- The paper introduces a JKO-style minimization framework using a graph-dependent metric to recover free-energy dynamics from discrete snapshots.
- It leverages discrete optimal transport and Riemannian geometry to compute geodesics and recover generative potentials on varied graph structures.
- Empirical results show lower Hellinger distances than baselines, demonstrating robust performance across noise regimes and diverse graph topologies.
Learning Discrete Diffusion of Graphs via Free-Energy Gradient Flows: An Expert Review
Introduction and Context
The paper "Learning Discrete Diffusion of Graphs via Free-Energy Gradient Flows" (2604.11311) addresses the longstanding theoretical and computational gap in constructing diffusion models over discrete spaces through gradient flow frameworks. The established Jordan–Kinderlehrer–Otto (JKO) scheme, which underpins many successful continuous diffusion models via the Wasserstein-2 (W2) geometry, fails to translate directly to finite-state discrete spaces due to fundamental incompatibilities—the metric derivative in W2 diverges for non-constant probability curves on discrete domains. This has rendered discrete gradient flow modeling both theoretically incomplete and computationally prohibitive, limiting the principled design of discrete diffusion models. The paper resolves these theoretical obstacles by adapting the discrete transport geometry of Maas et al. and the discrete Benamou–Brenier dynamic formulation, leading to a practical JKO-style learning methodology for discrete diffusion processes on graphs.
Discrete Gradient Flow Geometry
The central technical innovation is the adoption of a graph-dependent metric, WK, on the probability simplex, parameterized by an irreducible, reversible Markov kernel K over the finite set X. The core insight is that, under an appropriate choice of the mobility function (the logarithmic mean), the discrete heat equation on X becomes the gradient flow of the Kullback–Leibler divergence in the WK geometry—mimicking the role played by the Shannon entropy in the W2 geometry for the continuous case.
This metric leads to a Riemannian structure on the interior of the probability simplex, P∗(X), with tangent spaces identified with discrete gradients. The corresponding geodesics, gradient operators, and continuity equations are computationally tractable when appropriately formulated, enabling gradient flow characterization of generative Markov jump processes on graphs including highly structured, sparse, and inhomogeneous classes.
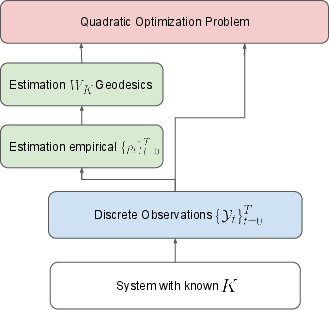
Figure 1: Schematic breakdown of the proposed pipeline: estimation of densities, geodesic computation, and quadratic loss-based learning.
Methodological Contribution: Learning Functionals from Snapshots
The paper introduces a JKO-style minimization for the discrete domain:
ρt+1=argρ∈P∗min{F(ρ)+2τ1WK(ρ,ρt)2}
Here, W20 is the free energy functional whose form is unknown: W21, with W22 a potential, and W23 the (relative) entropy. The learning target is to recover W24, i.e., both W25 and W26, given only temporal snapshots of empirical distributions. The key technical step is leveraging first-order optimality conditions: at the minimizer, the Riemannian gradient with respect to W27 vanishes, yielding a system that can be differentiated and minimized by quadratic loss.
The algorithm is computationally appealing: given empirical snapshots, it estimates densities and computes geodesic velocities via an efficiently structured quadratic program (solved by Schur–Cholesky factorization), which uniquely exploits the Riemannian geometry of W28. This unlocks sample-efficient recovery of the underlying dynamics without requiring trajectory data or access to the transition kernel.
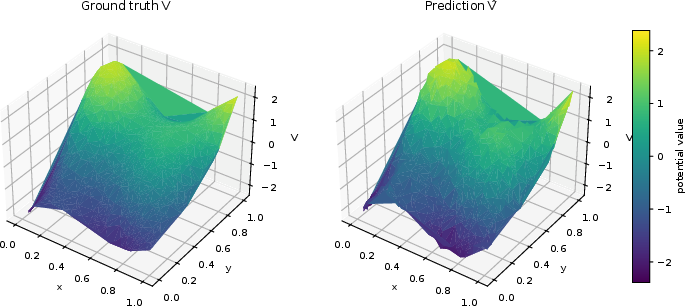
Figure 2: The left shows a smooth ground-truth potential on a Delaunay graph, while the right illustrates recovery of the potential by the proposed numerical method.
Numerical Results
Benchmarking and Baselines
The authors perform extensive evaluation on synthetic datasets constructed over a suite of graph classes with diverse topological properties, using randomly sampled ground-truth potentials and noise levels. Figures 5 and 6 showcase the breadth of graph topologies considered for benchmarking (e.g., stochastic block models, grids, small-world, Delaunay, complete, W29-partite, etc.).

Figure 3: Sampled representatives of the main graph classes used to benchmark learning and inference performance.
Against OpenFIM—a strong foundation model for zero-shot Markov jump process inference—the proposed method exhibits consistently lower Hellinger distances across all tested noise regimes and graph classes, with materially reduced parameter counts and training time, even for small graphs where the baseline is pre-trained.
