- The paper proposes BWTA by using binary weights and ternary activations to preserve zero-point and reduce quantization error in Transformers.
- It introduces a smooth multi-stage quantization strategy with levelwise degradation and magnitude alignment to stabilize training and maintain accuracy.
- The study integrates custom CUDA kernels for optimized GPU inference, achieving significant speedups (up to 24×) compared to standard FP16 implementations.
Introduction and Rationale
Ultra-low-bit quantization of Transformer-based models delivers substantial improvements in computational throughput and storage efficiency. However, extreme quantization, such as binarization, has historically led to significant accuracy degradation and poor model convergence, especially in large-scale NLP tasks. In addition, existing ultra-low-bit techniques are typically limited by a lack of GPU system support, restricting their practical deployment. "BWTA: Accurate and Efficient Binarized Transformer by Algorithm-Hardware Co-design" (2604.03957) addresses these core challenges via a joint algorithmic and hardware co-design strategy, introducing the Binary Weight Ternary Activation (BWTA) framework.
The BWTA scheme utilizes binarized weights (±1) and ternarized activations (−1,0,1), enabling ultra-low-bitwidth Transformer inference while specifically resolving the zeropoint distortion that impairs conventional full binarization. The framework includes a Smooth Multi-stage Quantization training paradigm that ensures stable optimization, and a custom CUDA MatMul kernel with instruction-level parallel bitpacking, achieving both algorithmic accuracy and realistic GPU-level speedup.
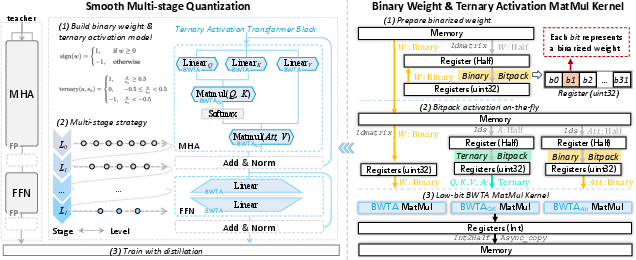
Figure 1: The BWTA framework comprises smooth multi-stage quantized training (left) and a full-stack custom CUDA kernel for fast binary/ternary GEMM on GPUs (right).
Zeropoint Distortion and Motivation for Ternary Activation
Attention probabilities in Transformers, derived via softmax, are typically distributed with most values near zero. Binarizing activations (with functions such as sign or bool) creates a hard split, losing the ability to represent small values and introducing high quantization error—especially by eliminating the zero point, which acts as a projection target for small-magnitude activations. Empirical analysis in the paper demonstrates that, as training progresses, binarized activations abruptly discard the representation of zeros, fragmenting the activation distribution and worsening convergence.
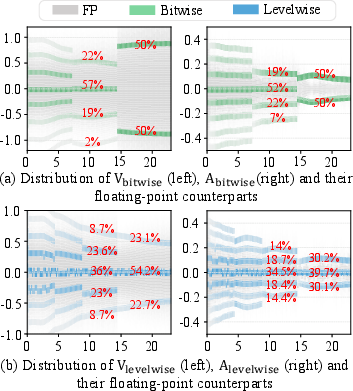
Figure 2: Histograms illustrate how bitwise (binarized) quantization removes the zero bin, while levelwise (ternary) quantization maintains a centered, balanced distribution.
Analytical and empirical support confirm that ternary quantization, which retains the zero value in the set, allows for consistent projection of small activations and preserves the statistical structure of activations throughout training. This insight motivates the BWTA paradigm, using binary weights and ternary activations.
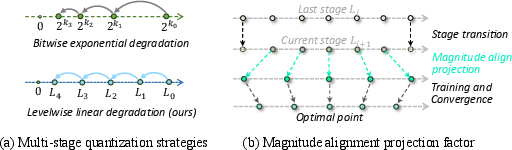
Smooth Multi-Stage Quantization: Stabilizing Training
Directly training with ultra-low-bit activations is unstable due to abrupt contractions of the representational space. To resolve this, the proposed Smooth Multi-stage Quantization progressively transitions the representation, combining two central concepts:
Empirical ablations demonstrate that levelwise strategies avoid the sharp accuracy loss and oscillations seen with bitwise quantization. The projection factor further accelerates convergence after each stage transition.
Algorithm-Hardware Co-Design: Fast Inference with Custom CUDA Kernels
The BWTA framework is realized in deployment through a full-stack custom CUDA MatMul kernel. Key features include:
- Instruction-Level Parallel Bitpack: Floating-point tensors are packed into binary/ternary bitstreams on-the-fly, with grouping and sign extraction optimized for warp- and thread-level GPU computation.
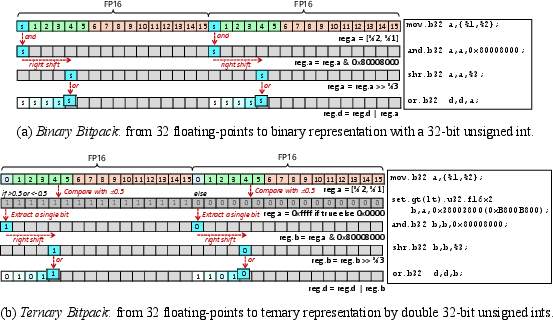
Figure 4: Efficient, SIMD-aligned bitpacking converts blocks of FP16 values to packed binary or ternary representations for register-level processing.
