- The paper establishes an empirical framework to characterize both steady and bursty congestion in diverse HPC interconnects.
- It employs controlled experiments using AlltoAll and Incast collectives across small testbeds and large production systems to isolate network effects.
- Results reveal significant performance disparities among Fat-tree, Dragonfly+, and Slingshot fabrics, underscoring the need for integrated congestion control.
Characterizing Congestion Effects in Modern HPC Interconnects
Introduction and Motivation
Modern high-performance computing (HPC) facilities serve a multi-tenant, heterogeneous mix of AI and simulation workloads, all imposing significant burdens on the shared network infrastructure. The evolution of network topologies towards higher scales and the adoption of advanced proprietary (InfiniBand, Slingshot) and Ethernet-based fabrics (Ultra Ethernet, RoCE with NSLB) create new complexities for congestion management, especially given the diversity of collective communication patterns typical in distributed workloads.
This work establishes a comprehensive, empirical analysis of congestion manifestation across leading interconnect technologies, focusing on both steady and bursty congestion profiles, realistic workload scales, and critical collective primitives. Particular emphasis is placed on the system-scale behavior, topology effects, and the efficacy of recent congestion control and load-balancing solutions deployed at the hardware and protocol levels.
Methodology
A custom experimental framework generates controlled congestion via aggressive traffic injection, interleaving aggressor and victim roles across the allocated nodes to maximize fabric stress. Both steady (persistent) and bursty (periodic) congestion scenarios are considered, using AlltoAll and Incast collectives to exercise both intermediate- and edge-link congestion domains. Measurements use bespoke implementations of communication-only collectives (ring AllGather, linear AlltoAll) to isolate network-level effects, removing confounding computation and memory handling latencies.
All experiments are validated on both small research testbeds (HAICGU, Nanjing) and large production supercomputers (Leonardo, CRESCO8, LUMI), spanning the latest EDR/HDR/NDR InfiniBand, Cray Slingshot, and RoCE Ethernet fabrics with and without advanced load balancing.
Small-Scale Congestion Behavior
Early analysis on small-scale testbeds exposes key fabric- and device-specific effects. For example, CE8850-based RoCE deployments on HAICGU suffer throughput instability even in the absence of explicit congestion, with large collectives exhibiting a sawtooth pattern—indicative of unstable CC response to high-rate traffic. This is resolved in newer CE9855 switches (Nanjing), where, with Network Scale Load Balancing (NSLB) enabled, the fabric sustains peak bandwidth even under adversarial AlltoAll congestion; disabling NSLB causes a significant 33% throughput reduction under identical conditions.
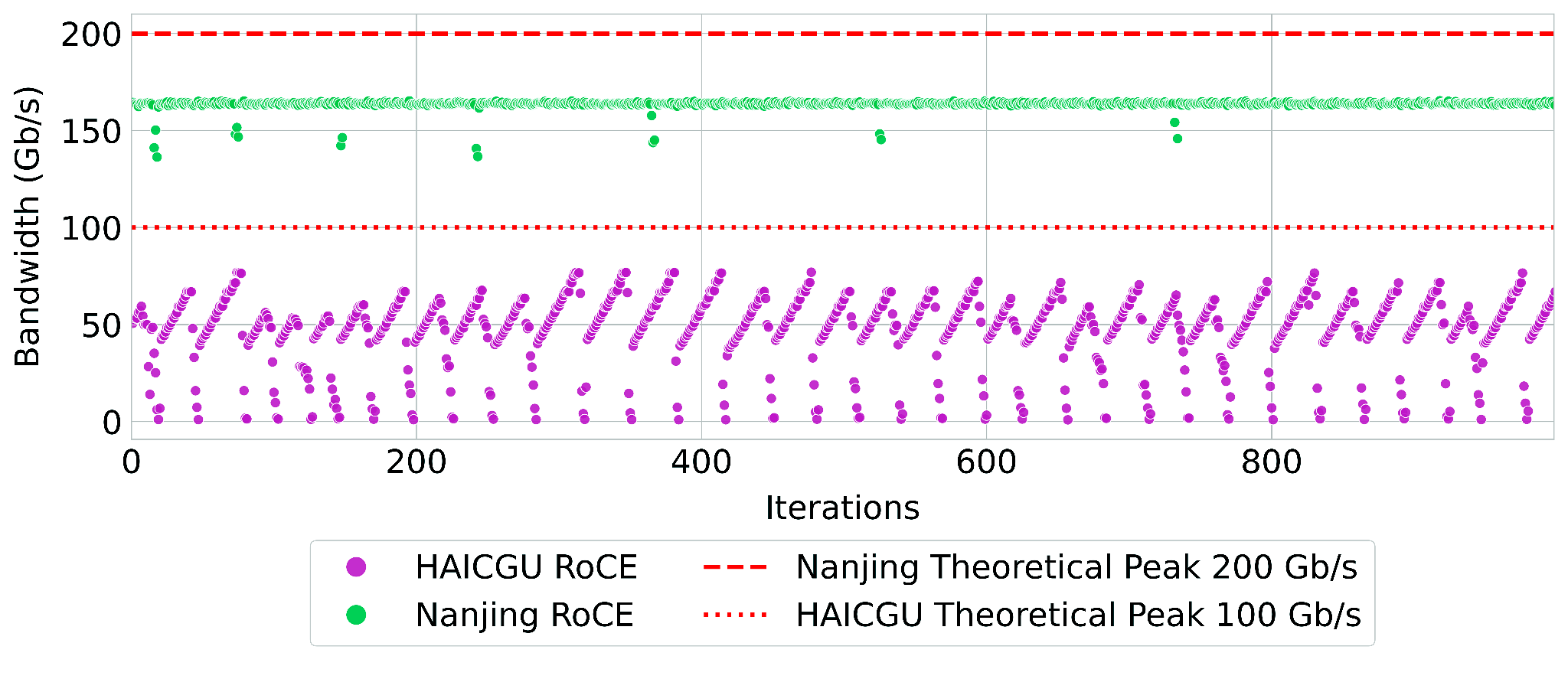
Figure 1: 4-node HAICGU sawtooth behavior for 128 MiB AllGather demonstrates instability on older CE8850, corrected in CE9855/Nanjing.
