- The paper introduces VLEED, a variational framework that separates identity-relevant and demographic information in face embeddings.
- It employs a split-latent VAE with an entropy-based loss to minimize mutual information between identity and sensitive attributes.
- Empirical results demonstrate controlled privacy–utility tradeoffs and bias mitigation on face recognition benchmarks.
Variational Latent Entropy Estimation Disentanglement: Controlled Attribute Leakage for Face Recognition
Introduction and Motivation
Current deep face recognition (FR) systems encode identity in learned embedding spaces, but these embeddings unintentionally leak other soft-biometric information such as gender and ethnicity. This results in both privacy concerns—if embeddings are shared or compromised, demographic attributes can be inferred without consent—and fairness issues, as downstream systems may exploit these attributes, fostering algorithmic bias. Disentanglement, if realized operationally, offers a mechanism to minimize the mutual information between identity-relevant and sensitive demographic data, enabling post-hoc mitigation of leakage and bias while preserving FR utility.
The paper "Variational Latent Entropy Estimation Disentanglement: Controlled Attribute Leakage for Face Recognition" (VLEED) (2604.11250) introduces a principled, information-theoretic variational framework for post-hoc transformation of pretrained face embeddings. The primary objective is to dissociate and suppress categorical demographic attributes (e.g., gender, ethnicity) from the identity-relevant representation. The method is evaluated against both linear and nonlinear state-of-the-art baselines on multiple FR benchmarks, demonstrating that VLEED achieves substantial reduction in attribute leakage with fine-grained control over the privacy–utility tradeoff and concomitant mitigation of group-level bias.
Methodology: The VLEED Framework
VLEED employs a split-latent variational autoencoder (VAE) architecture to decompose face embeddings into two complementary latent subspaces:
- Residual Latent (Zr): Captures identity-relevant information while being explicitly trained to minimize retention of sensitive attributes.
- Class Latent (Zc): Encodes the sensitive attribute (e.g., gender or ethnicity) in a controllable fashion, leveraging class-conditional priors to enforce separation.
This framework is instantiated post-hoc: pretrained FR embeddings are treated as inputs, and VLEED learns a transformation without requiring access to the original model or data.
For operational disentanglement, the core loss consists of three components:
- Reconstruction Term: Ensures that combined latent codes preserve the geometry of the original embedding, supporting downstream verification.
- KL Divergence Terms: Regularize both latents to their respective priors, with the class latent using class-conditional means.
- Entropy-based Disentanglement Term: Directly encourages minimization of the mutual information I(C;Zr) by maximizing H(C∣Zr). This is realized practically via an auxiliary classifier trained adversarially to distinguish classes from Zr, while the encoder strives to make the classifier maximally uncertain.
The disentanglement strength is modulated by a hyperparameter λdis, providing continuous control over the privacy–utility tradeoff.
Empirical Results
Attribute Leakage and Verification Tradeoff
VLEED is evaluated on IJB-C, RFW, and VGGFace2 under both gender and ethnicity removal scenarios. Attribute leakage is measured using linear (LR, shallow MLP) and nonlinear (deep MLP) classifiers, while verification performance is recorded through True Match Rate (TMR) at fixed FMR thresholds, with additional analysis of ROC curves and group-level Gini coefficients for fairness.
As λdis increases, VLEED progressively degrades attribute predictability for linear probes towards chance levels with relatively preserved verification rates, highlighting effective suppression of linearly encoded demographic information. Nonlinear leakage (measured by deep MLP accuracy) persists at moderate values of λdis, but collapses sharply at the point where verification rates begin to degrade substantially. For ethnicity, removal is achieved more abruptly and with less utility cost compared to gender.
