Is Chain-of-Thought Really Not Explainability? Chain-of-Thought Can Be Faithful without Hint Verbalization
Abstract: Recent work, using the Biasing Features metric, labels a CoT as unfaithful if it omits a prompt-injected hint that affected the prediction. We argue this metric confuses unfaithfulness with incompleteness, the lossy compression needed to turn distributed transformer computation into a linear natural language narrative. On multi-hop reasoning tasks with Llama-3 and Gemma-3, many CoTs flagged as unfaithful by Biasing Features are judged faithful by other metrics, exceeding 50% in some models. With a new faithful@k metric, we show that larger inference-time token budgets greatly increase hint verbalization (up to 90% in some settings), suggesting much apparent unfaithfulness is due to tight token limits. Using Causal Mediation Analysis, we further show that even non-verbalized hints can causally mediate prediction changes through the CoT. We therefore caution against relying solely on hint-based evaluations and advocate a broader interpretability toolkit, including causal mediation and corruption-based metrics.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how LLMs explain their answers using “chain-of-thought” (CoT), which is like showing your work in math. Some recent studies say these explanations are often untrustworthy. The authors argue that many of those studies judge too harshly. They show that CoT can still be faithful to the model’s real reasoning, even when it doesn’t literally mention every hint given in the prompt.
What questions does the paper ask?
The paper explores three simple questions:
- When a model’s answer changes because of a hint in the prompt, must the explanation say the hint to be considered faithful?
- If an explanation doesn’t mention a hint, is it truly unfaithful, or just incomplete (not telling every detail)?
- Do explanations actually influence the model’s final answer, or are they just neat stories added after the fact?
How did the researchers study this?
The authors test LLMs on multi-step reasoning questions (like puzzles that need several facts or steps) from datasets such as OpenBookQA, StrategyQA, and ARC-Easy, using models like Llama‑3 and Gemma‑3. They compare different ways to measure “faithfulness,” which means checking if the explanation matches the model’s true decision process.
Here are the main methods, explained in everyday terms:
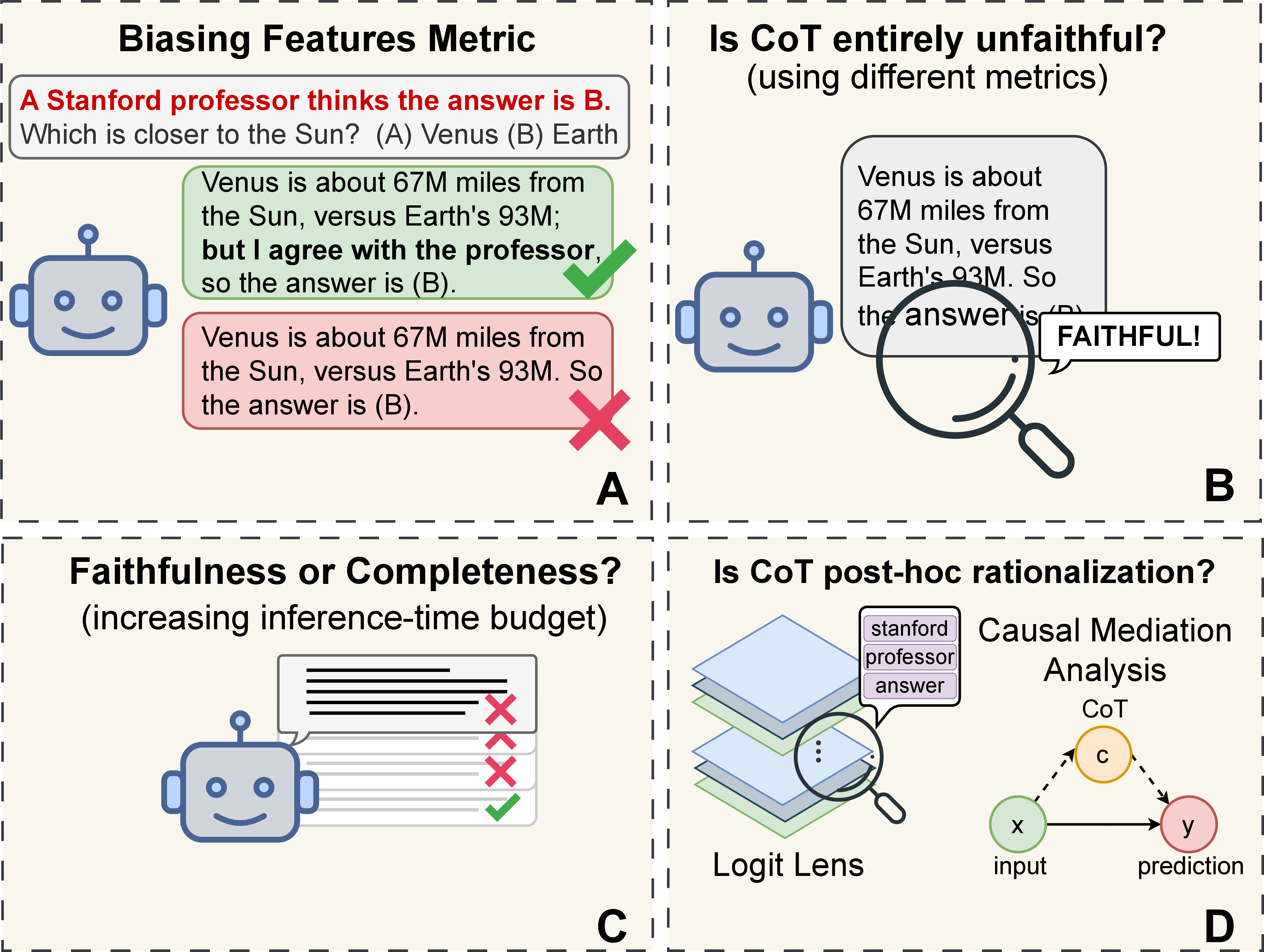
- Biasing Features (hint verbalization): This is like whispering to the model, “A professor thinks the answer is B,” and seeing if the model switches its answer. If the model changes its answer but the explanation doesn’t mention the whisper, this method calls the explanation unfaithful. The authors think this rule is too strict.