Leonardo, CRESCO8, and LUMI maintain near-baseline communication performance at small allocations, leveraging topology-provided path diversity and load balancing mechanisms to mask most steady congestion effects.
Large-Scale Congestion: Topology and Fabric Specifics
Scaling to 256 nodes clearly differentiates the robustness of the analyzed network fabrics under persistent congestion.
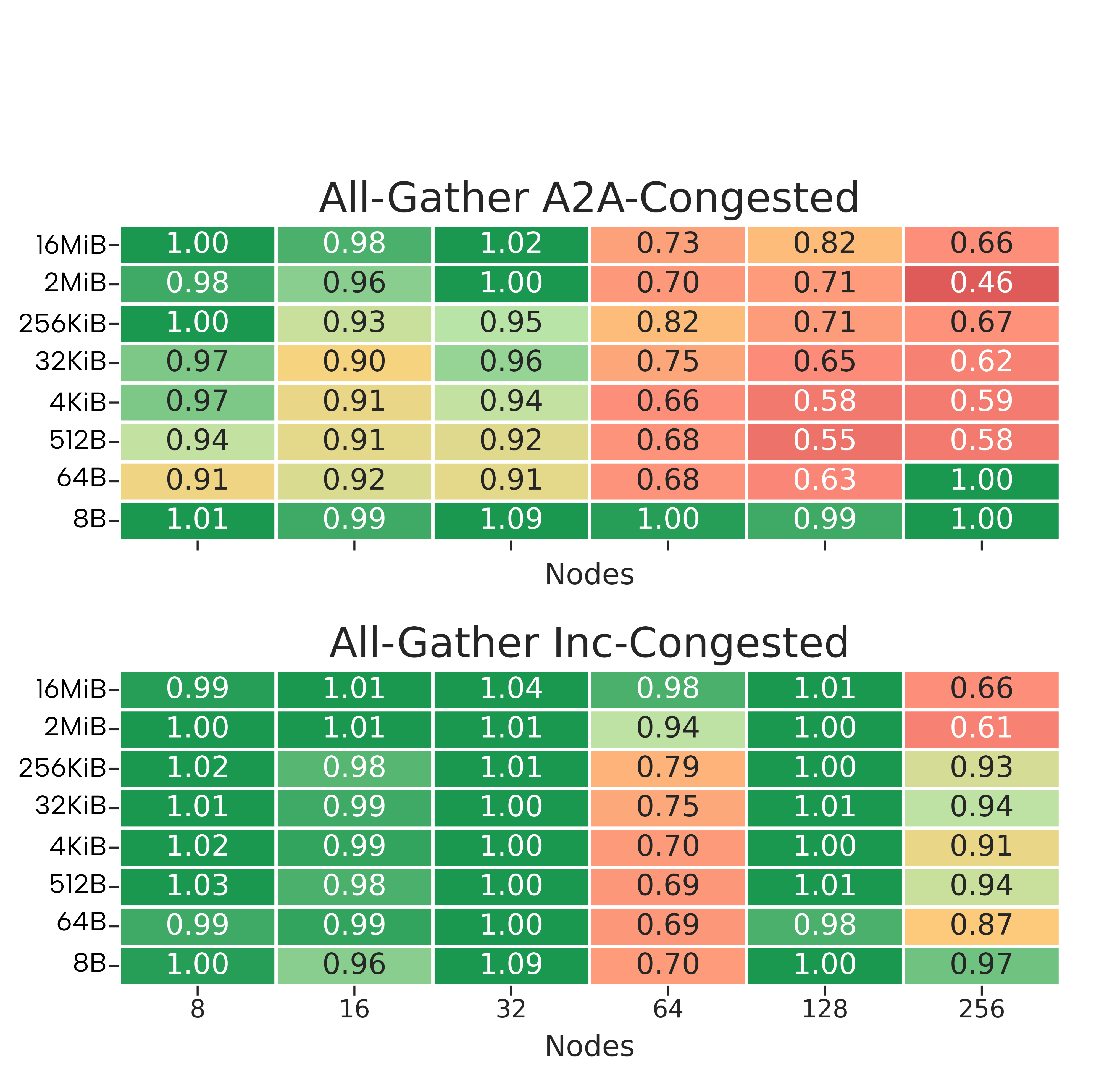
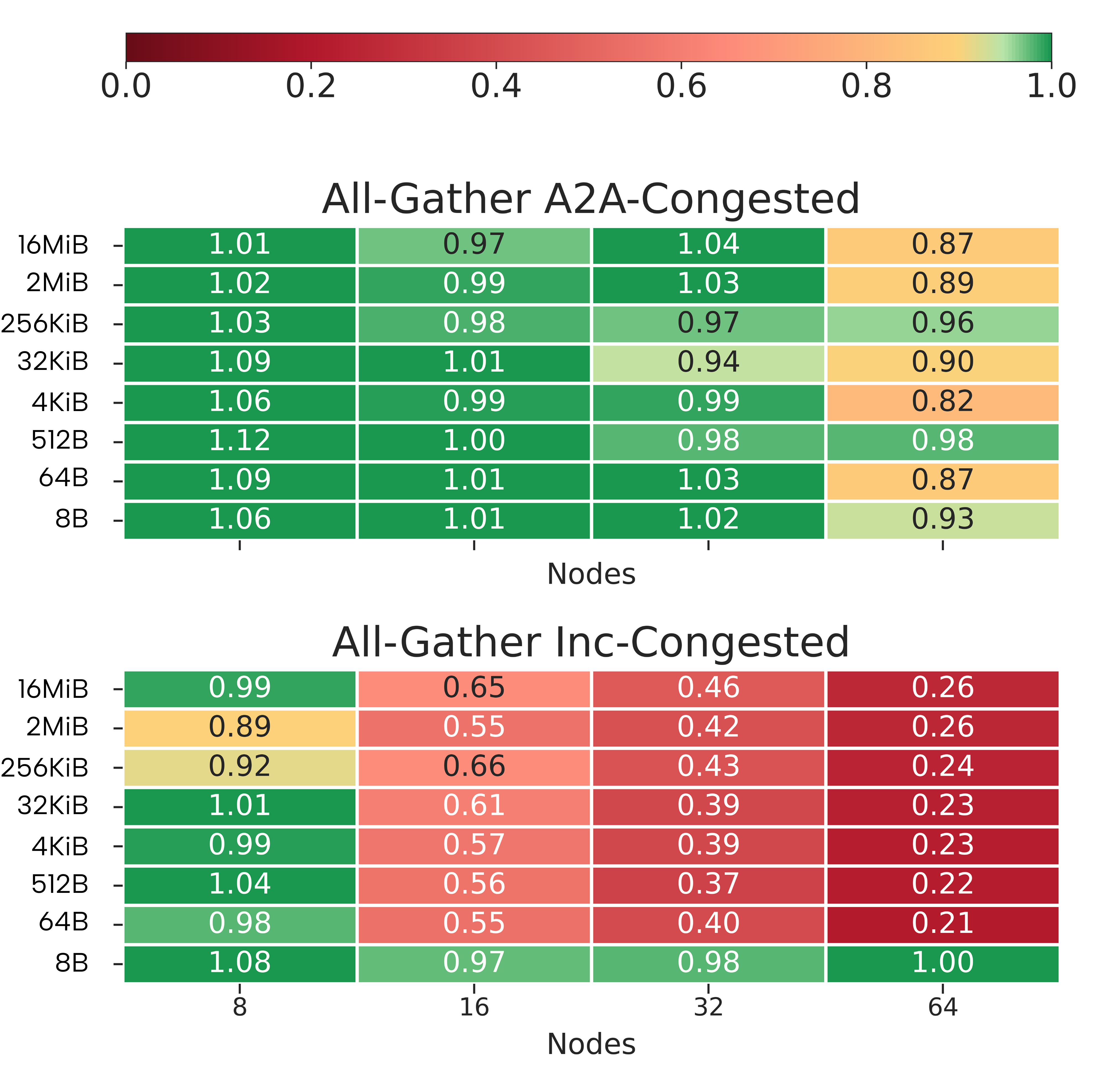
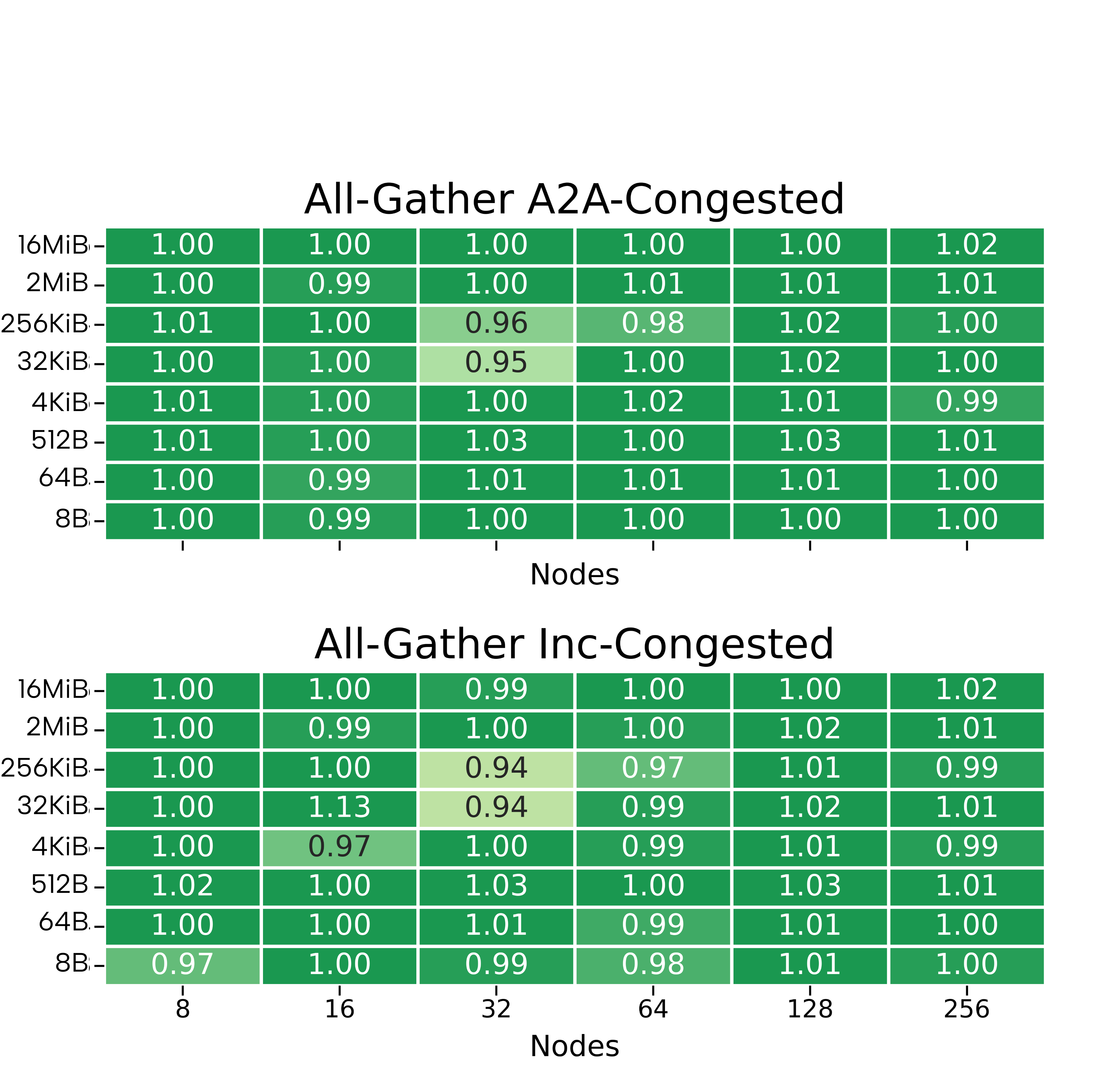
Figure 2: Ratio between uncongested and congested runtimes in CRESCO8, Leonardo, and LUMI, as a function of node count and collective size.
- Fat-tree (CRESCO8/NDR): Handles steady congestion up to 32 nodes well, but exhibits strong throughput collapse (ratios ≤0.45) beyond this scale, particularly for AlltoAll-induced intermediate congestion. For Incast-induced edge congestion, performance degrades further (slowdowns up to 25× for some collectives).
- Dragonfly+ (Leonardo/HDR): Exhibits resilience to AlltoAll stress due to abundant path diversity, with uncongested/congested ratios typically ≈0.95–1.05. However, Incast contention induces severe slowdowns (>5×) even at moderate scales (32–64 nodes), corroborating that endpoint-focused congestion is not fully mitigated by available path diversity or adaptive routing.
- Slingshot (LUMI): Demonstrates optimal isolation from both intermediate- and edge-induced congestion across the evaluated parameter space, with less than 5% degradation from the uncongested baseline, irrespective of vector size or aggressor pattern.
