- The paper introduces FACT-E as a causality-inspired framework that uses structural causal models to assess both chain-of-thought fidelity and answer consistency.
- It employs contrastive comparisons with perturbed reasoning chains to isolate genuine logical dependencies and mitigate inherent self-assessment biases.
- Empirical evaluations on benchmarks like GSM8K and MATH-500 show FACT-E reliably improves reasoning accuracy while effectively filtering noisy exemplars.
FACT-E: Causality-Inspired Evaluation for Trustworthy Chain-of-Thought Reasoning
Motivation and Problem Setting
Chain-of-Thought (CoT) prompting has substantially advanced LLM reasoning by eliciting explicit intermediate rationales. However, a persistent challenge is that LLMs generate stepwise reasoning chains that, while fluent, often harbor intra-chain logical failures or unnecessary steps that do not support subsequent inference. Conventional self-assessment methods, which typically apply the LLM as a judge (e.g., self-reflect), are susceptible to internal biases, including self-affirmation and reliance on statistical shortcuts, leading to unreliable faithfulness evaluations. These methods tend to favor coherence and final-answer correctness without robust scrutiny of intermediate logical dependencies.
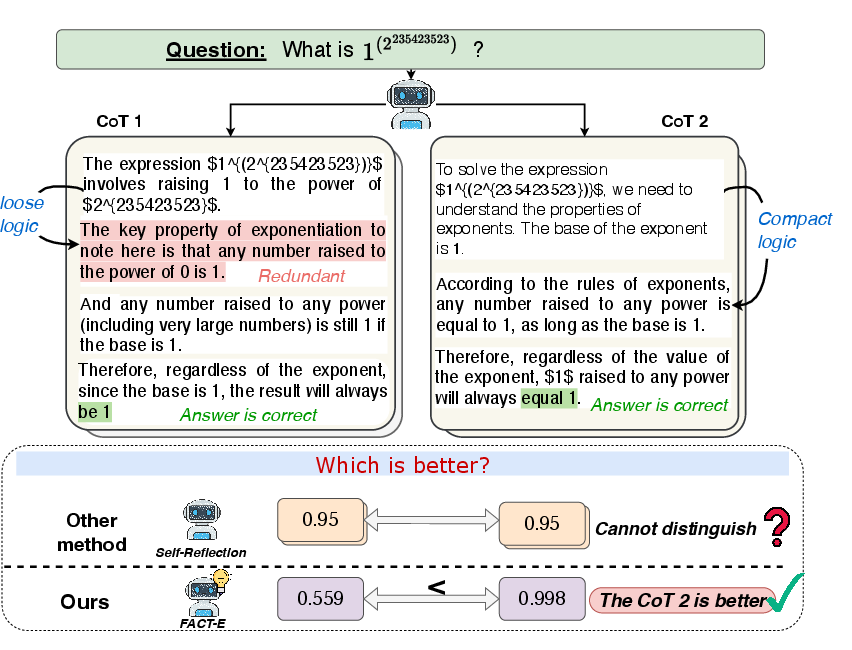
Figure 1: Illustration of LLM self-assessment limitations: Conventional methods assign similarly high scores to both reasoning chains, missing logical breakdowns, whereas FACT-E accurately identifies the faithful chain.
Methodology: Causal Framework for CoT Evaluation
The FACT-E (Faithfulness and Consistency Tandem Estimation) framework proposes a causality-driven approach to CoT quality estimation. The process leverages Structural Causal Models (SCMs) to disentangle genuine step-to-step dependency from artifacts induced by LLM biases. Specifically:
CoT-to-Answer Consistency
CoT-to-Answer Consistency quantifies whether a reasoning chain leads to the correct outcome, modeled as the causal path Q→S→A, with S mediating the effect of Q on final answer A. The consistency score is computed via multiple LLM judgment samples, reflecting the probability that S is sufficient for A.
Intra-Chain Faithfulness
Intra-Chain Faithfulness measures causal integrity between successive CoT segments, partitioning a chain at all intermediate steps and evaluating whether each prefix logically supports its suffix. Conventional LLM self-assessment is confounded by the LLM’s internal bias Z, as formalized in the causal graph.
