. "evaluating dialogue quality through MBTI-based categorization"
- Mechanistic analysis: Probing internal model processes (e.g., attention) to explain observed behaviors. "and conduct attention-based mechanistic analysis to uncover the internal mechanisms underlying the observed performance patterns."
- Nature Remains: A phenomenon where performance sensitivity persists for certain attribute valences (e.g., morality). "our results highlight that \"Nature Remains\" in the form of specific attribute sensitivity."
- Parametric Identity: Character-specific knowledge embedded in an LLM’s weights from pre-training. "Parametric Identity, which refers to the character-specific knowledge encoded within the LLM's weights during pre-training"
- Parametric knowledge: Information stored in a model’s parameters from its training data. "the dual nature of LLM parametric knowledge."
- PersonaGym: A single-turn, interview-style benchmark tailored to evaluate role-play quality. "PersonaGym evaluates response quality via dynamic, persona-tailored interviews"
- Persona injection: Inducing a model to adopt a specified persona via prompt-based descriptions. "Research on persona injection in LLMs has shown that prompt-based persona descriptions can reliably induce corresponding behavioral patterns."
- Polarity: The positive or negative orientation of an attribute (e.g., agreeable vs. disagreeable). "show minimal impact on performance regardless of polarity"
- Preference optimization: Training methods (e.g., RLHF) that align model outputs with preferred human judgments. "stemming from safety alignment and preference optimization during training."
- Retrieval-augmented generation: Enhancing generation by retrieving external documents to ground outputs. "including reasoning \citep{chen2024agentverse}, retrieval-augmented generation \citep{huang2024emotional}, and fine-tuning \citep{sun2025identity}."
- Safety alignment: Techniques ensuring model outputs adhere to safety constraints and avoid harmful content. "stemming from safety alignment and preference optimization during training."
- Saturation layer statistic: A metric for when a context segment’s influence appears across network layers. "and (ii) a saturation layer statistic capturing when each segment’s influence emerges across layers"
- Self-conditioning: The model’s tendency to rely on its own generated context during longer interactions. "compete with the model’s own self-conditioning signal"
- Storyline Quality: The coherence and quality of narratives produced in multi-agent interactions. "metrics like Anthropomorphism (An), Character Fidelity (CF), and Storyline Quality (SQ)."
- Superposition: An LLM’s ability to represent multiple roles or attributes simultaneously from its priors. "it also enables ``superposition,'' allowing self-aligned role-play without external metadata"
- Synthetic characters: Personas created from structured prompts or generated metadata rather than famous sources. "there is growing interest in ``synthetic characters'' relying on user-defined personas."
- Token-level cues: Specific input tokens providing explicit guidance to the model during generation. "As contexts lengthen, token-level cues from profile and history context become increasingly diluted"
- Turn ablation: Evaluating performance by varying the number of interaction turns to isolate effects. "We complement turn ablations with mechanistic analysis during decoding"
- Valence: The positive or negative value associated with an attribute (e.g., moral goodness vs. badness). "RPA performance is critically sensitive to the valence of Motivations and Interpersonal Relationships."
Collections
Sign up for free to add this paper to one or more collections.