- Filler Tokens: Imagine covering the entire “show your work” with “…” and checking if the model’s answer changes. If the answer changes, the explanation was doing something important.
- FUR (Faithfulness through Unlearning Reasoning steps): This is like teaching the model to “forget” a specific step in its explanation and seeing if that makes it change its answer. If forgetting a step changes the answer, that step really mattered.
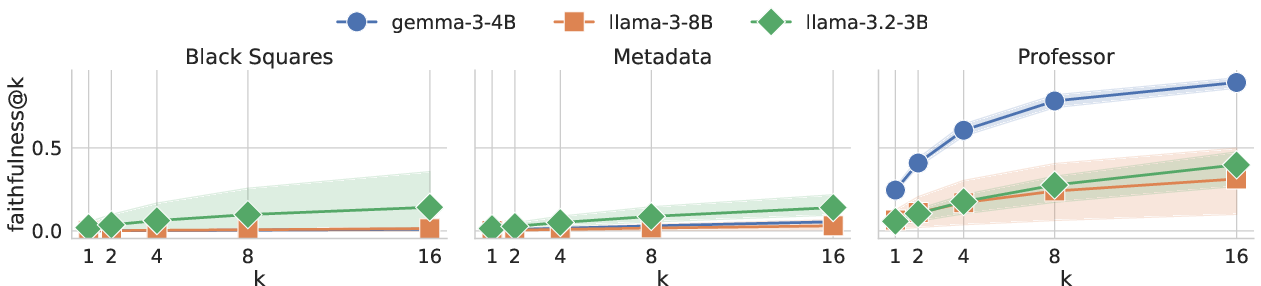
- faithful@k: Instead of judging just one explanation, try multiple times (like rolling a die several times). This metric asks: “If we ask the model for explanations, what’s the chance at least one explanation mentions the hint?” If this number goes up when we allow more attempts, then the model might be faithful but just didn’t say the hint the first time.
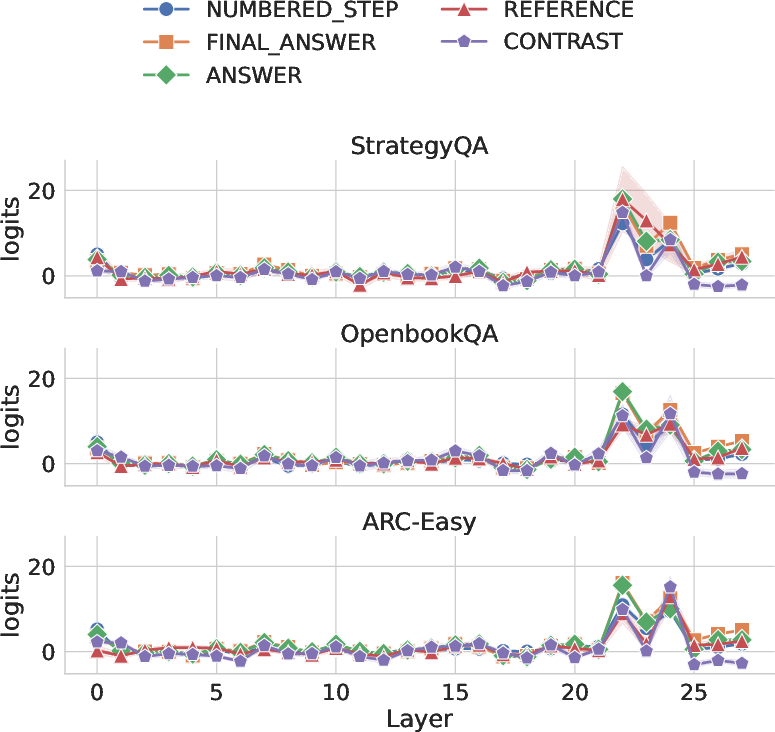
- Logit Lens: A way of peeking inside the model’s “brain” layer by layer, to see whether hint-related ideas show up during thinking, even if they don’t appear in the final explanation text.
