- The paper introduces BRIDGE, a unified multi-dataset benchmark for IoT intrusion detection under domain shift, revealing generalisation issues in prior methods.
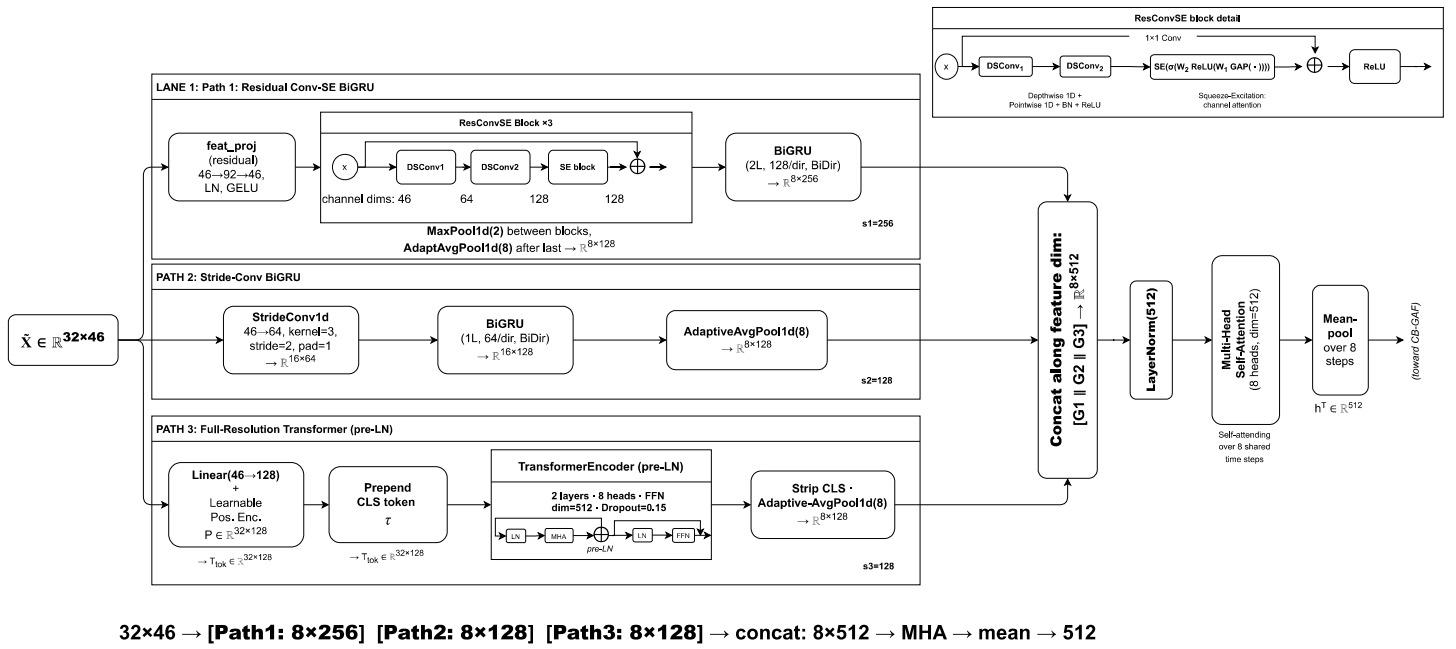
- It presents TCH-Net, a multi-branch architecture integrating temporal, statistical, and contextual modalities via a novel CB-GAF fusion for superior detection performance.
- Performance evaluations show significant F1 and ROC-AUC gains over baselines while exposing persistent cross-domain generalisation gaps to drive future domain-adaptive innovations.
BRIDGE and TCH-Net: Heterogeneous Benchmark and Multi-Branch Baseline for Cross-Domain IoT Botnet Detection
Motivation and Background
A critical and long-standing flaw in the IoT botnet detection literature lies in its exclusive reliance on single-dataset evaluations. This practice systematically overestimates model generalisation to realistic, heterogeneous deployments. Prior approaches are confounded by incompatible feature spaces, capture-tool idiosyncrasies, and a lack of standardized, auditable preprocessing. The absence of a reproducible, principled cross-dataset evaluation regime precludes meaningful advances in domain generalisation and adaptation. The present work addresses both the evaluation protocol gap and the feature heterogeneity problem via two principal contributions: the BRIDGE benchmark and the TCH-Net architecture.
