- The paper presents COST-Q, a framework for cost-optimal sequential testing that uses doubly robust Q-learning to achieve unbiased policy estimation even under model misspecification.
- It leverages innovative pseudo-outcomes, path-specific inverse probabilities, and backward induction to balance predictive accuracy with testing costs in adaptive clinical settings.
- Simulation and real-world results show reduced predictive loss and enhanced specificity, demonstrating COST-Q’s effectiveness in personalized diagnostic pathways.
Cost-Optimal Sequential Testing via Doubly Robust Q-learning: A Technical Synthesis
Introduction
This paper presents COST-Q ("Cost-optimal Sequential Testing via Doubly Robust Q-learning"), a framework for personalized, history-dependent, cost-sensitive sequential test selection, with a specific focus on retrospective clinical datasets where missingness arises adaptively from prior clinician decisions. The key innovation is a doubly robust Q-learning formulation that enables unbiased policy estimation even when either the acquisition propensity or the contrast model is misspecified. The framework combines path-specific IPW with orthogonal pseudo-outcomes, yielding strong theoretical guarantees and improved performance in simulations and real-world data.
The sequential decision process involves an initial baseline feature block X0, always available (cost-free), and M optional test blocks. Actions are represented as sequences (S1,...,SM), and the valid decision space respects constraints (e.g., tests can't be repeated). Each information state s corresponds to a terminal feature set and cumulative cost Cs.
Due to adaptive acquisition (e.g., additional tests are ordered based on prior results), missingness is informative and must be modeled explicitly. The analysis is built on a sequential Missing at Random (MAR) assumption: at each stage, the acquisition decision depends only on previously observed data—formally, Sj⊥(X−Oj,Y)∣Observed History, where Oj denotes the set of observed tests up to stage j.
The task is to learn a policy d that, at each stage, selects the next test (or terminates) to minimize the expected sum of predictive loss plus cumulative acquisition cost. This is formalized via stage-wise cost-augmented loss and Bellman recursion, with the optimal policy characterized by contrast functions capturing the expected utility of acquiring further information.
Doubly Robust Q-learning Algorithm
COST-Q operationalizes policy learning via a backward, stage-wise Q-learning procedure built upon doubly robust pseudo-outcomes. At each stage:
- Pseudo-outcomes are constructed using path-specific inverse probability weights (from the estimated acquisition model) combined with auxiliary contrast predictions. These have the form: Φ=Δ(Z)+w(V;π)[T−Δ(Z)], where M0 is the conditioning variable, M1 is the partial label, and M2 is the normalized path-specific importance weight.
- Double robustness is ensured: the estimator is unbiased if either the acquisition (propensity) model or the contrast model is correctly specified.
- Cross-fitting is used to avoid overfitting and bias, leveraging M3-fold sample splits so that nuisance parameter estimation is conducted independently of pseudo-outcome construction.
Backward induction proceeds from the final stage (full data acquired) to the initial state, with at each step the construction and regression of doubly robust pseudo-outcomes targeting the relevant conditional contrasts. The theoretical advantage is robust, consistent estimation of stage-wise contrasts and associated policy rules in the presence of complex, data-dependent missingness.
Statistical Guarantees
Theoretical analysis provides nonasymptotic oracle inequalities for the contrast estimators, showing that estimation error is bounded by the sum of oracle regression risk and second-order nuisance estimation bias (explicit in M4). Specifically, the following properties are established:
- Stage-wise double robustness: Consistency is achieved if either the pathwise propensities or contrast models converge at suitable rates.
- Policy regret: The expected regret of the learned policy is linear in the aggregate stage-wise estimation error.
- Misclassification bounds: Stage-wise misclassification probabilities are shown to be sublinear under margin conditions.
These rates hold for nonparametric or machine learning regressors as long as stability and cross-fitting are respected, and require only modest smoothness and positivity conditions.
Simulation Experiments
Simulation studies evaluated COST-Q against BOWL, Only-Complete, and one-shot policies under both correct and misspecified nuisance models at varying M5.