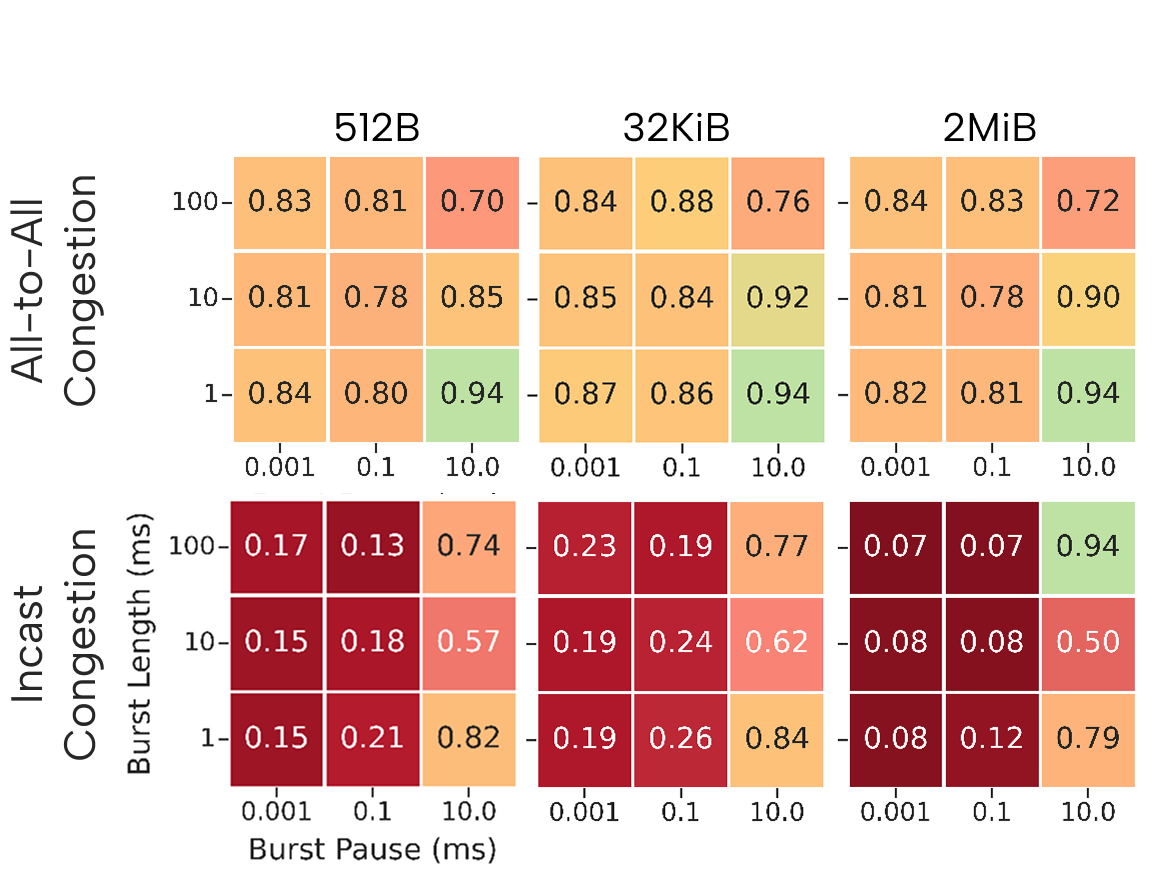
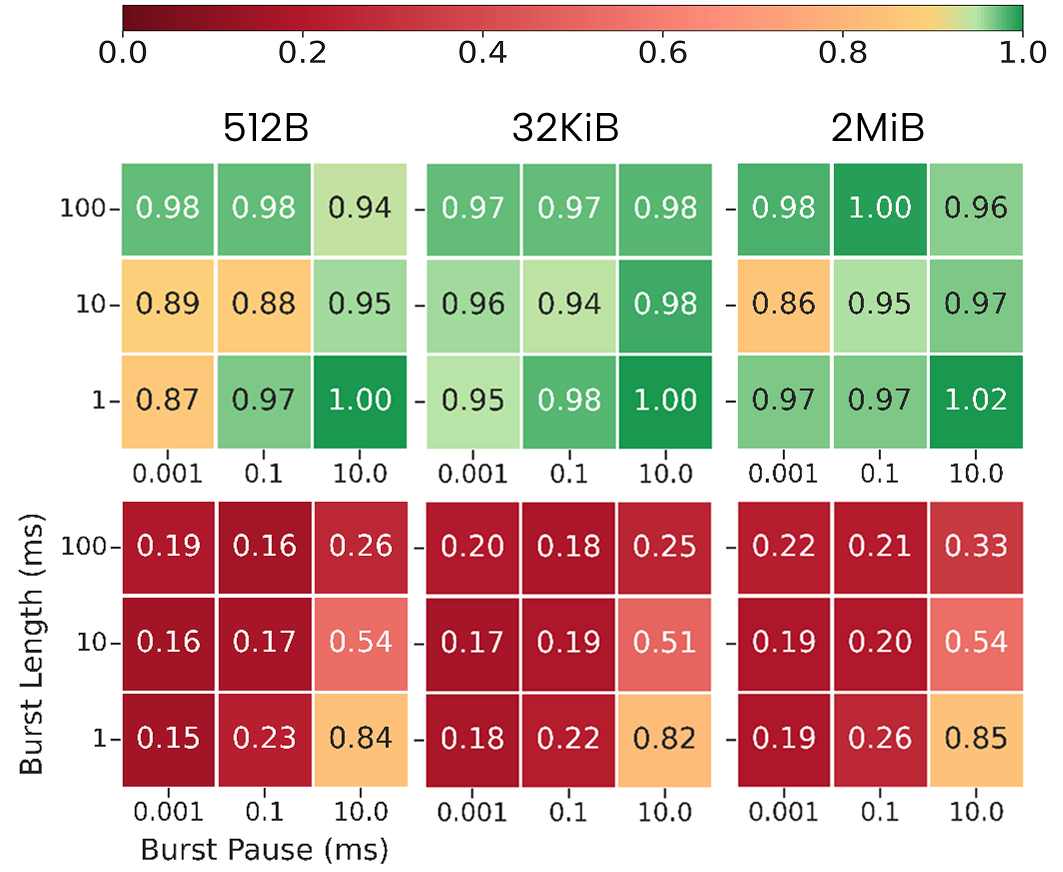
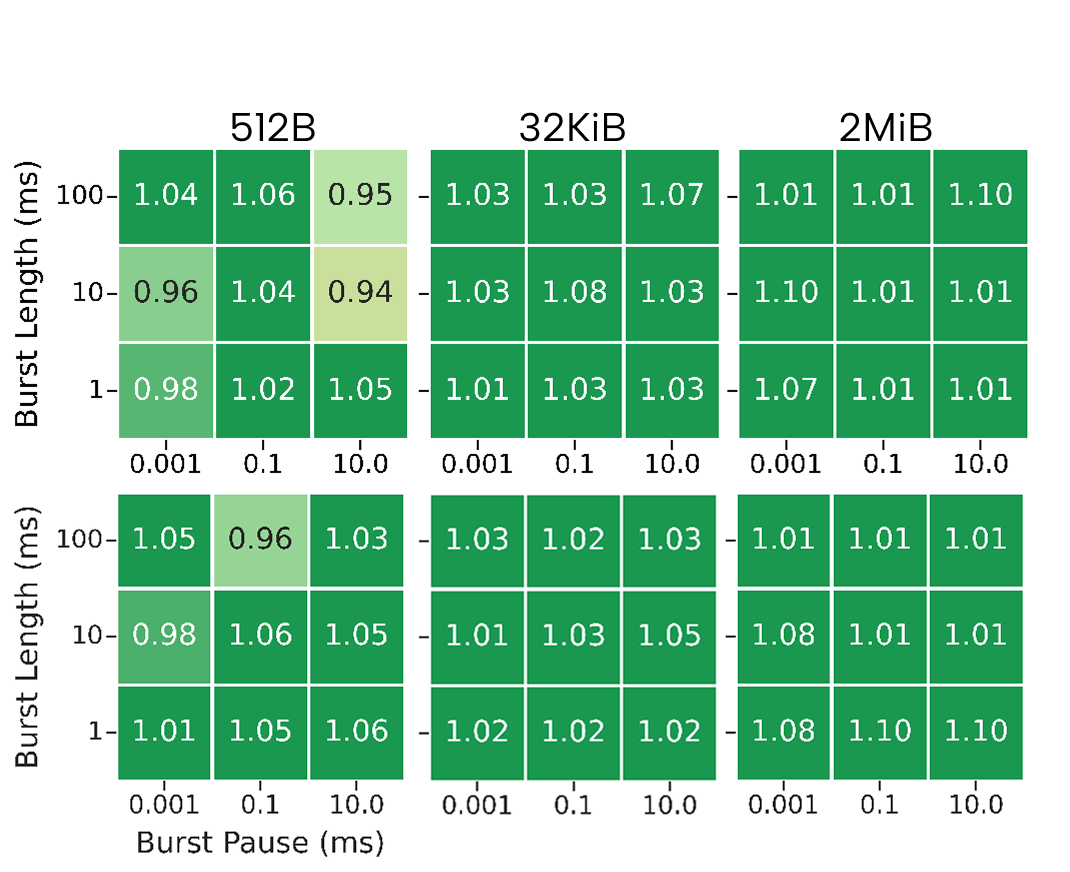
Figure 3: Breakdown of congested/uncongested runtime ratios for select message sizes and 64 nodes—LUMI remains robust while Fat-tree and Dragonfly+ exhibit congestion sensitivity depending on pattern.
Bursty Congestion Dynamics
Unlike steady congestion, bursty traffic patterns (configurable burst length and inter-burst idle time) test the reaction speed and stability of in-network and endpoint congestion control. These patterns closely approximate real AI/ML workloads, where communication alternates with computation, creating high-rate contention spikes.