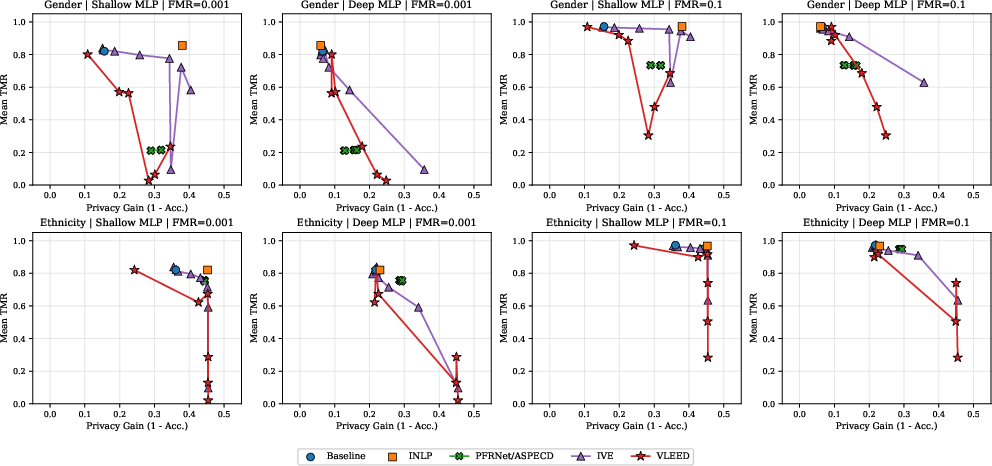
Figure 1: Visual analysis of VLEED behaviour and comparison with prior methods. (a)~t-SNE visualisation of how disentanglement strength affects the residual latent space. (b)~Aggregate privacy–utility tradeoff curves across datasets.
t-SNE visualizations of the residual latent space (Figure 4a) show class-conditional clusters (demographic groupings) in baseline embeddings. As disentanglement pressure increases, these clusters dissolve, resulting in a homogeneous latent space with minimal attribute-related structure and, ultimately, a collapse towards a concentrated spherical cap under high λdis. The privacy–utility tradeoff curves (Figure 4b) trace a controlled descent, where utility (TMR) is systematically exchanged for privacy (leakage reduction), with VLEED dominating prior methods in producing smoothly tunable operating points.
Comparison to Baselines
Compared to INLP, IVE, and PFRNet/ASPECD:
- INLP: Efficiently eliminates linear leakage but retains nonlinear attribute information.
- IVE: Effective in discrete steps but suffers abrupt collapse in utility when aggressively applied.
- PFRNet/ASPECD: Uses moment-matching for group-conditional alignment, but reduction in nonlinear leakage is limited by practical and numerical constraints; increasing disentanglement penalties beyond moderate levels yields little improvement.
VLEED, uniquely, manages fine-grained, empirically stable control over both linear and nonlinear leakage, spanning a wide Pareto frontier (see Figure 4b). This improvement is attributable to VLEED’s entropy-maximizing objective, which is not restricted to low-order statistics and integrates seamlessly with deep, nonlinear probes.
ROC and Fairness Analysis
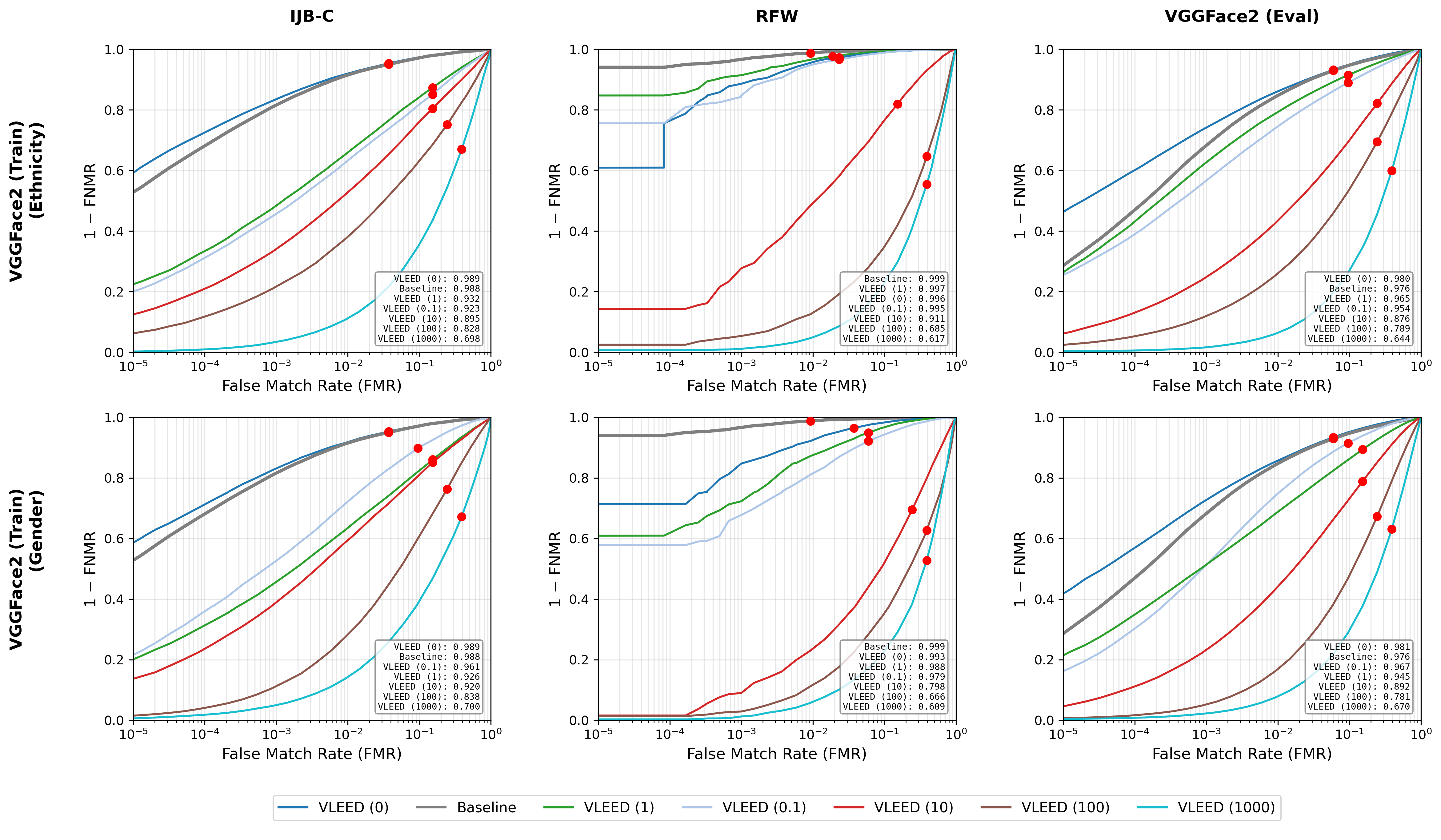
Figure 2: ROC curves (TMR vs. FMR) for VLEED across varying disentanglement weights λdis.
VLEED’s ROC curves show systematic degradation with increasing privacy pressure—a desired property for deployment, as it facilitates selection of a target operating point for a given privacy requirement.
