- The paper presents a wave-conditioned bilinear model that maps GPU kernel grid and loop parameters, reducing runtime configuration to O(1) table lookups.
- It employs sparse structural profiling with offline model fitting, enabling accurate prediction and near-oracle performance across diverse kernels and hardware.
- Experimental results demonstrate significant speedups in dense GEMM, Grouped GEMM, and FlashAttention, with up to 1.33× reduction in end-to-end time-to-first-token.
WaveTune: A Wave-aware Bilinear Modeling Framework for Efficient GPU Kernel Auto-tuning
Introduction and Motivation
Efficient GPU kernel execution remains central in large-scale LLM inference workloads, with tile-based kernels, especially GEMMs and Attention, dominating compute cost. Traditionally, kernel configuration has relied on exhaustive search, expert heuristics, or machine learning cost models, each suffering from fundamental limitations in terms of accuracy, generalization, or runtime overhead. WaveTune introduces a novel wave-conditioned, bilinear analytical approach that effectively eliminates the practical trade-off between execution optimality and configuration decision cost.
The key insight in this work is the identification of a hybrid latency structure: kernel runtime at scale is governed by discrete execution “waves” due to GPU SM occupancy constraints, yet, within each wave regime, execution exhibits piecewise bilinear scaling as a function of grid size and inner loop iterations. This observation enables a paradigm where only sparse, structured profiling is required offline, and runtime decision-making reduces to lightweight table lookups with negligible overhead.
GPU Kernel Wave Quantization and Its Implications
Modern tile-based GEMM kernels decompose computations into thread blocks scheduled across GPU SMs. When the grid size exceeds available SM concurrency, execution occurs in “waves”—batches of thread blocks dispatched concurrently—and quantization effects result in partial occupancy in the final wave. Classical models either treat this process as fully stepwise (quantized) or linearly scaled, each neglecting critical physical determinants for accurate and efficient configuration.
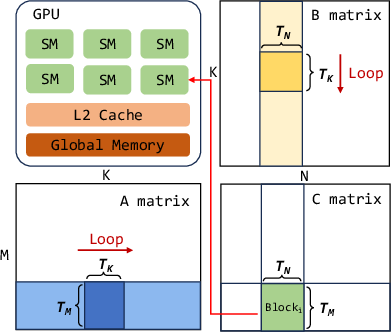
Figure 1: Illustration of the Tiled GEMM execution model.
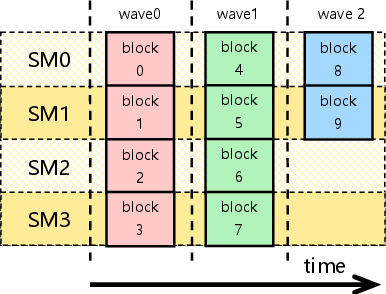
Figure 2: Illustration of the wave quantization effect where underutilized final waves emerge.
Empirical results demonstrate that real GPU kernel latency transitions from step-like to linear with increasing grid size, showing strong intra-wave bilinear trends and phase shifts at wave boundaries.
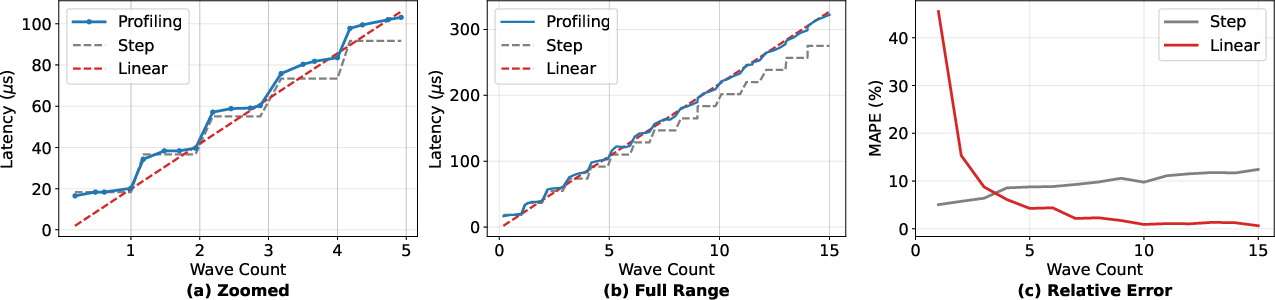
Figure 3: Measured GEMM latencies on an H100, highlighting model fit in small- and large-wave regimes.