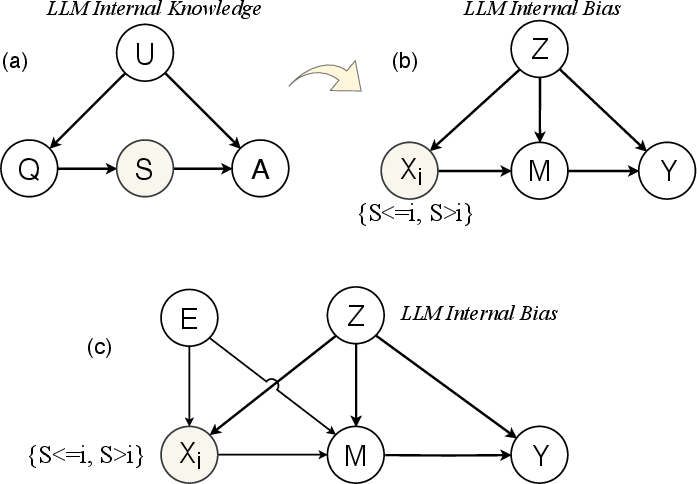
Figure 2: Structural causal graphs for CoT quality estimation. (a) The mediated reasoning pathway; (b) self-assessment with confounding bias; (c) FACT-E introduces instrumental noise to mitigate bias.
To overcome these confounding effects, FACT-E introduces external perturbations (noise) as an instrumental variable to create counterfactual continuations for each split. By contrastively comparing model preference for original versus perturbed chains (i.e., measuring the Average Causal Effect), the method isolates the genuine logical dependency. This contrastive design ensures stylistic parity and eliminates shortcut reliance, as both chains are self-generated and differ only in the injected logical corruption.
Algorithmic Implementation
FACT-E operates in two modes: standard (all steps checked) and lightweight (random checkpoints), striking a balance between computational overhead and evaluation granularity. For each CoT candidate, FACT-E first computes answer consistency; candidates with zero score are discarded. For remaining candidates, intra-chain faithfulness is measured