- The paper introduces AdvFLYP, a new adversarial fine-tuning method that emulates the original CLIP pretraining regimen to enhance zero-shot robustness.
- It replaces traditional cross-entropy based adversarial fine-tuning with a contrastive loss on noisy web-scale image-text data for improved transferability.
- Empirical results across 14 datasets demonstrate AdvFLYP's significant gains in robust accuracy while maintaining clean performance under multiple attack strengths.
Finetune Like You Pretrain: Enhancing Zero-shot Adversarial Robustness in Vision-LLMs
Introduction
This paper analyzes and addresses the limitations of existing adversarial fine-tuning (AFT) paradigms for vision-LLMs (VLMs), particularly CLIP, regarding zero-shot adversarial robustness. Current solutions primarily perform AFT on well-curated classification datasets (e.g., ImageNet) using cross-entropy losses, focusing on aligning adversarial images with class labels. The authors demonstrate that such methods inherently degrade zero-shot capabilities and yield poor transferability across domains due to deviations from the original pretraining distribution and objectives of VLMs. To counter these deficiencies, the paper introduces AdvFLYP, an AFT paradigm that strictly follows the pretraining regime—finetuning the vision encoder on noisy web-scale image-text pairs via a contrastive loss, as was used during pretraining. Regularization at both the logit and feature levels is also introduced to mitigate embedding shifts induced by adversarial perturbations over noisy data.
Limitations of Mainstream AFT Paradigms
Typical AFT strategies construct adversarial examples directly on labeled proxy datasets and fine-tune the vision encoder to classify these examples correctly via supervised cross-entropy loss.
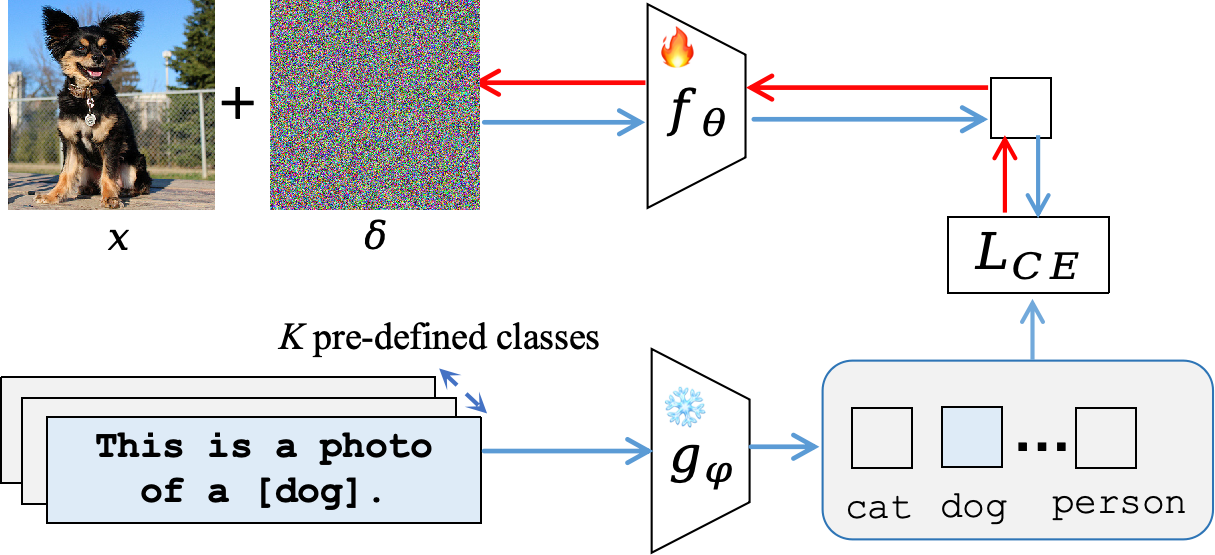
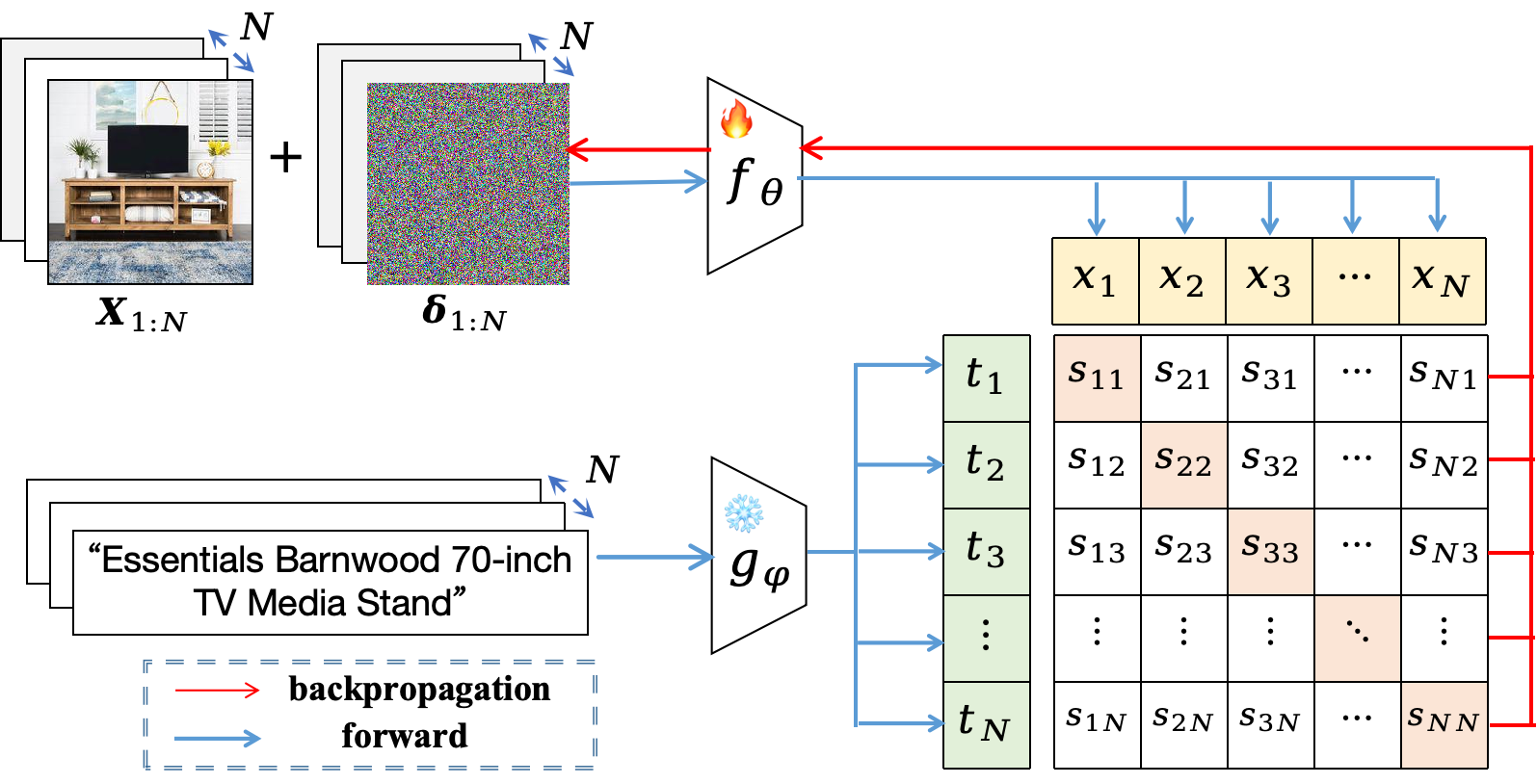
Figure 1: Mainstream AFT aligns adversarial images to class labels using cross-entropy on curated proxy datasets, neglecting the original pretraining objective and data distribution.
