- The paper demonstrates that decoupling knowledge-enhanced question synthesis from trace distillation via a two-stage RL curriculum leads to rare disease improvements up to +5.93%.
- It leverages a hybrid of synthetic and real data with controlled knowledge injection to optimize the tradeoff between rare disease specialization and general domain performance.
- Empirical results across multiple benchmarks validate the model’s stability and efficiency, with offline pseudo-labeling preventing reward hacking.
Eliciting Medical Reasoning with Knowledge-Enhanced Data Synthesis and Semi-Supervised Reinforcement Learning
Motivation and Problem Context
Accurate complex reasoning in medical AI systems is critically constrained by the lack of high-quality annotated data, with data scarcity being most acute for clinically important but underrepresented subdomains such as rare diseases. Analysis of current medical QA datasets reveals that only 22% are reasoning-intensive and a mere 3% pertain to rare disease contexts.

Figure 1: The overwhelming majority of questions in current medical datasets are not reasoning-intensive; rare diseases are severely underrepresented.
Existing medical LLM post-training pipelines tend to use proprietary LLMs to distill Chain-of-Thought reasoning traces and then apply RL from human feedback or direct preference optimization. This two-stage approach (trace distillation followed by RL) is expensive, primarily addresses domains well-represented in the supervised data, and demonstrates significantly diminished gains for rare disease QA. Empirical analysis shows that the improvement upper bound from previous RL post-training procedures on rare diseases is below +3%, with high compute and token costs due to long trace generation.
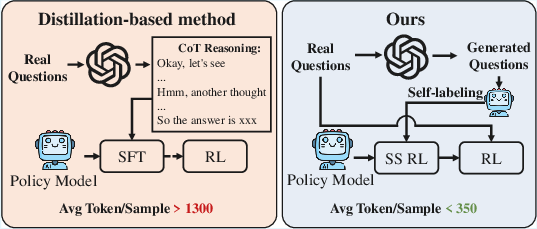
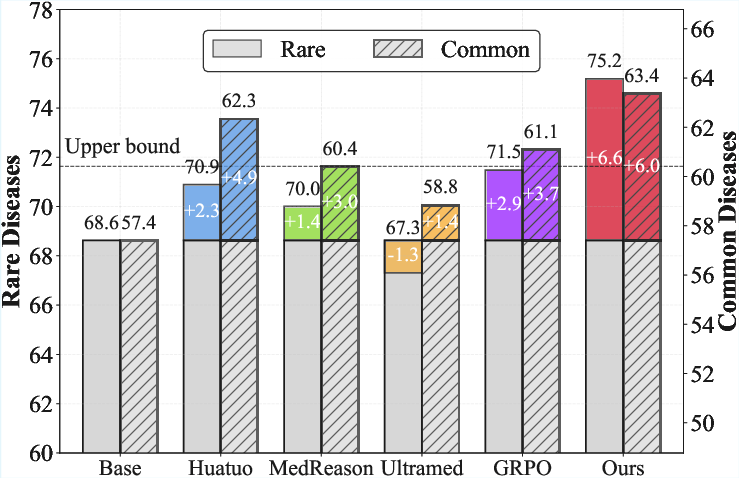
Figure 2: MedSSR achieves rare disease improvement well beyond prior upper-bounds; left subfigure quantifies compute cost of previous methods.
The MedSSR Framework
MedSSR (Medical Knowledge-enhanced Data Synthesis and Semi-Supervised Reinforcement learning) fundamentally rethinks post-training for medical reasoning LLMs by decoupling knowledge-intensive question generation from trace distillation and applying scalable semi-supervised RL on a hybrid of synthetic and real data. The workflow consists of two main components:
- Knowledge-enhanced, distribution-controllable question synthesis: The pipeline generates synthetic, reasoning-oriented medical questions with explicit control over the inclusion of rare disease entities, using seed questions, a structured external medical knowledge corpus, and a proprietary LLM for generation.
- Semi-supervised RL training: The policy model self-generates high-quality pseudo-labels for synthetic data via offline majority voting, supporting a two-phase strategy—first, self-supervised RL on synthetic data, then fully-supervised RL on human-annotated real data. This intrinsic-to-extrinsic curriculum avoids reward hacking and aligns learning with the model’s evolving capabilities.
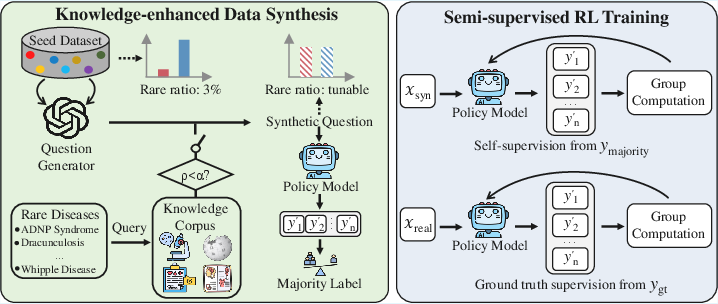
Figure 3: MedSSR pipeline: synthetic question generation (with rare disease knowledge injection when ρ<α), followed by semi-supervised RL.
