- The paper introduces a novel layerwise symmetry enforcement method that extracts a coupled, label-aware mean-shift dynamic for in-context classification.
- It enforces permutation symmetry at each layer, transforming noisy weights into a structured and interpretable algorithmic recursion.
- Empirical and theoretical analyses confirm that the approach enhances robustness across noisy, semi-supervised, and nonlinear classification tasks.
Layerwise Symmetric Dynamics in Transformer In-Context Classification
Introduction
This paper investigates the inference-time algorithmic motif underlying transformer-based in-context learning (ICL) for multiclass classification. The authors focus on the identifiability challenge: although transformers achieve high accuracy in ICL, their internal mechanism during inference is obscured by symmetry-breaking parametric choices. By enforcing layerwise feature- and label-permutation symmetry, the paper reveals and formalizes an explicit, algebraically readable, layerwise recursion, making the computation accessible for theoretical analysis and behavioral alignment. The emergent algorithm discovered is not gradient descent, but a coupled, label-aware, mean-shift dynamic, differentiating representation-space geometry shaping from parameter-space ERM analogies.
Figure 1: Enforcing task symmetries layerwise exposes the transformer’s coupled feature-label mean-shift algorithmic motif.
Methodological Framework: Symmetry Enforcement
The authors introduce a method that injects random block-permutation symmetry at each attention layer, compelling the network to implement the same computation in all symmetric coordinate systems. Rather than merely preserving functional outputs, this protocol denoises symmetry-breaking degrees of freedom, collapsing learned weights onto a low-dimensional, interpretable manifold that commutes with permutations. Empirical validation demonstrates that this procedure preserves the input-output mapping (prediction, local decision rule, context influence), enabling systematic reverse engineering.
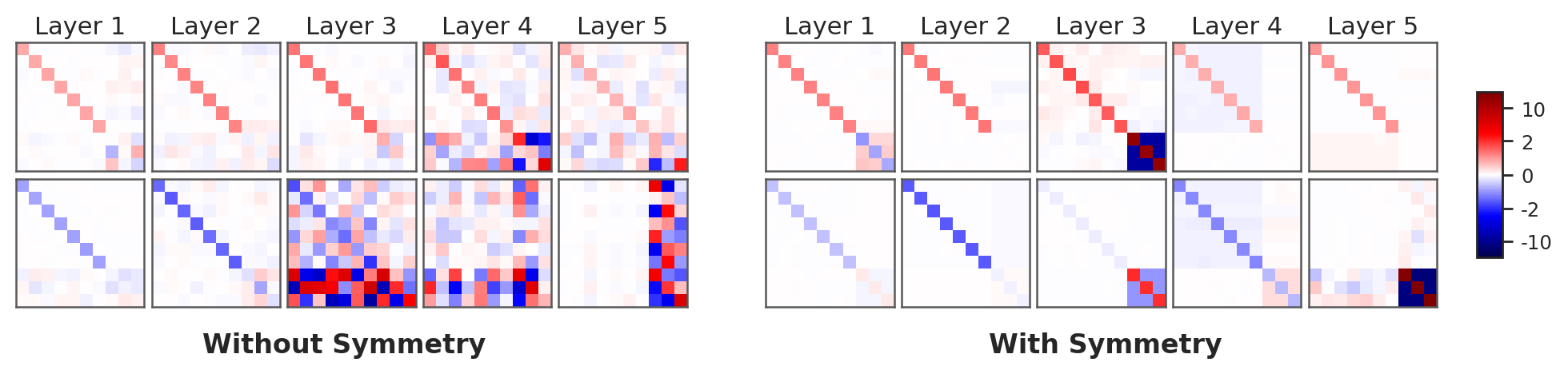
Figure 2: Enforcing symmetry converts visually noisy unconstrained weights (left) into structured patterns (right) that are easier to interpret.
From the symmetry-preserving transformer, the layerwise recursion is extracted: at each layer, attention is computed via a score matrix combining feature similarity and label agreement,
Aℓ=softmax(αXℓXℓ⊤+γYℓYℓ⊤)
Features and labels are then propagated in parallel,
Xℓ+1=Xℓ+α′AℓXℓ,Yℓ+1=Yℓ+γ′AℓYℓ
This process iterates over L layers, with depth directly corresponding to the number of algorithmic iterations. The transformation is not an optimizer-wrapper but a geometry-driven, dynamic clustering mechanism coupling the evolution of feature and label representations.