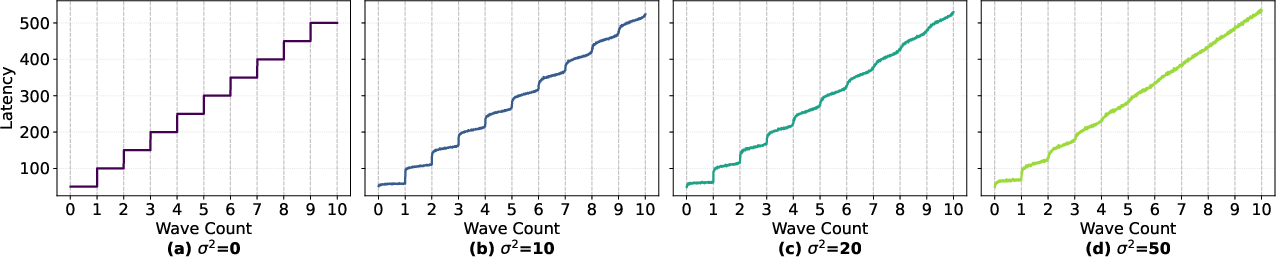
Figure 4: Simulation confirms that increasing intra-block variance desynchronizes execution, smoothing stepwise behavior into an asymptotic linear regime.
This hybrid effect—the coexistence of discrete, hardware-induced boundaries and continuous workload scaling—demands a formulation that can capture local, wave-conditioned bilinearities with high fidelity while preserving scalability and universality across workloads and hardware.
Analytical Bilinear Modeling and Abstractions
WaveTune conceptualizes kernel configuration as a two-level optimization problem, mapping logical input shapes to physical grid/loop coordinates (G,L) and decomposing configuration space into macro- (tile geometry) and micro-level (inner-block execution) parameters. Profiling and offline model fitting are stratified by wave count, yielding coefficients for the bilinear predictor in each regime:
T(G,L)≈αGL+βG+γL+δ
where α captures the dominant aggregate workload term, while β and γ model resource-specific scheduling and loop overheads. This model covers both the early quantized (small-wave) and throughput-bound (large-grid, large-wave) settings, with extrapolation modules for out-of-profile scenarios.
Sparse Structural Profiling and Runtime System
Instead of a dense, intractable sweep of all input-shape and config combinations, profiling is performed at selected anchor points in (G,L), covering different wave regimes and canonical loop counts. For each macro-config and wave regime, the optimal micro-config is cached. At runtime, configuration proceeds in two stages: (i) rapid model-based selection of the best macro-config via latency prediction, and (ii) nearest-loop-anchor retrieval of the corresponding micro-config.
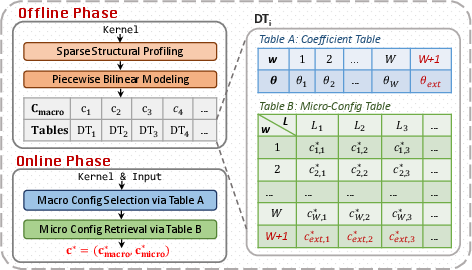
Figure 5: Overview of the WaveTune framework with dual-table coefficient and micro-config artifacts.
This ensures O(1) runtime configuration complexity, replacing millisecond-scale online cost model inference with microsecond-scale table lookups.
Experimental Results
Evaluation is conducted across three representative kernels (Dense GEMM, Grouped GEMM, FlashAttention) and five data-center GPUs, covering both NVIDIA and AMD architectures.
Kernel-level Speedup
WaveTune consistently achieves near-oracle kernel-level speedup (1.83× on FlashAttention, 1.27× on Grouped GEMM, and 1.04× on Dense GEMM), outperforming both learned cost models and data-driven dispatch baselines, which demonstrate strong instability and sometimes substantial regression when workload or hardware varies.
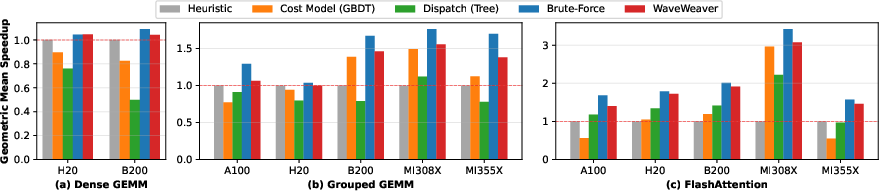
Figure 6: Kernel-level geometric mean speedup; WaveTune universally approaches oracle performance.