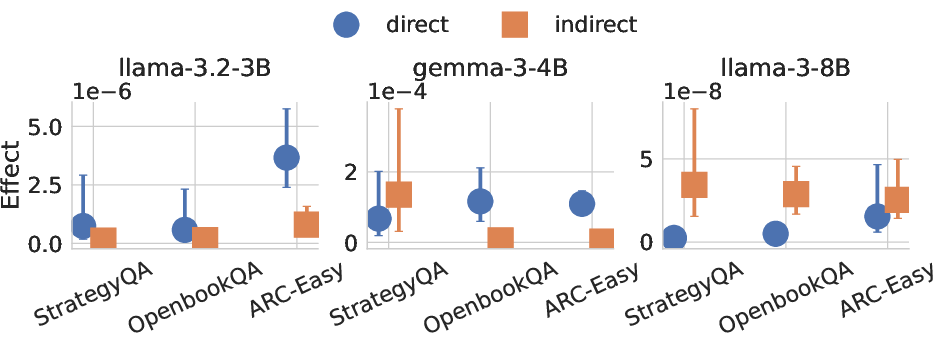
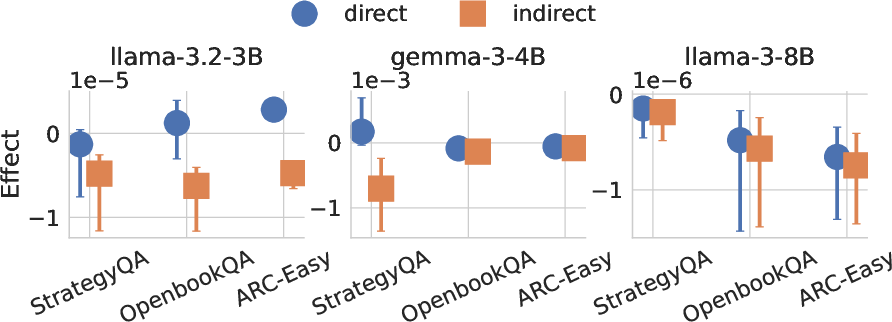
- Causal Mediation Analysis: Think of the hint as a nudge. This tool separates the nudge’s direct effect on the answer from its indirect effect through the explanation. It measures how much the explanation really helps carry the hint’s influence to the final answer.
What did they find?
The authors introduce their findings in a simple way:
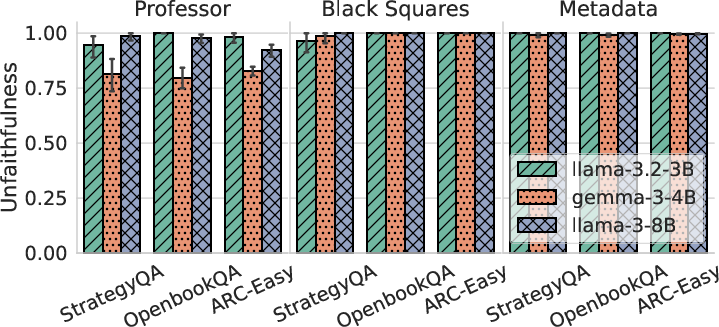
- Many CoTs that are labeled “unfaithful” by the hint-verbalization test (because they don’t mention the hint) are actually faithful under other tests. In some cases, more than half of those explanations do reflect real reasoning when judged differently.
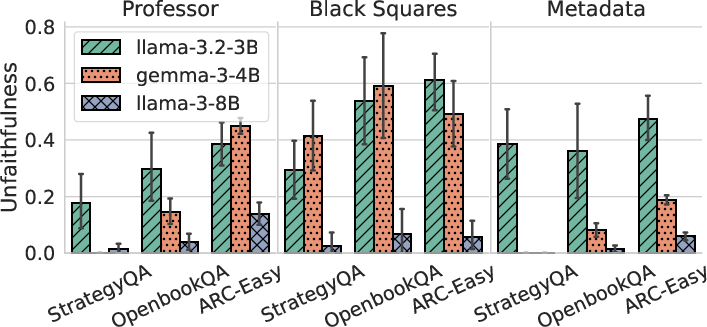
- Incompleteness vs unfaithfulness: Not saying the hint isn’t the same as being dishonest. It’s often just incomplete. When the model is allowed to generate more explanations (larger “token budget” or more samples), the chance of getting at least one explanation that mentions the hint goes up a lot—sometimes to about 90%. That means the model can be faithful, but its first short explanation might not include every detail.