Distribution Control and Rare Disease Knowledge Injection
MedSSR enables explicit tuning of rare disease content in the synthetic data through a parameter α. When ρ<α, a rare disease entity is sampled, and disease-specific context from the curated medical knowledge corpus is injected into the LLM prompt. Retrieved passages are encoded via a specialized medical retriever. This mechanism allows precise trade-off between rare disease specialization and generalization to other medical tasks.
Systematic ablation indicates that overall model performance can be optimized at an intermediate rare disease ratio (25%), with higher ratios resulting in loss of general domain performance, while substantial rare disease gains are realized absent tradeoff up to that point.
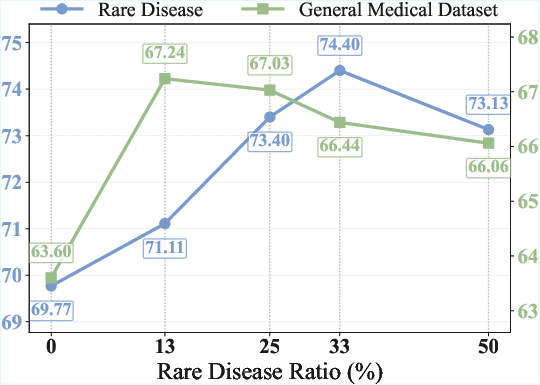
Figure 4: Increasing rare disease ratio yields monotonically increasing rare disease performance, but general performance peaks at moderate ratio.
Direct comparison across rare disease categories further demonstrates that knowledge injection yields robust improvements across symptom, cause, diagnosis, and affect-focused QA, confirming that the benefit is not limited to a narrow subset of rare disease tasks.
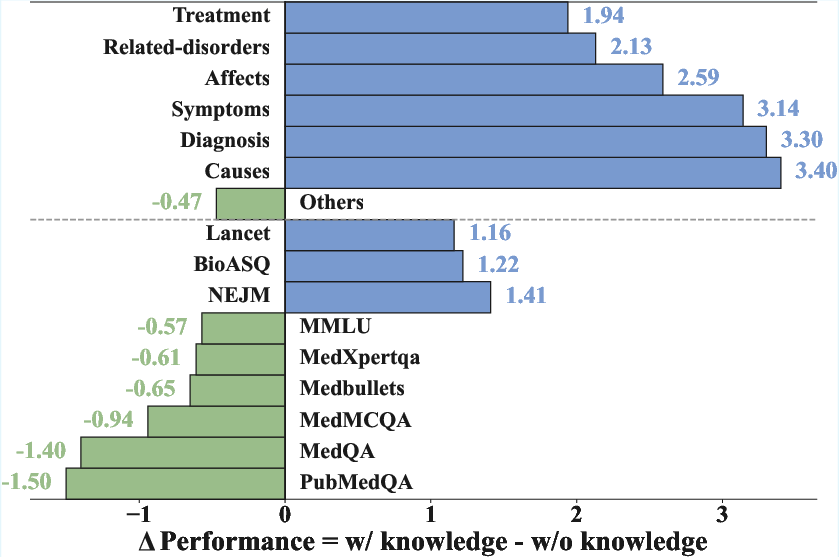
Figure 5: Knowledge injection confers substantial gains for all rare disease categories with minimal impact on general tasks.
Semi-Supervised RL and Self-Labeling Pipeline
Given the high cost and low coverage of manual annotation, MedSSR leverages intrinsic labeling by the policy model itself, employing offline majority voting across multiple rollouts to generate pseudo-labels for synthetic questions. The two-stage RL curriculum is key: self-supervised RL uncovers the model’s intrinsic reasoning capacity, while subsequent supervised RL (using real labels) further extends capability boundaries.
The design strictly separates synthetic and real data phases. Ablation studies reveal that interleaving (single-stage training) or using a reversed order is suboptimal; only the proposed intrinsic-to-extrinsic curriculum maximizes gains and stability.
Offline labeling (as opposed to online, in-loop labeling) is critical. Online majority voting leads rapidly to reward hacking, with decoupling of training reward from genuine performance and dangerous mode collapse; offline voting does not exhibit this pathology and supports thousand-step stable RL.
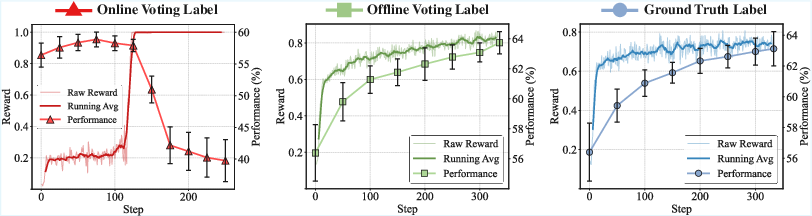
Figure 6: Offline voting tracks reliable reward curves and continuously increases performance, unlike online strategies that collapse due to reward hacking.
