- The paper introduces a cross-lingual mapping loss integrated with next-token prediction to enhance multilingual LLM performance and mitigate catastrophic forgetting.
- It reports significant improvements with increased BLEU scores, BERTScore-Precision, and accuracy, especially for low-resource languages like Czech and Ukrainian.
- A novel Language Alignment Coefficient is proposed to robustly quantify cross-lingual consistency and provide a stable alignment metric.
The increasing deployment of multilingual LLMs has exposed persistent inadequacies in cross-lingual generalization, especially affecting low-resource languages. Standard monolingual next-token prediction (NTP) pre-training accentuates monolingual fluency but fails to promote robust cross-lingual alignment, resulting in sub-optimal transfer for key tasks like machine translation (MT), cross-lingual question answering (CLQA), and natural language understanding (CLNLU). Bilingual fine-tuning and contrastive alignment methods encounter instability or rely on expensive parallel corpora and are largely incompatible with decoder-only LLMs. This motivates novel pre-training objectives and datasets capable of fostering stronger, instruction-agnostic cross-lingual correspondences during LLM training.
Cross-Lingual Mapping Objective and Pre-Training Framework
The paper introduces a cross-lingual mapping (CL) loss symmetrically integrated into continued pre-training alongside the NTP objective using a decoder-only architecture. NTP optimizes negative log-likelihood over monolingual sequences, supporting retention of high-resource language proficiency and mitigating catastrophic forgetting by maintaining a balanced batch composition across language strata. The CL task, in contrast, trains the model to autoregressively generate target-language sequences conditioned on full source-language inputs, using parallel sentence pairs. This dual formulation enforces alignment in the shared embedding space and enhances both multilingual comprehension and generative transfer, without explicit translation instructions or architectural modifications.
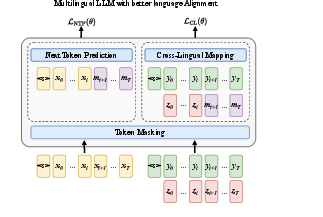
Figure 1: Schematic of continued pre-training, highlighting the interplay between Next-Token Prediction and Cross-Lingual Mapping; "<s>" denotes the start token and mi the mask for the ith token.
Empirically, the proposed CL objective is generalizable beyond supervised translation by promoting implicit semantic transfer across languages. This differentiates it sharply from prior approaches focusing on contrastive alignment, bilingual masking, or translation-instruction-based pre-training, and is uniquely suited for scalable extension to low-resource or typologically divergent language pairs.
Language Alignment Coefficient: Quantifying Cross-Lingual Consistency
Addressing weaknesses in established cosine similarity or projection variance-based alignment metrics, the study proposes the Language Alignment Coefficient (LAC), defined as the average embedding cosine similarity across layers normalized by standard deviation (the inverse of Coefficient of Variation). This metric provides robust quantification of alignment magnitude and stability, offering resilience against outliers and variability in shallow or noisy test sets. Higher LAC directly reflects enhanced cross-lingual coherence, especially crucial for evaluating models in low-resource or domain-shifted conditions.
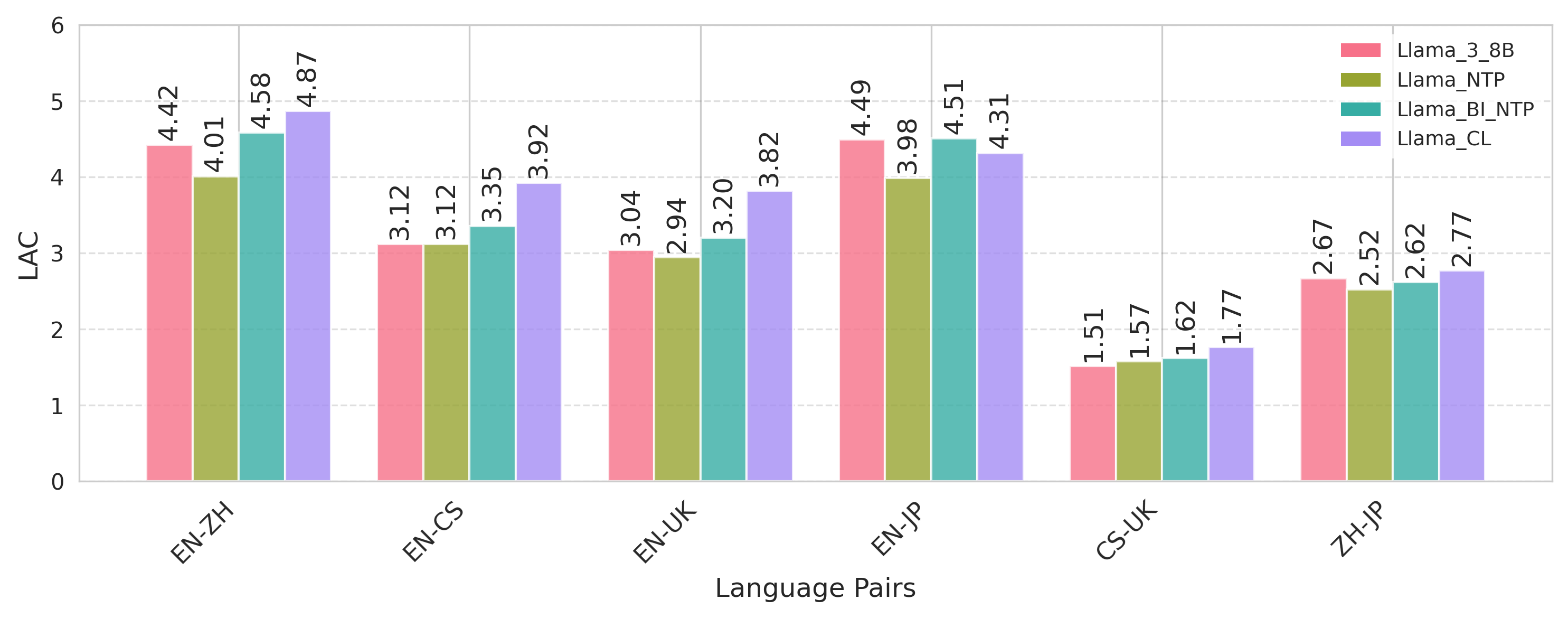
Figure 2: Comparative analysis of language alignment (LAC) across model variants, indicating the dominant contribution of the joint CL objective in boosting cross-lingual consistency.
