- The paper demonstrates that none of the evaluated LLMs reliably match human annotators in security-specific qualitative annotation.
- The paper employs structured prompt engineering with expert codebooks and calculates performance via Cohen's kappa, precision, and recall on 263 texts.
- The paper finds that while prompt refinement yields minor improvements, the models still require human oversight and domain-specific tuning.
Evaluating LLMs for Security-centric Thematic Annotation: Limitations and Insights
Introduction
The paper "LLMs for Qualitative Data Analysis Fail on Security-specific Comments in Human Experiments" (2604.10834) conducts a rigorous empirical assessment of leading LLMs' ability to perform thematic qualitative annotation on security-related human comments. Specifically, the authors target security-specific codes in free-text rationales provided by human subjects participating in vulnerability detection tasks. Their principal aim is to determine whether recent LLMs can reliably substitute human annotators for domain-specific codes such as the presence of code identifiers, references to security, exploit mentions, and expressions of uncertainty.

Figure 1: Sec4AI4Sec, an EU research initiative for developing security-by-design technologies and methodologies for AI-augmented systems.
Problem Specification and Experimental Design
The study is anchored on the realities of security experiment analysis, where thematic annotation is indispensable for extracting actionable themes from open-ended justifications. Human annotation in this context is costly, laborious, and irreducibly subjective. The paper operationalizes the question of LLM replaceability via two research questions:
- RQ1: Can LLMs reliably replace human annotators for security technical annotations?
- RQ2: What is the impact of structured prompt engineering—incorporating codebooks, examples, and conflict clarifications—on LLM annotation quality?
The experiment leverages a dataset of 263 security-centric free-text justifications from human subjects analyzing vulnerable C code. Nine domain-relevant binary codes are annotated by four human experts using an industry-standard protocol (iterative code emergence, codebook consensus, annotation, and joint review).
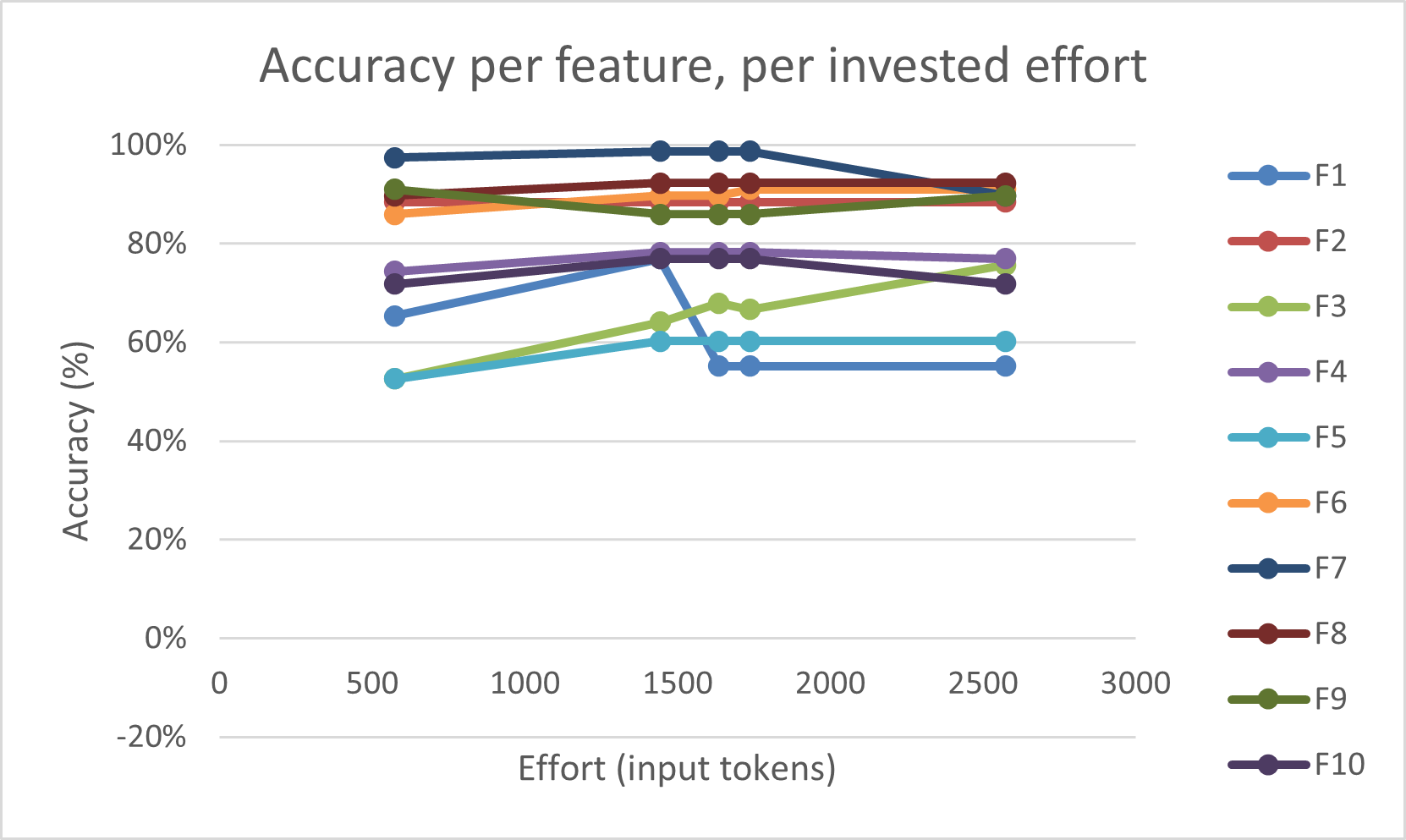
Figure 2: The protocol for annotation by human annotators and injection points for LLMs as stand-in annotators.
