- The paper shows that split-level noise in subject-exclusive cross-validation can mask true performance gains, often exceeding reported SOTA improvements.
- The study reveals that threshold-dependent F1 scores exhibit 2–3 times higher volatility compared to AUC, highlighting metric sensitivity to stochastic partitioning.
- It introduces Leave-One-Dataset-Out (LODO) evaluation as a superior protocol to capture true cross-dataset generalization and mitigate evaluation instability.
Quantifying Evaluation Instability in Facial AU Detection: Protocol Noise and LODO as a New Standard
Introduction
The evaluation of facial Action Unit (AU) detection models has historically relied on subject-exclusive cross-validation within single datasets, presupposing that such protocols offer stable and statistically reliable benchmarks. The paper "Beyond the Fold: Quantifying Split-Level Noise and the Case for Leave-One-Dataset-Out AU Evaluation" (2604.02162) systematically interrogates this assumption. The authors rigorously quantify both intra-dataset (split-level) evaluation noise and inter-dataset (domain) variability, providing compelling evidence that widely claimed state-of-the-art (SOTA) improvements are often indistinguishable from stochastic variance induced by random subject partitioning. Moreover, the work advocates for Leave-One-Dataset-Out (LODO) cross-dataset evaluation as a more robust, interpretable baseline for AU evaluation, substantiating this with empirical results and statistical analysis.
Split-Level Noise in Subject-Exclusive Cross-Validation
A central finding is the presence of significant split-level noise when subject-exclusive cross-validation is used for AU detection. On BP4D+, repeated random assignments of subjects to 3-fold splits yielded a 95% empirical noise floor of ±0.065 in average F1 score—often exceeding the magnitude of incremental improvements reported in recent literature.
This instability is not uniform across AUs. Low-prevalence units (e.g., AU1, AU4, AU24) exhibited the highest volatility, with 95% F1 margins surpassing 0.11–0.16, whereas high-prevalence AUs (e.g., AU6, AU10, AU12) were much more stable. Importantly, the volatility pattern persisted across diverse backbone architectures (ResNet50, VGG16, MobileViT), pinpointing the protocol and subject sampling as the dominant noise sources rather than model class.
(Figure 1)
Figure 1: Range of per-AU F1 and AUC scores across 3-fold cross-validation splits, visualizing noise introduced solely by subject partitioning.
Metric choice further compounds the problem: threshold-dependent F1 demonstrated 2–3 times higher fold-induced volatility compared to threshold-independent AUC. As a result, SOTA claims based on marginal F1 deltas of +0.01–+0.02 are routinely confounded by protocol variability, and model ranking is not stable under repeated partitioning.
Leave-One-Dataset-Out (LODO): Exposing True Generalization
The paper asserts that cross-domain robustness remains unassessed in protocol noise-dominated evaluations. To address this, the authors introduce Leave-One-Dataset-Out (LODO) as a gold-standard protocol. In LODO, models are trained on the pooled union of all but one AU dataset and evaluated on the held-out set, removing intra-dataset split randomness entirely and foregrounding true domain generalization.
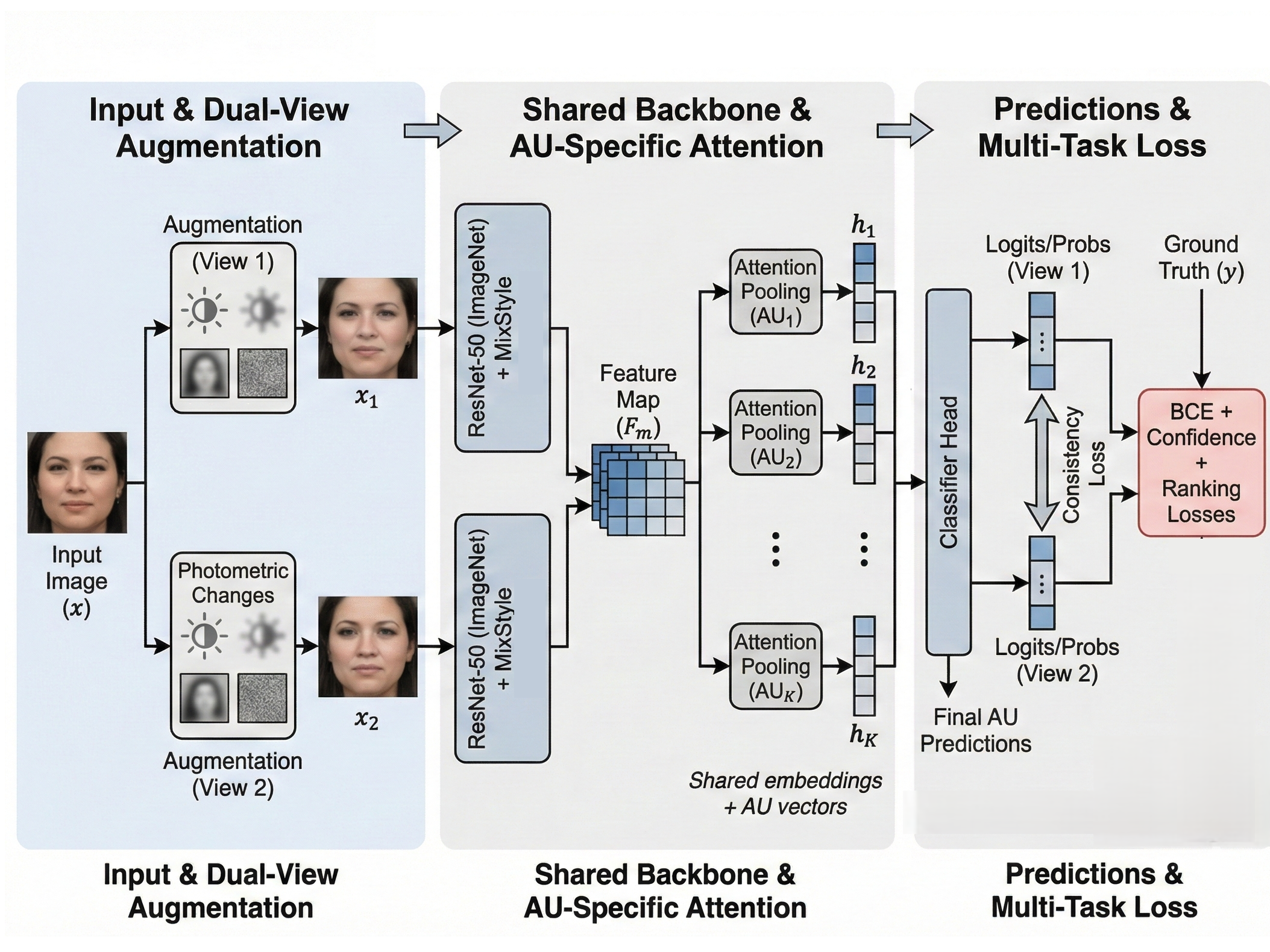
Figure 2: LODO training pipeline—models are trained on the union of all but one dataset and evaluated on the unseen target dataset, with domain robustness modules (e.g., MixStyle) encouraging feature invariance.