WaveTune’s performance stability is especially notable in cases with high workload dynamism (e.g., Grouped GEMM for MoE with unpredictable token routing), where ML-based alternatives deteriorate and expert heuristics generalize poorly.
End-to-end Latency and TTFT Reduction
When integrated into production inference stacks (e.g., SGLang with Qwen3-30B), WaveTune enables up to 1.33T(G,L)≈αGL+βG+γL+δ0 reduction in end-to-end time-to-first-token (TTFT) during the compute-dominated prefill phase, all with negligible configuration latency (5–6 μs).
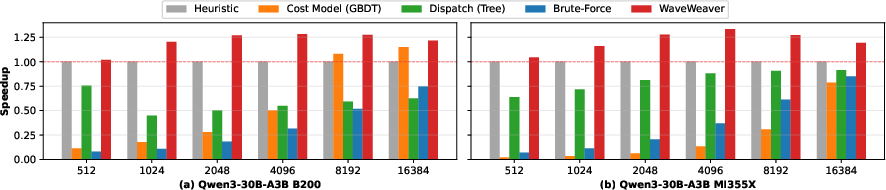
Figure 7: End-to-end TTFT speedup under variable input lengths, demonstrating persistent gains.
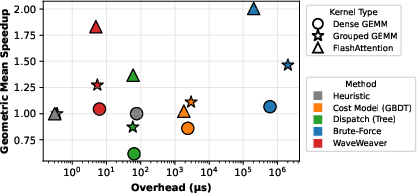
Figure 8: Pareto analysis of runtime decision overhead versus speedup; WaveTune uniquely occupies the high-speedup, low-overhead regime.
Ablations and Scalability
Ablation studies confirm that the combination of wave-aware partitioning and local bilinear modeling is essential: stepwise or global-linear variants yield significantly degraded speedup and less robust performance, especially in low-occupancy or highly variable input regions.
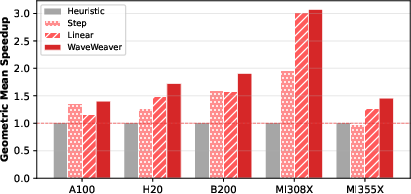
Figure 9: Ablation results on FlashAttention verify the full model’s superiority.
Profiling range analysis further indicates that sparse coverage suffices, as the extrapolation mechanism maintains model accuracy in both process and memory throughput regimes.
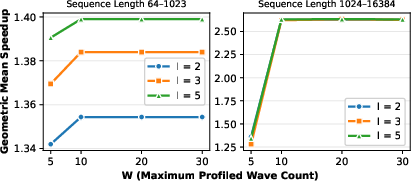
Figure 10: Performance impact as a function of profiling range T(G,L)≈αGL+βG+γL+δ1; high fidelity is sustained with modest profiling effort.
Practical and Theoretical Implications
On the practical side, WaveTune provides a deployable path for high-performance GPU kernel auto-tuning in online and dynamic LLM inference systems, effectively decoupling configuration quality from runtime cost. Its dual-table architecture naturally accommodates new kernels or hardware with minimal retraining/reprofiling, supports rapid deployment on unseen input regimes, and is robust to both hardware and workload heterogeneity.
Theoretically, WaveTune demonstrates the utility of integrating physical execution priors—specifically, wave and occupancy constraints—with lightweight parametric modeling. This structure-aware analytical modeling bridges the classical divide between mechanistic simulation and high-capacity black-box regression, establishing a scalable, interpretable approach with strong extrapolative properties.
Future Developments
Given the clear correspondence between physical execution artifacts and the bilinear model structure, future research may extend WaveTune to:
- Unified modeling across more diverse hardware, including multi-tenant or multi-GPU contexts.
- More sophisticated micro-config optimization within block-local scheduling and occupancy models.
- Coupling with higher-order compiler-level optimizations (e.g., fusion autotuning, L2 cache partitioning).
- Extension to end-to-end system co-design, integrating scheduling and prefetching strategies for multi-kernel workload graphs.
Conclusion
WaveTune represents a robust and practically deployable solution for runtime GPU kernel configuration in LLM inference, resolving the longstanding trade-off between generality, decision overhead, and empirical optimality. Its wave-conditioned, bilinear analytical modeling approach is well-grounded in hardware execution dynamics, enabling model-based configuration with negligible latency and significant performance gains in modern inference systems (2604.10187).