- The paper presents ET3, a test-time defense that minimizes energy functions to restore correct classifications in LVLMs facing adversarial perturbations.
- It employs a lightweight gradient descent step within an ε-ball, achieving robust accuracy boosts of 7–12% across various benchmarks.
- Theoretical analysis and empirical evaluations confirm that ET3 effectively counters adaptive threats while preserving clean accuracy.
Energy-Guided Test-Time Defense for Adversarial Robustness in LVLMs
Introduction and Motivation
Large-scale Vision-LLMs (LVLMs) and their foundational encoders (notably, CLIP and its derivatives) have become central to numerous multimodal tasks by enabling highly flexible, zero-shot generalization. Despite strong empirical performance, LVLMs remain acutely vulnerable to imperceptible adversarial perturbations targeting the visual stream, which cascade and compromise downstream tasks such as captioning and VQA. Prevailing defense strategies center around adversarial training (AT), which, while effective, presents limitations: transferability to unseen attacks is limited, and computational overhead, both training and inference, remains substantial.
Recently, gradients of progress have emerged through Test-Time Transformations (TTT), which dynamically refine input samples at inference to mitigate adversarial effects. However, these methods typically necessitate extra models, data augmentations, or repeated forward/backward passes, introducing notable inference costs. Addressing these constraints, the paper "A Provable Energy-Guided Test-Time Defense Boosting Adversarial Robustness of Large Vision-LLMs" (2603.26984) proposes ET3: an energy-guided, training-free TTT defense that directly exploits the EBM interpretation of discriminative classifiers.
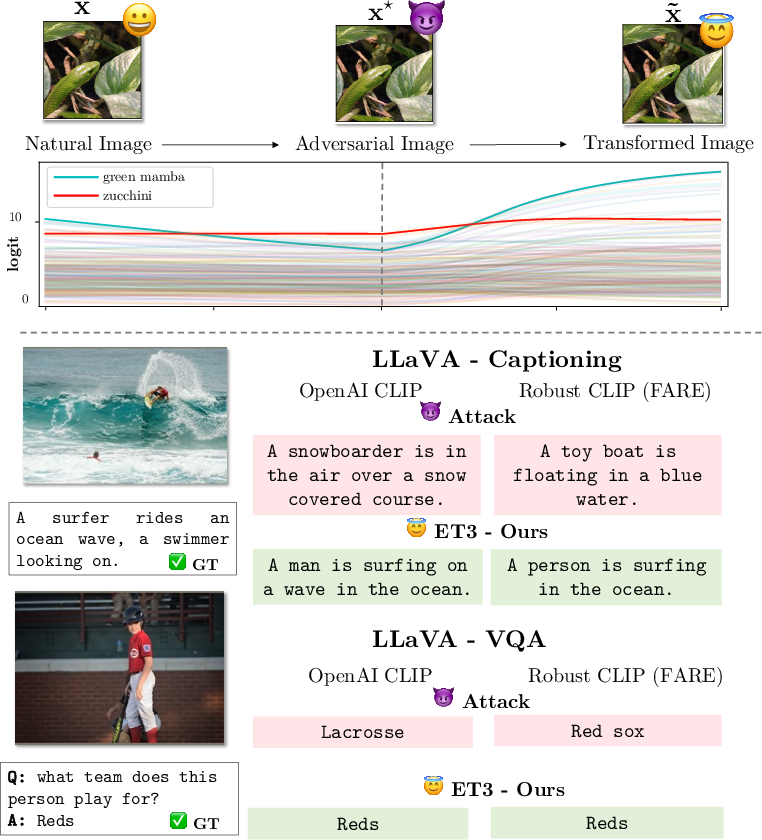
Figure 1: ET3 corrects the output of a robust classifier, restoring the correct classification even when the clean label is not the second most likely; it also boosts downstream robust accuracy for LVLMs like LLaVA.
The defense leverages the observation that a softmax classifier naturally induces an energy function over inputs:
E(x)=−log(k=1∑Kexp(fθ(x)k))
where fθ are model logits for input x. Adversarial samples typically yield higher energy, shifting off the data manifold.
Defense Mechanism
Given a test-time sample x (whether clean or adversarial), ET3 seeks a perturbed version x′ within an ϵ-radius that minimizes E(x′). The optimization is lightweight (typically one or two iterations) using gradient descent on the energy with projection back to the ϵ-ball:
x(t)=ΠBϵ(x)(x(t−1)−α∇xE(x(t−1)))
ET3 thus directly enforces on-manifold restoration without the need for generative models or external denoising modules. Crucially, this transformation operates entirely at inference time and is agnostic to the model’s training procedure, making it deployable with any classifier or CLIP-based vision encoder.