at multiple split points via contrastive comparisons with counterfactual, perturbed continuations. The final reliability score RS=FS×CS integrates both dimensions—only reasoning chains exhibiting both faithful intermediate dependencies and outcome-supporting logic are selected as trustworthy.
Empirical Evaluation
FACT-E is evaluated across GSM8K, MATH-500, and CommonsenseQA, as well as noisy-rationale benchmarks including NoRa-Math and NoRa-Commonsense. Experimental setup assesses three aspects: answer accuracy improvement by selection, in-context learning (ICL) with curated exemplars, and noise detection under adversarial conditions.
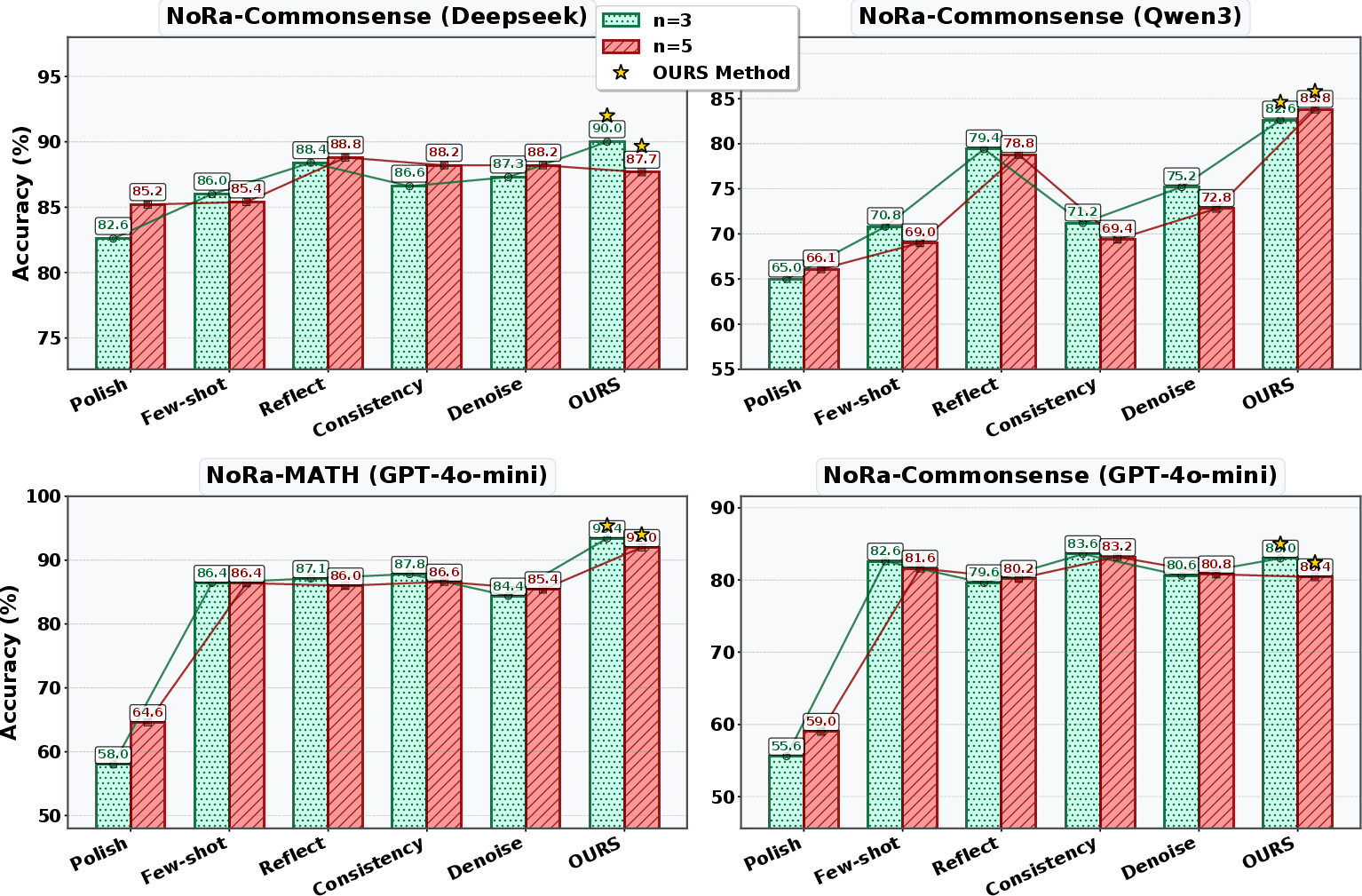
Figure 3: FACT-E robustness on noisy-rationale benchmarks: Top accuracy across varying numbers of noisy demonstrations in context.
Empirical results demonstrate that FACT-E, both standard and lightweight, consistently outperforms all baselines—self-reflection (Reflect), iterative refinement (Polish), self-denoising (Denoise), and self-consistency (Consistency)—for all LLM backbones and benchmarks. Notably, FACT-E yields up to 5.34% absolute gains