- The paper proposes DualComp, a training-free dual-stream pipeline that adaptively compresses tokens to preserve both semantic details and geometric structures in ultra-high-resolution remote sensing images.
- It employs a duality-aware routing mechanism to assign token budgets for semantic and geometric streams, achieving up to a 42× token reduction while maintaining or boosting performance.
- Empirical evaluations demonstrate improved inference throughput and enhanced task accuracy in geometry-sensitive and semantic tasks, validating its effective plug-and-play design for MLLMs.
Semantic-Geometric Dual Compression for Ultra-High-Resolution Remote Sensing in MLLMs
Motivation and Problem Analysis
The proliferation of ultra-high-resolution (UHR) remote sensing imagery introduces significant computational bottlenecks in Multimodal LLMs (MLLMs) due to the explosion in visual token counts during patch-based feature encoding and AnyRes-style multi-cropping. Standard visual token compression techniques apply static, uniform strategies, ignoring the intrinsic dichotomy in remote sensing reasoning: object semantic tasks prioritize abstract semantics and favor aggressive denoising, while scene geometric tasks require retention of spatial topology for structural fidelity. The lack of task-adaptive token selection is a substantial limitation in scaling MLLMs to UHR imagery.
A pilot study demonstrates a task-dependent duality in token utility: increased compression benefits semantic-dominant subtasks, but is detrimental to geometry-dependent ones, revealing a tension between background redundancy and geometric evidence as a function of the reasoning target.
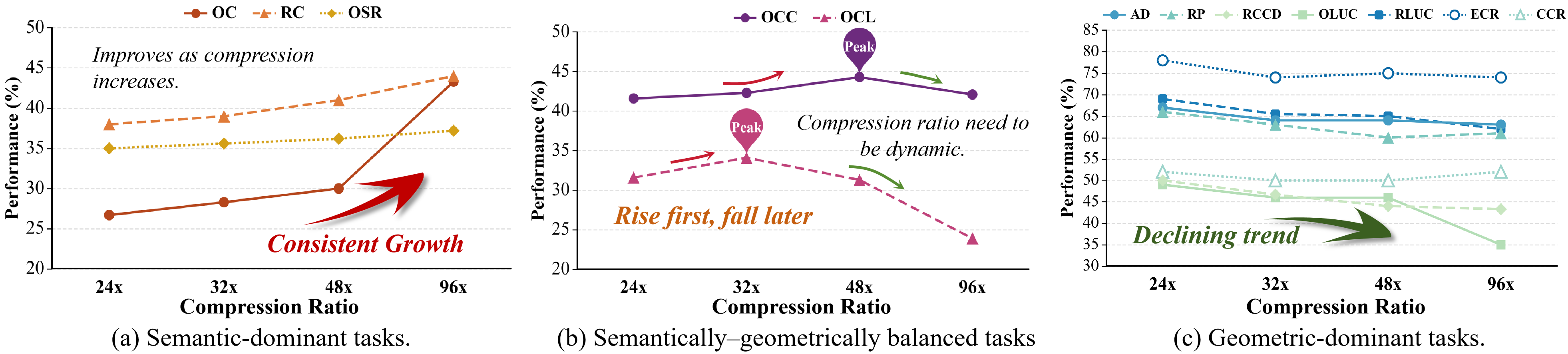
Figure 1: Ablation under varying compression ratios demonstrates that semantic tasks benefit from background token pruning, whereas geometry-centric tasks require context preservation.
DualComp: Task-Adaptive Dual-Stream Token Compression
To address the semantic-geometric duality, the paper introduces DualComp—a plug-and-play, training-free dual-stream visual token reduction pipeline. DualComp leverages an offline-trained, lightweight router driven by textual instruction to dynamically schedule compression aggressiveness and semantic-vs-geometric token allocation. This design fundamentally moves away from passive, task-agnostic token elimination to intent-aware evidence scheduling.