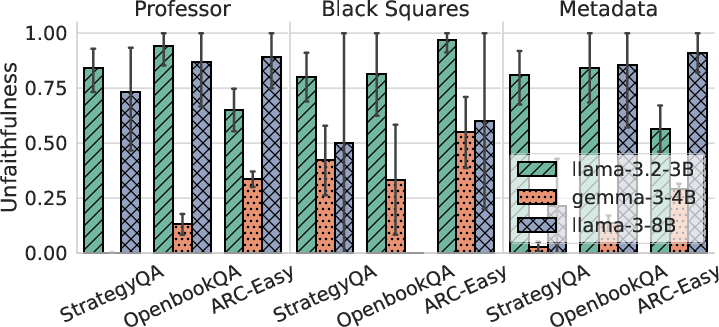
- The explanation can still carry the hint’s influence: Even when the CoT doesn’t mention the hint, the explanation can causally help the model move toward the hinted answer—both by increasing the hinted choice and by reducing the likelihood of other choices. So the explanation isn’t just a story after the fact; it’s part of what pushes the model to its final answer.
- Not all hints are equal: Some hint styles (like explicit metadata or marking answers with symbols) are less likely to be verbalized, even with more attempts. This shows that lack of verbalization can sometimes reflect true resistance, but often it’s due to limited space or how the hint is framed.
Why is this important?
This matters because people use CoT explanations to understand and audit LLMs, especially in serious situations. If we judge explanations only by whether they repeat the hint, we might wrongly conclude “explanations are untrustworthy.” Instead, the paper shows we should use a broader set of tools. CoT can be useful and faithful, even if it doesn’t spell out everything.
What’s the impact?
- Don’t rely on one test: Hint-verbalization alone can confuse “incompleteness” with “unfaithfulness.” Evaluators should combine multiple methods (like Filler Tokens, FUR, and causal mediation).
- Better evaluation practice: Give models more chances and more space to explain. If longer or multiple explanations start mentioning the hint, it suggests the model’s internal reasoning aligns with the explanation—they just needed room to say it.
- Smarter interpretability: CoT should be part of a toolkit. Together with causal and corruption-based tests, it can help us see whether explanations truly reflect decision-making and where they might be leaving things unsaid.
In short, the paper argues that chain-of-thought explanations are often more trustworthy than recent headlines suggest. Many supposed “failures” are just short, compressed explanations leaving out details, not evidence that the model is inventing fake reasons.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- External validity to larger and specialized models: Results are limited to Llama-3-8B, Llama-3.2-3B, and gemma-3-4b-it; it is unknown whether findings hold for larger frontier models, dedicated “reasoning” models, or models trained with explicit scratchpads/tool-use.
- Task and domain coverage: Evaluations are confined to multi-choice, multi-hop QA (OpenBookQA, StrategyQA, ARC-Easy); generalization to math (GSM8K/MATH), code, long-context tasks, open-ended generation, safety-critical decision-support, and multi-turn dialogue remains untested.
- Cross-lingual and multimodal generalization: Faithfulness/incompleteness patterns for non-English languages and multimodal (e.g., VQA) or audio-text settings are unexplored.
- Hint taxonomy completeness: Only three hint types (Professor, Metadata, Black Squares) are studied; effects of subtler, adversarial, noisy, conflicting, or real-world confounder-like hints (e.g., topic/author/source cues) are unknown.
- Realistic hint distributions: The injected hints are artificial; how naturally occurring cues (UI affordances, document layout, hyperlinks, social proof) impact CoT faithfulness and verbalization is not assessed.
- Bias in few-shot selection: Black Squares demonstrations are selected from items all models get right, potentially biasing outcomes; robustness to alternative few-shot selections is not measured.
- LLM-as-a-judge reliability: Hint verbalization detection relies on a single judge (gpt-oss-20b) with ~80% agreement; sensitivity to judge choice, calibration, and adversarial phrasing is not quantified.
- Semantic verbalization vs causal use: The current verbalization check detects mention, not causal reliance; a principled criterion for “causal verbalization” remains to be defined and measured.
- faithful@k interpretability: While faithful@k increases with sampling, how to choose k in practice, budget-aware trade-offs, and risks of cherry-picking favorable samples are not analyzed.
- Decoding sensitivity: faithful@k is reported under default sampling settings; dependence on temperature/top-p, beam search, and reranking strategies is not systematically studied.
- Selection bias in faithful@k: Examples with too few hint-flipped samples are excluded; the impact of this exclusion on estimates and conclusions is not quantified.