on MATH-500 (ChatGPT) and exhibits high stability across models, suggesting insensitivity to backbone scale and architecture. The method also reliably identifies and filters noisy exemplars, preserving performance even with substantial rationale corruption.
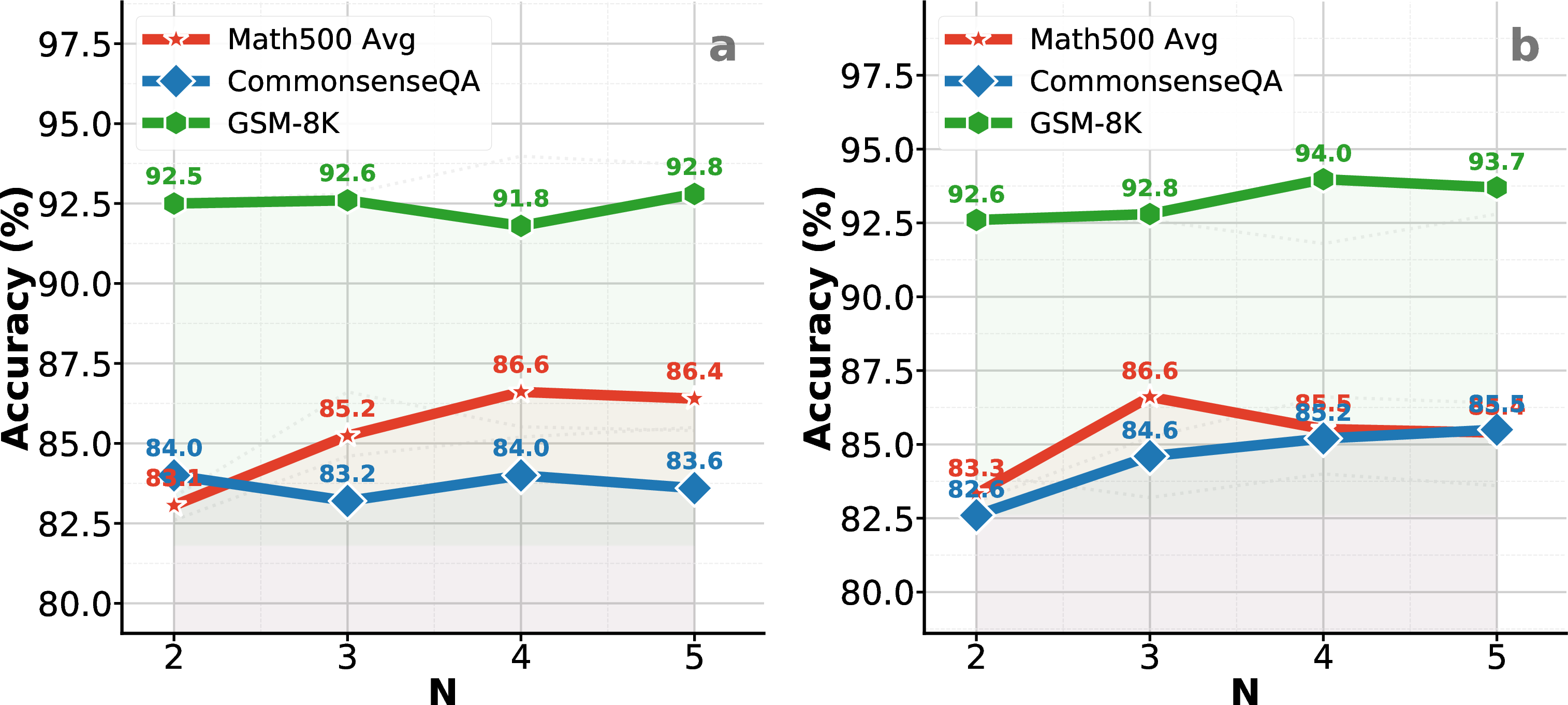
Figure 4: FACT-E performance as function of sampling trials (N); accuracy saturates after three iterations, indicating efficient convergence.
Case studies further substantiate FACT-E’s discriminative power: flawed reasoning chains (e.g., incorrect trigonometric application) receive low scores even when superficially fluent, while rigorous chains are identified and scored near 1.0, demonstrating granularity beyond mere answer correctness.
Ablation and Scalability Analysis
Ablative analysis confirms that joint use of intra-chain faithfulness and answer consistency is essential; individually, each dimension is insufficient for reliable selection. The lightweight variant maintains competitive performance with significantly lower inference requests, scaling linearly in N checkpoints rather than chain length.
