- The paper introduces Strix, a modular NPU reliability framework that partitions the accelerator pipeline into targeted, critical modules.
- It employs lightweight ECC, dual-vector checksums, and ABFT-inspired techniques to achieve >99% error detection (INT8) with a performance slowdown of ≤1.07x.
- The approach scales effectively for DNN/LLM workloads while incurring modest hardware overhead (area: 8.7–20.7%, power: 16.8–23.2%), maintaining near-TMR accuracy.
Strix: A Systematic Framework for NPU Reliability
Motivation and Reliability Challenges in NPUs
The increasing reliance of DNNs and LLMs on NPUs, particularly in safety-critical domains, has significantly raised the stakes for hardware reliability. As technology nodes shrink and model complexity grows, bit-level hardware faults are becoming more common, threatening both model correctness and safety compliance. Standard fault-tolerance approaches—ranging from algorithmic robustness via fault-injection training to instruction-level redundancy (IR) and micro-architectural ECC—either fail to provide direct in-hardware detection or impose unsustainable performance and area overheads. Moreover, prevailing system-level treatments, such as treating the NPU monolithically and employing TMR, fail scalability and deployment viability tests, creating an unresolved gap between reliability requirements and practical solutions.
A key insight from fault injection stress-testing of models (Figure 1) is that, while DNNs and LLMs display a degree of fault tolerance under low error rates, faults above device-realist thresholds (e.g., silent-error rates >10−7) sharply degrade accuracy and functional fidelity. Notably, critical bit positioning—especially sign and exponent bits for FP32/BF16—dominates the propagation and impact of errors, suggesting that targeted bit-level protection offers a more cost-effective path than blanket redundancy.
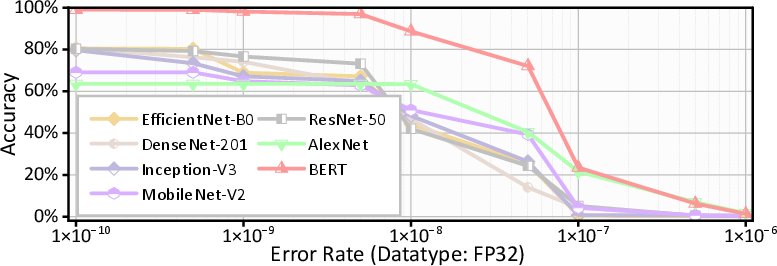
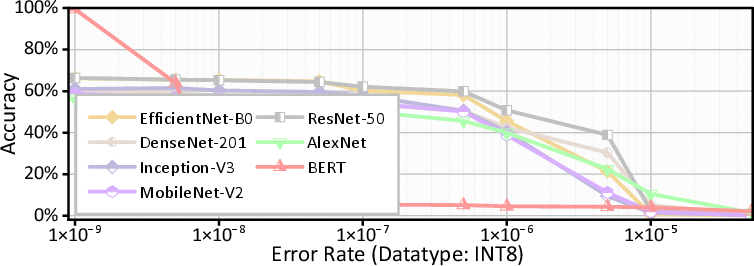
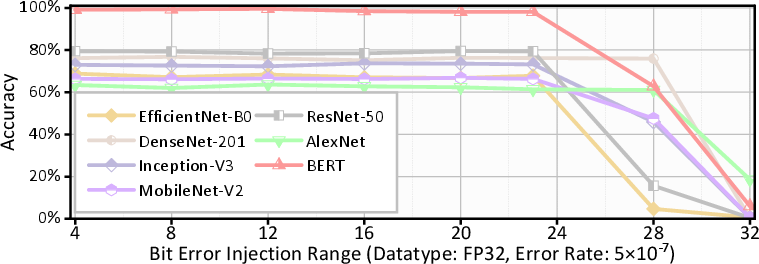
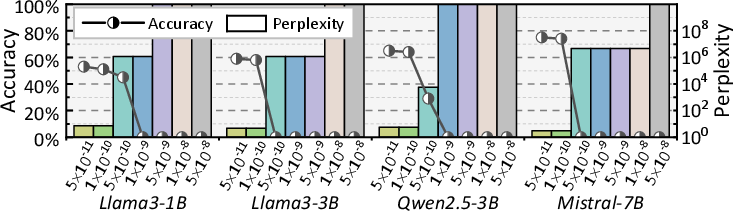