The BRIDGE Benchmark: Canonical Feature Alignment for Cross-Domain Comparison
BRIDGE (Benchmark Reference for IoT Domain Generalisation Evaluation) institutes the first rigorously-specified, multi-dataset evaluation benchmark for IoT intrusion detection under domain shift. Critically, five structurally distinct publicly available datasets (CICIDS-2017, CIC-IoT-2023, Bot-IoT, Edge-IIoTset, and N-BaIoT) are unified through a 46-dimensional canonical feature vocabulary built upon CICFlowMeter nomenclature with strict semantic equivalence constraints.
The mapping employs explicit zero-filling for missing features, ensuring interpretability and integrity auditing; per-dataset coverage varies sharply (15%−93%), reflecting the divergent data-generating regimes and stress-testing model robustness to heterogeneous input representation.
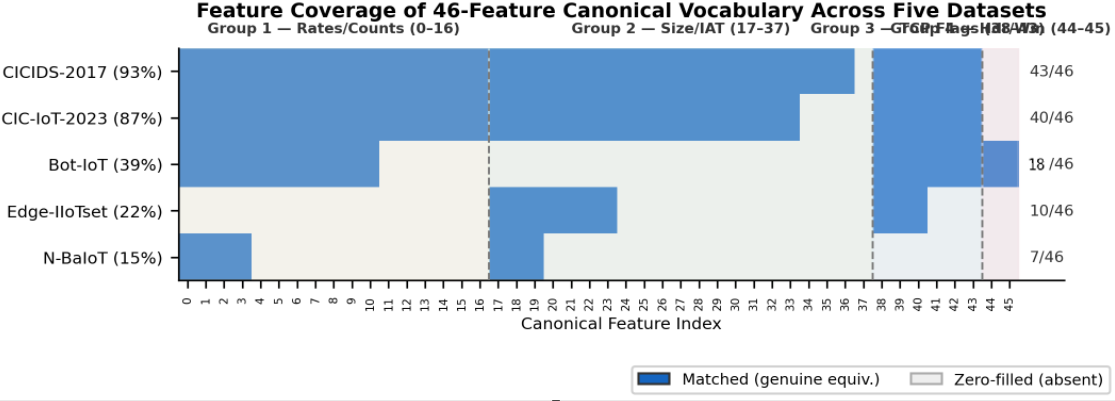
Figure 1: Feature coverage of the 46-feature canonical vocabulary across five BRIDGE datasets. Blue indicates a mapped feature, grey denotes explicit zero-fill.
A reproducible preprocessing pipeline (class balancing, robust scaling, windowed sequence construction, and leakage-free split) underpins BRIDGE, ensuring transparency and consistency. Critically, BRIDGE operationalizes a leave-one-dataset-out (LODO) evaluation protocol, providing, for the first time, formally measured generalisation gaps that expose the limitations of in-distribution overfitting.
TCH-Net: Multi-Branch Neural Baseline for Heterogeneous IoT IDS
TCH-Net is introduced as a strong, reproducible baseline tailored to BRIDGE’s structural heterogeneity. TCH-Net’s architecture is decisively multi-branch, explicitly fusing three distinct modalities:
Branch representations, after initial shared nonlinear feature projection, are integrated with a novel Cross-Branch Gated Attention Fusion (CB-GAF) mechanism. Each branch independently queries the other two via cross-attention; a learnable per-branch sigmoid vector gate enables feature-wise, asymmetric fusion calibrated by input context.