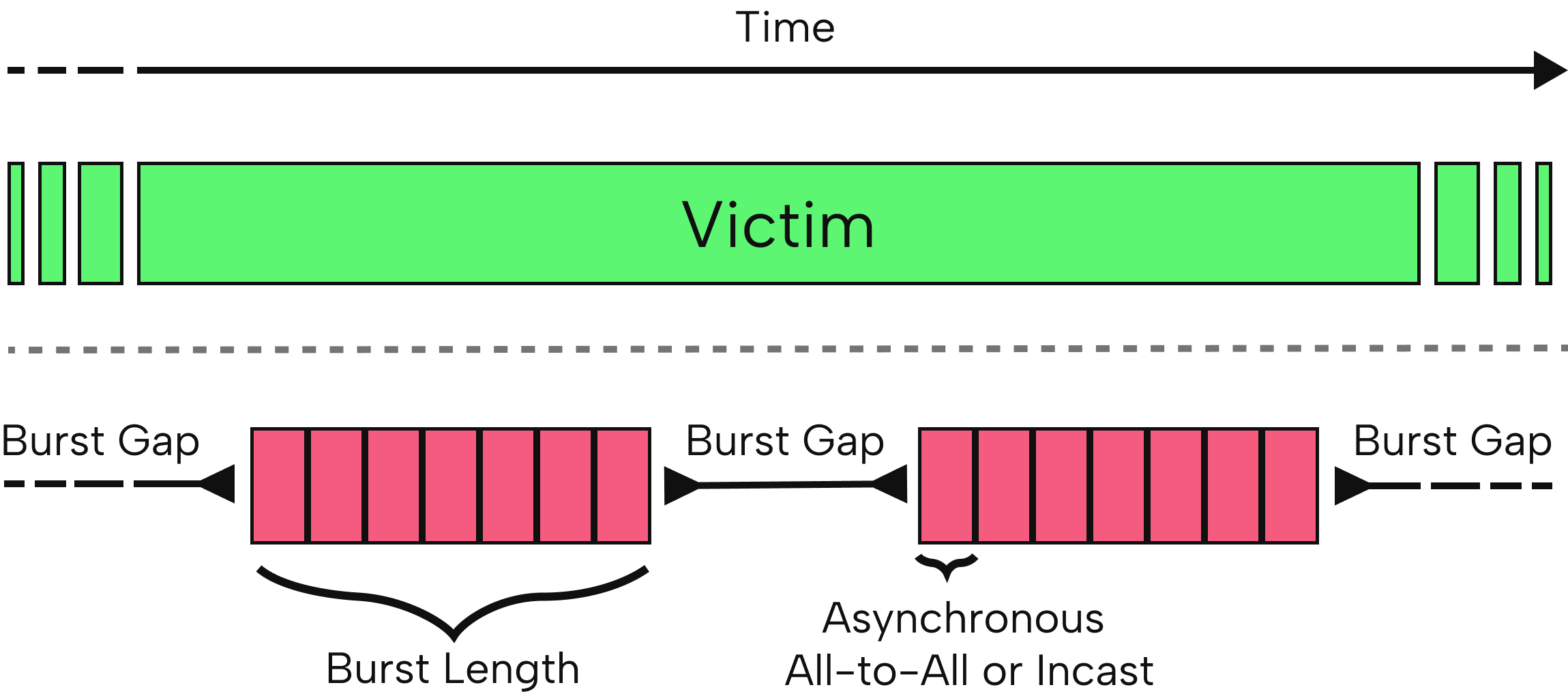
Figure 4: Bursty congestion injection: aggressor bursts (bottom) and victims (top), visualizing temporal traffic patterns typical of distributed training jobs.
For CRESCO8, adaptation to bursty AlltoAll congestion mimics steady-state degradation, but Incast bursts can induce performance reductions to ~8% of the uncongested baseline under aggressive burst regimes. At higher node counts, this effect is slightly ameliorated by the increased capacity to spatially spread the congestion but never fully mitigated.
Leonardo remains relatively robust against bursty AlltoAll, except in the most aggressive (minimal pause) scenarios, but is strongly susceptible to even moderate Incast bursts. LUMI maintains near-baseline performance in all burst configurations, highlighting the intrinsic stability of Slingshot’s congestion isolation mechanisms.
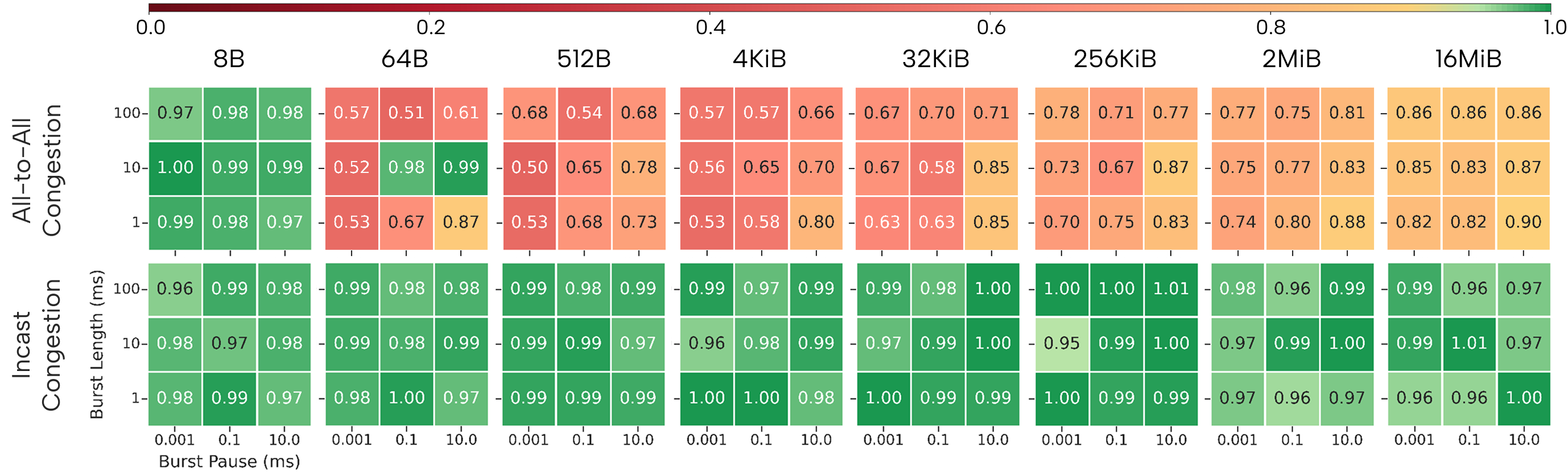
Figure 5: CRESCO8, 128 nodes AllGather: dramatic slowdowns under Incast bursts (ratios <<1), milder under AlltoAll.