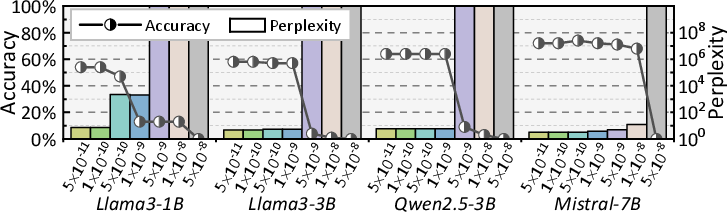
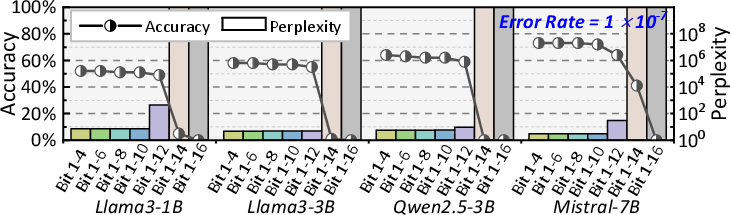
Figure 1: FP32 DNNs under different error rates, illustrating sharp drops in model accuracy beyond acceptable fault thresholds.
Strix Architecture: Full-Stack, Modular Reliability
Strix is designed as a comprehensive reliability framework for NPUs, implemented atop an open-source systolic-array-based architecture (Gemmini). Unlike monolithic or hyper-granular approaches, Strix partitions the NPU pipeline into critical modules: instruction/control registers, local memory, the systolic array, and non-linear operators (Figure 2). It delivers module-specific safeguards, each tuned to the failure modes of its target.
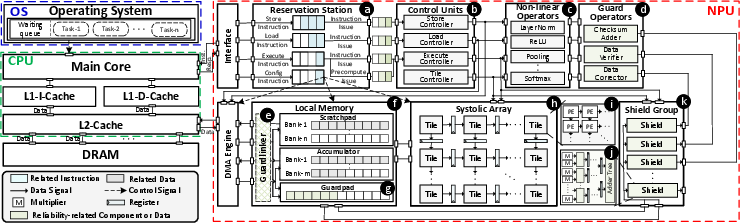
Figure 2: The architectural overview of Strix. Strix applies module-specific hardware safeguards for NPUs.
- Registers employ SEC-DED ECC, balancing minimal state size and maximal fan-out with bounded hardware overhead.
- Local Memory is protected by a dual-vector checksum mechanism. This design leverages a dedicated guardpad and guardlinker, providing high-throughput, block-wise error detection and correction with effective permanent fault localization (Figure 3).
- Systolic Array reliability leverages a fully decoupled, ABFT-inspired "shield group" that operates in parallel to the core array, using row/column checksum verification with zero critical-path extension (Figure 4).
- Non-linear Operators are either verified via algebraic invariants (e.g., LayerNorm, Softmax) or with selective redundancy for more complex or approximate arithmetic.
- ISA Extensions align the hardware protections with the software/runtime stack, supporting error-aware orchestration and reporting by the operating system.
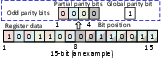
Figure 5: SEC-DED ECC: each partial parity bit verifies data of the same colour, and the global parity bit verifies the partial parity bits.
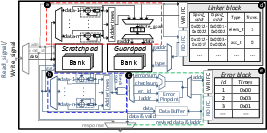
Figure 3: Components related to local memory reliability. Blue lines: read path; black lines: write path; grey lines: common path.

