- The paper demonstrates that power capping modulates SM frequency and throughput, with H100 maintaining an edge in compute-bound DGEMM benchmarks under moderate power limits.
- The study applies regression analysis on DGEMM and Schönauer Triad kernels to isolate memory subsystem effects and quantify differences in effective bandwidth and power distribution.
- The research highlights that memory-bound workloads gain efficiency from H200’s advanced HBM3e, achieving higher throughput at elevated power caps despite increased memory power draw.
Architectural and Power-Capping Trade-offs in NVIDIA H100 and H200 GPUs
Introduction
This study systematically examines the energy efficiency and performance trade-offs between the NVIDIA H100 (HBM2e) and H200 (HBM3e) GPUs under hardware-enforced power-capping. Both platforms are Hopper-architecture devices with identical compute capabilities but distinct memory bandwidth characteristics. By isolating memory subsystem differences while controlling for other variables, the analysis reveals how power caps modulate GPU subsystem power distribution, frequency scaling, and overall performance. Methodologically rigorous, the study leverages regression analysis across extensive benchmarking data with compute-bound (DGEMM) and memory-bound (Schönauer Triad) kernels, extracting hardware-level behaviors relevant for high-performance and power-constrained AI/ML and HPC scenarios.
Experimental Setup and Methodology
The evaluation utilizes a controlled testbed of Helma cluster nodes, each hosting four H100 or H200 GPUs. The primary architectural difference is in memory technology and capacity (H100: HBM2e, 94 GiB, 2.41 TB/s bandwidth; H200: HBM3e, 144 GiB, 4.89 TB/s bandwidth), while core compute specifications remain constant. Power-cap enforcement is incremented from 200 W to 700 W, capturing throughput, SM frequency, memory frequency, and fine-grained power draw metrics (total, SM, memory) via the NVIDIA management toolkit and custom monitoring scripts. The compute- and memory-bound axes of the Roofline model are probed using large DGEMM and Schönauer Triad benchmarks, executed 50 times per power setting to provide robust statistical characterization.