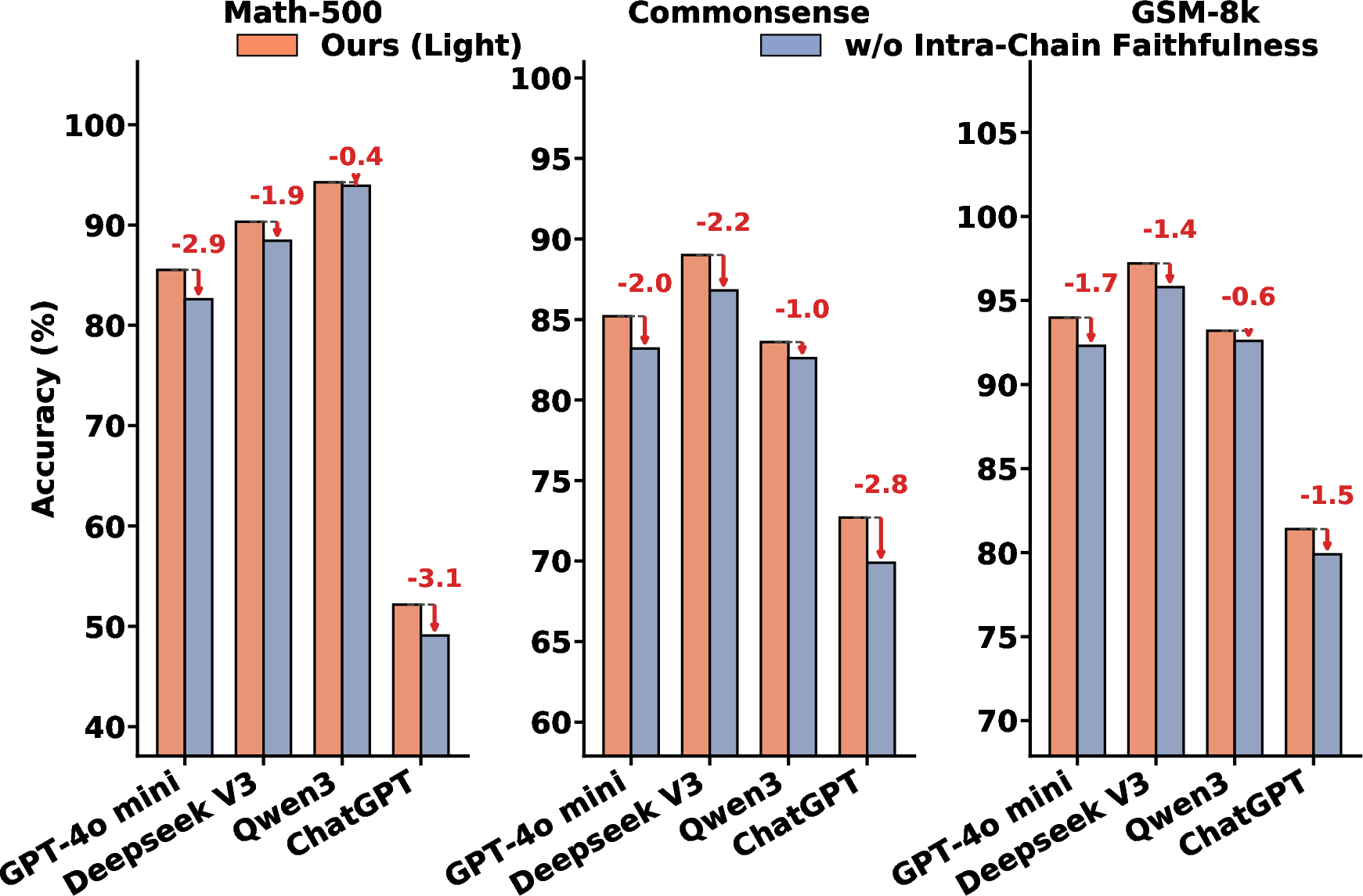
Figure 5: Ablation study reinforces necessity of both faithfulness and consistency modules in FACT-E.
Analysis across difficulty levels in MATH-500 reveals that FACT-E is robust against "performance cliffs," sustaining accuracy as logical complexity increases, unlike baseline methods that degrade sharply.
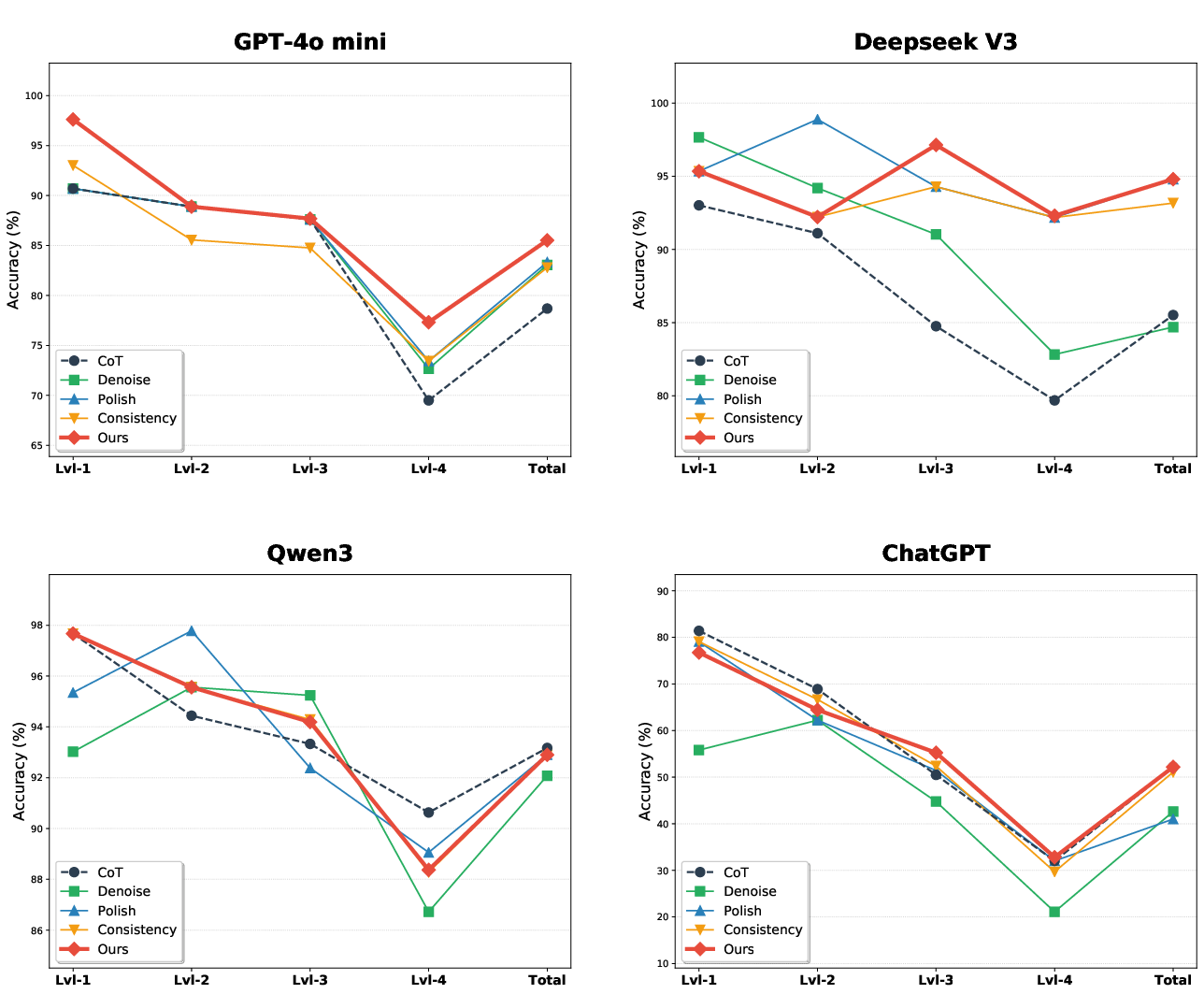
Figure 6: Robust accuracy decay across levels of MATH-500 for FACT-E compared to baselines.
Practical and Theoretical Implications
- Bias-mitigation: FACT-E rigorously addresses self-affirmation and shortcut bias via explicit causal intervention, circumventing the closed-loop pitfalls of black-box self-assessment.
- Granular Quality Control: The framework enables fine-grained evaluation of reasoning traces, crucial for high-stakes applications where explanation reliability is paramount (e.g., mathematical and scientific domains).
- Enhanced Prompt Curation: FACT-E-selected exemplars demonstrably improve in-context learning, supporting scalable transfer to new queries and enhancing few-shot performance.
- Noise Robustness: FACT-E's stress-test approach provides principled denoising for prompting, useful in scenarios with uncertain, adversarial, or mixed-quality exemplars.
Future Directions
Future work may extend FACT-E to compositional reasoning contexts (e.g., Graph-of-Thought, multi-turn debates [Besta_Blach_Kubicek_Gerstenberger_Podstawski_Gianinazzi_Gajda_Lehmann_Niewiadomski_Nyczyk_Hoefler_2024]), integrate cross-model verification for inter-model bias isolation [xiong-etal-2023-examining], and optimize perturbation design for higher-order causal relations. Scalable variants can be explored for integrating FACT-E into real-time LLM reasoning pipelines.
Conclusion
FACT-E provides a principled framework for trustworthy CoT evaluation by unifying causal faithfulness assessment with outcome consistency. By systematically injecting controlled perturbations and quantifying the causal effect, FACT-E achieves fine-grained, bias-resilient selection of reasoning chains suitable for downstream use. The approach is shown to be robust, scalable, and effective across diverse models and reasoning tasks, establishing a new standard for CoT quality control in LLMs (2604.10693).