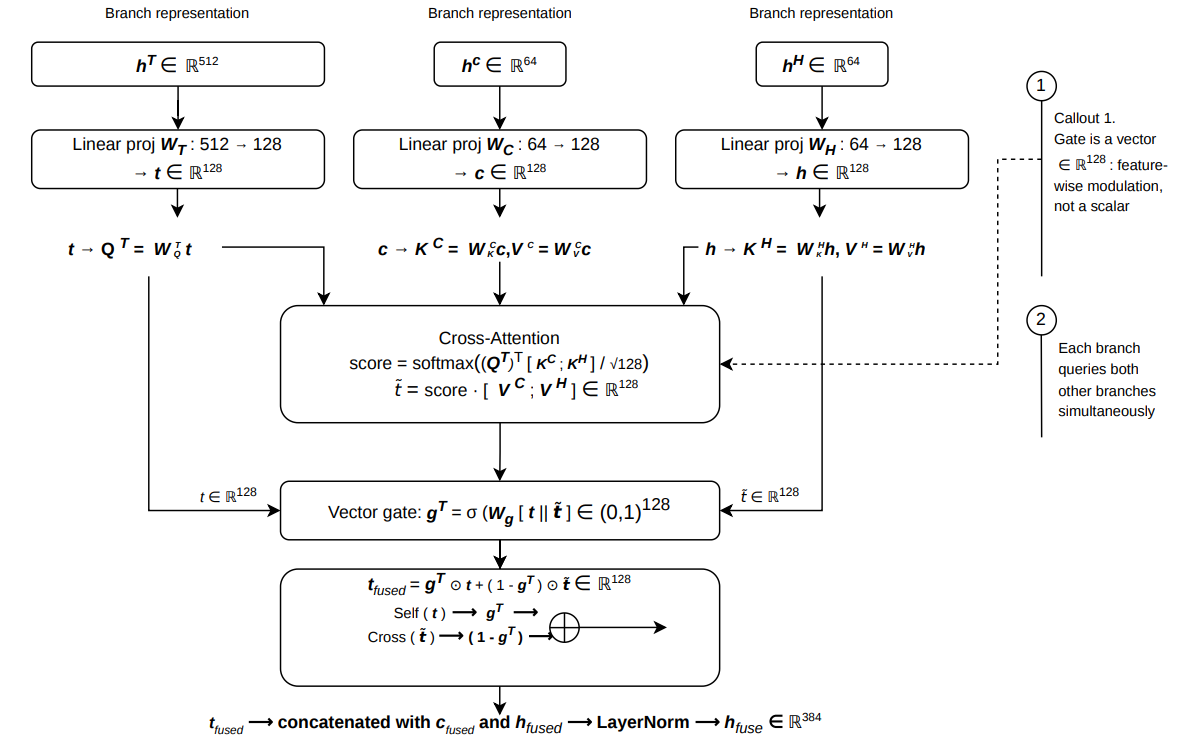
Figure 2: CB-GAF mechanism enables dynamic cross-branch information flow, modulated by per-branch, feature-wise gates.
The final output layer employs a residual skip pathway for improved gradient dynamics and auxiliary feature reconstruction regularisation to stabilise training in the presence of missing data.
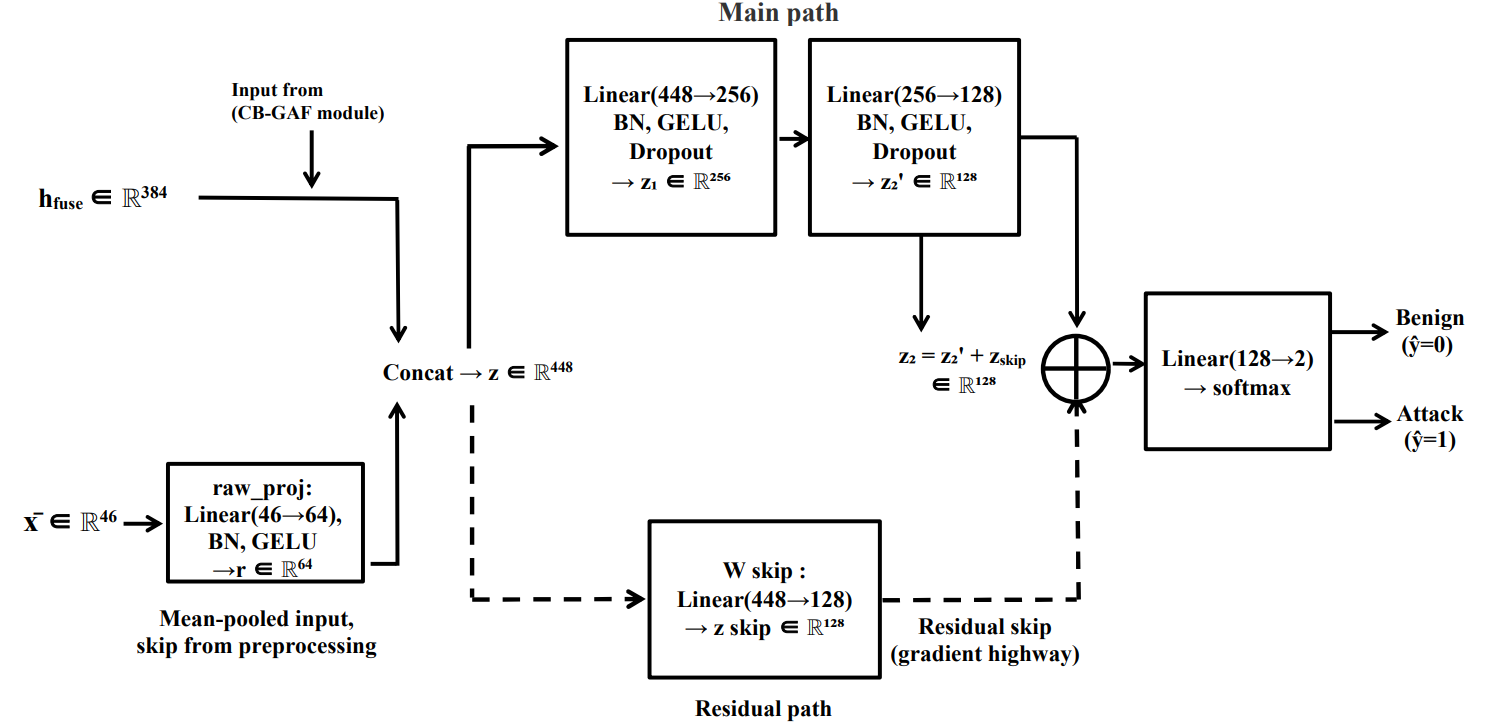
Figure 4: Classification head with a residual connection ensuring robust gradient propagation.
Experimental Evaluation
Benchmarking Against Prior Art