Impact of Architectural Differences on Effective Bandwidth
To quantify the raw advantage of HBM3e over HBM2e, effective bandwidth for multiple access kernels was profiled. The H200 demonstrates a twofold increase in sustainable bandwidth compared to the H100 across diverse access patterns, underlining the impact of memory subsystem enhancements.
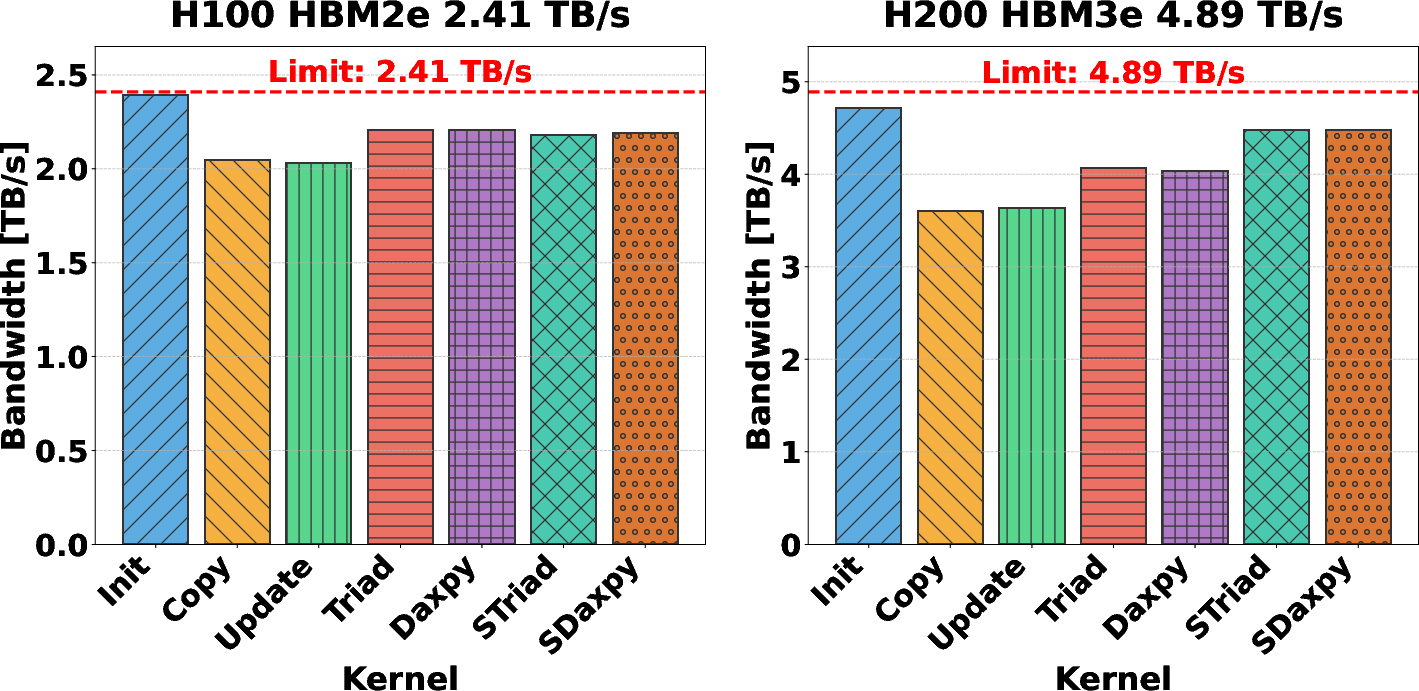
Figure 1: Effective bandwidth for various kernels on NVIDIA H100 (HBM2e) and H200 (HBM3e) demonstrates clear H200 superiority for bandwidth-intensive operations.
Power-Capping Behavior: Compute-Bound versus Memory-Bound Regimes
DGEMM (Compute-Bound)
Power versus performance analysis underlines that both H100 and H200 saturate their power allocations during DGEMM, with the H100 maintaining a slight throughput and efficiency advantage at fixed power caps. This is a consequence of disproportional memory power draw on the H200, which, at equivalent