- The paper presents a predictive safety shield that enhances the Dyna-Q algorithm by simulating safe trajectories to update its Q-values.
- It employs a model-based approach with short predictive horizons to dynamically balance safety and exploration in gridworld environments.
- Experimental results show improved performance with fewer looping behaviors compared to static safety strategies, leading to faster convergence.
Predictive Safety Shield in Dyna-Q Reinforcement Learning
Introduction to Provably Safe Reinforcement Learning
The integration of safety guarantees in Reinforcement Learning (RL) represents a critical direction for enabling its applicability in real-world tasks, particularly in safety-critical environments. Traditional safety mechanisms often treat safe actions as arbitrary, disregarding their impact on future performance. The paper "Predictive Safety Shield for Dyna-Q Reinforcement Learning" (2511.21531) introduces a novel safety shield which addresses this gap by incorporating predictive elements to optimize the safety-performance tradeoff.
Methodology: Predictive Safety Shield
The essence of the paper's contribution lies in developing a safety shield that modifies the Dyna-Q algorithm by embedding a predictive mechanism to better align with safe actions across future states. Unlike fallback strategies which might be inefficient under distribution shifts, the proposed shield utilizes a local update of the Q-function derived from simulating safe trajectories in an environment model. This simulation anticipates the consequences of actions, thereby offering a nuanced safety mechanism that preserves optimality beyond immediate considerations.


Figure 1: Gridworlds for distributional shift problem. The left figure is the environment used for training, while the right one is for deployment.
Implementation Framework
In the proposed shield, a model-based RL approach is adopted where the Q-values are updated using simulated trajectories that account for safety constraints over multiple time steps—a process delineated in Algorithm 1 within the paper. In evaluating actions, a set of reachable states and their associated safe actions are computed up to a prediction horizon. This decision-making framework leverages dynamic programming principles akin to Model Predictive Control (MPC), where only the immediate action of the computed sequence is executed, ensuring adaptation to unforeseen changes in environment dynamics.
The evaluation focuses on discrete state-action spaces exemplified through gridworld environments (Figure 2). These experiments exemplify the shield’s robustness against distributional shifts and its ability to mitigate conservative behaviors typically associated with static safety solutions.
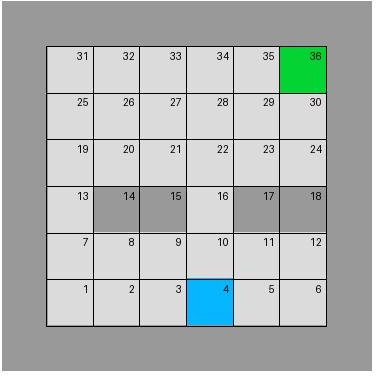

Figure 2: A variant of classic grid maze. The gate in the left figure is opened, reflecting the training environment, while that in the right one is closed but will be opened at the third time step.
Experimental Results
The experiments on gridworld settings reveal the approach's strengths in optimizing safe exploration. Notably, predictive horizons are shown to be critical; even relatively short ones can suffice for optimal path identification. For example, under varying maze configurations, the shield successfully navigates previously unseen environments by adapting its Q-value updates, leading to more efficient trajectories (Figure 3).
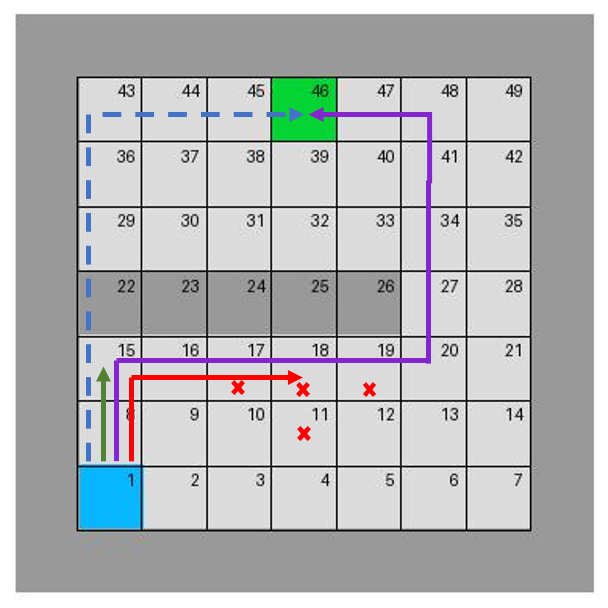
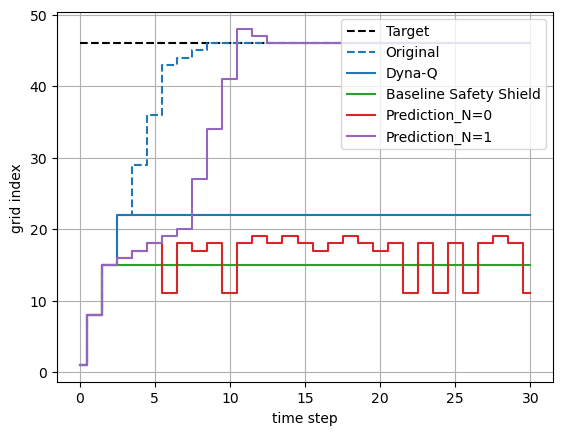
Figure 3: Impact of prediction horizon on agent trajectories. The color of the trajectories on the left corresponds to that of the plots on the right, representing different test conditions. Red crosses mean that the agent is stuck in a loop in these grids.