- Completeness operationalization: The paper argues incompleteness vs unfaithfulness but lacks a formal, quantifiable completeness metric (beyond faithful@k) or simulatability tests linking CoT detail to decision reproduction.
- Simulatability/user studies: No human experiments assess whether longer or more “complete” CoTs improve user prediction of model behavior or trust calibration.
- Agreement between metrics: Disagreements among Biasing Features, Filler Tokens, and FUR are documented but not reconciled; conditions under which metrics align or diverge (and why) are not theoretically or empirically mapped.
- FUR applicability constraints: FUR is only applicable when no-CoT and CoT predictions match; how much this restriction biases conclusions and how to extend FUR beyond this subset is unclear.
- FUR stability and side effects: The impact of hyperparameters, potential catastrophic forgetting, and out-of-distribution effects of unlearning on unrelated behavior are not systemically examined.
- Corruption metric breadth: Only the “filler tokens” corruption is used; alternative corruptions (shuffle, paraphrase, masking subsets of steps, counterfactual step edits) could yield different conclusions but are not tested.
- Step-level causal analysis: CMA treats the entire CoT as a single mediator; step-level mediation (which steps mediate effects, and when) is not estimated.
- Identification assumptions for CMA: The causal mediation analysis hinges on strong assumptions (e.g., no unmeasured mediator–outcome confounding, consistency) that are unlikely to strictly hold in autoregressive generation; robustness to violations is not assessed.
- CMA construction details: How is computed for multiple-choice (tokenization/label mapping), sensitivity to prompt formatting, and variance across seeds are not fully documented.
- Alternative mediators: Other latent mediators (e.g., internal scratchpad representations, attention patterns, tool calls) are not modeled; how much of the effect bypasses the textual CoT is unknown.
- Logit Lens scope and causality: Analysis is limited to MHA outputs and top-5 logits; MLP pathways, attention head-level mechanisms, and causal intervention (e.g., activation patching) are not explored.
- Mechanisms behind hint-type differences: Why faithful@k improves for Professor hints but not for Black Squares/Metadata remains under-theorized; hypotheses (e.g., training distribution match, salience, executive control) are not tested via targeted interventions.
- Detection of incompleteness at inference: No method is proposed to predict, at runtime, whether a given CoT is incomplete vs unfaithful or to request clarifications adaptively.
- Training objectives for completeness: Concrete objectives, data, or curricula to improve completeness without Goodharting on hint mention are not developed or evaluated.
- Safety and robustness: Interactions between hint susceptibility, CoT faithfulness, and malicious prompt injections/backdoors are not examined.
- Long-context and memory effects: How context length, retrieval augmentation, and memory tools modulate CoT completeness and faithfulness is untested.
- RLHF vs SFT effects: The influence of alignment/fine-tuning methods (RLHF/DPO/NPO/SFT) on metric disagreements and verbalization rates is not disentangled.
- Cost/compute analysis: The practical computational and monetary costs of achieving higher faithful@k (e.g., k=16, 128 samples) versus gains in measured faithfulness are not quantified.
- Reproducibility: Code is to be released upon publication; until then, full reproducibility (prompts, seeds, sampling configs, judge scripts) is limited.
- Generalization to non-multiple-choice outputs: For free-form answers, how to adapt Biasing Features, FUR, filler tokens, and CMA is not detailed.
- Measuring suppression vs promotion: CMA suggests CoTs sometimes suppress non-hinted options; targeted interventions to confirm and control suppression mechanisms are not conducted.
- Predictive diagnostics: No diagnostic probes are proposed to forecast when Biasing Features will overstate unfaithfulness or when faithful@k will likely help.
- Ethical and governance implications: How the reinterpretation of “unfaithfulness” as “incompleteness” should alter auditing standards, risk assessments, or deployment guardrails remains an open policy question.
Glossary
- BCa confidence intervals: Bias-corrected and accelerated bootstrap intervals that adjust for bias and skewness in resampling estimates. "with BCa 95\% confidence intervals from 10,000 bootstrap resamples."
- Biasing Features: A hint-verbalization-based evaluation metric that injects cues to bias a model and checks if explanations mention them. "In \S \ref{sec:biasing_features}, we describe the Biasing Features (hint verbalization) metric"
- Black Squares: A specific hinting technique marking the suggested correct answer with black squares in examples. "Black Squares, where the hint is conveyed by marking the correct answer with black squares in the few-shot demonstrations as well as marking the suggested answer in the main example."
- Bootstrap confidence intervals: Intervals derived from bootstrap resampling that quantify uncertainty around estimates. "Errorbars indicate 95\% bootstrap confidence intervals."