- Customized GEMM and Attention Ops: The kernel implements variants for linear, attention-score/value, and QK (query/key) multiplications, carefully mapping logical combination and accumulation rules to CUDA’s MMA tile instructions.
- Efficient Data Layout and Thread Allocation: Data is structured in layouts (e.g., m8n8k128) to maximize device throughput, with simultaneous storage and computation for weights and activations.
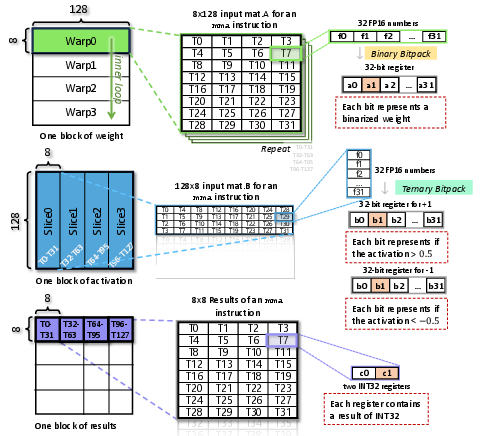
Figure 5: Data allocation across SIMT threads and registers is tightly packed for ultra-low-bit GEMM.
- Instruction/Arithmetic Rule Mapping: Matrix multiplication of binary and ternary matrices is realized via combinations of logical gates and population counts, minimizing the instruction count.
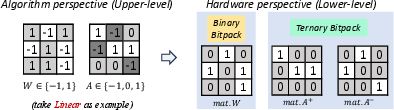
Figure 6: Mapping from high-level BWTA quantization rules to hardware-level bitwise and arithmetic implementations.
This allows BWTA layers to execute as drop-in replacements for FP16/BF16 linear/attention layers, enabling true end-to-end low-latency inference on commodity GPUs.
Experimental Results and Ablations
BWTA achieves strong results on both BERT-scale and LLM-scale Transformers, with extensive empirical substantiation:
- On BERT (GLUE benchmark): BWTA with $1$-bit weights and $1.5$-bit activations achieves an average drop of only −3.5% from full-precision, with less than 2% loss on five out of eight tasks—significantly outperforming prior art among binary/ternary methods.
- On LLMs (e.g., Bitnet, Llama-2, OPT): Replacement of even a minority of layers with BWTA modules yields negligible perplexity/accuracy degradation compared to higher-bit quantization, but delivers 216–330 tokens/sec prefill throughput and 12–15 tokens/sec decode speedup on 2B–3B parameter models.
Kernel-level benchmarks demonstrate 16–24−1,0,10 speedup over FP16 kernels, and the method supports both linear and attention pathways. Ablations on Smooth Multi-stage Quantization show that levelwise strategies and projection factors yield faster, more robust convergence and improved final task loss compared to bitwise approaches.
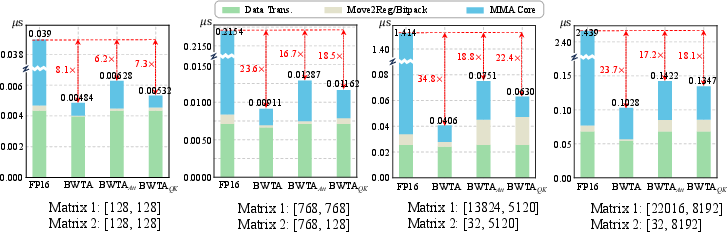
Figure 7: Timing breakdowns for GEMM kernels illustrate MMA core dominance and the large advantage of the BWTA kernel for large-dimension operations.
Convergence diagnostics—including scaling factor statistics and gradient evolution—confirm that BWTA mitigates typical divergence and oscillation behaviors seen in low-bit training.
Implications, Limitations, and Future Outlook
The results presented in this study demonstrate that ultra-low-bitwidth quantization can be made practical for real-world Transformer inference on GPUs, without the typical accuracy compromise or the need for specialized hardware. The proposed smooth quantization training framework and hardware-conscious kernel can be integrated with existing toolchains, extending deployment feasibility to both cloud and edge inference.
Notably, the preservation of centered ternary activations addresses a key historical bottleneck—zeropoint distortion—and may inform further advancements in mixed-precision quantization and quantization-aware training methods.
Theoretical implications include:
- Enhanced understanding of the interplay between quantization distribution centering and convergence in high-depth architectures.
- The impact of quantization-stage granularity and scaling-factor alignment on training dynamics.
Practical implications include:
- Realization of transformer-scale binarized models deployable on off-the-shelf GPU infrastructure, reducing hardware cost and energy consumption for large-scale LLM inference.
- The technique’s compatibility with selective layer-wise application permits application-dependent trade-offs between model quality and inference speed/memory.
Future directions include adapting BWTA principles to other architectures (e.g., multimodal, vision, or audio Transformers), exploration on CPU/FPGA/ASIC platforms, and expansion to end-to-end integer quantization (e.g., low-bit nonlinearities and tokenizers) where hardware permits.
Conclusion
The BWTA framework substantiates that algorithm-hardware co-design enables accurate, stable, and exceptionally efficient binarized Transformers. By coupling ternary activation quantization with smooth multi-stage training and a high-throughput GPU kernel, the method achieves state-of-the-art accuracy at ultra-low bitwidths, robust training convergence, and substantial inference acceleration. These findings establish a foundation for practical deployment of low-bit Transformers and stimulate further investigation into scalable quantization strategies for advanced deep learning workloads.