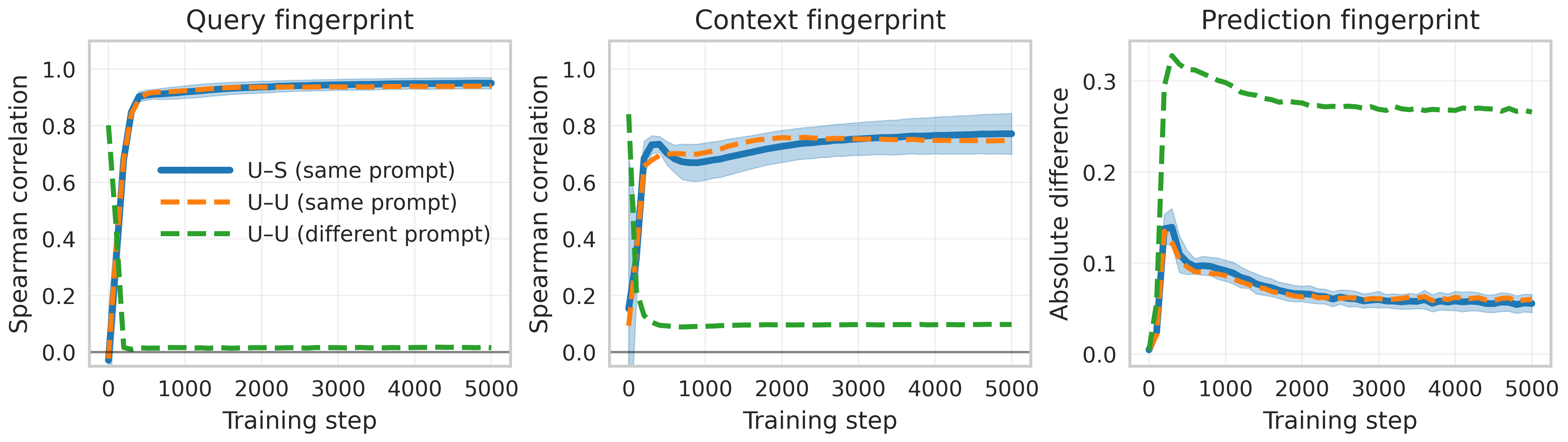
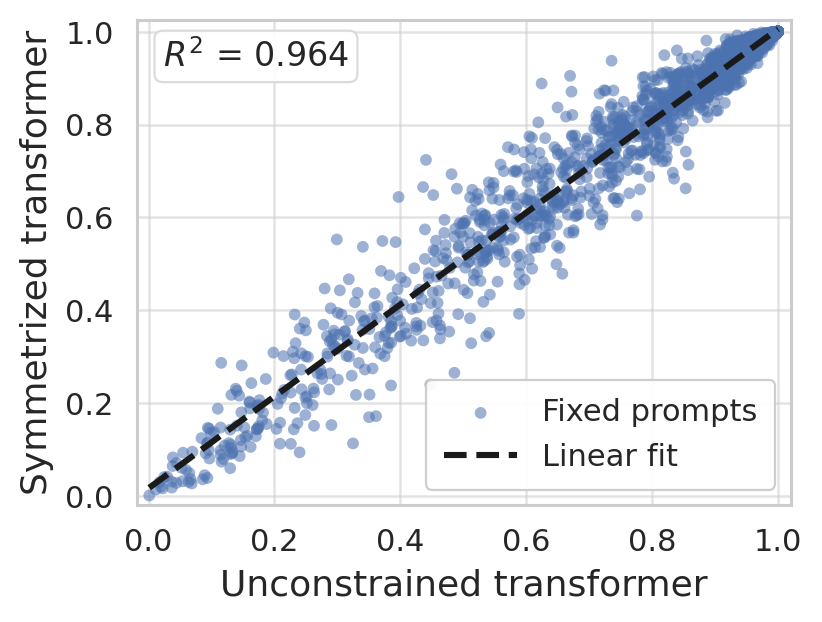
Figure 3: Behavioral fingerprinting confirms symmetrized transformer input-output alignment with unconstrained models across query, context, and predictions.
Mean-Shift Dynamics and Theoretical Analysis
In the regime γ/α≫1, the dynamics become label-driven and the attention matrix block-diagonalizes into classwise clusters. This yields a supervised mean-shift procedure, amplifying inter-class geometric separation. The authors provide proofs establishing that these coupled dynamics monotonically increase class centroids’ margin and that a test token is guided toward the correct cluster, with label logits growing exponentially under sufficient initial proximity.