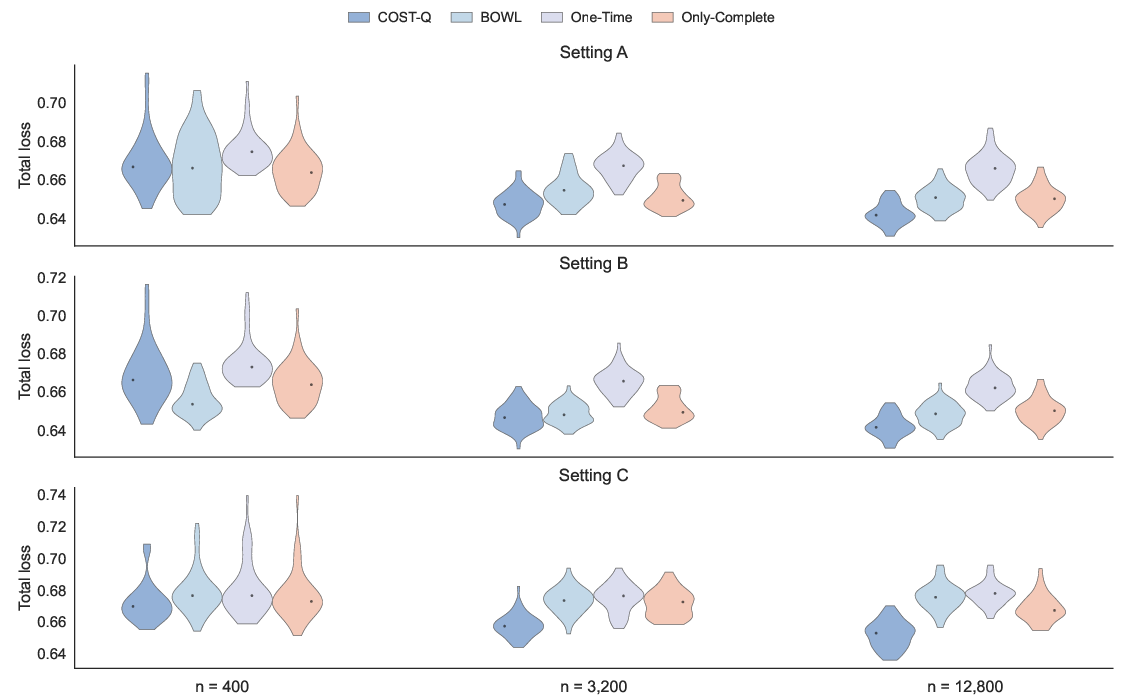
Figure 1: COST-Q delivers superior or competitive loss performance under three nuisance-model scenarios in simulation Scenario 1, especially in moderate-to-large samples.
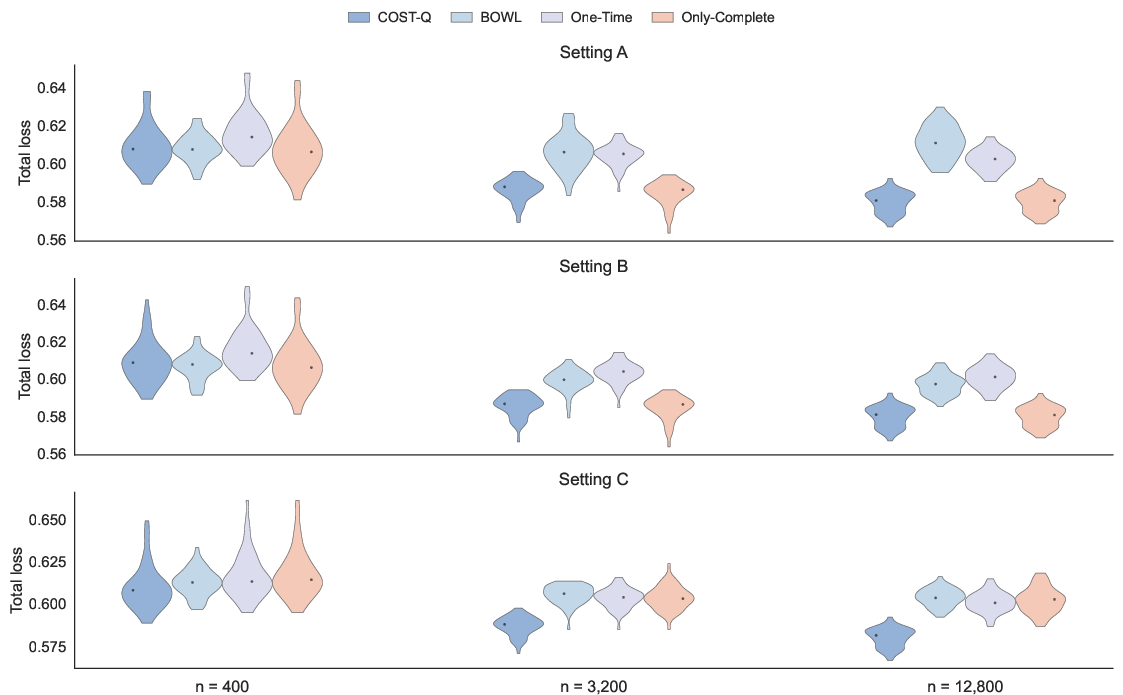
Figure 2: Simulation Scenario 2 further demonstrates robust performance by COST-Q under both correct and misspecified settings.