Four top-performing LLMs are evaluated: GPT-5, Claude-4 (Sonnet), DeepSeek-V3.2, and Qwen3-Max, each representing distinct (commercial and open-source) architectures, and selected for their LiveBench Reasoning leaderboards and spreadsheet input fidelity.
Methodology: Prompt Engineering and Metrics
Prompt engineering systematically escalates in structure, beginning with mere task descriptions and code names, and culminating with full formal codebooks, positive/negative examples, and clarifications for subtle code distinctions. The latter mirrors best practices in human coding to reduce annotation ambiguity.
Evaluation is standardized using Cohen's kappa (chance-corrected accuracy), precision, recall, and overall accuracy. Kappa thresholds for practical replaceability are adopted—values above 0.6 denote potential substitutability, with 0.4<κ<0.6 indicating only moderate concordance. Statistical significance is adjudicated via Wilcoxon paired tests on a per-code, per-annotator, per-prompt basis.
Empirical Results
Replaceability of LLM Annotators (RQ1)
The core result is negative: none of the evaluated LLMs achieve sufficient agreement with human annotators to be considered reliable stand-ins for security code annotation.
- Aggregate κ scores max out at 0.61 for Qwen3-Max and 0.53 for DeepSeek-V3.2, indicating moderate agreement at best. GPT-5 and Claude-4 perform worse, hovering in the 0.3 range (Table of main results).
- Even when restricting evaluation to comments where human annotators were unanimous (removing codebook ambiguity), LLMs underperform on most codes except those identifying clear non-vulnerability statements.
- Open-source models (DeepSeek-V3.2, Qwen3-Max) outperform proprietary ones (GPT-5, Claude-4) on nearly all codes of interest.
Prominent error modes include semantic conflation of natural language with technical identifiers, over-triggering on security keywords, inability to discriminate subtle uncertainty, and systematic miscoding of ambiguous