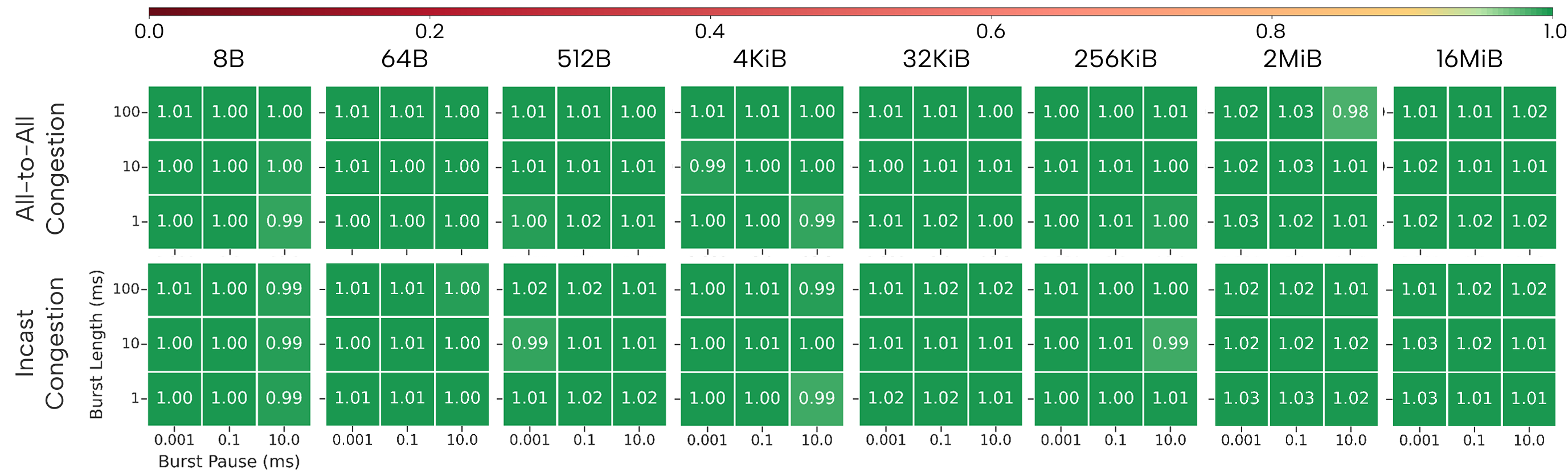
Figure 6: LUMI, 256 nodes: sustained near-baseline ratios under all burst patterns, for both AlltoAll and Incast.
Implications and Forward-Looking Perspective
The findings demonstrate no straightforward correlation between fabric physical topology and congestion resilience. Instead, resilience emerges from the synergy of topology, network generation, switch and NIC congestion control implementation, and protocol-stack tuning. Key theoretical implications include:
- Path diversity (Dragonfly, Fat-tree) is necessary but not sufficient: It is effective for intermediate-link contention but does not address endpoint (edge) congestion—unavoidable in Incast or closely-aligned collective phases.
- Load balancing algorithms (e.g., NSLB, adaptive routing, flowlet/flowcell/OPS/Flowcut switching) must be tightly integrated with low-latency, precise congestion control (ECN/AI ECN/telemetry-driven protocols) to prevent queue buildup and distributed backpressure.
- Burst-handling latency remains a limiting factor: If control loops adapt more slowly than burst duration, backpressure and performance-limiting queueing effects propagate uncontrollably, especially in multi-tenant contexts where background load is stochastic.
Practical implications include the necessity to move beyond static provisioning and peak bandwidth as procurement metrics. Future fabrics (Ultra Ethernet, advanced RoCE, Slingshot) must prioritize fast, robust edge- and endpoint-level congestion mitigation, especially as collective communication patterns in AI/ML training further stress the network at scales unattainable by traditional simulation workloads.
With the push for larger LLM/AI training clusters and exascale design, the results motivate further research into:
- Explicit hardware support for ultra-fine-grained congestion signaling and feedback.
- Protocols leveraging in-band telemetry for real-time adaptive throttling.
- Out-of-order delivery/packet reordering solutions (e.g., Flowcut, ConWeave) that enable more aggressive path utilization without sacrificing RDMA or collective performance semantics.
- Cross-layer co-design between collective libraries and network stacks that can exploit workload phase compatibility [(2604.11432), 10.1145/3563766.3564115].
Conclusion
This work provides a definitive, comparative, empirical framework for dissecting congestion effects in state-of-the-art HPC fabrics. The analysis reveals the persistence of edge congestion as a bottleneck, the criticality of end-to-end congestion response latency, and makes clear that adaptive, workload-aware, and burst-resilient congestion management is essential for future scaling. No single-topology or fabric solution can guarantee congestion freedom; only the co-design of topology, in-network hardware, endpoint algorithms, and collective libraries will enable sustained communication and compute scalability (2604.11432).