TCH-Net is comprehensively evaluated against twelve established baselines: recurrent models (BiLSTM, BiGRU), convolutional (1D-CNN, CNN-LSTM), transformer IDS, classical (RF, XGBoost), autoencoder-based, DNN, and GNN architectures. All models are assessed under identical data processing, balancing, and evaluation regimes. TCH-Net achieves the highest score on all key metrics (mean F1 =0.8296, ROC-AUC =0.9380, MCC =0.6972), with statistically significant performance improvements across the board.
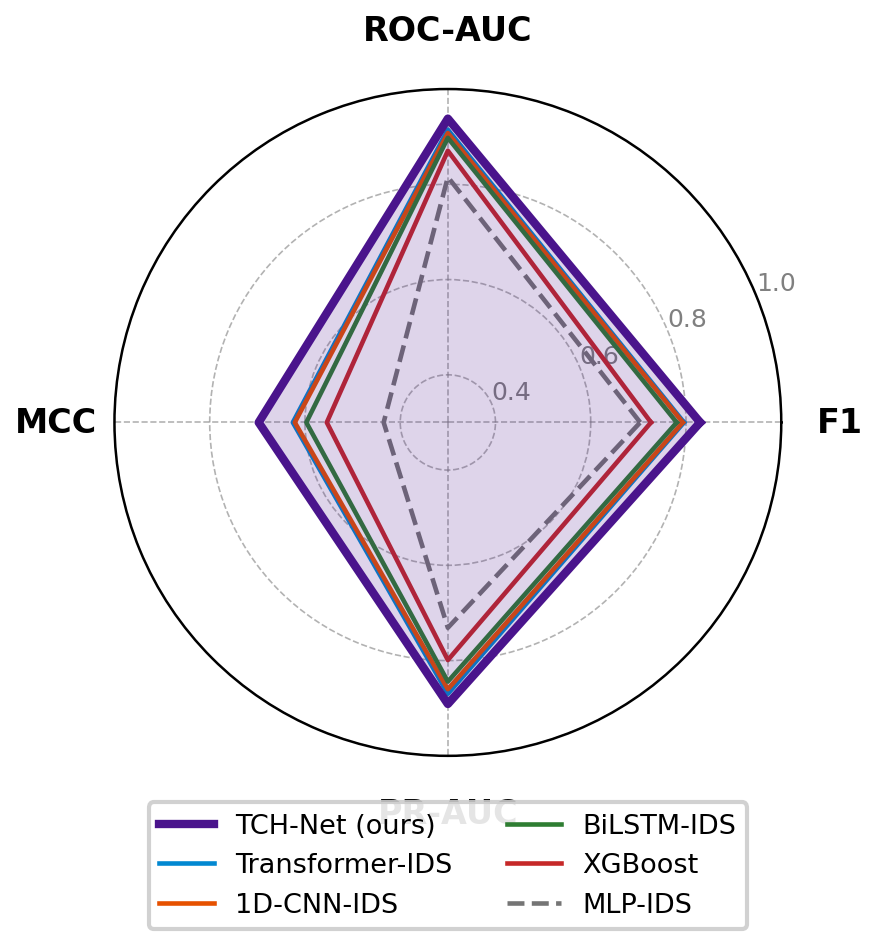
Figure 5: Radar plot showing TCH-Net’s metric superiority over top baseline models.