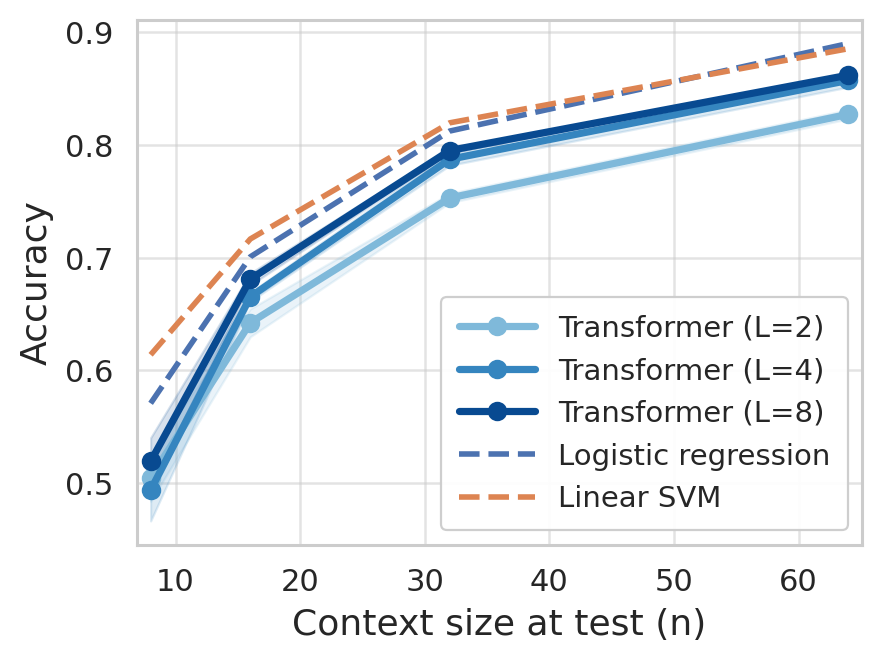
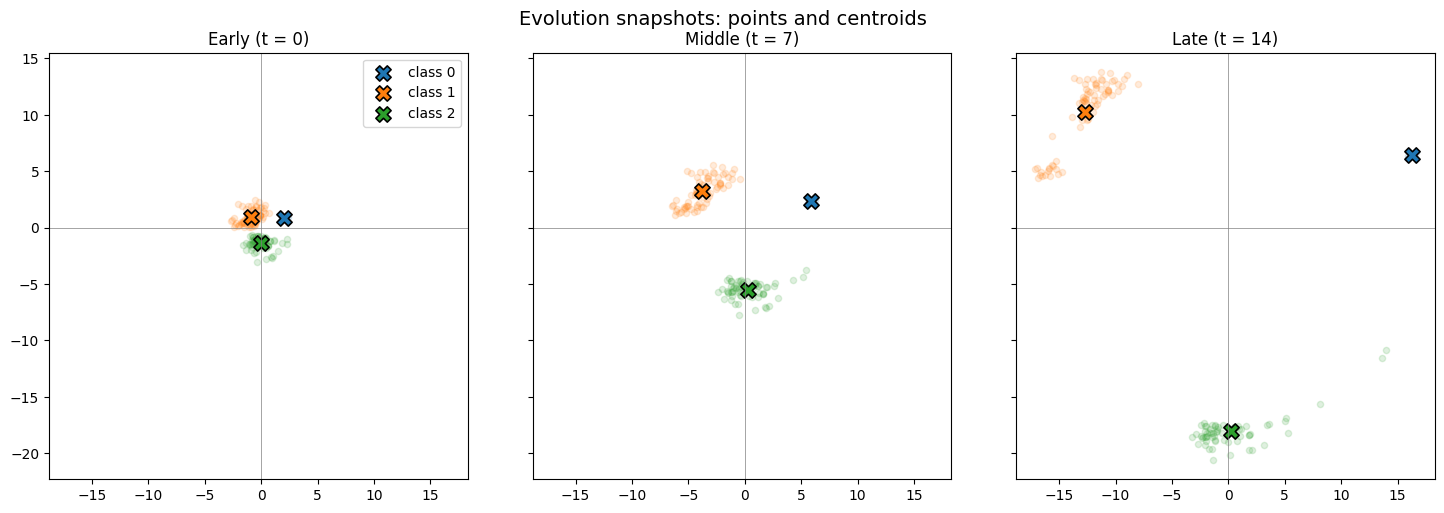
Figure 4: Left: Transformer performance matches classical baselines. Right: Simulated class centroid trajectories demonstrate amplified separation from label-driven mean-shift.