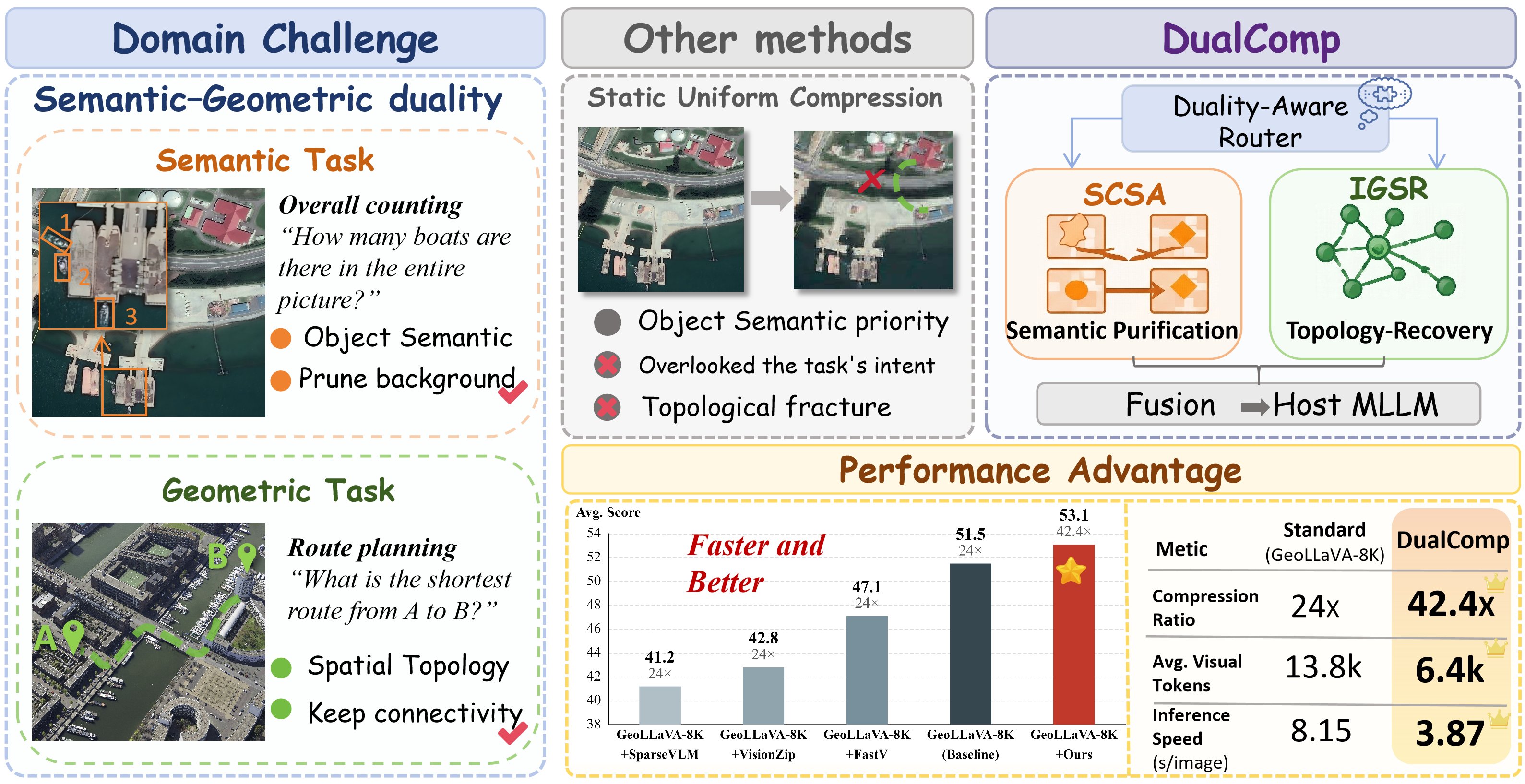
Figure 2: DualComp adaptively and efficiently manages semantic and geometric evidence via dual-stream compression, achieving robustness under high compression.
Duality-Aware Routing and Streamed Execution
DualComp's router parses task intent to infer (1) an overall retention strength ρ and (2) a duality allocation factor λ, which parametrically controls the ratio of tokens assigned to semantic and geometric streams. The router's outputs govern token budgets for each pathway, steering the compression process end-to-end.