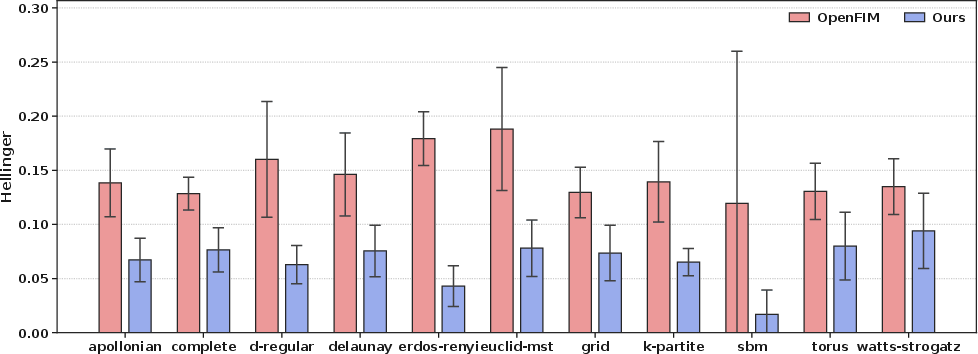
Figure 4: Hellinger distance comparison across all WK0 levels, demonstrating the systematic performance advantage of the proposed approach over OpenFIM.
Scaling and Ablation
Scalability with respect to the number of samples and state space size is favorable. Performance, as measured by Hellinger distance, is largely stable beyond moderate sample sizes, indicating that empirical density estimation is sufficient for practical learning regimes.
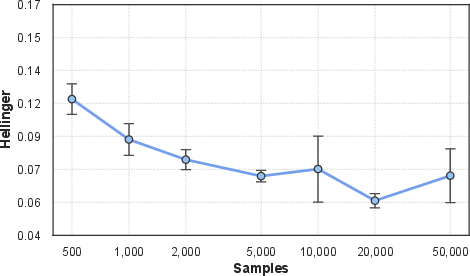
Figure 5: Hellinger distance decreases and stabilizes with increasing sample size, averaged across all graph classes of fixed size.
Increasing the graph size causes a modest, approximately linear degradation of predictive accuracy. Occasional optimization failures (e.g., degenerate solutions at the simplex boundary) become non-negligible as the space grows, attributed to inherent instabilities near the simplex boundary—a generic pathology for Riemannian geometry with degeneracy at the boundary.
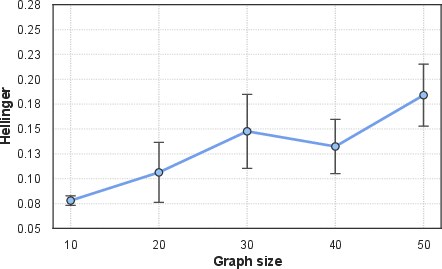
Figure 6: Scaling Hellinger distance versus graph size, capturing the linear trend of error growth with increasing state space.
Theoretical Impact and Extensions
The main theoretical significance is in operationalizing free-energy gradient flows—previously established in pure mathematics but not exploited computationally—for discrete, finite spaces relevant for generative modeling on graphs. The construction provides a clean route for learning the structure of discrete diffusion trajectories as gradient flows of explicitly parameterized functionals. Importantly, this mechanism is agnostic to the choice of underlying graph WK1 and supports arbitrary potentials, thus extending beyond classical heat flow and accommodating heterogeneity in graph structure.
Practically, this framework enables both analysis and synthesis of generative Markov processes and could, with further scalability, impact discrete generative models for molecular design, language modeling, and complex combinatorial data. Integration with scalable, conditional, or marginal-score modeling architectures now prevalent in large-scale discrete diffusion models (e.g., language and protein generation) is a natural extension, as is leveraging log-concavity and irreducibility regularization to robustify learning in extremely large discrete spaces.
Limitations
The requirement for explicit density estimation from temporal snapshots, as opposed to leveraging conditional score matching or sufficient statistics (e.g., as in sequence denoising score-based generative models), currently restricts applicability to moderate-size graphs. While the presented approach is computationally efficient for WK2 up to a few hundred, naive scaling to very high-dimensional discrete spaces (e.g., token graphs for long sequences) is precluded by the curse of dimensionality in density estimation. The theory, however, does not preclude integration with scalable diffusion model architectures; rather, efficient conditional factorization remains an open engineering direction.
Conclusion
This paper provides a principled, implementable solution for learning discrete diffusion dynamics on finite graphs as gradient flows of free-energy functionals. Drawing on recent mathematical advances in the geometry of discrete optimal transport, it introduces an efficient method for functional recovery based on WK3-geodesic computation and quadratic optimality loss. Empirically, the approach yields strong predictive performance, outperforming recent foundation models in small- to medium-sized settings. The geometric and algorithmic framework established herein lays the theoretical groundwork for scaling discrete gradient flow modeling toward domains of practical significance in generative learning.
References
- Dario Rancati, Jan Maas, Francesco Locatello. "Learning Discrete Diffusion of Graphs via Free-Energy Gradient Flows" (2604.11311)