Ablation and Component Analysis
Ablation experiments unequivocally demonstrate that all three branch types contribute orthogonally—removal of any single branch or CB-GAF results in consistent degradation (>0.054 F1 loss). The contextual branch, in particular, is indispensable for calibrating information flow based on dataset provenance and coverage.
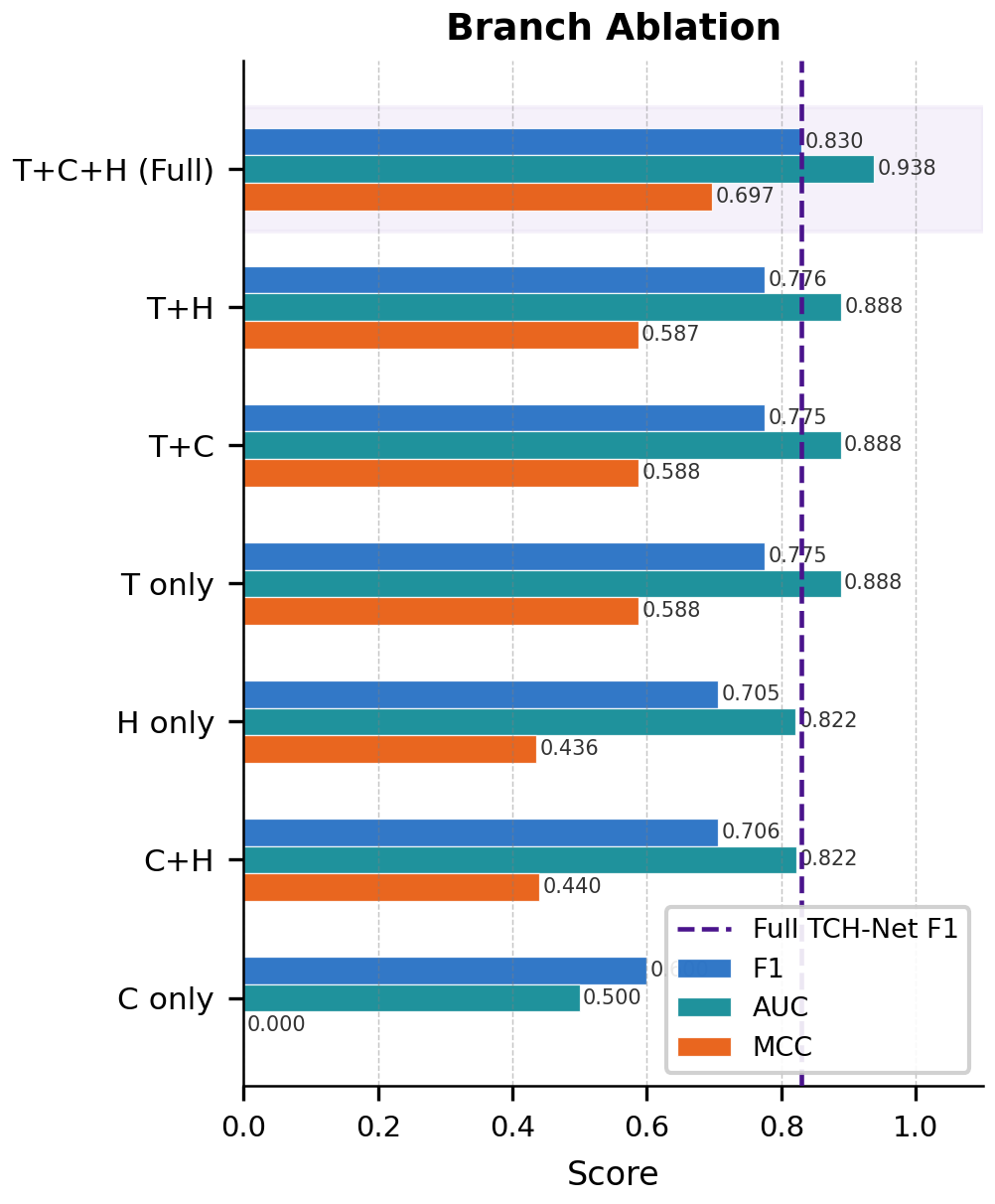
Figure 6: Branch ablation study confirms the necessity of all three branches and CB-GAF for optimal performance.