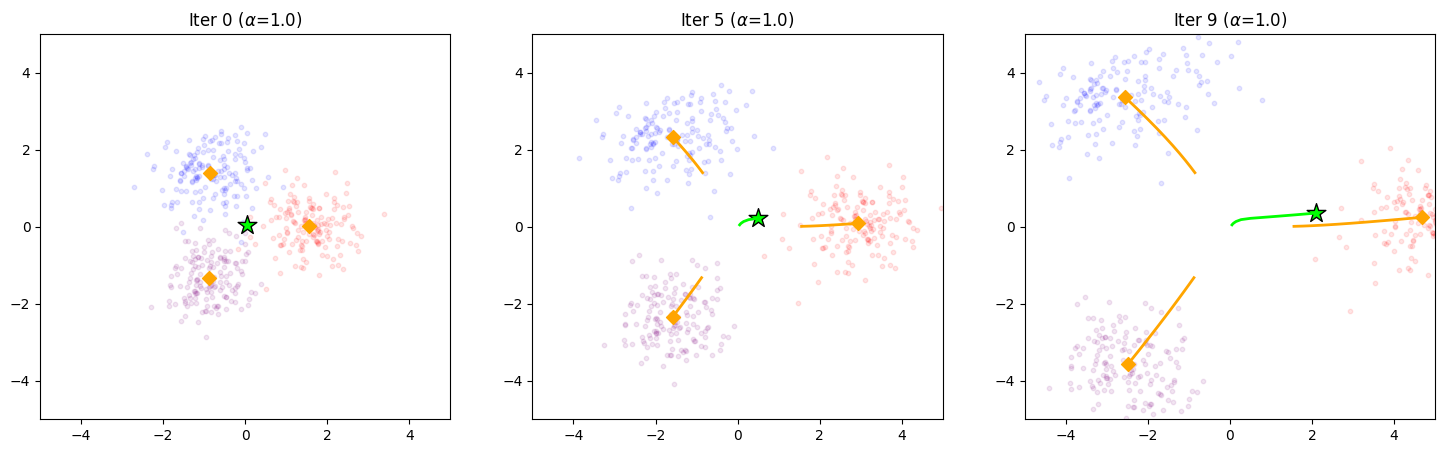
Figure 5: Test-point mean-shift trajectories: the probe accumulates evidence toward the correct cluster.
Robustness and Extension Across Classification Tasks
The extracted algorithmic motif is robust to several perturbations. When training on noisy labels, semi-supervised contexts (unlabeled tokens present), and nearest-centroid (Voronoi) classification, transformers retrained under symmetry again discover the same coupled mean-shift dynamics and cluster structure in weights. The method demonstrates:
- Noise tolerance: Mean-shift aggregation averages out random label flips, preserving class prototypes.
- Semi-supervised learning: Unlabeled points, via geometric alignment, improve decision boundaries.
- Nonlinear extension: The motif generalizes to prototype-based and piecewise-linear classification when clusters are well separated.