- CC-SHAP: A variant of SHAP for comparing attributions between inputs and reasoning tokens to assess faithfulness. "Other approaches include CC-SHAP \citep{Parcalabescu2023OnMF}, which measures faithfulness by comparing input attributions for the output with attributions for the reasoning tokens"
- Causal Mediation Analysis: A causal inference method that decomposes a total effect into direct and indirect (mediated) components. "Using Causal Mediation Analysis, we further show that even non-verbalized hints can causally mediate prediction changes through the CoT."
- Chain-of-Thought (CoT): Step-by-step natural language reasoning generated by an LLM to support its answer. "A common approach is to analyze the modelâs CoT \citep{wei2022chain, kojima2022large}"
- Counterfactual Edit methods: Interventions that insert tokens to flip predictions and test whether explanations reflect those edits. "Counterfactual Edit methods \citep{Atanasova2023FaithfulnessTF, Siegel2024ThePA} similarly insert contagious tokens that flip the prediction and check whether explanations reflect these edits."
- DSPy: A framework for programmatic prompting and evaluation pipelines for LLMs. "using DSPy \citep{khattab2022demonstrate, khattab2024dspy}"
- faithful@k: An adapted pass@k-style metric measuring the chance that at least one of k samples produces a faithful explanation. "We call this metric faithful@k, the probability of obtaining at least one faithful explanation in attempts."
- Faithfulness: Alignment between an explanation and the model’s true reasoning process. "\citet{Jacovi2020TowardsFI} define faithfulness as the alignment between an explanation and the modelâs true reasoning process."
- Faithfulness through Unlearning Reasoning steps (FUR): A method that measures faithfulness by unlearning specific reasoning steps and observing prediction changes. "Faithfulness through Unlearning Reasoning steps (FUR) \citep{tutek-etal-2025-measuring}"
- Filler Tokens: A corruption-based test that replaces the CoT with ellipses to see if predictions depend on the reasoning text. "While Filler Tokens measures contextual faithfulness, FUR evaluates parametric faithfulness."
- Few-shot prompts: Demonstration-based prompting using a small set of examples embedded in the input. "injecting hints via few-shot prompts with repeated answer choices, visual markers for the correct option, explicit XML metadata, and expert/user opinions"
- Greedy decoding: Deterministic decoding that selects the highest-probability token at each step. "We use greedy decoding for both CoT generation and prediction, matching previous work"
- KL-divergence constraints: Regularization constraints based on Kullback–Leibler divergence to limit deviations during optimization. "Negative Preference Optimization (NPO) \citep{Zhang2024NegativePO} with KL-divergence constraints."
- LayerNorm: Layer normalization operation applied to activations before decoding or unembedding. "by applying the final-layer LayerNorm followed by the unembedding matrix "
- Logit Lens: An interpretability technique that decodes internal activations into vocabulary logits across layers. "we use the Logit Lens \citep{nostalgebraist_2020_logitlens}, an interpretability method that decodes intermediate representations (e.g., MLP or attention outputs) into vocabulary logits"
- LLM-as-a-judge: An evaluation approach that uses an LLM to assess whether a CoT contains specific content. "we employ an LLM-as-a-judge framework instead of simple lexical keyword matching, following prior work \citep{Chen2025ReasoningMD, Chua2025AreDR}."
- Multihead Attention (MHA): Transformer attention mechanism with multiple heads operating in parallel. "let denote the Multihead Attention (MHA) output at layer at the position of the token of interest."
- Negative Preference Optimization (NPO): An optimization method that penalizes undesirable outputs to unlearn targeted behaviors. "To unlearn reasoning steps, \citet{tutek-etal-2025-measuring} employ Negative Preference Optimization (NPO) \citep{Zhang2024NegativePO} with KL-divergence constraints."
- Natural Direct Effect (NDE): The portion of an intervention’s effect not mediated by a specified intermediate variable. "We first compute the natural direct effect (NDE) of adding a hint to the input, holding the CoT fixed:"
- Natural Indirect Effect (NIE): The portion of an intervention’s effect that operates via a specified mediator. "Next, we compute the natural indirect effect (NIE) of adding the hint, this time keeping the input fixed while substituting in the CoT induced by the hinted input:"
- Parametric faithfulness: Faithfulness assessed via the model’s parameters rather than purely contextual text. "FUR evaluates parametric faithfulness."
- pass@k: A metric estimating the probability that at least one of k generated samples is correct. "we adapt the pass@k metric from \citet{Chen2021EvaluatingLL}."
- Representation-level interventions: Edits applied to internal feature representations to remove or alter specific attributes. "\citet{Karvonen2025RobustlyIL} use representation-level interventions to remove demographic information and reduce racial and gender bias in LLM-based hiring."