caps, leaves less headroom for the SMs and causes more aggressive frequency throttling. The effect is evident in the direct relationship between SM frequency and DGEMM performance. The efficiency gain curve exhibits diminishing returns past 500 W, with the performance scaling plateauing as additional power allocation yields minimal further increases.
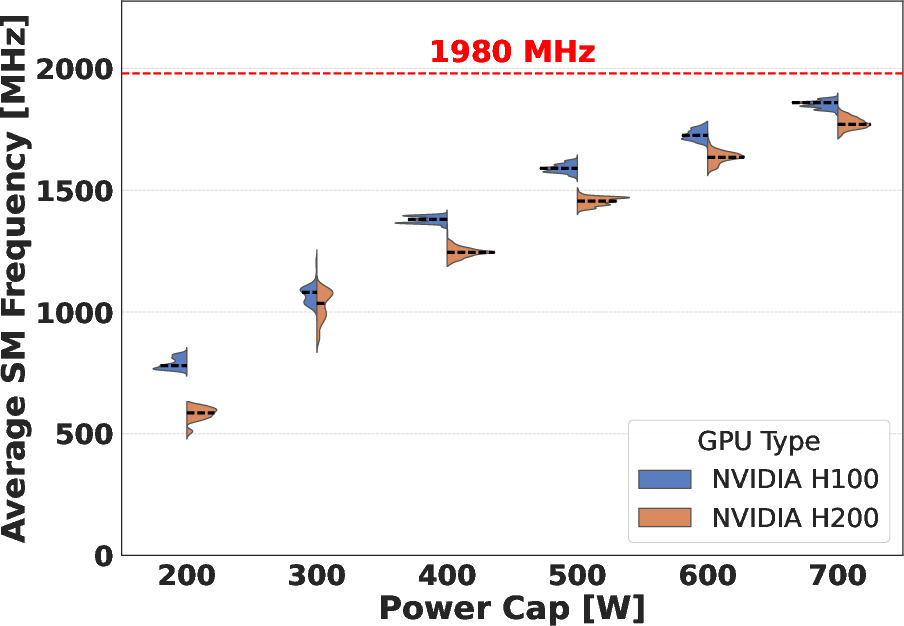
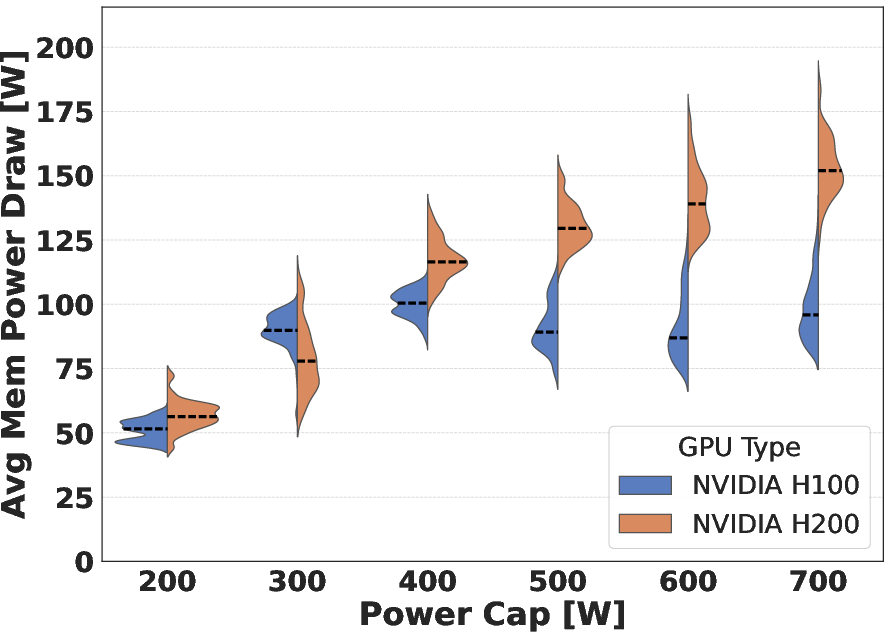
Figure 2: Average SM Frequency for DGEMM across power caps, illustrating increased throttling in H200 due to higher memory power demand.
Schönauer Triad (Memory-Bound)
For memory-bound workloads, the H200's double-bandwidth HBM3e presents a significant advantage, particularly at moderate-to-high power caps. However, achieving maximum bandwidth utilization requires substantially more power on the H200 (~550 W) versus the H100 (~350 W). At the strictest cap (200 W), the H200 cannot maintain memory performance, frequently violating the set cap and exhibiting unstable frequency behavior.
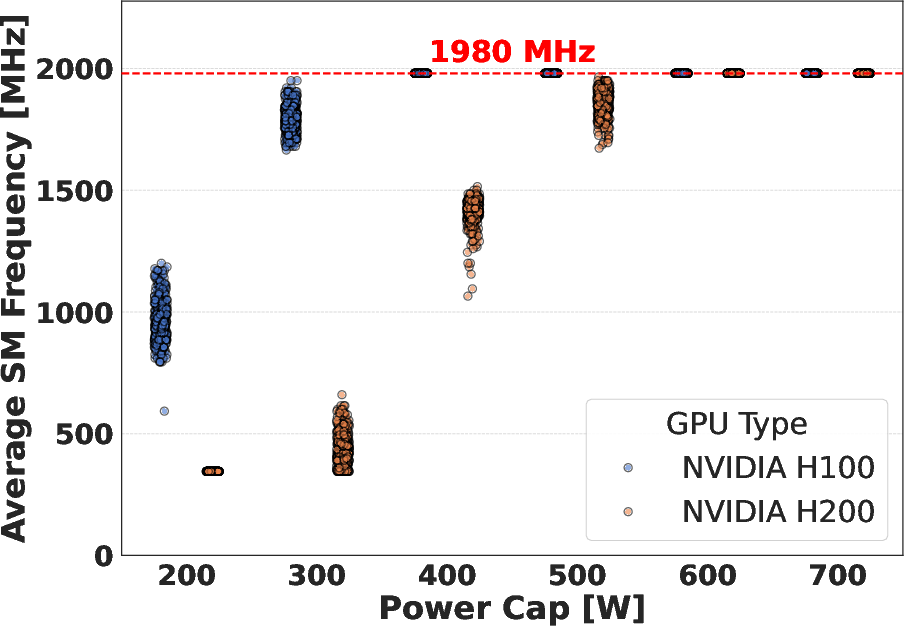