Comparison with Baseline Approaches
Quantitative metrics derived from these experiments highlight superior performance relative to baseline safety shields which do not factor in performance implications. Pursuing the method’s verification, the adaptive mechanism not only achieves safety but enhances the exploration-exploitation dynamic traditionally hindered by static shields. As shown in Figure 4, trajectory comparisons underscore the approach's capacity for minimizing loop-in behaviors and converging on optimal paths faster than alternatives.
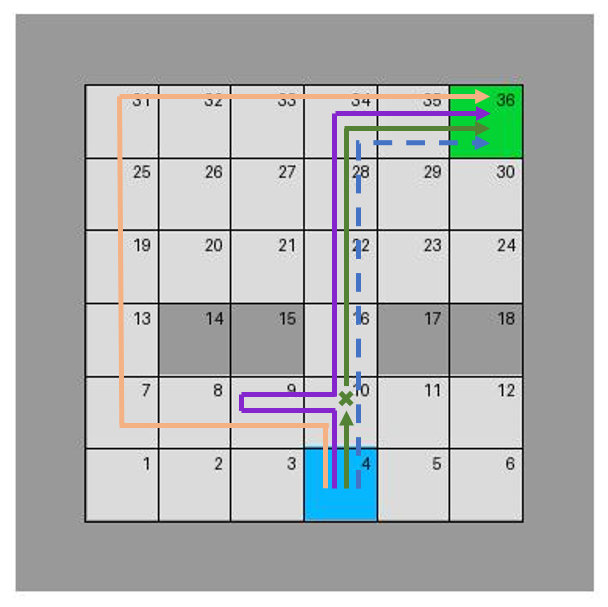
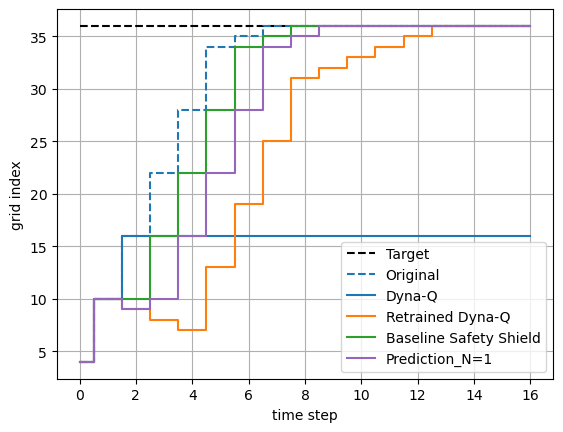
Figure 4: Trajectory comparisons between retraining of RL algorithms such as Dyna-Q learning and our approach. The color of the trajectories on the left corresponds to that of the plots on the right, representing different test setups.
Discussion and Future Directions
The predictive safety shield signifies a pivotal improvement in safety-critical RL by consciously integrating predictions into task-level planning. While the current approach is optimized for static obstacles within discrete environments, extending this framework to continuous spaces and dynamic obstacles remains an open challenge. Further research could explore augmentations for real-time adaptability and application to high-dimensional robotic systems, potentially leveraging sophisticated reachability analyses.
Conclusion
In summary, the paper presents a strategic advancement for safety in RL policy deployment. Through robust predictive simulations, the proposed safety shield circumvents limitations of prior static methods, offering a comprehensive solution to confidently deploy RL agents in environments characterized by notable uncertainty and dynamicity. This work lays a foundation for future extensions into broader, more complex environments, emphasizing performance without sacrificing the assurance of safety.