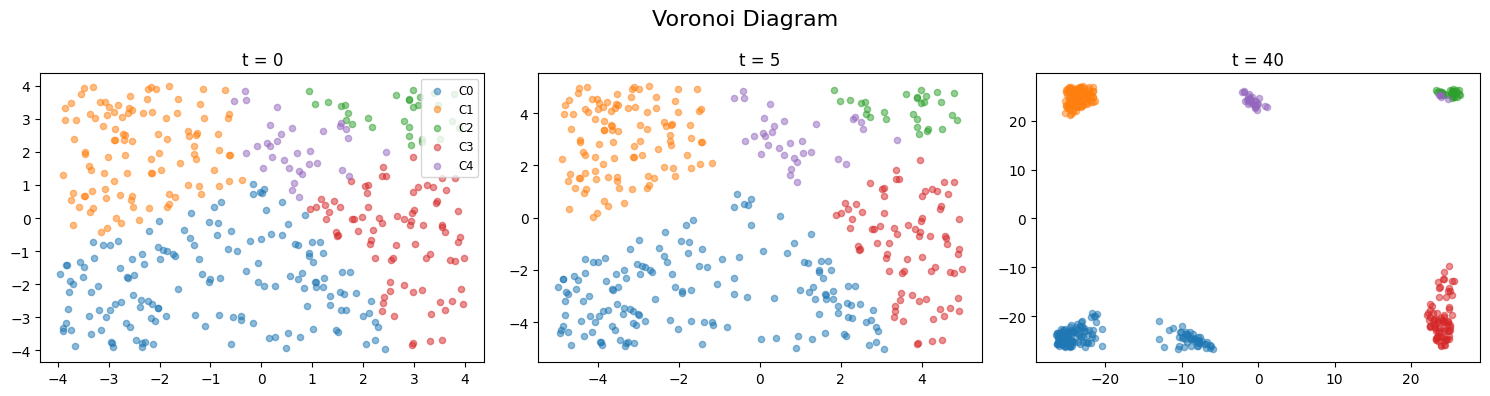
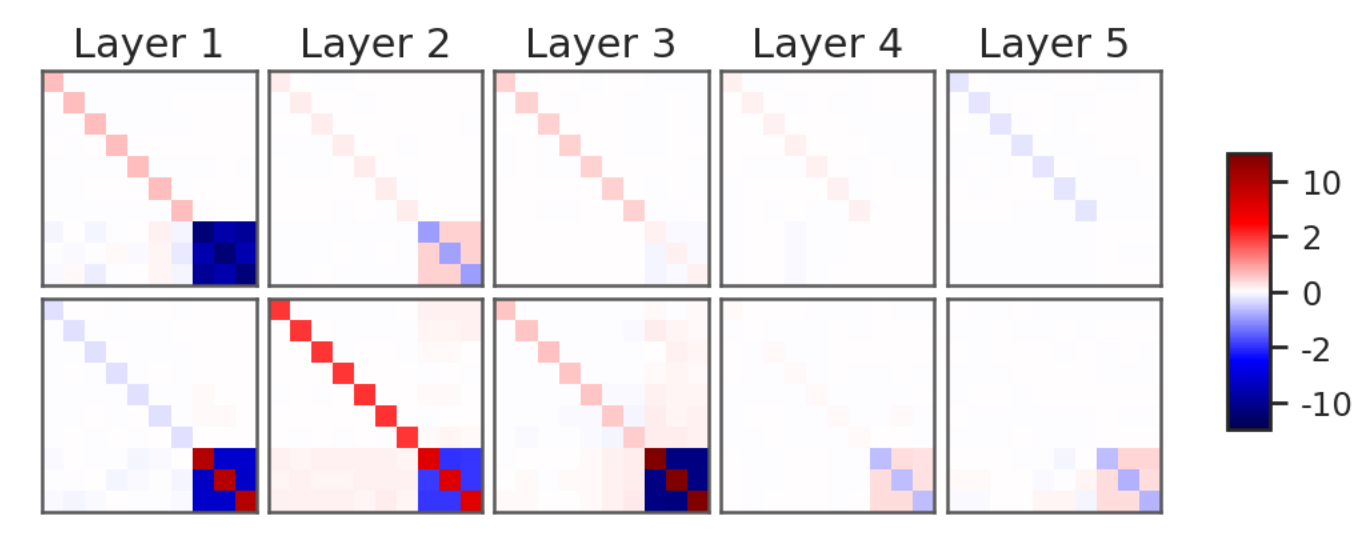
Figure 6: Top: Mean-shift simulation in Voronoi classification. Bottom: Learned weights encode same dynamics as block abstraction.
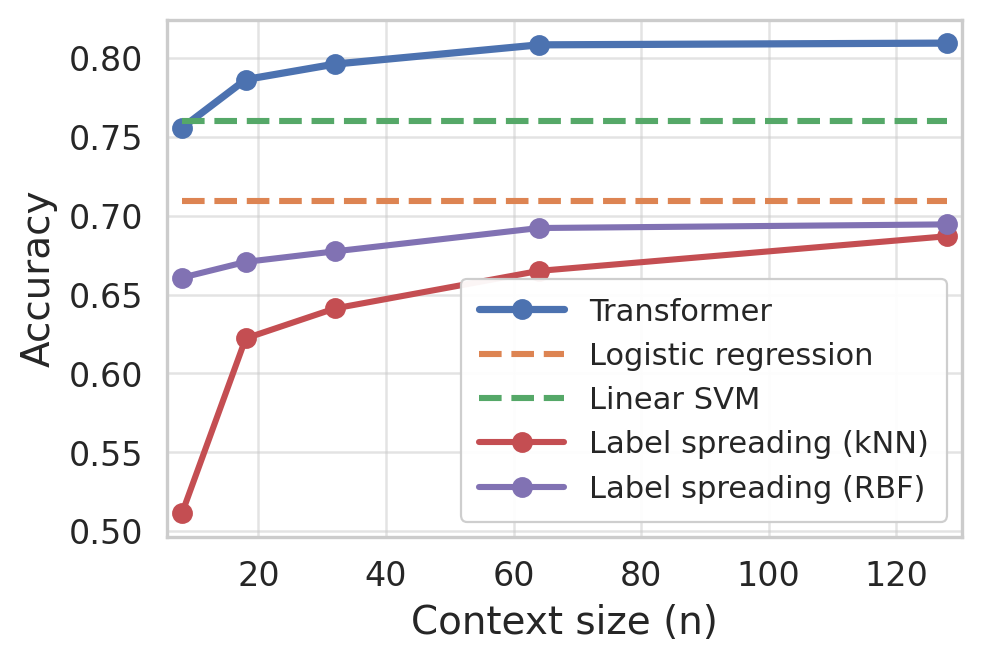
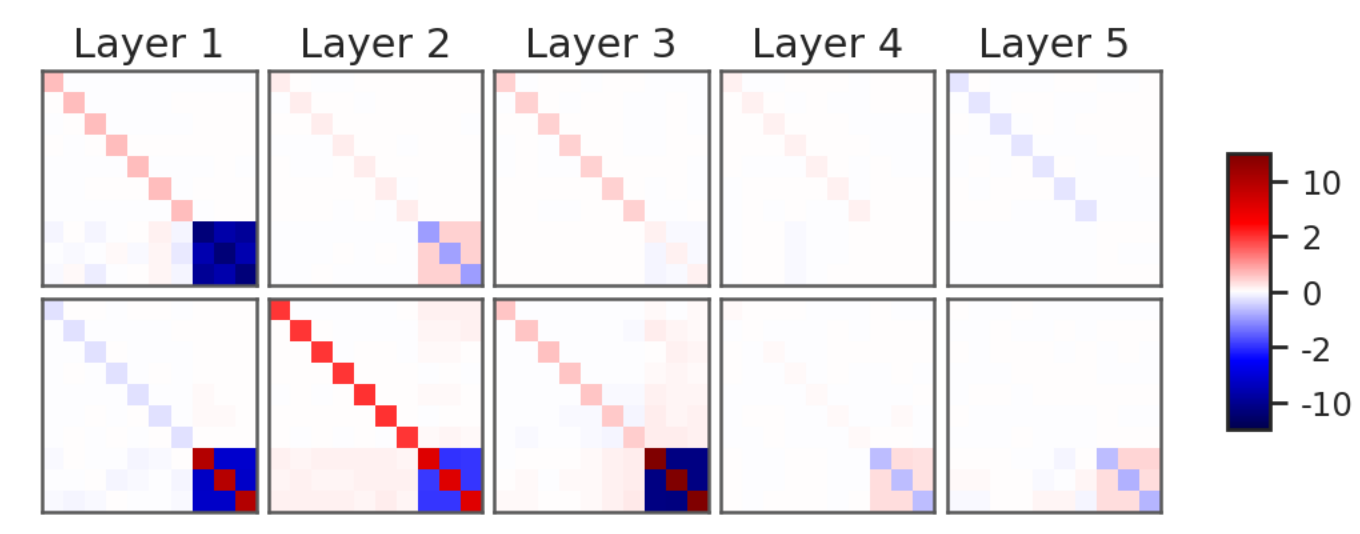
Figure 7: Semi-supervised ICL: Transformer accuracy improves with added unlabeled context, surpassing classical baselines as context size increases.
Weight Structure, Compression, and Fidelity
The symmetry-enforced abstraction enables progressive compression of learned weights. Clustering weights into diagonal and background parameters preserves nearly full accuracy and functional alignment. Fixing certain coefficients further reduces complexity to two parameters per layer (feature and label update strengths), with negligible loss in predictive fidelity.
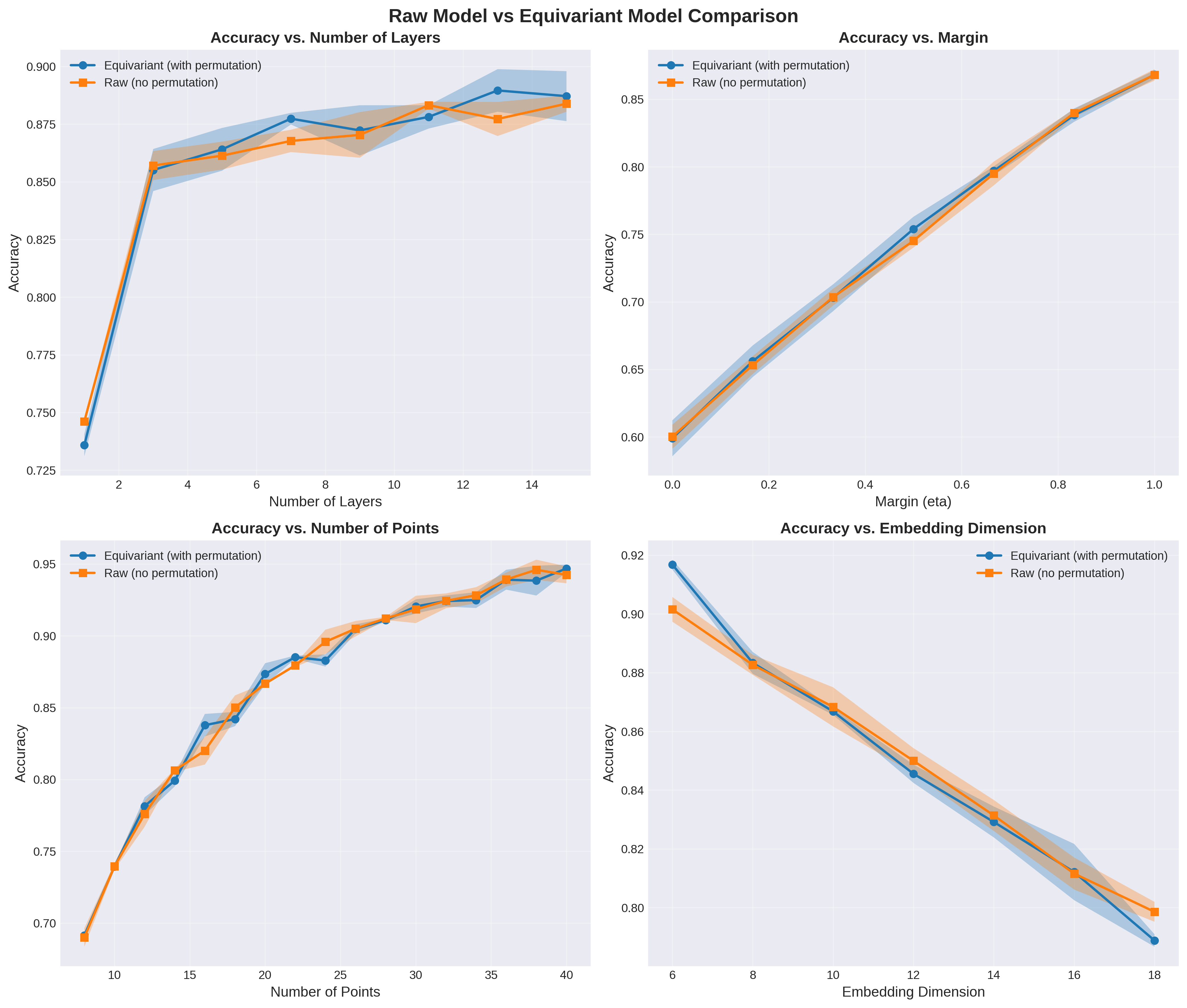
