- The paper introduces the Teacher-guided Robust Adaptation (TgRA) framework, leveraging a non-robust teacher to guide both clean and adversarial learning signals.
- It demonstrates that aligning adversarial outputs with fixed teacher predictions stabilizes optimization and mitigates the moving target problem during test-time adaptation.
- Empirical results on CIFAR-10 and ImageNet show TgRA substantially improves clean and robust accuracy compared to TRADES-U under distribution shifts.
Test-Time Robustness Adaptation from a Non-Robust Teacher
Problem Statement and Motivation
This work addresses the degradation of adversarial robustness under distribution shift for DNNs adapted at test time. The principal focus lies on unsupervised test-time adaptation (TTA), where a model, pretrained on a source distribution, is deployed in a target environment with access only to a small set of unlabeled samples. While TTA protocols can efficiently recover clean accuracy in the target domain, they rarely address—let alone preserve—adversarial robustness, especially when starting from non-robust backbones. The challenging question considered here is: Can robustness be improved via adaptation at test time when neither labels nor robust source models are available?
Technical Barriers
- Classical adversarial training (AT) frameworks require label supervision, which is absent in the TTA scenario.
- Robust distillation approaches assume a robust teacher, but in practical scenarios only non-robust models are available.
- Direct adaptation of standard AT objectives (e.g., PGD, TRADES) to the unsupervised and non-robust teacher setting leads to unstable optimization, with high sensitivity to hyperparameters and weakened robustness-accuracy trade-offs.
Teacher-Guided Robust Adaptation (TgRA) Framework
To address these issues, the paper introduces Teacher-guided Robust Adaptation (TgRA), a label-free robustness adaptation paradigm that consistently uses a non-robust teacher as a fixed semantic anchor for both clean and adversarial learning signals.
After formalizing the target scenario—where only a non-robust pretrained model and unlabeled target samples are available—the paper specifies the two main routes to unsupervised test-time robust adaptation:
- Student Self-consistency (e.g., TRADES-U): Replace the clean supervised loss with KL alignment against the teacher, but retain a standard TRADES self-consistency robustness regularizer (student output on clean vs. adversarial input).
- Teacher-anchored Consistency (TgRA): Use the non-robust teacher as the reference for both the clean prediction loss and the robustness objective, i.e., the student’s prediction on adversarial examples aligns to the teacher’s prediction on clean examples.
The framework is summarized below.
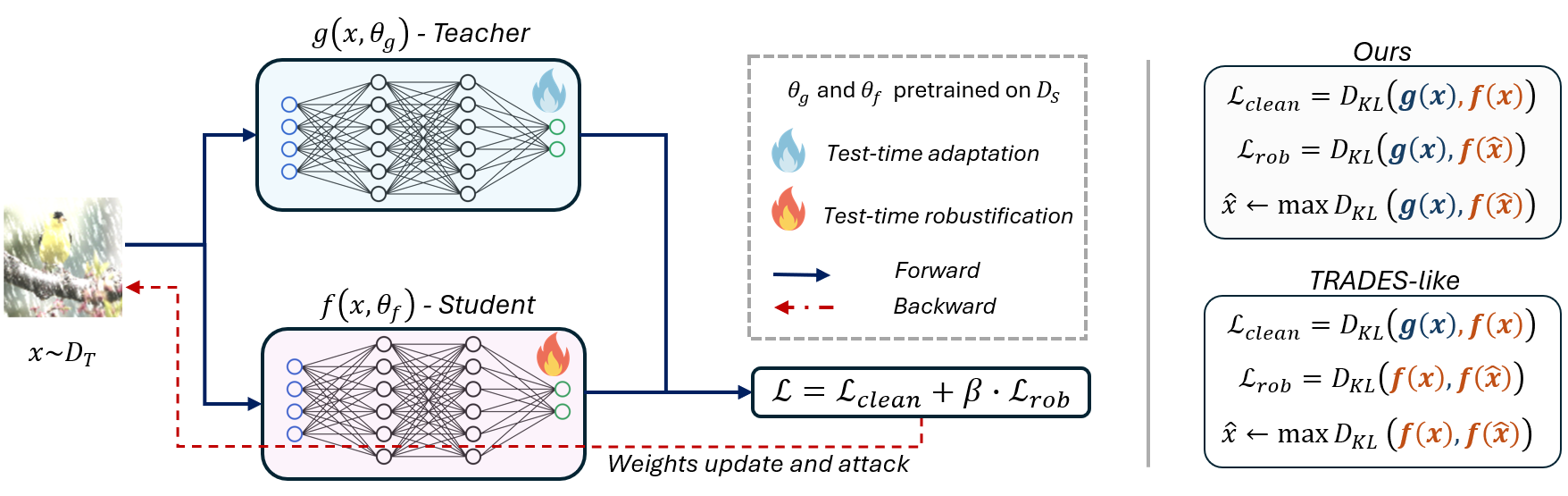
Figure 1: The Teacher-guided Robust Adaptation (TgRA) framework adapts a student network at test time, using the non-robust teacher's predictions as targets for both clean and adversarial losses.
This approach differs from prior distillation-based adversarial training techniques [e.g. (Chen et al., 2021)] in two core aspects: (i) only non-robust teachers are available (realistic for TTA), and (ii) the teacher guides both objectives, eliminating the instability introduced by a moving self-referential student distribution.
Theoretical Analysis of Robustness Optimization Stability
A central contribution is the theoretical analysis of stability under different regularization strategies. Let Rself be the self-consistency robustness regularizer, and Rteach the teacher-anchored variant. The paper shows:
- Self-consistency (Rself): Both input and reference distributions are parameter-dependent, creating a feedback loop where adversarial weight updates can destabilize clean predictions.