Experiments on five core AU datasets (BP4D, BP4D+, DISFA, GFT, UNBC) revealed that per-AU base rates and annotation coverage vary substantially across corpora, introducing real domain shifts. LODO results highlighted pronounced instability in threshold-dependent metrics: while AUCs remained moderately consistent under transfer, operating-point F1 scores frequently collapsed for rare AUs in the target set. Subject-level bootstrapping confirmed that these cross-dataset shifts were systematic and statistically significant in a majority of cases, especially for low-prevalence AUs where F1 Domain Sensitivity exceeded 80–100% across transfers. In contrast, AUC showed much lower domain-induced sensitivity, revealing a bifurcation between ranking robustness and operating-point reliability.
Implications and Recommendations for Evaluation Protocols
The synthesis of intra-dataset and inter-dataset analyses yields critical implications for AU detection evaluation:
- Protocol-Induced Noise Dominates Small Gains: Performance differences within the intra-dataset noise floor (e.g., <0.06 F1) should be considered statistically insignificant and not interpreted as definitive SOTA improvements.
- Metric Selection is Crucial: F1 exaggerates the effects of both stochastic fold noise and domain shift; robust assessment mandates the inclusion of threshold-independent scores (AUC), explicit reporting of variance, and statistical significance testing.
- LODO as a Standard: LODO or related multi-dataset hold-out schemes should supplant single-dataset cross-validation as the principal evaluation method to accurately benchmark cross-domain generalization and model robustness.
- Variance Reporting and Protocol Transparency: Authors should systematically report metrics across repeated splits and LODO folds, including confidence intervals or bootstrap-based significance to prevent overclaiming on spurious deltas.
The demonstrated protocol-induced volatility further explains the saturation of progress on standard AU benchmarks in the last several years: most recent advances in high-performing models cannot be reliably distinguished under standard protocols, conflating evaluation artifacts with architectural benefits.
Limitations and Future Directions
While establishing LODO as a necessary advance in evaluation rigor, the paper recognizes intrinsic limitations. Current LODO results are bounded by the diversity and representativeness of available datasets; extending this paradigm to newer, more heterogeneous data is essential for external robustness. The extension of variance analysis to repeated LODO and hybrid cross-validation protocols, alongside ablation on backbone, domain perturbation, and dataset composition, will be indispensable for future work. The authors advocate scaling benchmark construction and providing comprehensive reporting across protocols.
Conclusion
This paper definitively establishes that subject-exclusive cross-validation does not provide stable or reliable model ranking in facial Action Unit detection due to significant split-level noise—a finding that generalizes across architectures and metrics. The introduction of LODO as a protocol, grounded in its ability to measure bona fide domain generalization, marks a principled upgrade over traditional evaluation. Theoretical and empirical assessments contained herein have clear implications for how the field should structure, interpret, and report AU detection benchmarks, and by extension, how similar issues of protocol-induced noise may be systematically addressed in other domains of machine learning.