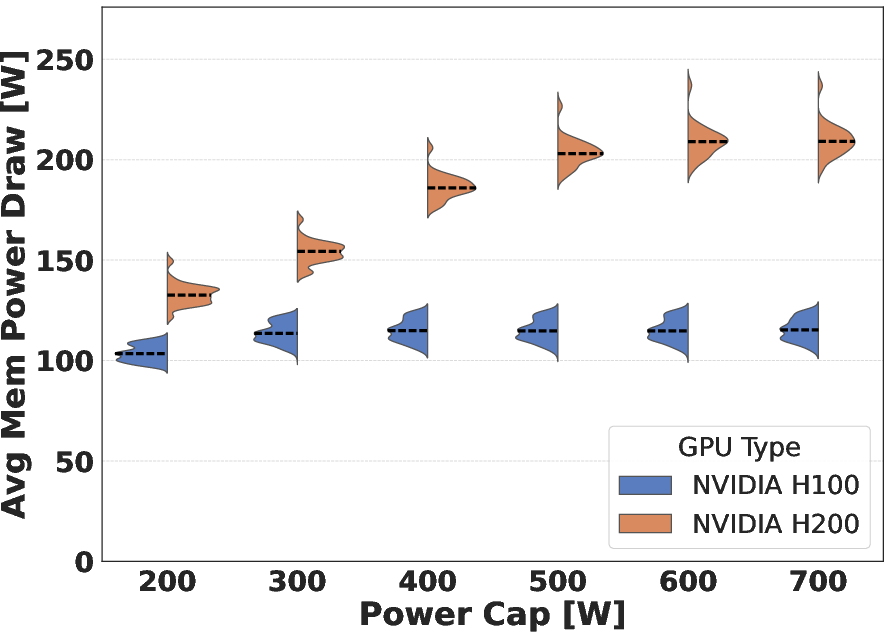
Figure 3: Average SM frequency under the Schönauer Triad benchmark, showing that H200 SMs drop to base frequencies under strict power caps, reflecting higher baseline memory power demand.
Efficiency Analysis and Subsystem Power Breakdown
The efficiency (performance-per-watt) trends diverge notably between compute and memory-intensive scenarios. For compute-bound DGEMM, both devices benefit from moderate power-capping, but H100's lower memory burden allows better SM frequency retention across caps, granting it a marginal efficiency lead. For memory-bound workloads, the H200 achieves substantially higher energy efficiency, even at reduced power limits, thanks to its high-bandwidth memory system—provided sufficient headroom exists for both SM and memory subsystems.
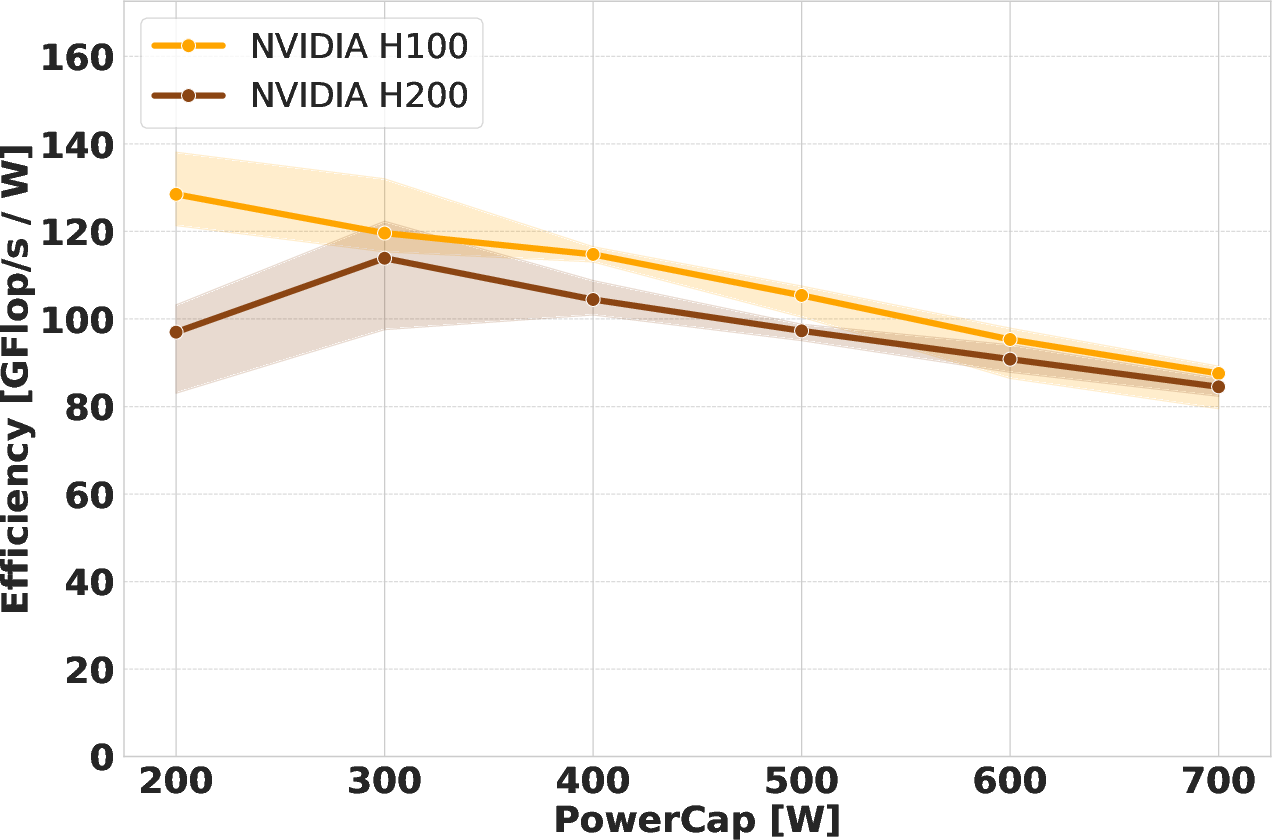
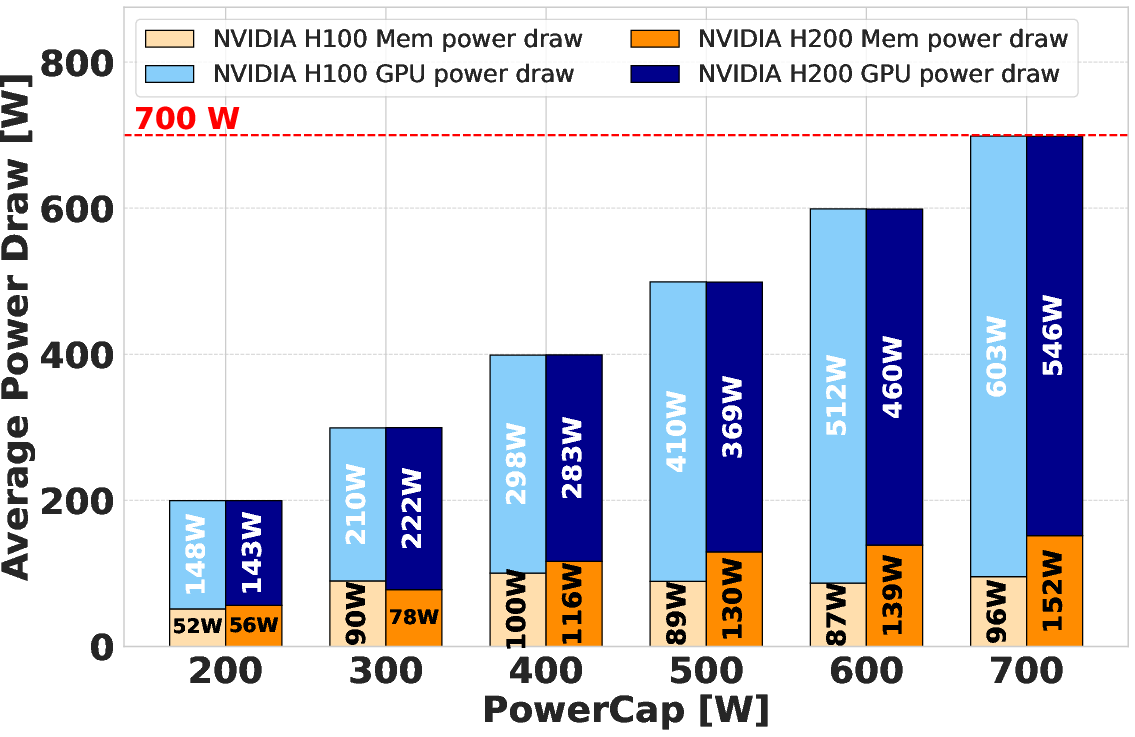
Figure 4: DGEMM efficiency analysis visualizing the marginally superior performance-per-watt of H100, especially at intermediate power caps.