constructs. For example, models frequently mislabeled all instances of “debug” or “vulnerable” as positives and failed to parse expressions of programmer doubt as true uncertainty codes.
Effect of Prompt Refinement (RQ2)
The addition of codebook definitions and explicit positive/negative examples yielded a one-time significant improvement (mean κ increase from 0.37 to 0.42). Further refinement—adding reviewer conflict clarifications and annotated contrasts—failed to produce significant global improvements, and, in several cases, degraded consistency or caused model confusion, especially for proprietary models.
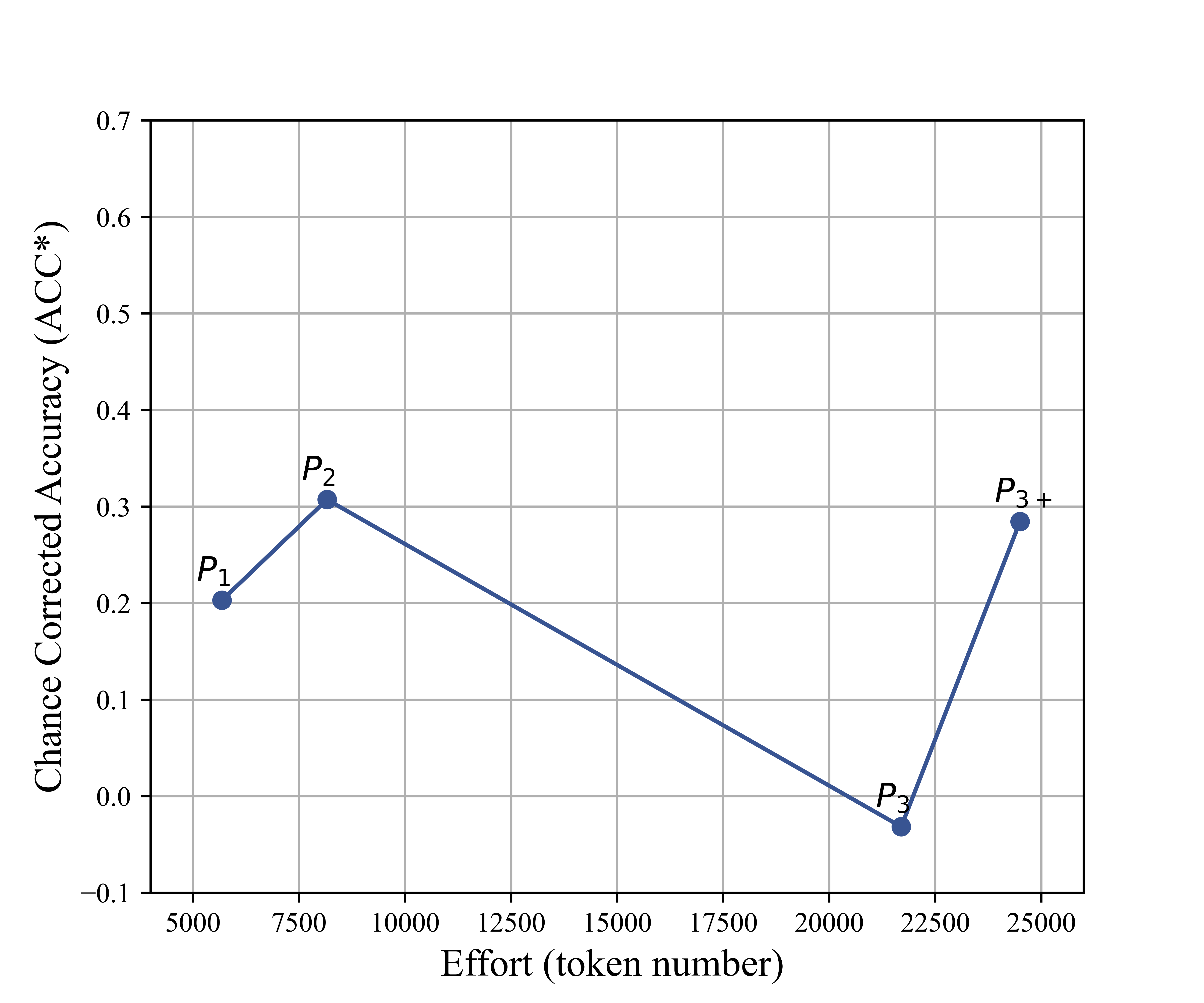
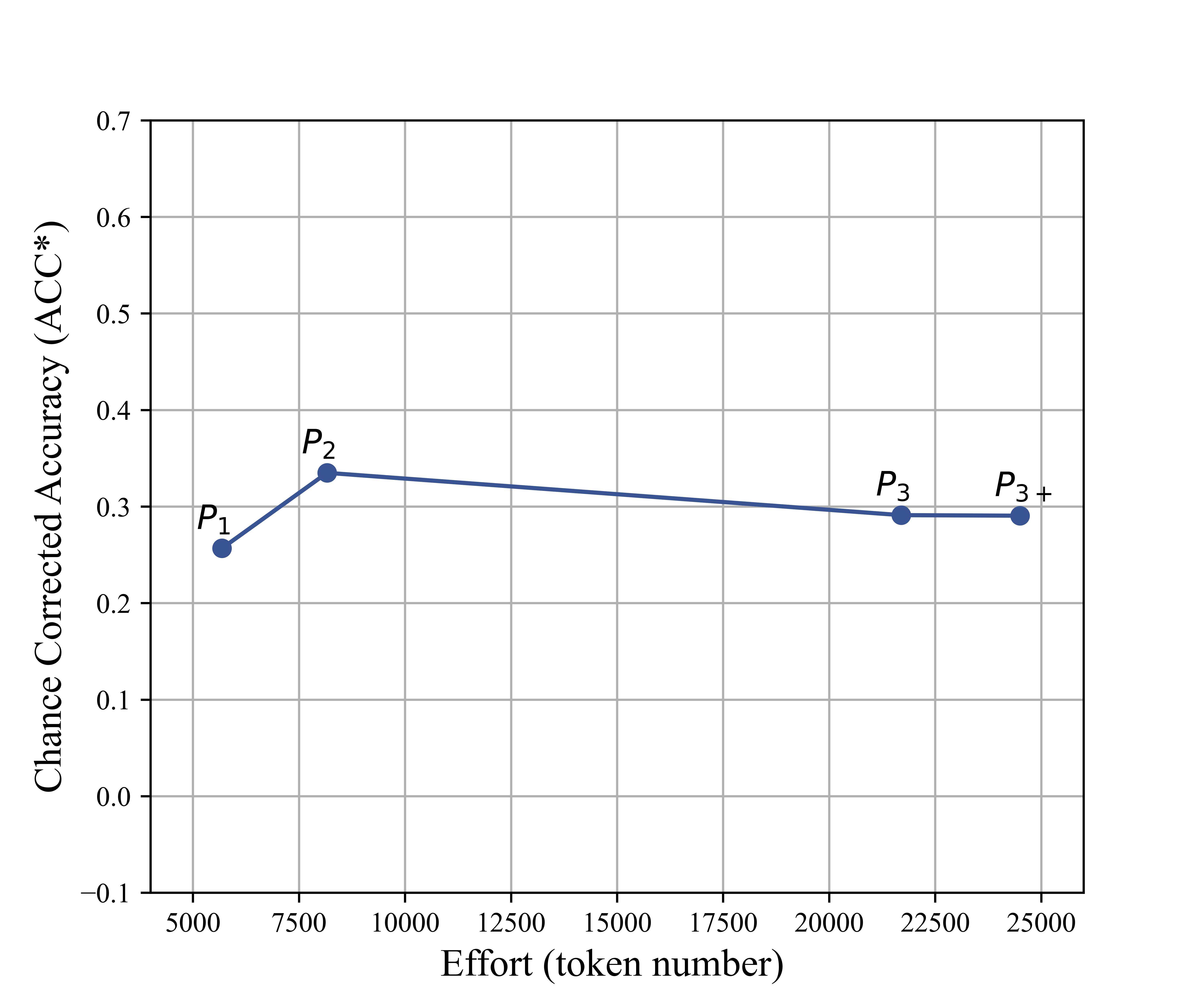
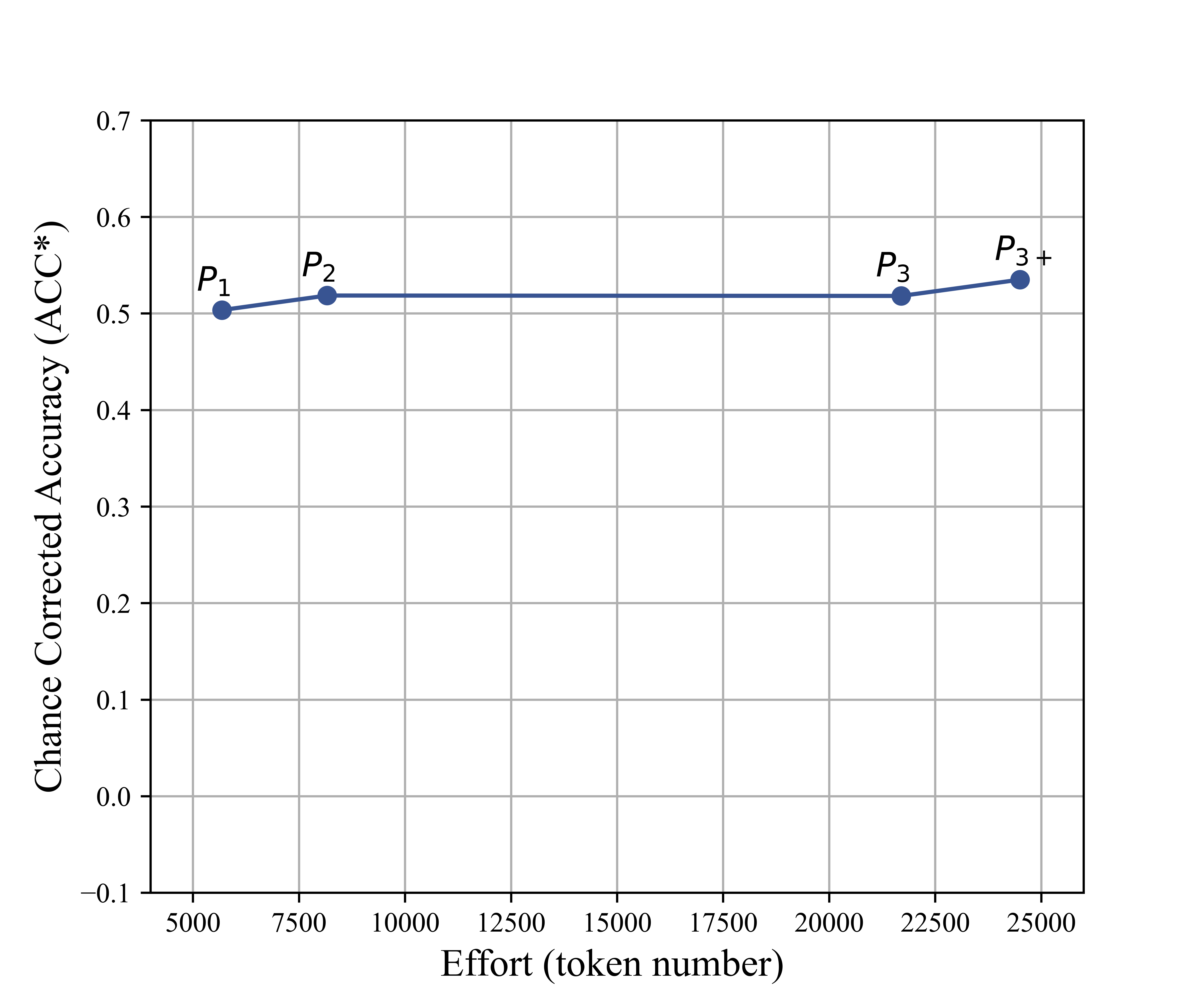
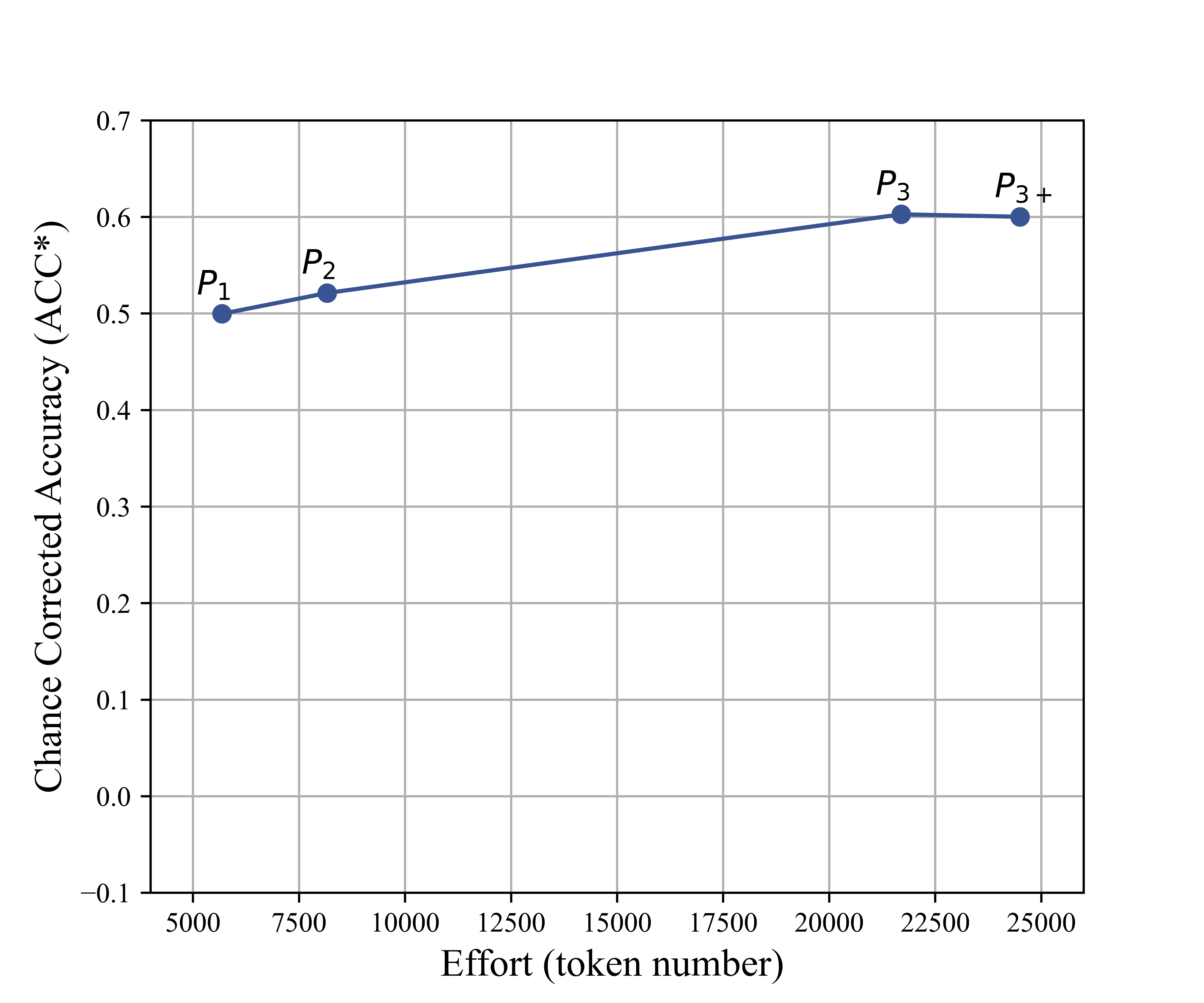
Figure 3: Average Cohen's kappa (chance-corrected accuracy vs. prompt size in tokens), indicating diminishing returns after initial prompt enrichment.
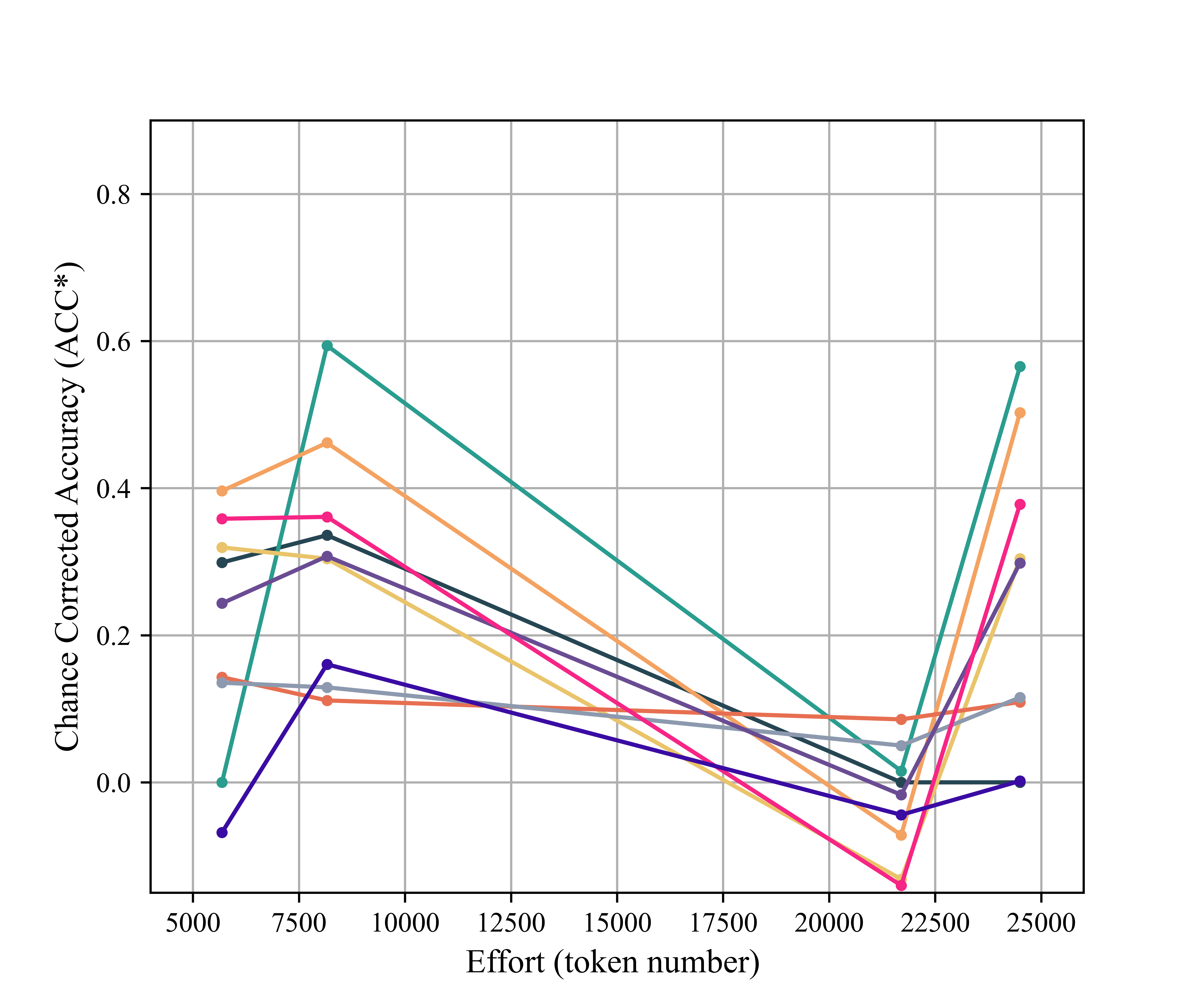
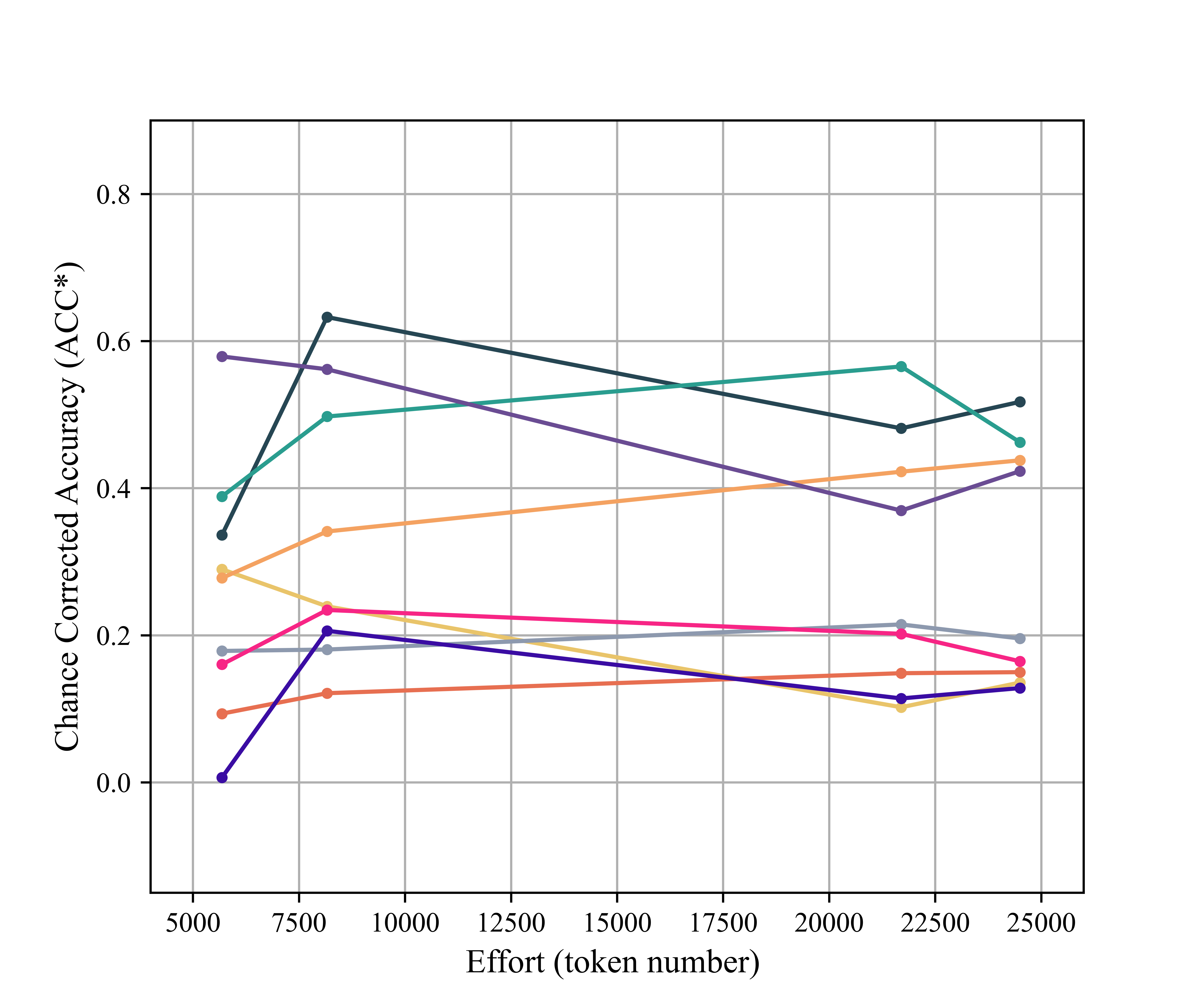
