- The paper introduces the ACMG framework to improve depression detection by adaptively gating modality-specific cues that address the sparsity of clinical signals.
- It leverages dual-branch pipelines with frozen pre-trained encoders and cross-modal attention, yielding a 1.47% and 4.04% performance gain over baselines.
- Results on PDCD2025 and DAIC-WOZ datasets demonstrate enhanced accuracy and interpretability, underscoring the framework's potential for clinical diagnostics.
Adaptive Cross-Modal Gating for Depression Detection: Technical Assessment
Introduction
The task of detecting depression from speech is an emergent and clinically significant direction in affective computing. The paper "Learning to Attend to Depression-Related Patterns: An Adaptive Cross-Modal Gating Network for Depression Detection" (2604.10181) advances this area by introducing a new framework, Adaptive Cross-Modal Gating (ACMG), explicitly designed to model the sparsity of depression-related cues in acoustic and textual streams. This essay analyzes the system’s architecture, experimental findings, and implications for robust multimodal mental health assessment.
Problem Motivation and Background
Speech contains multidimensional markers of depressive states distributed across acoustic (prosodic, paralinguistic) and textual (semantic, affective) channels. However, depression-associated signatures in both modalities exhibit marked sparsity—manifesting in localized segments of an utterance rather than pervasively. Prevailing multimodal models and simple aggregation strategies (e.g., global average pooling) overlook this sparsity, which can lead to diminished sensitivity to diagnostic cues. The ACMG framework provides a principled approach to addressing this challenge, adaptively refining frame- and token-level representations to align with clinical salience, not uniform feature relevance.
ACMG Architecture and Mechanisms
The ACMG network adopts a dual-branch pipeline for acoustic and textual modalities, employing frozen, pre-trained encoders—HuBERT for speech and Qwen-Embedding-0.6B for language. Acoustic frames and ASR-derived transcript tokens are embedded into sequence representations. The system’s differentiator is its explicit Adaptive Cross-Modal Gating module.
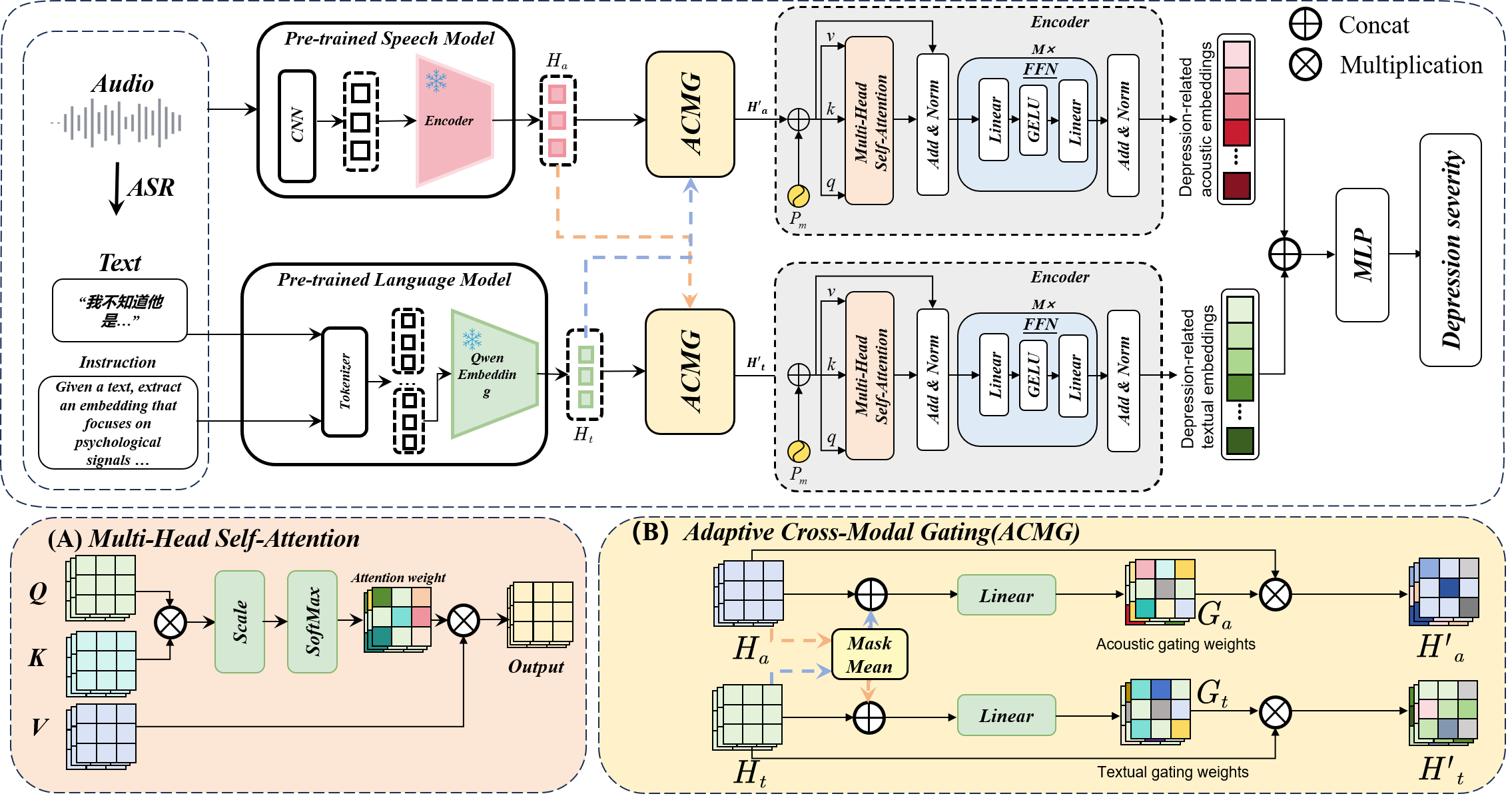
Figure 1: Overall ACMG framework integrating Multi-Head Attention and ACMG modules for adaptive feature selection across modalities.
The ACMG module operates by extracting global context vectors for each modality and leveraging these for the computation of gating weights:
- Global Context Extraction: Through masked mean pooling, the model calculates non-padding-aware global representations for both modalities, dynamically accommodating variable sequence lengths.
- Adaptive Gating: The module supports both unimodal (modality-self-guided) and cross-modal (modality-other-guided) gating. In cross-modal gating, for instance, the global textual context modulates framewise acoustic weights, enabling semantic information to drive acoustic attention, and vice versa.
- Frame/Token Refinement: The computed gating weights are applied multiplicatively to the feature sequences, allowing dynamic attenuation or amplification of frames/tokens based on their hypothesized diagnostic value.
Notably, the ACMG design enables cross-modal enhancement—for example, linking flattened intonation co-occurring with negative self-referential expressions—rather than independent feature selection.
Experimental Evaluation
Datasets and Training Protocol
Evaluation is conducted on both the PDCD2025 corpus (Chinese telephone counseling, three-way labels: Healthy, Mild, Moderate) and the English DAIC-WOZ benchmark (PHQ-8, binary labeling). Baselines include strong sequence-based multimodal systems and state-of-the-art pre-trained model backbones, ensuring robust comparative analysis.
Quantitative Results
Across all splits and both corpora, ACMG equipped models consistently outperform baselines. The cross-modal gating configuration yields clear improvements:
- PDCD2025: The optimal ACMG model (Qwen-Embedding + cross-modal gating) achieves 81.25% accuracy, a 1.47% absolute increase over the state-of-the-art [Table 1 in the source paper].
- DAIC-WOZ: The system attains a validated F1 score of 69.39%, surpassing both previous multimodal fusion architectures and recent transformer-based pipelines.
These numerical findings strongly support the claim that adaptive gating and explicit multimodal interaction produce more clinically relevant depression detectors.
Instruction-Guided Language Modeling
Another salient finding is the superiority of instruction-aware LLMs (Qwen-Embedding) over general-purpose LLMs (e.g., RoBERTa) in extracting depression-sensitive semantics. This is demonstrated by a 4.04% absolute gain on PDCD2025, suggesting that controllable representations induced by downstream task instructions provide substantial benefit for subtle affective analysis.
Analyses of the Gating Mechanism
To substantiate the interpretability and clinical meaningfulness of ACMG’s attention mechanisms, the authors provide both quantitative and visual analyses.
