- The paper introduces a novel five-stage pipeline that aligns textual, visual, and spatial cues for zero-shot video-based 3D reconstruction.
- Its methodology leverages progressive object discovery, optimal-view asset generation, and iterative refinement to achieve high geometric fidelity and semantic coherence.
- Experimental results on the C3DR benchmark demonstrate superior object recall, F1 scores, and visual quality metrics compared to state-of-the-art baselines.
ReplicateAnyScene: Zero-Shot Video-to-3D Composition via Textual-Visual-Spatial Alignment
Introduction and Motivation
ReplicateAnyScene introduces a fully automated, zero-shot compositional 3D reconstruction framework that operates directly on casually captured videos. Distinct from traditional holistic scene modeling (e.g., NeRF, 3DGS), compositional 3D reconstruction explicitly segments objects and reconstructs their geometry and semantic layout, enabling manipulation, interaction, and efficient scene understanding crucial for Embodied AI and spatial intelligence. Existing approaches exhibit brittle dependence on manual intervention, auxiliary annotations, and overly simplistic environments due to cross-modal misalignment and limited exploitation of Vision Foundation Models (VFMs). ReplicateAnyScene addresses these challenges by systematically aligning textual, visual, and spatial priors from VFMs via a five-stage pipeline, yielding structured, semantically coherent, and physically plausible 3D scenes.

Figure 1: The ReplicateAnyScene framework enables fully automatic, zero-shot compositional 3D reconstruction from videos, aligning cross-modal priors into coherent 3D scenes.
Methodology
Pipeline Overview
The framework is structured as a five-stage cascade, with each stage targeting specific modality alignment: (1) Progressive Object Discovery, (2) Spatial-Guided Visual Deduplication, (3) Optimal-View 3D Asset Generation, (4) Iterative Visual-Spatial Alignment, and (5) Semantic-Aware Scene Refinement.
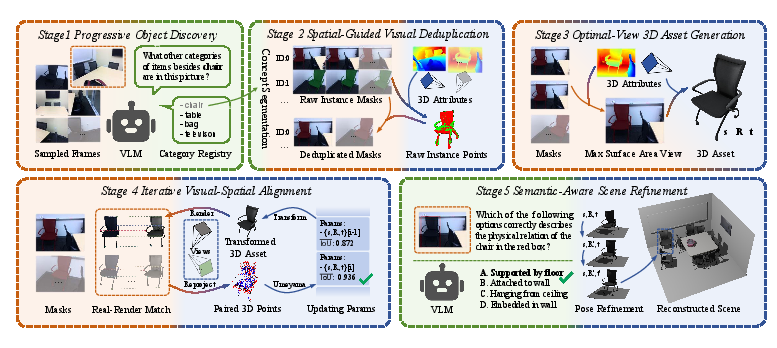
Figure 2: The five-stage pipeline, each resolving targeted alignment gaps for textual (green), visual (orange), and spatial (blue) modalities, progressively integrates multimodal priors into a cohesive 3D scene.
Progressive Object Discovery
A VLM is progressively queried on select frames (via a space-aware frame sampling strategy), dynamically updating a non-redundant open-vocabulary object list. This prevents omission and mitigates synonym-induced redundancy, resulting in high coverage with minimal semantic overlap.
Spatial-Guided Visual Deduplication
To address identity fragmentation in 2D mask tracking (due to occlusion and re-entry), 2D masks are lifted into 3D space using depth and pose from VGGT. A geometric overlap criterion is used to cluster fragmented tracks via Union-Find, enforcing one-to-one correspondence between physical objects and instance identities.
Optimal-View 3D Asset Generation
Given multi-view observations, the method computes the optimal view for each object by maximizing the recovered 3D surface area, rather than simply using the largest visible pixel area, effectively informing SAM3D-based mesh generation for superior geometric fidelity.
Iterative Visual-Spatial Alignment
SAM3D's initial object placement is iteratively refined via a render-match-optimize loop. Unlike conventional ICP, which is geometry-only and initialization-dependent, this method leverages dense, perceptually-matched correspondences (using MASt3R) between rendered assets and real views, aggregating multi-view constraints and optimizing similarity transforms robustly.
Semantic-Aware Scene Refinement
To correct physically implausible results (e.g., floating, collisions), the VLM infers high-level relationships (e.g., "supported by") and semantic priors drive deterministic geometric refinements. This addresses artifacts in spatial layout unresolvable by visual matching alone.
C3DR Benchmark
To address the absence of a holistic evaluation protocol, the work introduces the Compositional 3D Reconstruction Benchmark (C3DR). C3DR consists of 50 richly annotated, complex indoor scenes (text, geometry, spatial), curated from multiple real and synthetic sources. Objects are reconstructed and placed by professional modelers for ground truth, supporting comprehensive evaluation of semantic, visual, and spatial quality.