Cross-Dataset Generalisation and Domain Shift Measurement
The principal value of BRIDGE lies in its reproducible quantification of the generalisation gap. LODO results demonstrate that even state-of-the-art architectures (including TCH-Net and all established deep baselines) suffer a mean F1 collapse from 0.83 (random split) to 0.56 (LODO), exposing the domain shift as a structural barrier that cannot be elided via feature alignment alone.
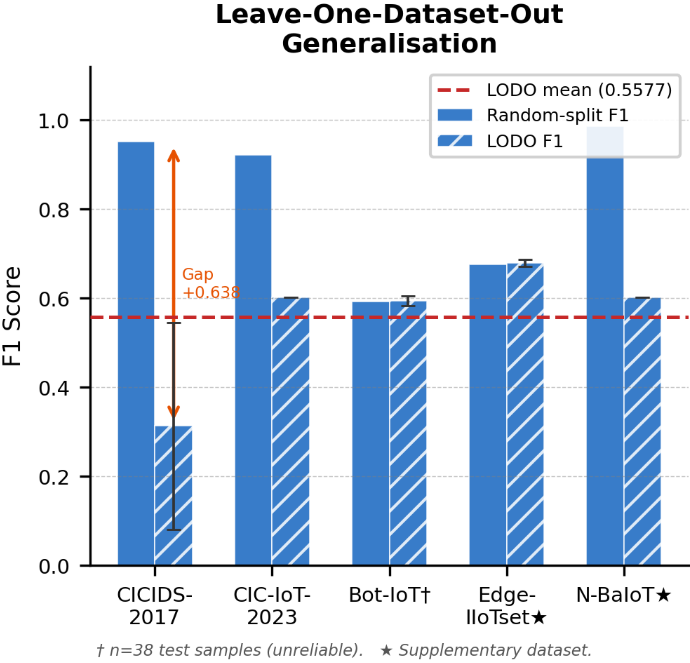
Figure 7: Leave-One-Dataset-Out (LODO) F1 scores reveal the severity of the generalisation gap; in-distribution F1 is not predictive of cross-domain performance.
A generalisation shortfall as high as −0.638 for single-dataset-dominant settings (CICIDS-2017) underscores the necessity of methods that go beyond naive alignment, motivating future work on domain-adaptive architectures.
Practical and Theoretical Implications
BRIDGE provides a community benchmark for cross-domain IoT IDS generalisation. By establishing a rigorous, reproducible protocol and canonical feature vocabulary, it makes systematic progress in domain adaptation actually measurable—a critical advance for the field. The findings invalidate prior optimism rooted in single-dataset results and recenter the research agenda on approaches robust to feature-set heterogeneity and distributional shift.
TCH-Net, via multi-branch fusion and CB-GAF, demonstrates that architectural heterogeneity and provenance conditioning are effective but not sufficient: an F1 gap of ∼0.27 in LODO remains an open problem. Future work should focus on domain adversarial training regimes, dataset-conditional normalisation, and extension to diverse packet-level input representations. Additionally, the generalisation-critical setting of multi-class attack classification (beyond binary detection) is theoretically and operationally salient.
On the practical front, TCH-Net’s computational efficiency (∼2.7M parameters, 6.4ms inference latency, <11MB RAM) is compatible with current-generation edge inference platforms, making real-world deployment in IoT gateways feasible. However, deployment in ultra-constrained microcontroller settings will necessitate further advances in model compression via knowledge distillation and quantisation.
Conclusion
This work exposes and quantifies the generalisation problem in IoT botnet detection via the BRIDGE benchmark and establishes TCH-Net as a new strong multi-modal baseline. The persistent domain shift evidenced by the LODO F1 gap presents a compelling direction for future algorithmic innovation targeting robust adaptation under severe feature and distribution mismatch. The canonical vocabulary, codebase, and evaluation protocol provided by BRIDGE now enable the research community to measure progress on foundational generalisation challenges, moving the field beyond overfitting to specific, isolated datasets.