Figure 8: Predictive performance equivalence across unconstrained and symmetry-preserving architectures holds for varying problem instances and model depths.
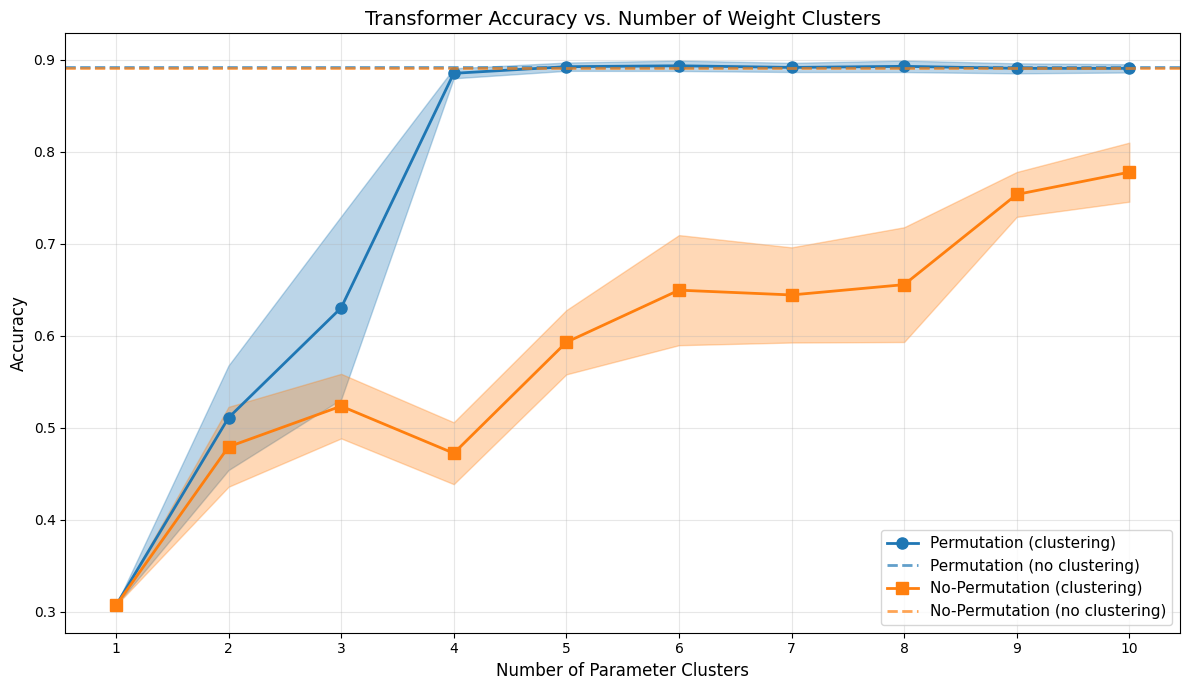
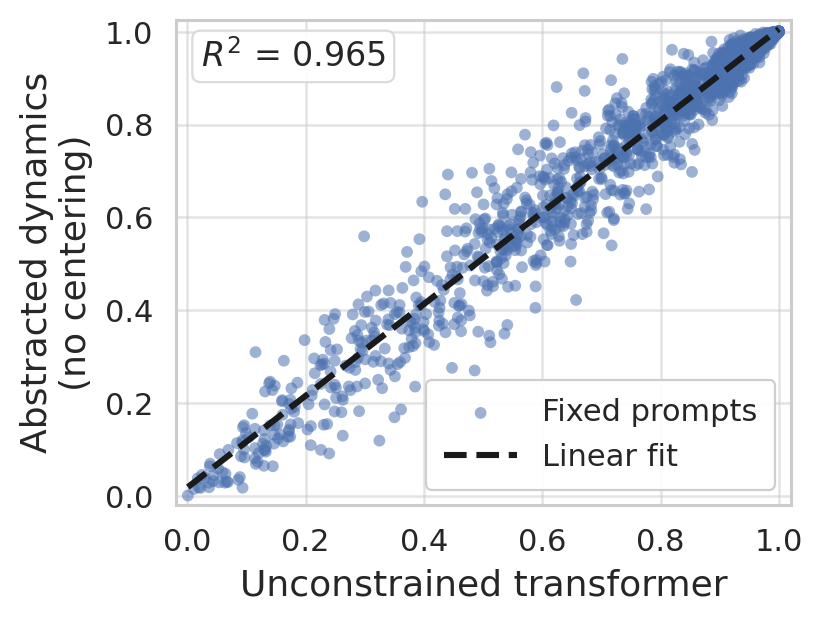
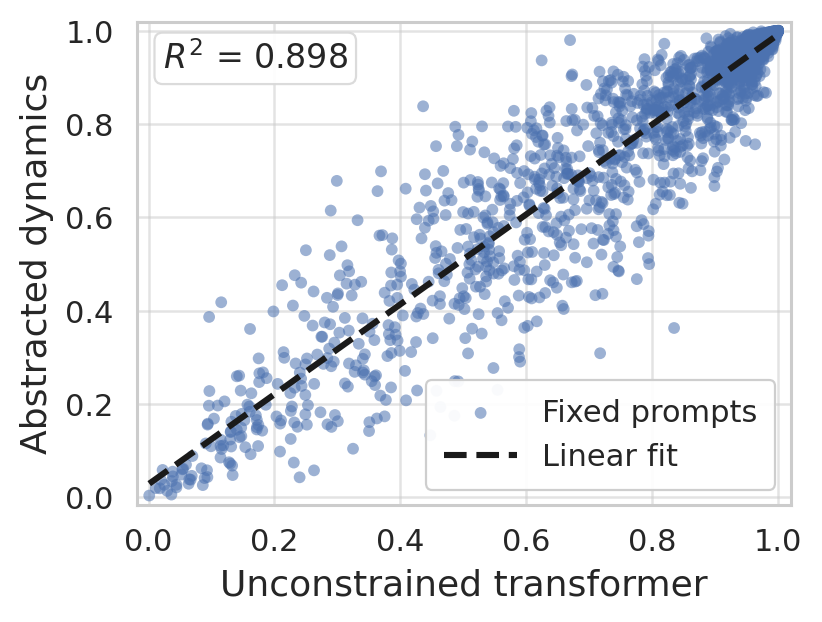
Figure 9: Weight clustering reveals that a minimal parameterization suffices to encode the inference-time algorithm.
Practical and Theoretical Implications
The identifiability protocol via layerwise symmetry enables systematic algorithmic extraction from trained transformers in settings where the target function obeys permutation, feature, and label symmetries, reducing the space of representations to canonical forms. This not only advances mechanistic interpretability but also facilitates theoretical analysis of inference dynamics, prediction robustness, and algorithm reusability across task variations.