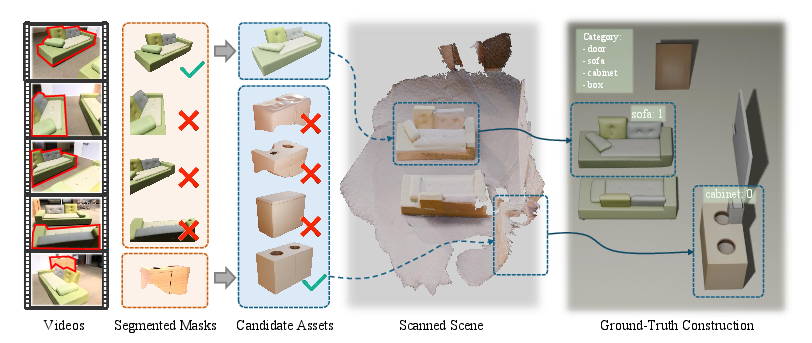
Figure 3: C3DR benchmark construction pipeline: semantic labeling, multi-view asset generation, and manual alignment yield physically accurate, richly annotated ground-truth scenes.
Experimental Results
Quantitative and Qualitative Evaluation
Extensive experiments on C3DR demonstrate superior performance in all metrics over MetaScenes and SimRecon baselines. ReplicateAnyScene yields higher object recall and F1, better visual PSNR/SSIM/LPIPS/MUSIQ, and stronger geometric fidelity (lower Chamfer Distance, higher F-Score and Normal Consistency).

Figure 4: Qualitative results on C3DR, comparing ReplicateAnyScene (right) to MetaScenes and SimRecon. ReplicateAnyScene achieves higher fidelity and semantic alignment.
Ablation Studies
Ablations reveal each pipeline stage is essential. Deduplication eliminates redundant instances; optimal-view selection resolves visibility artifacts; iterative visual-spatial alignment corrects scale/pose errors; semantic-aware refinement ensures physical plausibility. Configurations lacking any of these steps show notable degradation, both visually and quantitatively.
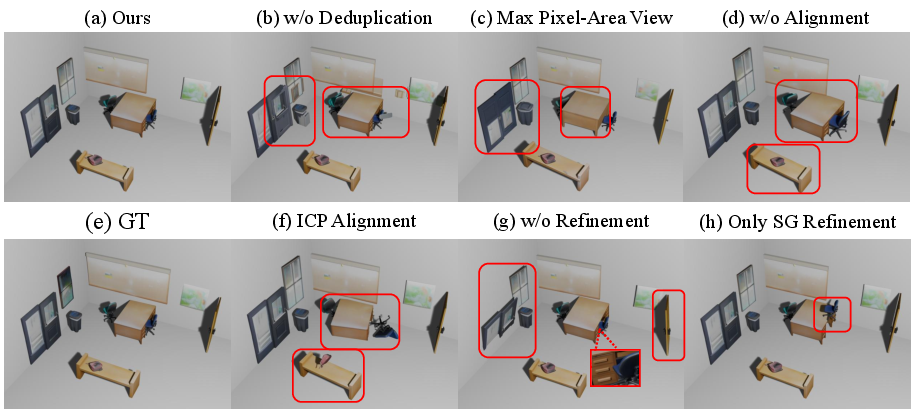
Figure 5: Qualitative ablations on stages 2–5: ablation of any stage yields characteristic artifacts (duplicates, misalignments, incomplete geometry); the full pipeline achieves the best result.
Discussion and Implications
The methodology's core strength lies in systematic, cross-modal alignment. By not naively assembling VFMs but introducing explicit, structured integration of textual, visual, and spatial cues, information fragmentation (e.g., identity mismatch, scale ambiguity, disjoint layouts) is robustly resolved. This enables reliable, zero-shot compositional reconstruction from casual input videos, a requirement for scalable, real-world applications (e.g., scene editing, embodied agents, simulation, and robotics). Furthermore, the introduction of a multimodal benchmark addresses evaluation gaps in the field.
However, the method is presently limited to indoor environments. Scene composition involving highly irregular, organic, or unbounded outdoor elements remains unsolved due to challenges in natural object synthesis and environmental alignment. Future work will focus on scaling for natural environments, harnessing the pipeline for large-scale interactive dataset generation, and enabling advanced downstream tasks in Embodied AI.
Conclusion
ReplicateAnyScene establishes a new paradigm for zero-shot, fully automated compositional 3D scene reconstruction from video. The five-stage pipeline demonstrates strong alignment of multimodal foundation models, unprecedented automation without human intervention, and robust performance across semantic, visual, and geometric metrics as measured by a novel, comprehensive benchmark. This work highlights the necessity of strategically aligning cross-modal priors in large vision and LLMs to advance toward embodied spatial intelligence and autonomous scene understanding (2604.10789).