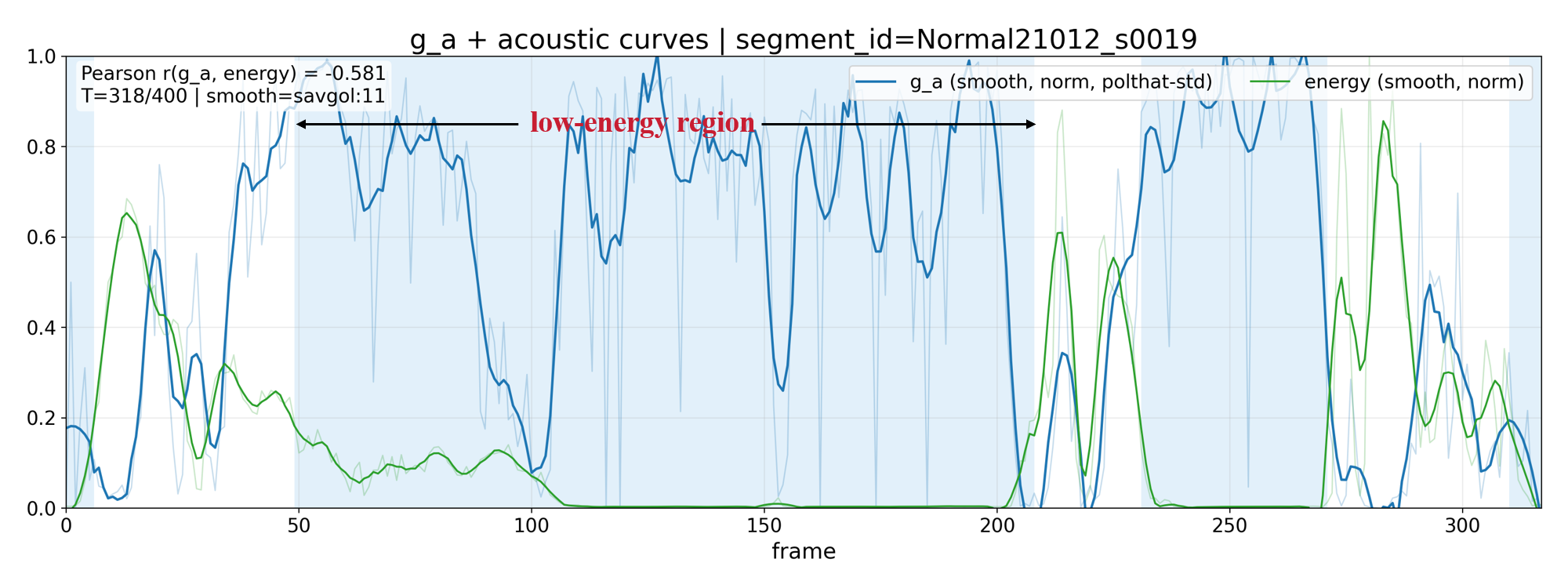
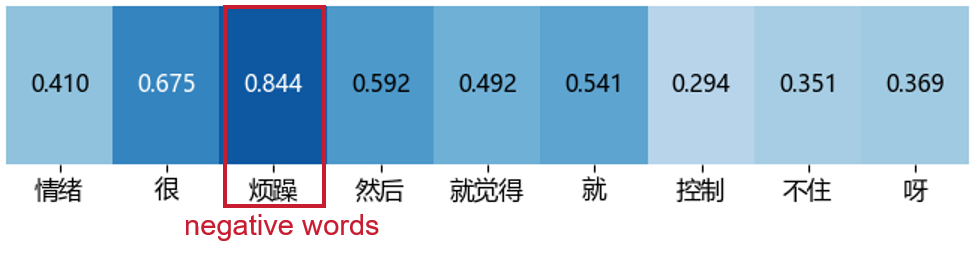
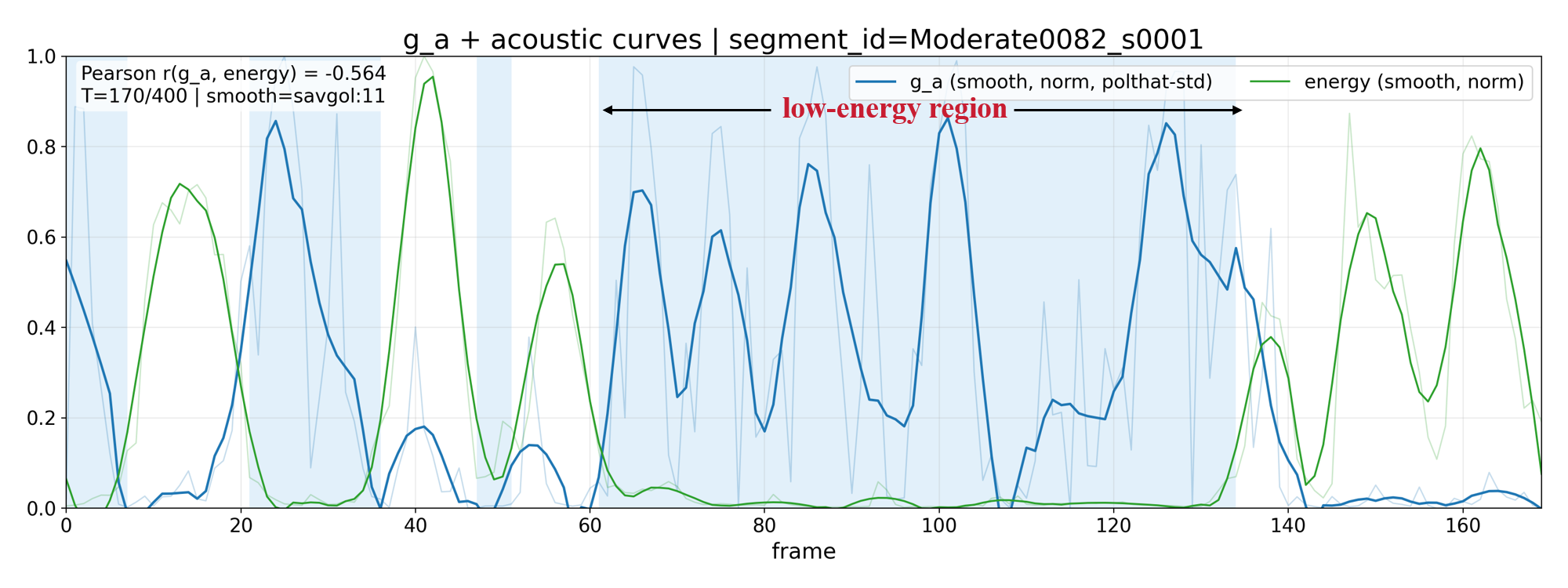
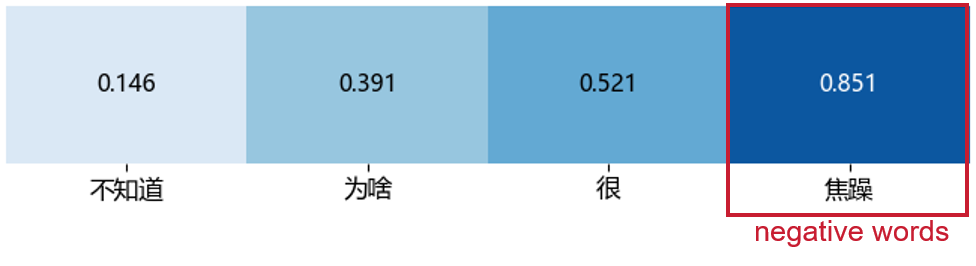
Figure 2: Visualization of gating weights—curves and heatmaps demonstrate adaptive selection of low-energy acoustic regions and negative sentiment words in transcripts.
- Acoustic Modality: Gating weights show a strong negative correlation (−0.329 overall) with speech energy, indicating a systematic emphasis on low-energy regions typified by lengthened pauses and flat prosody—established acoustic markers of depression. The effect amplifies with increasing severity, confirming the system’s adaptive focus as depressive symptoms intensify.
- Textual Modality: Gating visualizations expose selective amplification of tokens expressing negative affect, self-referential language, and other depression-linked psycholinguistic features. Neutral or content-irrelevant tokens are downweighted, aligning the model’s attention patterns with clinical linguistic findings.
These multimodal gating behaviors validate the technical premise of ACMG and its potential for model transparency, a critical aspect for medical AI tools.
Theoretical and Practical Implications
The ACMG mechanism concretely demonstrates that structured, cross-modal attentional gating outperforms uniform aggregation or independent within-modality attention, especially in sparse-label affective tasks. This approach encourages future research in:
- Generalization to Other Sparse-Label Settings: The gating paradigm could be extended to domains such as anxiety, bipolar disorder, or neurodegenerative diseases, leveraging modality-specific and cross-modal priors.
- Instruction-Aware Representation Learning: The effectiveness of Qwen-Embedding in this context underscores the broader utility of instruction conditioning for clinical NLP.
- Interpretability: The fine-grained gating visualizations support post-hoc model explanation, which is indispensable for deploying mental health AI in high-stakes environments.
Practically, ACMG lays groundwork for more precise, scalable, and transparent digital diagnostic tools for depression and, by extension, other psychiatric conditions.
Conclusion
The proposed ACMG network constitutes a rigorous approach to multimodal depression detection, incorporating cross-modal gating mechanisms to address the sparsity and locality of clinically relevant information in spoken interactions. Empirical advances are demonstrated through robust performance improvements on diverse datasets, while interpretability analyses confirm that ACMG learns to attend to features substantiated by psychiatric literature. The system’s core architectural insights—cross-modal dynamic weighting and instruction-guided text encoding—hold considerable promise for future affective computing applications and transparent AI clinical decision support.