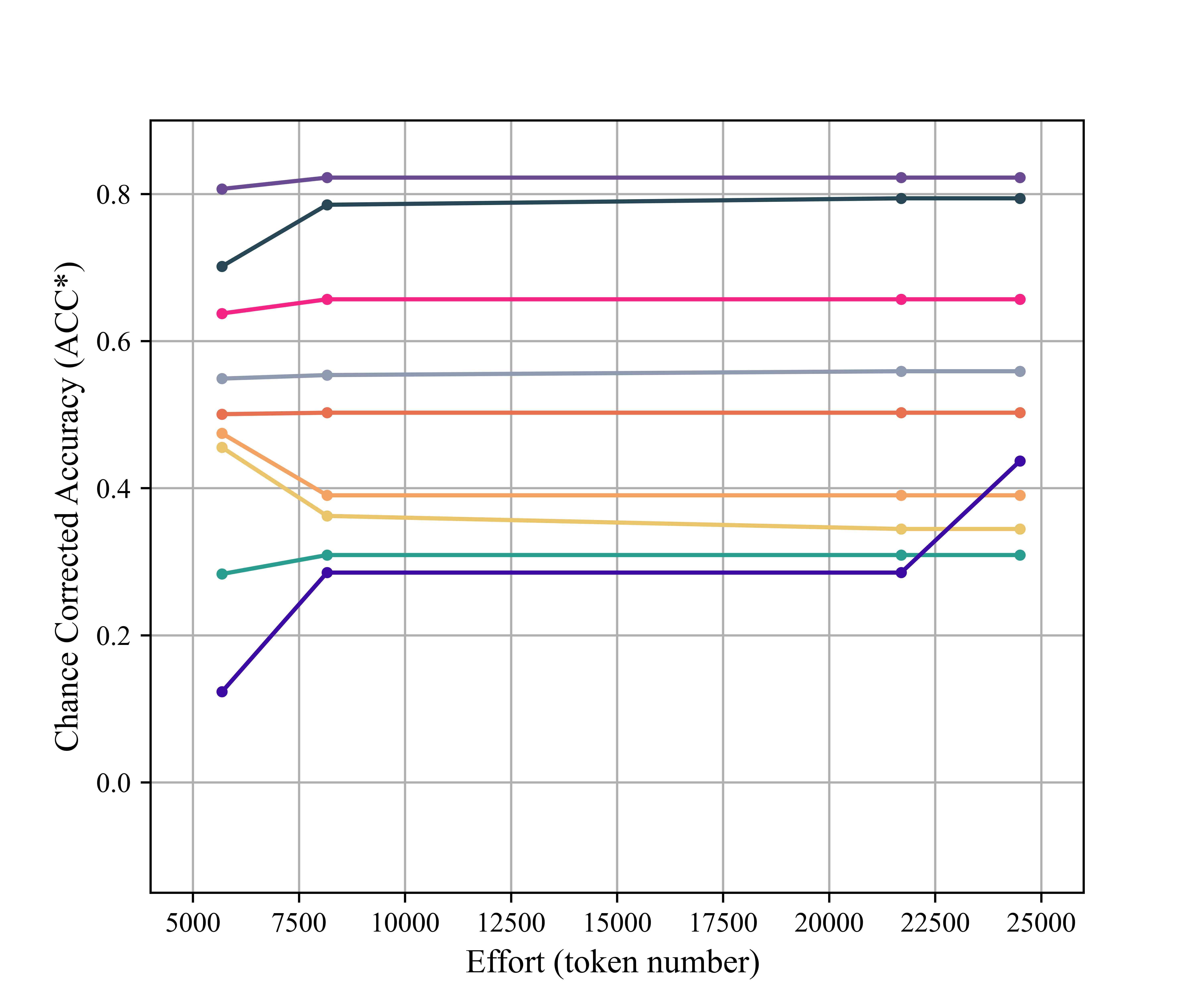
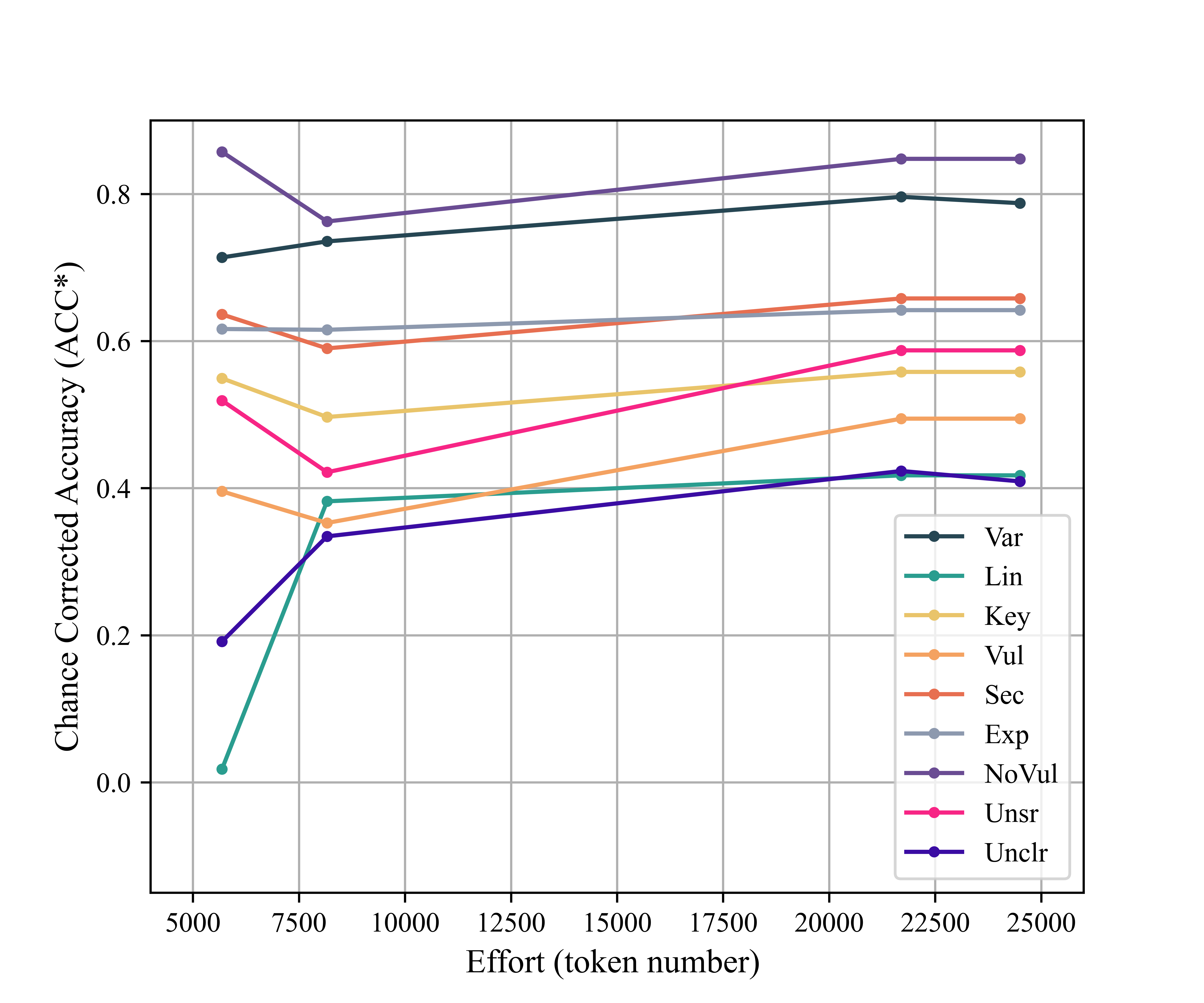
Figure 4: Token-wise effort vs. performance per code, revealing variability in code difficulty and diminishing prompt returns.
Key insight: Increasing prompt length and complexity provides diminishing or negative returns beyond succinct code definitions with canonical examples, contradicting the notion that prompt engineering can alone bridge the semantic gap for high-fidelity domain annotation.
Qualitative Observations
- Many LLMs fail to produce tabular outputs reliably, with some returning malformed or misaligned spreadsheets, impeding systematic analysis.
- Open-source models are superior at processing large tabular inputs and maintaining structural output integrity.
- LLMs are prone to classification artifacts: “hallucinating” feature presence, being misdirected by common domain terms, and showing unreliable handling of uncertainty or negation cues.