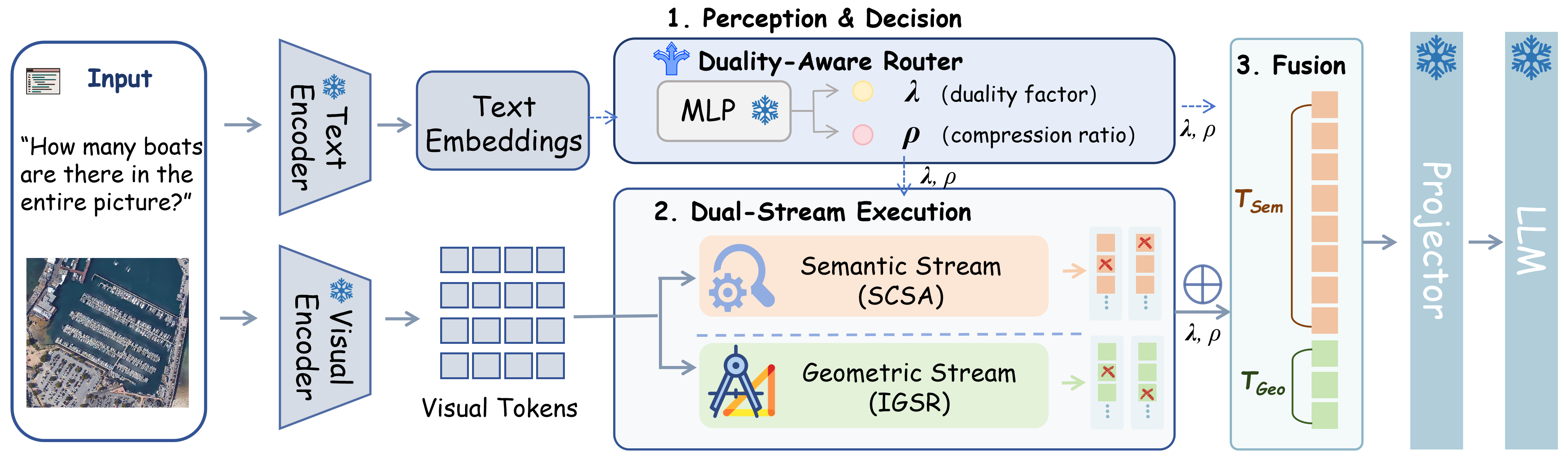
Figure 3: One-pass workflow: instruction-conditioned router outputs (λ,ρ), dynamically controlling SCSA (semantic) and IGSR (geometric) reduction and fusion.
Semantic Stream: Spatially-Contiguous Semantic Aggregator (SCSA)
SCSA targets background redundancy by spatially aggregating homogeneous background patches while ensuring preservation of small, semantically relevant objects. SCSA employs τ(λ)-adaptive clustering using cosine similarity of CLIP visual embeddings, coupled with cluster scoring via [CLS]-to-patch attention heads from frozen ViTs. Size-adaptive selection strategies ensure retention of fine-grained tokens for small clusters and summarized tokens for larger regions, tightly governed by λ.
Geometric Stream: Instruction-Guided Structure Recoverer (IGSR)
IGSR focuses on restoring and preserving topology and spatial relationships critical for geometric reasoning. This is achieved through:
- Local-difference anchor extraction, emphasizing high-variation features for geometric saliency.
- Text-aware modulation based on image-text similarity, ensuring alignment with user intent.
- Parallel greedy path tracing for explicit topology completion, recovering spatial continuity otherwise lost in heavy compression regimes.