Assessment of the Gini coefficient of intra-group FMR differentials demonstrates that as leakage declines, variation in error rates across demographic groups is reduced, indicating substantial bias mitigation. However, the relationship is complex and, especially at intermediate operating points, can be non-monotonic due to nontrivial geometric effects in latent contraction and group balance idiosyncrasies.
Theoretical and Practical Implications
VLEED’s introduction of entropy-based disentanglement via variational inference provides several salient advantages:
- Theoretical Fairness: Directly minimizing Zc0 is fundamentally optimal for attribute suppression, extending beyond the moment-matching or linear-nullspace regimes of prior work.
- Practical Tunability: The continuous Zc1 schedule yields flexible, deployment-friendly privacy–utility tradeoffs.
- Stability and Generality: Training is empirically stable, handling categorical variables with arbitrary cardinality, and is immediately applicable to any deployed FR embedding backbone.
However, privacy guarantees are empirical, and performance is backbone-dependent. Assessing formal leakage resilience against adversaries with unbounded capacity remains for future work.
Conclusions
The VLEED framework establishes a new paradigm for post-hoc, distributional, information-theoretic disentanglement of soft-biometrics in FR embeddings. The entropy-based objective enables robust removal of categorical demographic information (gender, ethnicity) from identity-preserving representations, with empirical reductions in both attribute leakage (linear and nonlinear) and group-level bias (fairness disparity), controlled via a single interpretable parameter. In comparative evaluation, VLEED demonstrates improved privacy–utility tradeoffs and tuning granularity relative to both linear and nonlinear state-of-the-art post-hoc methods.
Anticipated extensions include simultaneous removal of multiple (potentially continuous) attributes, deployment on heterogeneous backbone features, and formal upper bounds for residual leakage under adversarial threat models.