Extension to Zero-Shot CLIP and LVLM
The method is seamlessly adapted to zero-shot classification (via CLIP) and LVLMs: for CLIP, the textual label set used in zero-shot inference is repurposed as the energy’s reference set, generalizing across tasks and datasets. For LVLMs, the refined input is injected into the vision encoder, with language generation layers unchanged, thereby boosting downstream robustness (captioning, VQA, etc.).
Theoretical Guarantees
A key contribution is a theoretical guarantee for the efficacy of ET3 on robust (specifically, locally linear) binary classifiers. The paper shows that under mild local linearity and gradient norm separation assumptions (frequently realized by robust architectures), the energy minimization will restore the sample to correct classification regardless of whether the input is clean or adversarial. The constructive condition involves the gradient ratio between the correct and incorrect label logit directions, with formal bounds in the main theorem:
(Figure 2)
Figure 2: Illustration of the ET3 defense dynamics: the transformation gradient opposes the adversarial attack, restoring the correct logit margin when local gradient norms are favorably separated.
Empirical analysis reveals most robust models exhibit high gradient ratios (i.e., the energy gradient points more strongly toward the correct label), validating that the theoretical precondition is met in practice for clean and adversarial samples.
Empirical Evaluation
Zero-Shot Classification and LVLMs
The paper evaluates ET3 on state-of-the-art robust CLIP vision encoders (TeCoA, FARE) and diverse LVLMs (notably LLaVA), under strong threat models with ℓ∞-norm attacks (AutoAttack, APGD). Key findings:
- Robust accuracy boosts: For TeCoA and FARE, ET3 consistently increases robust accuracy by 7–12% under substantial attacks (e.g., fθ0), with minimal impact on clean accuracy.
- Complementarity: When composited with other defense strategies (ensemble augmentations, prompt-tuning, robustified CLIP encoders), ET3 yields additive gains, outperforming prior TTT and test-time purification methods across 14 datasets.
Downstream Captioning and VQA
ET3 outperforms baseline and prior TTT defenses for LVLMs, improving robust performance across captioning (COCO, Flickr30k) and VQA (TextVQA, VQAv2) domains—again, with negligible clean task degradation.




Figure 3: Example captions show ET3 rectifying adversarially induced errors and further refining robust model outputs on CLIP, TeCoA, and FARE backbones.







Figure 4: ET3 enables more robust short-form VQA: adversarially induced errors are corrected even in robust model variants.
Robust Classifiers and Adaptive Threats
On robust classifiers from RobustBench, ET3 increases worst-case robust accuracy (against adaptive threat models using BPDA and transfer attacks) over competitive TTT/purification baselines by 2–3%, e.g., boosting a ResNet-50 from 34.96% to 37.70% robust accuracy under worst-case threat.
Comparative and Ablation Analyses
- Inference Efficiency: ET3’s computational overhead is minimal: a single gradient step increases inference time by fθ12–3% on contemporary GPU hardware.
- Fairness to Attack Budget: Although the default projection uses fθ2, even with matched fθ3 projection, ET3 yields significant improvements.
- Label Set Choice: Using large label sets (e.g., ImageNet-21k) as energy references provides slightly higher robust accuracy, while curated sets minimize clean accuracy drop.
- Single-Step Variants: Robustness is increased even with a one-step minimization protocol, allowing flexibility in compute–accuracy tradeoff.
Implications, Limitations, and Future Directions
This work establishes ET3 as a general-purpose, plug-and-play TTT defense grounded in EBM principles and backed by formal proof. Its implications are both practical—enabling simple deployment with robust pretrained encoders—and theoretical, as it demonstrates that energy-guided inference alone can restore correct predictions provided the classifier's local landscape is sufficiently regular.
The main limitation lies in scenarios where the two key assumptions (local linearity and ground-truth gradient dominance) are violated, such as in certain highly non-linear or poorly separated classifier regimes. Nevertheless, multiple robust training protocols empirically support these assumptions across architectures.
Future directions include: (1) explicitly regularizing networks during training to maximize the local linearity radius and gradient separation, thereby amplifying ET3’s efficacy; (2) extending energy-guided TTT to multi-modal generative models; (3) integrating learned energy models or more sophisticated label subset selection at test time for sharper bounds and more controlled defense/accuracy tradeoffs.
Conclusion
The ET3 defense demonstrates that energy-guided, training-free TTT on top of robust visual encoders enables significant, theoretically motivated improvements in adversarial robustness for classification, zero-shot recognition, and vision–language interpretation. Its lightweight, architecture-agnostic nature and provable properties position it as a strong candidate for fortifying future LVLM systems against both current and adaptive adversarial threats (2603.26984).