The geometric, mean-shift-like mechanism uncovered aligns with diffusion and graph-based semi-supervised learning, but achieves superior performance in high-dimensional Gaussian regimes (where classical kernels are fragile) and is resilient to label noise. The findings emphasize the importance of symmetry-commuting architectural choices in algorithm distillation. The theoretical proofs provided for cluster separation and test token margin growth furnish concrete performance guarantees absent in heuristic analogies to gradient descent.
Future Directions
The method is well-suited to tasks obeying permutation symmetries and geometric class structures. Extending it to settings with richer symmetries, more complex data distributions, or non-permutation-driven mechanisms—such as circuit-based compositional reasoning or hierarchical tasks—is an important avenue. Automated identification and cataloging of task symmetries remains an open challenge. Applying this protocol to natural tasks may yield interpretable inference-time algorithms for practical applications and facilitate generalization analysis in pretraining regimes.
Conclusion
Layerwise symmetry enforcement transforms transformer ICL from an opaque high-performing predictor into an interpretable, algebraically tractable dynamical system implementing a label-aware, coupled mean-shift mechanism. The closed-form recursion extracted is validated empirically and theoretically, with strong behavioral alignment and robustness across classical, semi-supervised, and nonlinear tasks. This protocol offers new tools for algorithmic distillation, mechanistic interpretability, and theoretical understanding of representation-space dynamics in transformers, with broad implications for design and analysis of deep learning architectures (2604.11613).