A detailed power breakdown shows memory power draw saturates at higher values on H200 (up to 220 W, with outlier GPUs exceeding this). This increased consumption compresses the available power budget for compute, with prominent effects at low total power budgets. The study also uncovers intra-model variability, with some GPUs acting as outliers in memory power consumption, underlining the necessity for regression approaches in architectural characterization.
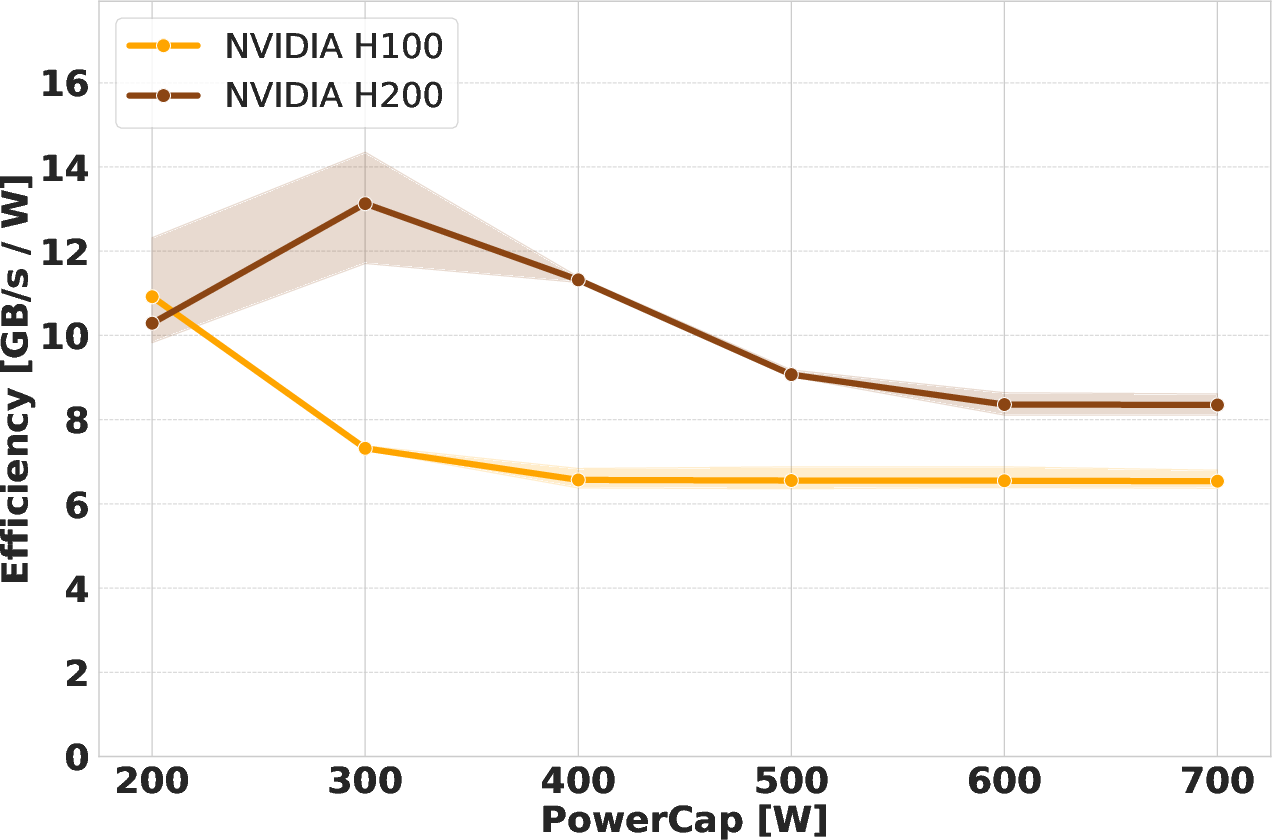
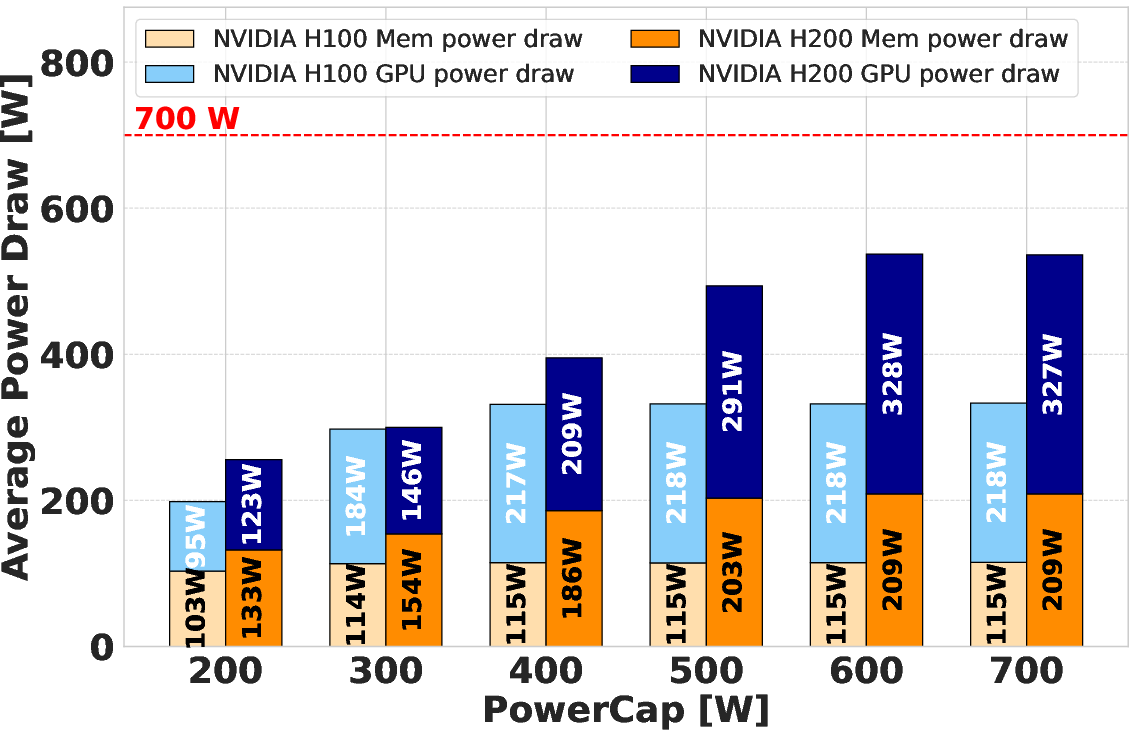
Figure 5: Efficiency analysis for Schönauer Triad highlights H200's superior performance-per-watt at all but the strictest power caps, even surpassing H100 at full TDP when H200 is power-limited to 400 W.
Implications for Energy-Efficient GPU Deployment
These results have immediate implications for power-scaled AI and HPC deployments:
- Compute-Dominated Workloads: H100 is preferable when strictly compute-bound, due to its lower memory subsystem power consumption allowing higher average SM frequencies under capped conditions.
- Memory-Bound Workloads: H200 is significantly more efficient for highly bandwidth-constrained codes, despite its higher absolute and relative memory power consumption, provided cap settings do not induce excessive frequency throttling.
- Operational Margins: Aggressive power caps (≤300 W) introduce instability in both throughput and efficiency, largely due to memory power variability and subsystem throttling behaviors, particularly acute on the H200.
- Architectural Guidance: The distinct power budgets for SMs and memory in HBM3e-era GPUs require fine-grained cap management; application/hardware co-design should explicitly consider the memory-power-to-compute-power ratio for optimal deployment.
- Hardware Variability: Outlier devices with anomalously high memory power draw can distort system-level efficiency predictions, making per-device characterization vital for large-scale GPU procurement and allocation.
Conclusion
Comprehensive regression-based analysis of the NVIDIA H100 and H200 under power caps reveals subtle yet impactful architectural trade-offs in the context of energy efficiency. The H100 maintains a marginal edge for strictly compute-bound applications due to its more efficient SM-to-memory power ratio. Conversely, the H200's significantly enhanced HBM3e subsystem realizes best-in-class efficiency for memory-bound workloads, though at the expense of a higher baseline power draw that can complicate deployment in severely power-constrained environments. The existence of hardware outliers further emphasizes the necessity for device-level efficiency auditing in production clusters. These insights are central for practitioners tasked with balancing power, performance, and operational cost in future exascale and AI data centers.