This approach significantly diverges from the intrinsic CLIP pretraining paradigm, which utilizes large-scale, noisy, and diverse web image-text pairs and a contrastive loss to establish multimodal correspondence. While such AFT can provide some gains in adversarial robustness, it imposes strong biases toward the proxy dataset, causes rapid overfitting, degrades the model's zero-shot capabilities, and yields limited robustness transferability to out-of-domain samples. This is further compounded by the misalignment between the task (classification) and the original pretraining objective (contrastive image-text matching), as well as the risk of intra-class feature collapse due to repeated alignment to the same text prompt.
The AdvFLYP Paradigm
To address these structural deficiencies, AdvFLYP proposes adversarial fine-tuning that adheres as closely as possible to the original pretraining patterns of CLIP.
The core tenets of AdvFLYP are:
- Training Data Selection: Utilize large-scale, noisy web image-text pairs (sampled from LAION-400M) instead of clean, curated, labeled datasets.
- Contrastive Objective: Employ the contrastive loss as in pretraining, aligning each adversarial image with its own text rather than with a fixed class prompt.
- Batchwise Attack Construction: Produce adversarial examples by maximizing the contrastive loss over entire batches, diverging from sample-wise adversarial generation.
- Regularization: Introduce regularization at both the logit and feature levels to control for potential embedding distortion caused by aligning adversarial and noisy images.
The AdvFLYP formulation proceeds as follows:
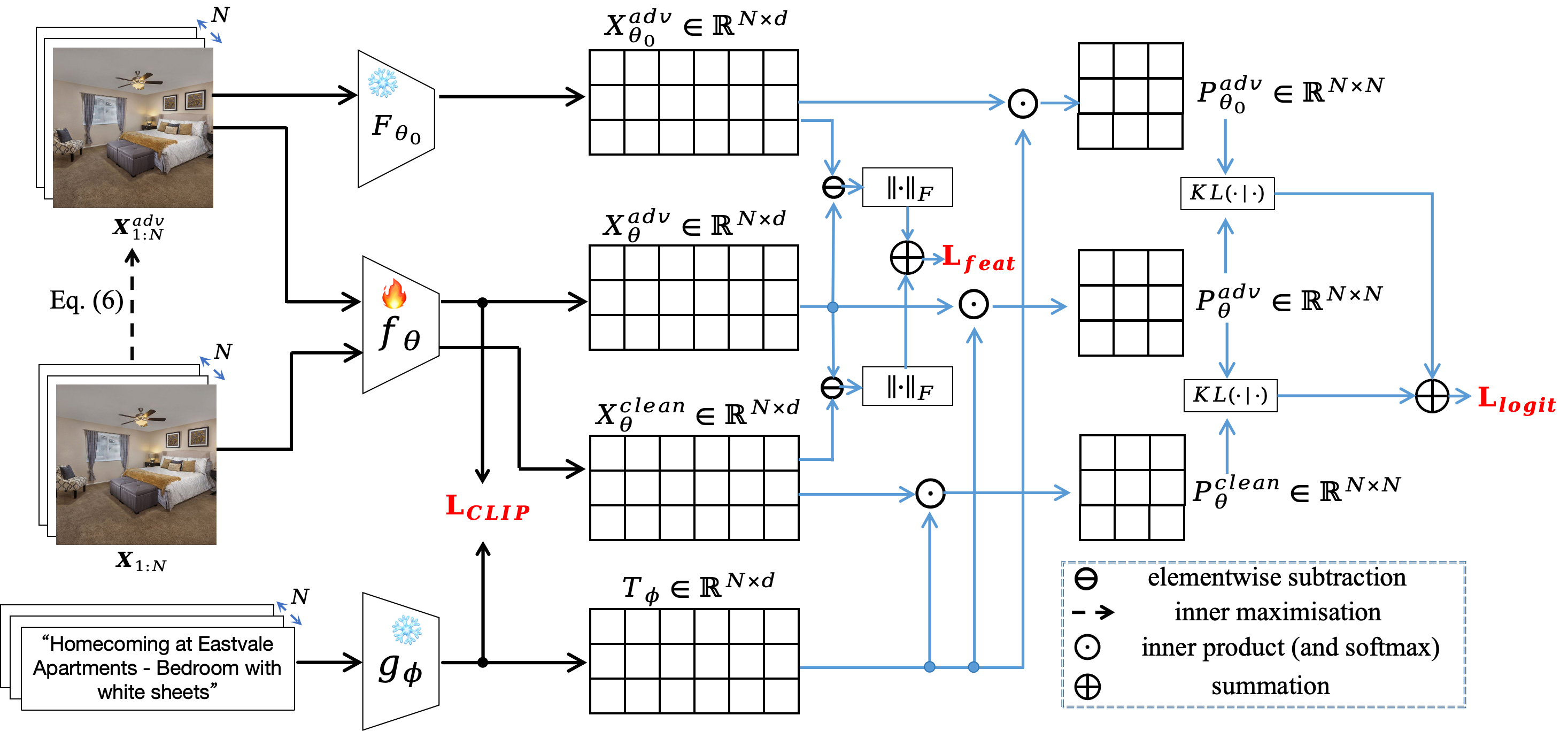
Figure 2: Overview of AdvFLYP's loss function, incorporating the original CLIP contrastive loss, logit-level, and feature-level regularization to penalize both output and embedding shifts between adversarial and clean samples.
