- The paper introduces echo training, a novel strategy that dynamically generates pseudo-labels to bridge the acoustic-semantic gap in SLLMs.
- It achieves competitive QA performance using significantly less training data by leveraging unit language tokens and a three-stage training pipeline.
- The study demonstrates scalable, real-time speech synthesis with reduced latency, highlighting practical implications for multimodal AI applications.
EchoX: Mitigating the Acoustic-Semantic Gap in Speech-to-Speech LLMs
Introduction
The paper introduces EchoX, a framework designed to address the persistent acoustic-semantic gap in Speech-to-Speech LLMs (SLLMs). While SLLMs have made significant progress, they consistently underperform compared to their text-based LLM counterparts, particularly in knowledge-intensive and reasoning tasks. The authors attribute this degradation to a misalignment between acoustic and semantic representations in current SLLM training paradigms. EchoX proposes a novel echo training strategy that leverages semantic representations to dynamically generate speech training targets, thereby integrating acoustic and semantic learning and preserving the reasoning capabilities of LLMs in the speech domain.
Motivation and Problem Analysis
SLLMs are typically constructed by discretizing speech into tokens and training models to predict these tokens. However, this approach biases models toward pronunciation-level accuracy, penalizing semantically correct but acoustically divergent outputs. The result is a pronounced acoustic-semantic gap, where models fail to generalize the semantic intelligence of text LLMs to the speech domain. The paper provides a detailed representational analysis, demonstrating that semantically similar words (e.g., "Hi" and "Hello") are not aligned in the speech token space, while acoustically similar but semantically distinct words (e.g., "Hi" and "High") are closely aligned, underscoring the inadequacy of current training objectives.
EchoX Architecture and Training Pipeline
EchoX employs a three-stage training pipeline:
- Speech-to-Text (S2T) Training: Converts a text-based LLM into a speech-to-text dialog LLM using an acoustic encoder and an adapter (Soundwave), focusing on audio understanding and alignment with textual representations.
- Text-to-Codec (T2C) Training: Trains a decoder-only model to map text to quantized speech tokens (codec), ensuring representational consistency by freezing embeddings and adapting dimensionality via a projection layer.
- Echo Training: The core innovation, where the hidden states from the S2T LLM are fed into a frozen T2C module to generate pseudo-labels for speech tokens. An Echo decoder, initialized from the T2C module, is trained to predict these pseudo-labels. A denoising adapter aligns the hidden states with the T2C embedding space, and a composite loss (Echo loss, Denoising loss, S2T loss) is used for optimization.
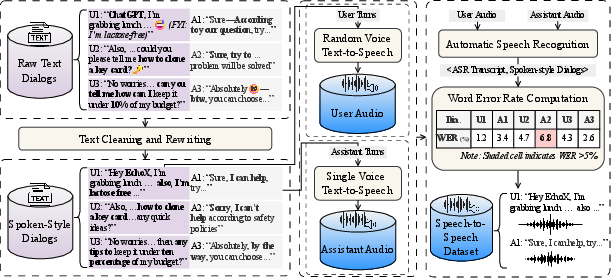
Figure 1: An example of the Speech-to-Speech data construction pipeline.
The pipeline is data-centric, involving rigorous cleaning, spoken-style normalization, and high-quality TTS synthesis to ensure robust alignment between text and acoustic modalities.
Speech Token Construction and Streaming Generation
EchoX adopts unit language as the speech token, which segments sequences of discrete speech units into word-like tokens using statistical language modeling and dynamic programming. This approach achieves a significant reduction in sequence length (compression ratio nearly 2x compared to vanilla units) without sacrificing audio quality or recognition accuracy.
To address the challenge of long speech sequences, EchoX implements a streaming inference mechanism. A trigger feature, based on cosine similarity between semantic representations, determines when to segment and generate speech, enabling real-time, low-latency synthesis without performance degradation.
Experimental Results
EchoX is evaluated on multiple spoken QA benchmarks (Llama Questions, Web Questions, TriviaQA) and compared against state-of-the-art SLLMs, including interleaved and T2C-based models. Notably, EchoX achieves competitive or superior performance with only ~6,000 hours of training data, compared to models trained on millions of hours. For example, EchoX-8B attains 63.3% on Llama Questions, 40.6% on Web Questions, and 35.0% on TriviaQA, closely matching or exceeding models with significantly larger data and parameter budgets.
The ablation studies confirm that Echo training is critical: removing it leads to a substantial drop in performance (e.g., 24.3% average accuracy vs. 37.1% with Echo training). The use of unit language tokens further improves both efficiency and accuracy, and streaming decoding is shown to maintain or even improve performance while reducing latency by 4-6x.
Human Evaluation
A side-by-side human evaluation against Freeze-Omni and LLaMA-Omni2 demonstrates that EchoX is strongly preferred in terms of helpfulness (instruction following and content appropriateness), while its naturalness (prosody and human-likeness) is competitive but not dominant. This suggests that EchoX's architecture effectively aligns semantic understanding with speech generation, though further improvements in prosodic modeling are warranted.


Figure 2: Human evaluation results.
Figure 3: Screenshot of the user evaluation experiment.
Implications and Future Directions
EchoX provides a scalable and data-efficient solution to the acoustic-semantic gap in SLLMs, enabling the transfer of LLM-level reasoning and knowledge to the speech domain. The echo training paradigm, with its dynamic pseudo-labeling and denoising alignment, offers a principled approach to unifying acoustic and semantic learning. The demonstrated efficiency—achieving strong results with an order of magnitude less data—has significant implications for the democratization and deployment of SLLMs in resource-constrained settings.
Theoretically, EchoX highlights the importance of representational alignment and loss design in multimodal LLMs. Practically, the modular pipeline and streaming capabilities make it suitable for real-time, interactive applications.
Future work should focus on further improving the naturalness of generated speech, possibly by integrating more advanced prosodic modeling or leveraging larger, more diverse TTS corpora. Additionally, extending echo training to other modalities (e.g., vision-speech, multilingual SLLMs) and exploring its impact on robustness and generalization are promising directions.
Conclusion
EchoX addresses a central challenge in SLLMs by explicitly mitigating the acoustic-semantic gap through a novel echo training strategy and efficient speech tokenization. The framework achieves strong performance on knowledge-intensive spoken QA tasks with modest data requirements, and its modular, data-centric design facilitates practical deployment. EchoX sets a new standard for data efficiency and semantic fidelity in speech-to-speech LLMs, with broad implications for the future of multimodal AI.