Key empirical findings include:
- Under correct specification, COST-Q matches or outperforms benchmarks as M6 increases.
- Under nuisance misspecification (erroneous acquisition or contrast models), COST-Q's double robustness yields clear performance advantages (e.g., loss reduction, lower prediction error).
- The benefits derive primarily from improved predictive accuracy rather than merely test cost reduction, indicating effective learning of the acquisition–prediction tradeoff.
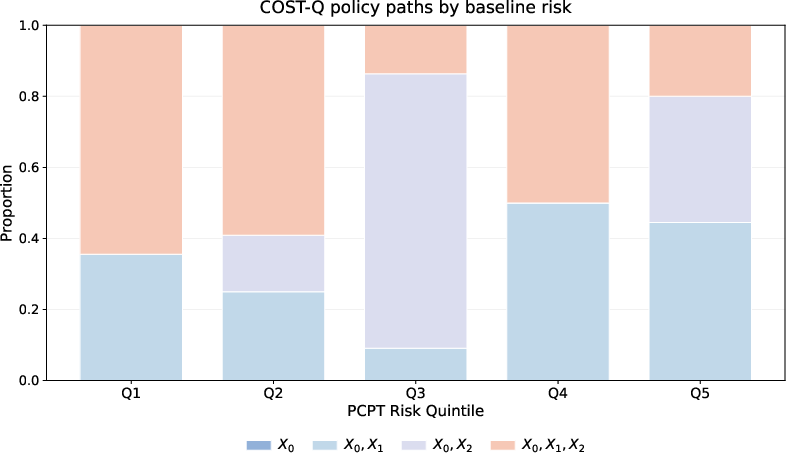
Application to Prostate Cancer Diagnostic Pathways
COST-Q is applied to the NCI-EDRN PCA3 prostate cancer diagnostic cohort, where the objective is to deploy blood and urine biomarkers in conjunction with baseline clinical risk (M7) for effective biopsy recommendations. Adaptive, sequential testing policies are compared on out-of-sample test cases using both cost-augmented loss and discrimination metrics.
Tables from the manuscript corroborate these findings for prediction loss, average cost, AUC, specificity, and G-mean.
Implications and Future Directions
COST-Q provides a rigorous solution for sequential, cost-sensitive feature/test selection under complex missingness in retrospective datasets. The main methodological implication is that double robustness and path-specific normalization are critical for unbiased, low-regret learning in clinical or other high-stakes settings where full data are rarely available. Practically, the approach is architecture-agnostic, can be optimized for explicit test budgets, and adapts to protocol constraints (e.g., permitted acquisition paths).
Open directions include:
- Extending to patient- and context-specific cost structures.
- Scaling to larger numbers of diagnostic actions.
- Integrating noncoarsened, censored, or unknown missing data mechanisms typical of broader healthcare or RL domains.
Conclusion
COST-Q bridges causal inference, reinforcement learning, and cost-sensitive prediction for clinical decision support. By explicitly modeling the acquisition mechanism and leveraging doubly robust pseudo-outcomes with backward induction, the framework realizes individualized, cost-efficient testing strategies that reduce measurement burden while maintaining or enhancing predictive accuracy. This represents a substantial improvement for observational datasets where test availability is contingent on prior outcomes and decisions.