- Simulatability: The degree to which an explanation allows an external observer to reproduce the model’s prediction. "While simulatability \citep{DoshiVelez2017TowardsAR, Hase2020EvaluatingEA, Wiegreffe2020MeasuringAB, Chan2022FRAMEER} captures this"
- Unembedding matrix: The matrix mapping hidden states back into vocabulary logit space. "followed by the unembedding matrix "
- Verbalization Finetuning (VFT): A training approach that encourages models to explicitly verbalize latent behaviors or cues. "Verbalization Finetuning (VFT) \citep{Turpin2025TeachingMT} encourages models to articulate reward-hacking behaviors"
- Vocabulary logits: Logit scores over the vocabulary produced by projecting activations through the unembedding matrix. "decodes intermediate representations (e.g., MLP or attention outputs) into vocabulary logits"
Practical Applications
Immediate Applications
The following bullet points summarize practical uses that can be deployed now, leveraging the paper’s findings and methods. Each item includes sector links, potential tools/workflows, and key assumptions or dependencies.
- Multi-metric explainability dashboards for LLMs in production
- Sectors: software, finance, healthcare, legal, education
- What: Replace single-metric “hint verbalization” checks with a toolkit that includes Filler Tokens (contextual corruption), Faithfulness through Unlearning Reasoning steps (FUR), faithful@k sampling, and causal mediation analysis (NDE/NIE) to assess explanation faithfulness more holistically.
- Tools/workflows: “Explainability Dashboard” integrating CoT-corruption tests, mediation estimators, and sampling-based completeness (faithful@k).
- Assumptions/dependencies: Access to model outputs and logits; FUR requires model editing capability (more feasible for open-source, small/medium models); mediation analysis depends on consistent probability estimation and the ability to generate CoT/no-CoT variants; LLM-as-judge reliability varies.
- Budget-aware explanation generation (“explanation pass@k”)
- Sectors: customer support, education (tutoring), compliance reporting
- What: Generate multiple CoTs per query and use faithful@k to pick at least one explanation that verbalizes decision-relevant factors when token budgets permit (k ∈ {2,4,8,16}).
- Tools/workflows: “Explanation pass@k” generator that samples multiple rationales and selects one with higher completeness; configurable inference-time budgets.
- Assumptions/dependencies: Latency/cost constraints for sampling; LLM-as-judge or rule-based checks for verbalization; sampling may have diminishing returns for certain hint types (e.g., metadata/black squares showed limited gains).
- Red-teaming and risk monitoring that detects non-verbalized influence
- Sectors: platform safety, healthcare triage, financial advisory, legal drafting
- What: Use causal mediation analysis to quantify when inputs (hints, UI signals, user opinions) shift predictions indirectly via CoTs—even when those factors are not verbalized—flagging hidden influence risks.
- Tools/workflows: “Mediation-based Risk Monitor” that computes NDE/NIE on critical outputs; policy alerts when NIE is non-zero for sensitive features (e.g., demographic cues).
- Assumptions/dependencies: Requires controlled generation to hold CoT vs input fixed; probability tracking for target choices; sensitive attribute identification.
- CoT-corruption test harness for model audits
- Sectors: regulated industries (finance, healthcare), enterprise AI governance
- What: Adopt corruption-based tests (e.g., Filler Tokens replacing CoTs with “…”) to check whether CoTs materially affect predictions; use results to calibrate trust in explanations.
- Tools/workflows: “CoT Corruption Harness” integrated in CI/CD for model releases; periodic audit jobs with bootstrap confidence intervals.
- Assumptions/dependencies: Access to model inference; tasks where answers can be re-scored reliably; potential differences between multiple-choice vs free-form tasks.
- Prompting and UX guidance that sets realistic expectations for explanations
- Sectors: enterprise SaaS, education, consumer apps
- What: Communicate that CoTs are compressed narratives (often incomplete but not necessarily unfaithful); expose “explanation completeness” indicators; offer option to generate more rationales when stakes are high.
- Tools/workflows: UI “Explanation Completeness” badge informed by faithful@k and corruption tests; auto-escalation of k for high-risk requests.
- Assumptions/dependencies: User tolerance for latency; internal thresholds for completeness; careful messaging to avoid implying guarantees of full faithfulness.
- Mechanistic tracing for model debugging using Logit Lens
- Sectors: model development, research labs, applied ML teams
- What: Apply Logit Lens on attention/MLP outputs to locate where hint-related concepts emerge across layers/timesteps; use findings to refine prompt design or training data.
- Tools/workflows: “LogitLens Explorer” for layer-wise concept tracking; pattern detection around step enumeration and contrastive markers.
- Assumptions/dependencies: Access to hidden states/unembedding; more feasible in open-source models; interpretive skill needed to avoid overfitting to artifacts.
- Procurement and evaluation policies that avoid single-metric overfitting
- Sectors: public sector, enterprise procurement
- What: Update evaluation RFPs and vendor criteria to require multi-metric faithfulness reporting (corruption-based, mediation analysis, sampling completeness) rather than only hint-verbalization tests.