Given a batch of N image-text pairs (xi,ti), a perturbation δi is assigned to each image, optimized to maximize the batchwise contrastive loss. The vision encoder is then trained to minimize this loss on the adversarial images paired with their texts. Logit regularization encourages the adversarial image logits to remain close (via KL divergence) to those of clean images, both on the current and original (frozen) models. Feature regularization penalizes the embedding shift at the image feature level, further preserving the structure of the representation space under perturbation.
This approach is intentionally designed to avoid any explicit biases toward downstream classification tasks, focusing exclusively on aligning adversarial and clean images to their respective captions as in pretraining.
Empirical Evaluation
Experiments were conducted on 14 downstream datasets, spanning general object recognition (e.g., CIFAR-10/100, Caltech-101/256), fine-grained domains, scenes, and texture recognition. Robustness was measured under strong adversarial attacks (PGD, CW, AutoAttack) with ϵ∈{1/255,2/255,4/255} and compared against established AFT methods, including TeCoA, PMG-AFT, TGA-ZSR, and unsupervised FARE.
AdvFLYP consistently outperforms all baselines in average robust accuracy across the evaluation suite, with an even larger margin under higher attack strengths, and crucially with minimal degradation to clean accuracy (Tables show up to 2.5–4.4% higher adversarial accuracy than best previous methods, depending on attack strength).
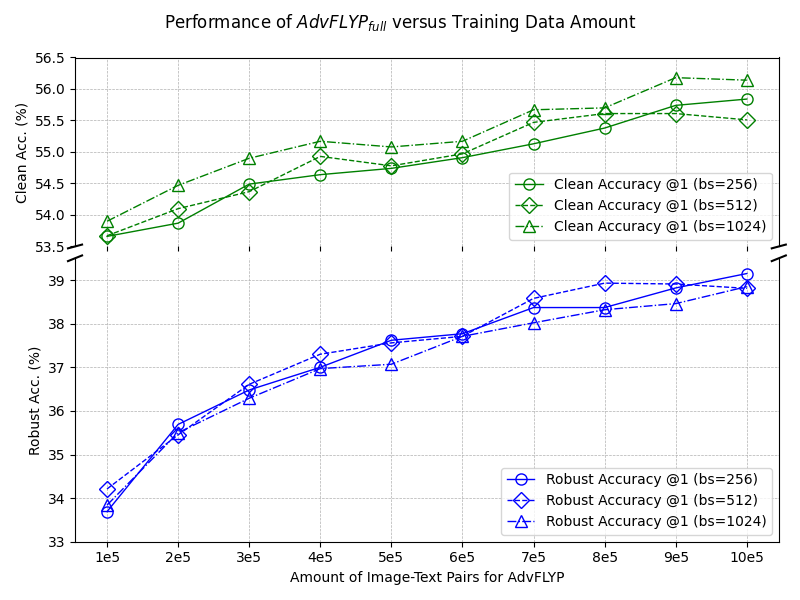
Figure 3: Performance of AdvFLYP and regularized AdvFLYP (AdvFLYPfull) compared to mainstream methods across multiple datasets and increasing attack strengths, showing superior robustness and accuracy.