- Teacher-anchoring (Rteach): The teacher output is fixed, making the gradient only depend on the adversarial branch and thus drastically reducing the moving-target effect.
This distinction has practical consequences:
- The robustness-accuracy trade-off parameter β introduces instability in TRADES-U, while in TgRA it primarily adjusts the trade-off without pronounced adverse effects.
- Instability and performance collapse—particularly evident under non-robust initialization and large distribution shifts—are mitigated in TgRA due to the fixed reference.
Experimental Evaluation
The empirical evaluation spans CIFAR-10 and ImageNet under synthetic, controlled distribution shifts through photometric corruptions. Results are reported for varying adaptation set sizes, corruption severities, and β values, and target both clean and robust accuracies under adaptive attacks (PGD-20, PGN, Square). Both WideResNet-34 and high-capacity ImageNet backbones (ResNet-50, ViT-B/16) are considered.
Robustness under Distribution Shift
Initial analyses show that even mild corruptions can significantly degrade adversarial robustness in standard pretrained models, while clean accuracy remains stable. This exposes a marked robustness-generalization gap:
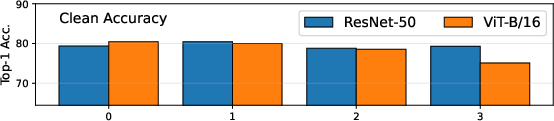
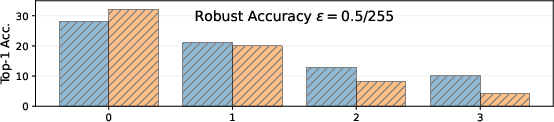
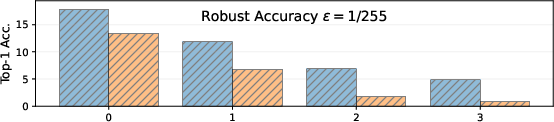
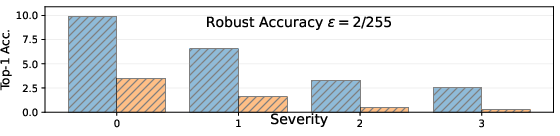
Figure 3: On ImageNet, robust accuracy drops sharply under photometric shifts, while clean Top-1 accuracy is relatively invariant across corruption severities and ϵ budgets.
Numerical Results: CIFAR-10 and ImageNet
Extensive comparisons demonstrate the superiority of TgRA over the TRADES-U adaptation baseline:
- Stability: Across all values of β and severities, TgRA yields stable clean and robust accuracy curves, with minimal sensitivity to hyperparameters.
- Performance: On CIFAR-10 with severe corruptions, TgRA outperforms TRADES-U by over 16 points in clean accuracy and 11 points in robust accuracy, demonstrating consistent advantages as the shift increases.
- Data Scarcity Regime: When only limited target samples (e.g., 50% split of CIFAR-10 test set) are available, both baselines’ performance degrades, but that of TgRA remains considerably higher and less prone to collapse.



Figure 2: Training dynamics on CIFAR-10—TgRA maintains high clean and robust accuracy, especially under increased distribution shift and throughout the learning process.


Figure 4: On CIFAR-10, final clean and robust accuracy (PGD-20) demonstrate significant gains for TgRA as severity increases, compared to self-consistency adaptation.
ImageNet experiments show similar trends: teacher anchoring is robust to high photometric corruption severities and adversarial perturbation budgets, and performs at least on-par with, or surpasses, fully supervised robust fine-tuning with oracle labels.
Training Dynamics
Throughout adaptation, TgRA exhibits smoother optimization, rapid robustness recovery, and avoids the fast initial accuracy drop prevalent in TRADES-U. This is especially marked under non-zero distribution shift and non-robust initialization, confirming the theoretical arguments.
Practical and Theoretical Implications
This work demonstrates that robustness can be substantially improved at test time using only unlabeled target samples and non-robust supervision. The principled formulation of TgRA addresses the primary failure mode of prior test-time adversarial adaptation schemes—namely, the instability from self-consistency regularizers initialized from non-robust weights.
On the practical side:
- This removes the necessity for robust source models, making adversarial robustness achievable in deployment-centric, real-world settings.
- The resilience to hyperparameter tuning and data limitations increases viability in automation and safety-critical deployment—areas where labeled data is rare and distribution shift is common.
Theoretically, the moving target problem in robustness optimization is clarified and resolved; the separation between reference and adaptation branches proposed here could be adapted to other forms of post-deployment self-training.
Outlook and Future Directions
Advancing this framework opens several promising lines:
- Enhanced teacher adaptation: More sophisticated or continual test-time adaptation strategies for the teacher could further amplify the effect, as teacher guidance quality directly impacts student robustness.
- Continual and nonstationary environments: Extending to dynamic domains where the target distribution incessantly evolves calls for further analysis of anchor stability and adaptation efficacy.
- Self-supervised and contrastive teacher signals: Exploring alternative label-free anchors for even greater generalization and adaptation flexibility in diverse modalities.
Conclusion
The paper establishes a new direction for adversarial robustness enhancement at test time, showing that with a simple and theoretically sound teacher-anchored adaptation objective, substantial clean and robust accuracy gains are possible, even from non-robust initialization and under significant distribution shift. These results have direct implications for robust deployment of machine learning systems in open-world and resource-limited settings, and lay groundwork for future research in robust, self-supervised, and continual post-deployment adaptation.
Reference:
"Learning Robustness at Test-Time from a Non-Robust Teacher" (2604.11590)