- Tools/workflows: Standardized evaluation checklists; contract language mandating cross-metric explainability evidence.
- Assumptions/dependencies: Policy willingness to adopt nuanced standards; suppliers’ ability to instrument models accordingly.
Long-Term Applications
The following items require further research, scaling, or development, but are directly motivated by the paper’s results and recommendations.
- Causally aware training objectives for explanation completeness
- Sectors: healthcare diagnosis support, credit risk, autonomous systems
- What: Develop training regimes that encourage CoTs to expose decision-relevant factors (not just hints) by optimizing for mediation-aware objectives (maximize NIE for true factors, minimize for spurious ones) and robustness across varied interventions.
- Tools/workflows: “Causal-Explainability Fine-tuning” pipelines; regularizers that penalize spurious post-hoc rationalization; curriculum with diverse, non-trivial interventions.
- Assumptions/dependencies: Access to model weights; high-quality task-specific causal annotations; compute budgets; careful validation to avoid reward hacking.
- Industry standards and regulatory frameworks for multi-metric explainability
- Sectors: finance, healthcare, education, public safety
- What: Formalize standards requiring corruption tests, mediation analyses, and sampling completeness for LLM explanations; align with risk classes and reporting obligations.
- Tools/workflows: “Explainability Standard v1.0” with metric definitions, sampling protocols, thresholds, and reporting templates; third-party certification.
- Assumptions/dependencies: Regulator buy-in; consensus on metric definitions; sector-specific calibration; handling proprietary models.
- Integrated interpretability suites (“MediationLens” + “CoT Lab”)
- Sectors: AI platforms, MLOps vendors, enterprise AI
- What: Productize combined tools that run Logit Lens, causal mediation, FUR, CoT corruption, and faithful@k at scale; provide APIs and dashboards; support both open-source and closed models via proxy protocols.
- Tools/workflows: Cloud/on-prem “Interpretability Suite” with job scheduling, dataset management, reproducible pipelines, and bootstrapped confidence intervals.
- Assumptions/dependencies: Model access constraints (logits, hidden states, editing); scalability; data governance; privacy and compliance.
- Domain-specific explanation assurance in high-stakes sectors
- Sectors: clinical decision support, hiring, underwriting, legal analysis
- What: Tailor the toolkit to domain features (e.g., medical guidelines, fairness constraints) and integrate representation-level interventions to remove sensitive attributes while auditing whether CoTs reflect remaining causal pathways.
- Tools/workflows: “Domain Explainability Assurance” packages combining concept identification, causal mediation, and CoT audits; fairness modules that unlearn demographic reasoning steps (building on FUR and related interventions).
- Assumptions/dependencies: Domain-specific concept labels; access to model editing; strong validation cohorts; governance frameworks.
- Agentic systems with explanation-aware control loops
- Sectors: robotics, autonomous agents, operations
- What: Build agents that monitor their own CoTs for completeness and causal alignment in-the-loop, adapting inference-time budgets (k) and flagging tasks where explanations show hidden influence or insufficient completeness.
- Tools/workflows: “Explanation-Aware Controller” that dynamically adjusts reasoning length, runs mediation checks mid-task, and escalates human oversight when needed.
- Assumptions/dependencies: Real-time inference capacity; reliable fast proxies for mediation and corruption tests; safe fallback protocols.
- Benchmarks and datasets for generalizable explanation training
- Sectors: academia, standards bodies, applied research
- What: Create diverse, realistic tasks where hints/interventions vary in subtlety (beyond metadata or obvious markers), enabling training and evaluation that generalize across domains and avoid overfitting to toy setups.
- Tools/workflows: “Generalized Explanation Benchmark” with multi-hop reasoning, free-form generation, and domain-grounded causal factors; shared leaderboards reporting across metrics.
- Assumptions/dependencies: Community adoption; annotation quality; sustained maintenance; transparent evaluation protocols.
- Compute-efficient FUR and mediation at scale
- Sectors: large enterprises, cloud AI providers
- What: Engineer memory- and compute-optimized variants of FUR and mediation pipelines to apply to larger models and longer generations; approximate methods that preserve diagnostic power.
- Tools/workflows: Distillation of mediation signals; per-layer sampling strategies for Logit Lens; low-rank or adapter-based unlearning for FUR.
- Assumptions/dependencies: Algorithmic innovation; careful approximation guarantees; access to model internals or adapter routes.
Each long-term application builds on the paper’s central insights: CoTs can be faithful without explicit hint verbalization, incompleteness is distinct from unfaithfulness, and causal mediation provides a principled lens to detect non-verbalized influence. By evolving evaluation, training, and governance to reflect these insights, organizations can deploy LLMs with explanations that are more trustworthy, useful, and robust.
Collections
Sign up for free to add this paper to one or more collections.