Notably:
- **AdvFLYP's robust accuracy at ϵ=1/255 attains 39.15% (PGD attack) compared to 35.85% (PMG-AFT) and 33.77% (TeCoA), with improvement persisting to ϵ=4/255.
- The regularized AdvFLYP (AdvFLYPfull), with both logit and feature-level penalties, further boosts robust accuracy while yielding best-in-class clean image accuracy among all supervised fine-tuning schemes.
- Ablations show that logit regularization predominantly benefits adversarial robustness, while feature regularization significantly preserves clean accuracy, a pattern in contrast to previous findings in supervised AFT.
- AdvFLYP's robustness gain generalizes better across out-of-distribution datasets, due to strict adherence to the pretraining regime.
Analysis of Data and Objective Design
The findings highlight three crucial design dimensions for adversarial fine-tuning of VLMs:
- Data Distribution: Adversarial examples must be constructed on noisy, diverse web image-text pairs that mimic pretraining, not on curated, labeled datasets. Such web data prevents overfitting and maintains generalization.
- Training Objective: The contrastive loss remains critical for both zero-shot and robust abilities. Ablation demonstrates classification-oriented losses (cross-entropy) induce catastrophic forgetting of zero-shot capabilities and restrict robustness to the proxy dataset.
- Regularization: In high-noise regimes, feature-level regularization becomes vital for controlling embedding collapse, while logit-level regularization is key for preserving transferability of robustness.
Empirically, models fine-tuned on clean or captioned ImageNet fail to match AdvFLYP's transfer robustness. Furthermore, expanding the AdvFLYP web dataset size and batch size yields monotonic improvements in both clean and robust accuracies.
Practical and Theoretical Implications
From a practical perspective, AdvFLYP establishes that maximizing alignment with the pretraining protocol, including data and objective, is paramount for effective adversarial robustification of VLMs. This insight suggests that robustification for other foundation models (e.g., large vision or multimodal transformers) will similarly require process-matched fine-tuning pipelines rather than standard supervised schemes.
Theoretically, the results also contradict common wisdom from unimodal adversarial training—that using curated and labeled data is optimal when transfer robustness is desired. For VLMs, the complexity and noisiness of web data, and the structure of contrastive supervision, are essential ingredients for generalizable robustness.
Future Research
Directions include scaling AdvFLYP to larger vision-language backbones, investigating optimal web data sampling for robustness, and extending the paradigm to other cross-modal foundation models (e.g., video-language, audio-image). Moreover, a nuanced exploration of regularization strategies to further balance clean/robust trade-offs and systematic studies of batch size effects in batchwise adversarial construction would be valuable.
Conclusion
AdvFLYP challenges and replaces the prevailing AFT practices for VLMs by advocating a direct emulation of the pretraining process during adversarial fine-tuning. By switching from labeled proxy data and cross-entropy losses to noisy image-text pairs and contrastive losses, and by adding targeted regularization, AdvFLYP yields superior zero-shot adversarial robustness and generalization capability. This work serves as a paradigm shift, stressing that respecting the pretraining recipe is essential for robust foundation vision-language representation learning.