Empirical Results and Analysis
MedSSR was evaluated across two major open-source LLM backbones (Qwen3-8B and Llama-3.1-8B) and a comprehensive suite of ten medical benchmarks. The method consistently and robustly surpasses all baselines (including RLHF, SFT, and process reward models), with rare disease improvements up to +5.93% and clear, statistically stable gains even in the general domain (+3.91%).
Importantly, MedSSR shatters prior upper-bounds for rare disease tasks, which prior art could not breach (+3%) due to supervision scarcity and data generation bottlenecks. Across all scales, MedSSR confers large, consistent relative improvements, and physician review of synthetic data confirms high factual accuracy (incorrect/harmful rate <1%) and high clinical plausibility (4.8/5).
Direct comparison of question-only synthesis versus full chain-of-thought synthesis shows that question-only approaches dominate both in performance and compute cost.
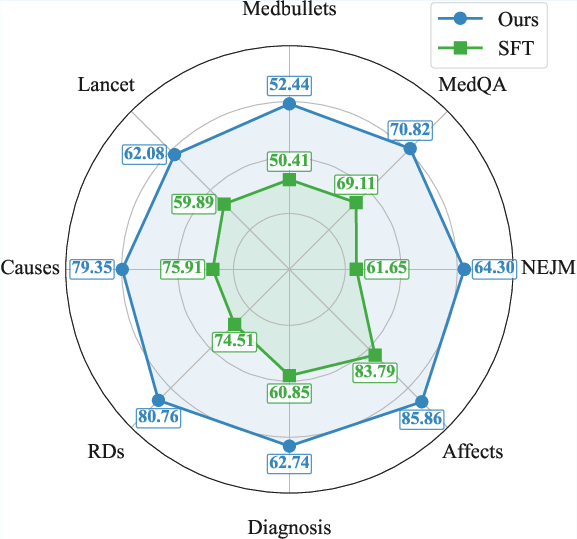
Figure 7: Question-only synthesis outperforms long reasoning chain SFT across all tasks.
Extension analyses demonstrate that MedSSR is robust to model scale-up (with tested models up to 14B), is not brittle across dataset shifts, and produces explicit, interpretable reasoning outputs critical for clinical acceptance.
Practical and Theoretical Implications
MedSSR addresses a major bottleneck in the development of clinical LLMs: scarcity of complex, high-quality supervised data for out-of-distribution, safety-critical subdomains such as rare disease. By decoupling question generation from long-trace distillation, leveraging structured medical knowledge, and using scalable semi-supervised reinforcement learning, MedSSR provides a template for efficient, cost-effective escalation of medical reasoning competence with minimal human labor.
The framework’s explicit distribution control enables robust navigation of the specialization-generalization tradeoff—a key requirement for future medical AI deployment. The approach is model-agnostic and expected to yield greater incremental returns with further LLM scaling, given more extensive latent medical knowledge.
On a broader theoretical level, MedSSR exemplifies how structured, controllable synthetic data generation and well-calibrated auto-labeling can unlock performance improvements in domains with entrenched supervision bottlenecks. The reward hacking analysis provides further confirmation that self-supervised RL in large models is only viable with careful reward design, such as offline voting.
Conclusion
MedSSR presents a fully-internal, knowledge-enhanced paradigm for post-training medical LLMs. It demonstrates that offline pseudo-labeling, robust synthetic data generation with knowledge injection, and a two-stage intrinsic-to-extrinsic RL curriculum can yield strong, stable, and controllable improvement—particularly for rare disease reasoning tasks previously resistant to LLM post-training interventions. The methodology is immediately extensible to larger model scales and other specialized data-scarce scientific domains.
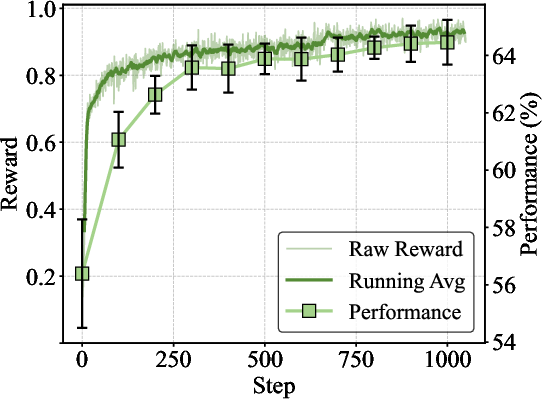
Figure 8: Extended training curve: MedSSR's offline labeling consistently increases test performance across over 1K steps, confirming long-term stability.
Reference: "Eliciting Medical Reasoning with Knowledge-enhanced Data Synthesis: A Semi-Supervised Reinforcement Learning Approach" (2604.11547)