Prior investigations have demonstrated some success of LLMs in thematic and qualitative text analysis in general discourse and less-technical domains [dai2023llm, li2024comparing]. The present findings robustly qualify those results for security-centric and technical experimentation: performance achieved in general sentiment, opinion, or healthcare annotation does not generalize to the subtle contextual distinctions central to security code rationale.
Whereas LLMs like GPT-4 exhibit moderate concordance on deductive coding in psychological or educational analysis, their efficacy sharply drops in security experiments with ambiguous or implicitly-coded rationales (e.g., distinguishing absence of evidence from evidence of absence, or discerning precise variable references from context).
Implications and Future Directions
The practical implication is clear: current LLMs are unsuitable as autonomous human annotator replacements for security-specific qualitative annotation in empirical SE research. They may serve an assistive role, e.g., for initial suggestion or low-complexity binary tagging, but mandate rigorous human review and correction for codes that require interpretive judgment, domain grounding, or contextual nuance.
Theoretical implications include the inadequacy of in-context learning and prompt engineering to “close the gap” for technical domain annotation tasks and the necessity for fine-tuned, domain-specific LLMs (possibly using contrastive security annotation corpora) if reliable automation is to be realized. This also points to the open research challenge of building LLMs that encode not only surface linguistic features but also software engineering logic, code context, and human annotator heuristics.
Future work should explore hybrid human-in-the-loop pipelines, data-efficient model fine-tuning, and tailored model architectures for code-comment reasoning. Benchmark datasets with richer security annotation tasks—including more annotators, broader vulnerability types, and real-world developer populations—are essential for progress.
Conclusion
The paper establishes that, at present, advanced LLMs—even those optimized for reasoning and with state-of-the-art scores on challenging general benchmarks—demonstrate only limited, code- and context-dependent success on security-relevant thematic annotation in program comprehension tasks. The gap between model and human performance is not easily bridged by prompt engineering alone, and the social and methodological risks of over-reliance are substantial. For robust security experimentation, rigorous human annotation remains indispensable; LLMs, while promising collaborators, must be subject to critical evaluation and not delegated ground-truth establishment in technically demanding contexts.
References
For relevant related work on LLMs in qualitative analysis and thematic annotation, see [dai2023llm], [li2024comparing], [xiao2023supporting], [rasheed2024can] and the empirical protocol for security comment annotation in [papotti2025effects].