Data Curation and Setup
Experiments span diverse typological pairs, including high-resource (EN-ZH, ZH-JP), mid-resource (EN-CS), and low-resource (CS-UK) scenarios. The evaluation encompasses MT, CLQA, CLNLU, and summarization, leveraging datasets such as Cleaned Alpaca, CrossSum, OpenHermes-2.5, XQuAD, and Belebele; pre-training incorporates approximately 4.1M monolingual and 3.7M parallel cross-lingual sentence instances. Careful separation of training and evaluation splits ensures uncompromised generalization assessment.
Empirical Results
Language Modeling and Alignment
The joint NTP+CL pre-training schema (Llama_CL) produces substantial cross-lingual improvements over monolingual (Llama_NTP) and bilingual (Llama_Bi_NTP) NTP baselines, with complementary reductions in perplexity across all languages under test, notably for low-resource Czech and Ukrainian. Explicit modeling of bilingual mappings produces consistent LAC elevation and improved latent alignment, outperforming models with code-switched or instruction-tuned translation data. The gains extend to zero-shot language pairs, indicating generalization beyond observed alignments.
MT demonstrates BLEU increases up to 11.9 points (e.g., EN-CS), BERTScore-Precision increases of over 6.7 in CLQA, and >5% accuracy improvements in CLNLU relative to strong instruction-tuned Llama-3-8B baselines using identical downstream datasets. Comparison with models incorporating explicit translation instructions in pre-training reveals that such instruction signals can induce overfitting and limit general-purpose cross-lingual transfer, a phenomenon not observed in the instruction-agnostic CL approach. Notably, the proposed methodology yields even stronger relative improvements when applied to weaker base architectures (e.g., BLOOM-3B), suggesting its suitability as a universal enhancement.
Open-Ended and Reference-Free QA
LLM-assisted evaluation on open-ended QA using human and model-based judgments verifies consistent generative quality improvements, both in content and stylistic complexity, directly attributable to stronger semantic alignment from CL pre-training.
Ablation and Analysis
Ablations confirm that data volume is not solely responsible for the gains; embedding cross-lingual tasks as CL objectives in pre-training outperforms both pre- and post-hoc instruction-tuning on parallel data. The CL loss provides an alignment inductive bias unavailable from increased parallel data alone, and does not compromise performance on English monolingual understanding, as demonstrated with MMLU, LogiQA, and AlpacaEval benchmarks.
Case studies further reveal reduced source-language copying, improved treatment of rare words, and decreased translation/reasoning errors relative to NTP or instruction-tuned translation counterparts.
Theoretical and Practical Implications
The cross-lingual mapping paradigm clarifies that explicit pre-training objectives, rather than task-specific fine-tuning or reliance on large parallel corpora after pre-training, are necessary for robust and transferable cross-lingual representation learning in decoder-only LLMs. Importantly, the improved flexibility and stability in alignment metrics enable scalable evaluation pipelines for multilingual models, especially in the context of limited or noisy resources.
The approach aligns with trends observed in recent surveys and empirical studies highlighting the need for architecture-agnostic, instruction-agnostic, and data-efficient cross-lingual adaptation [see, e.g., (Singh et al., 2024), 2024.emnlp-main.572].
Conclusion
The paper introduces an instruction-agnostic, cross-lingual mapping objective for decoder-only LLMs, supported by a robust alignment metric (LAC) and extensive empirical evaluation spanning MT, CLQA, CLNLU, and summarization. The results demonstrate clear superiority over conventional fine-tuning and bilingual NTP strategies, yielding pronounced BLEU and BERTScore-Precision gains. This methodology establishes a scalable template for future multilingual LLM research, with immediate practical implications in both high- and low-resource language settings. Future research should address remaining gaps in abstractive summarization and logical reasoning, and extend the framework to broader linguistic coverage and more complex cross-lingual reasoning paradigms.
References
(2604.10590)