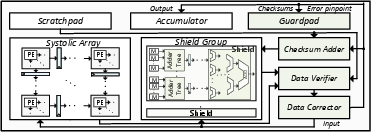

Figure 4: Mathematical principle and an example of the shield group, enabling efficient ABFT-based protection.
Numerical Results and Comparative Evaluation
Strix's efficacy and efficiency were validated on diverse DNN and LLM workloads, spanning INT8, FP32, and BF16 precision and deployed both in academic (default Gemmini) and industrial-scale configurations.
- Performance Overhead: Strix achieves ≤1.07× slowdown across all models, with a geometric mean of 1.04×—an order-of-magnitude improvement over TMR (up to 3.68×) and significant gains over IR or SOTA rollback-based approaches (Figure 6).
- Coverage: Error detection consistently exceeds 99% (INT8) and 97% (FP32/BF16) at industry-relevant fault rates. Correction coverage remains above 95%, only declining at extreme error rates and with very large arrays (Figure 7).
- DNN/LLM Accuracy: Across fault regimes, Strix sustains model accuracy at levels near TMR and outperforms IR and rollback schemes, which degrade rapidly with permanent faults and increased array scaling (Figures 8 and 9). Notably, Strix maintains LLM perplexity and accuracy even in INT8 and BF16 quantized settings.
- Detection Latency: Strix achieves sub-microsecond worst-case error localization terms thanks to boundary pipelining and decoupled verifier/corrector logic. The critical path remains defined by the native NPU, not the Strix extensions.
- Hardware Overhead: Area and power costs are modest—ranging from 8.7–20.7% (area) and 16.8–23.2% (power), with costs amortized on larger arrays.

Figure 6: Performance overhead (ResNet-50, AlexNet, MobileNet-V2, BERT). Strix achieves a geometric of 1.04×.


Figure 7: Error detection coverage of Strix.



Figure 8: Impact of different strategies on DNN accuracy under INT8-D.
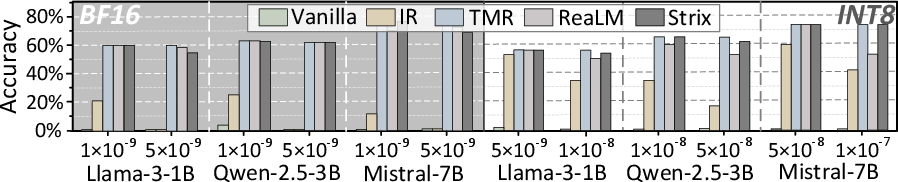
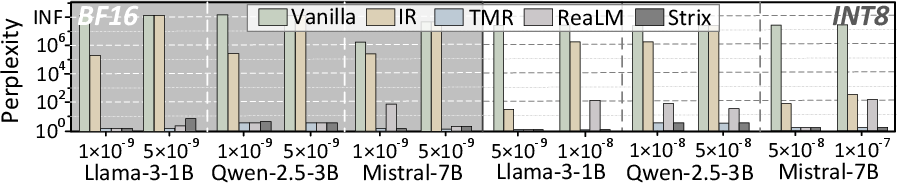
Figure 9: Impact of different strategies on LLM accuracy.
Implications and Future Directions
Strix demonstrates that high-coverage, low-latency protection for NPUs is tenable without the expense of brute-force redundancy or severe performance compromise. The architectural principles—modular, task-aware isolation; light-weight ECC and checksum logic at data path boundaries; ABFT-inspired verification within the systolic array; and ISAs to coordinate hardware-software reliability semantics—chart a concrete path towards certifiable NPUs for critical AI deployment.
Practically, Strix's methodologies will be increasingly relevant as model scaling, memory bandwidth, and compute density continue to stretch hardware margins. The implication for AI systems in autonomous vehicles, data centers, and edge deployment is substantial: system designers can deliver fault containment and diagnosability that aligns with emerging standards (e.g., ISO-26262), even as compute loads and error exposures grow.
Looking ahead, several avenues present themselves:
- Extending Strix-style modular protection to heterogeneous accelerators and multi-chiplet SoC deployments.
- Integrating dynamic reliability monitoring and runtime adaptation, enabling real-time reconfiguration in response to spatial/temporal fault clustering.
- Exploring co-optimization of quantized model representations and hardware protection policies for maximal reliability/cost trade-off under stringent resource budgets.
Conclusion
Strix introduces a system perspective to NPU reliability, re-partitioning the accelerator pipeline for module-specific protection and enabling near-complete fault coverage at minimal latency and resource overhead. The framework synthesizes hardware and software design, yielding scalable, certifiable fault tolerance—an essential foundation for deploying AI at scale in reliability-critical settings.
Citation: "Strix: Re-thinking NPU Reliability from a System Perspective" (2604.10484)