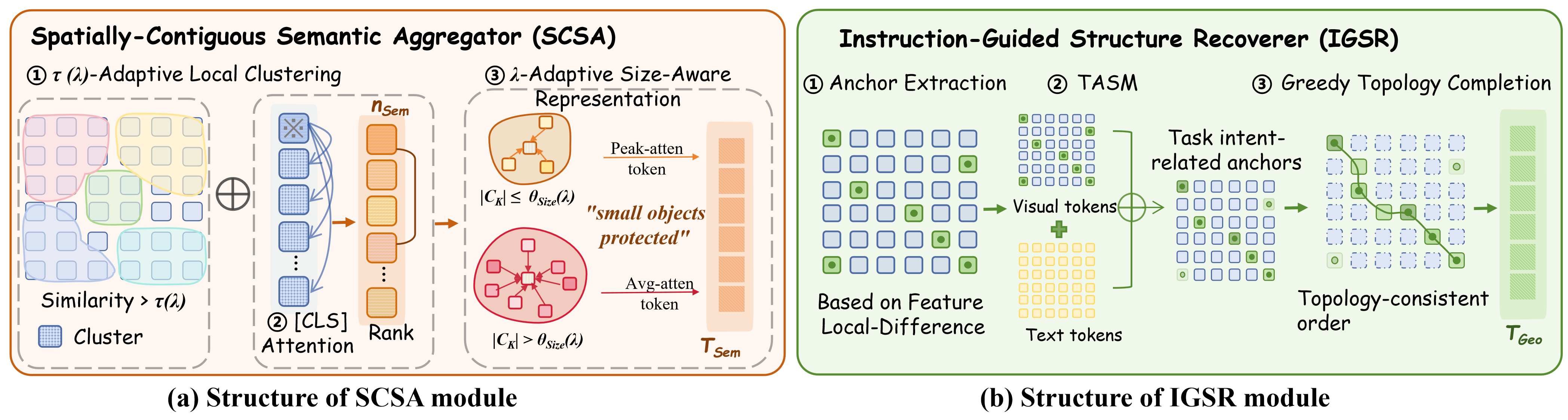
Figure 4: SCSA (a) performs semantic-aware background aggregation; IGSR (b) restores spatial topology via instruction-guided, greedy path tracing.
Dual-Stream Fusion
After separate reductions, semantic and geometric tokens are fused via λ-weighted concatenation, ensuring that task intent is reflected both in token composition and representation magnitude. IGSR ensures connected positional order for the geometric stream, enabling native LLM positional encodings to leverage local connectivity without architectural changes.
Empirical Evaluation
Evaluated on XLRS-Bench, DualComp achieves superior average accuracy (53.10%) compared to both task-agnostic and remote-sensing-specific compression baselines, outperforming GeoLLaVA-8K and all major token-pruning methods under a compression ratio of 42× (reducing average token count from 14k to 6.4k). The most pronounced gains occur in geometry-sensitive tasks (e.g., Route Planning: 66% to 72%, Land Use Classification: 49% to 53%), confirming architectural suitability for topology-dependent reasoning. Semantic tasks also see competitive or improved performance, notably in counting (38% to 45%) and object color identification.
DualComp delivers the best inference throughput (3.87 s/image), effectively halving the TFLOP requirements of the LLM without numerical degradation, a pronounced advantage over approaches like VisionZip and FastV. The ablation analysis substantiates the necessity of both streams: SCSA-only and IGSR-only configurations show tangible degradation, underscoring the importance of dual evidence preservation for broad UHR task coverage.
DualComp's task-adaptive design is further validated by its transfer to general-purpose models such as Qwen2.5-7B, where it maintains or marginally outperforms existing advanced compression techniques at equal or higher compression levels, thus confirming generality and plug-in utility for open vocabulary MLLMs.
Theoretical and Practical Implications
The work establishes that static token reduction paradigms are fundamentally mismatched with the heterogeneous demands of UHR remote sensing, and that procedure-level adaptation guided by instruction-conditioned routing is critical for robust and efficient downstream performance. By decoupling semantic and geometric evidence pathways, DualComp provides a blueprint for structured, dynamic token selection aligned with task intent, eliminating the need for expensive end-to-end retraining.
Practically, DualComp enables real-time or near-real-time inference for high-throughput or latency-sensitive remote sensing applications without sacrificing reasoning fidelity, even at aggressive compression ratios. It opens the path for integration in cloud-based and edge AI deployments where memory and compute are scarce.
Theoretically, the manner in which DualComp formalizes task-conditioned token scheduling generalizes beyond remote sensing: semantic-geometric duality, or analogous decompositions, likely applies in other vision-language domains where both fine-grained categorization and spatial reasoning are concurrent demands.
Conclusion
This work offers a rigorous technical advance for efficient UHR remote sensing understanding with MLLMs, demonstrating that training-free, dual-stream, intent-driven compression can improve both computational economy and reasoning performance. The explicit modeling and preservation of semantic and geometric evidence, along with instruction-informed token allocation, are the cornerstones of DualComp. The framework is modular, generalizes across backbones, and sets a reference architecture for future research in task-adaptive multimodal compression (2604.11122).