- The paper introduces MF-GCN, an innovative model that fuses tri-modal signals via multi-frequency graph convolution to enhance depression detection.
- It details a custom dataset of 103 subjects with synchronized eye-tracking, facial, and acoustic data, validated through psychiatrist consensus.
- Experimental outcomes show 96% sensitivity and a 0.94 F2-score, underscoring the model’s superior performance and robust cross-modal fusion.
Multi-Frequency Graph Convolutional Networks for Tri-Modal Depression Detection
Introduction and Background
Major depressive disorder (MDD) is a globally prevalent mental health condition with substantial personal and societal impacts. Traditional diagnostic protocols such as DSM-5 and PHQ-9, while foundational, introduce subjective bias and are often limited by cultural, linguistic, and practitioner variability. The paper "MF-GCN: A Multi-Frequency Graph Convolutional Network for Tri-Modal Depression Detection Using Eye-Tracking, Facial, and Acoustic Features" (2511.15675) advances automated, scalable, and objective clinical assessment through multimodal machine learning that integrates ocular, facial, and acoustic signals.
The authors address two deficits in the existing literature: (1) the lack of high-quality, trimodal datasets with psychiatrist-validated ground truth for depression severity, and (2) the limited expressive power of conventional graph-based multimodal architectures, which overwhelmingly rely on low-frequency relationships and ignore salient high-frequency spectral features crucial for discriminative tasks.
Dataset Construction and Experimental Protocol
A custom dataset was assembled comprising 103 subjects (PHQ-9 score range: 0–27) stratified across mild, moderate, and severe depression classes as validated by psychiatrist consensus. Data acquisition occurred at the National Institute of Mental Health and the University of Dhaka. Each subject contributed:
- Audio recordings (microphone-based during PHQ-9 interviews)
- Video capture of facial expressions (webcam-based)
- Eye-tracking logs (150 Hz gaze point tracker)
Ground truth is established via a two-stage clinical diagnosis protocol: preliminary screening by a clinical physiatrist, followed by PHQ-9 administration and confirmation by two psychiatrists.
The histogram in (Figure 1) demonstrates the broad PHQ-9 score distribution in this cohort, supporting effective stratification for supervised learning.
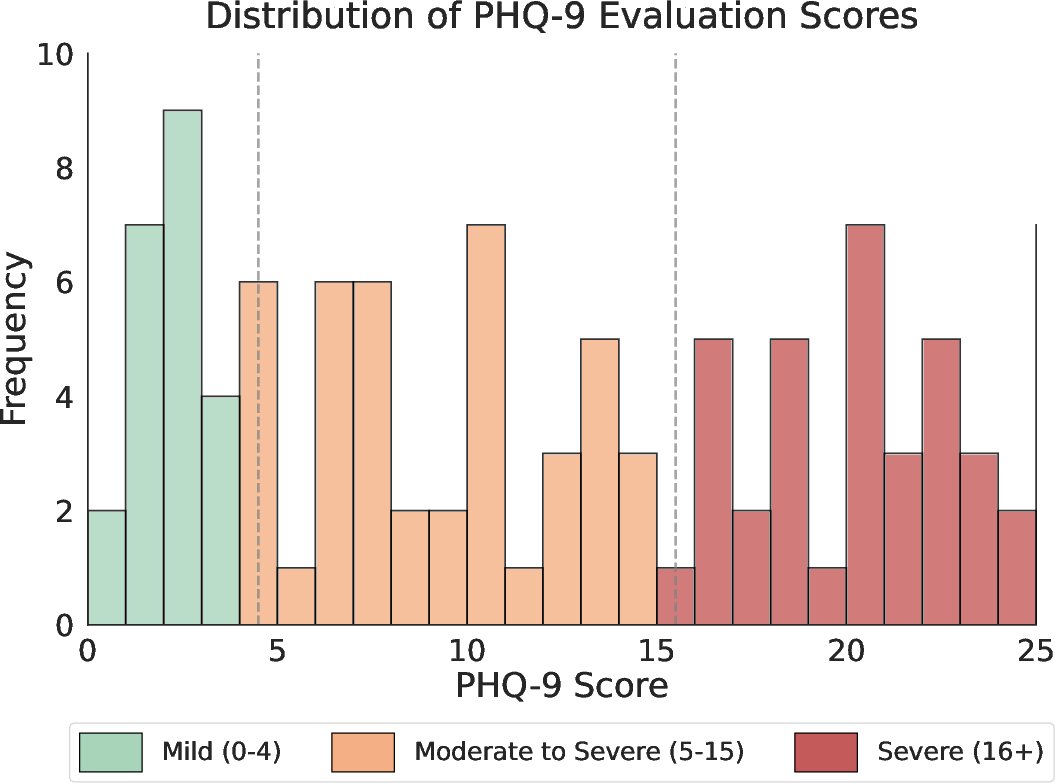
Figure 1: Histogram illustrating the distribution of Patient Health Questionnaire-9 (PHQ-9) scores among subjects.
Multimodal synchronization is ensured by the protocol illustrated in (Figure 2), covering session design, data quality control, and annotation procedures.
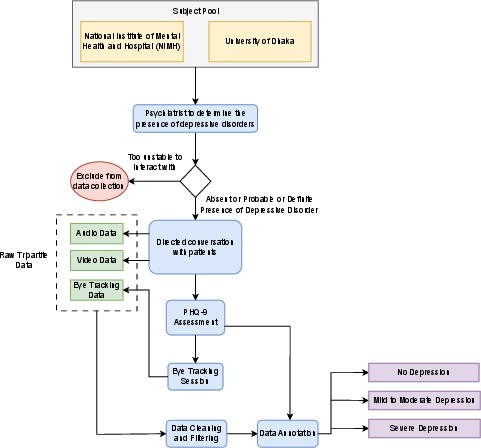
Figure 2: Workflow for synchronized collection and preprocessing of audio, video, and eye-tracking data at clinical sites.
Stimulus images (Figure 3) and the experimental setup (Figure 4) guarantee the elicitation of diverse affective responses and standardized data collection.

Figure 3: Triadic combinations of affective and neutral facial stimuli used during eye-tracking.
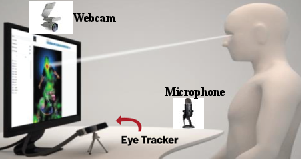
Figure 4: Integrated recording of facial expressions, audio responses, and gaze patterns during PHQ-9 administration and visual stimulus presentation.
Feature Extraction and Modality Analyses
Visual Saliency:
Eye-tracking saliency heatmaps reveal pronounced attentional biases associated with depression severity (Figure 5). Severely depressed subjects exhibit more focal, restricted gaze fixations, consistent with established models of negative emotional bias.
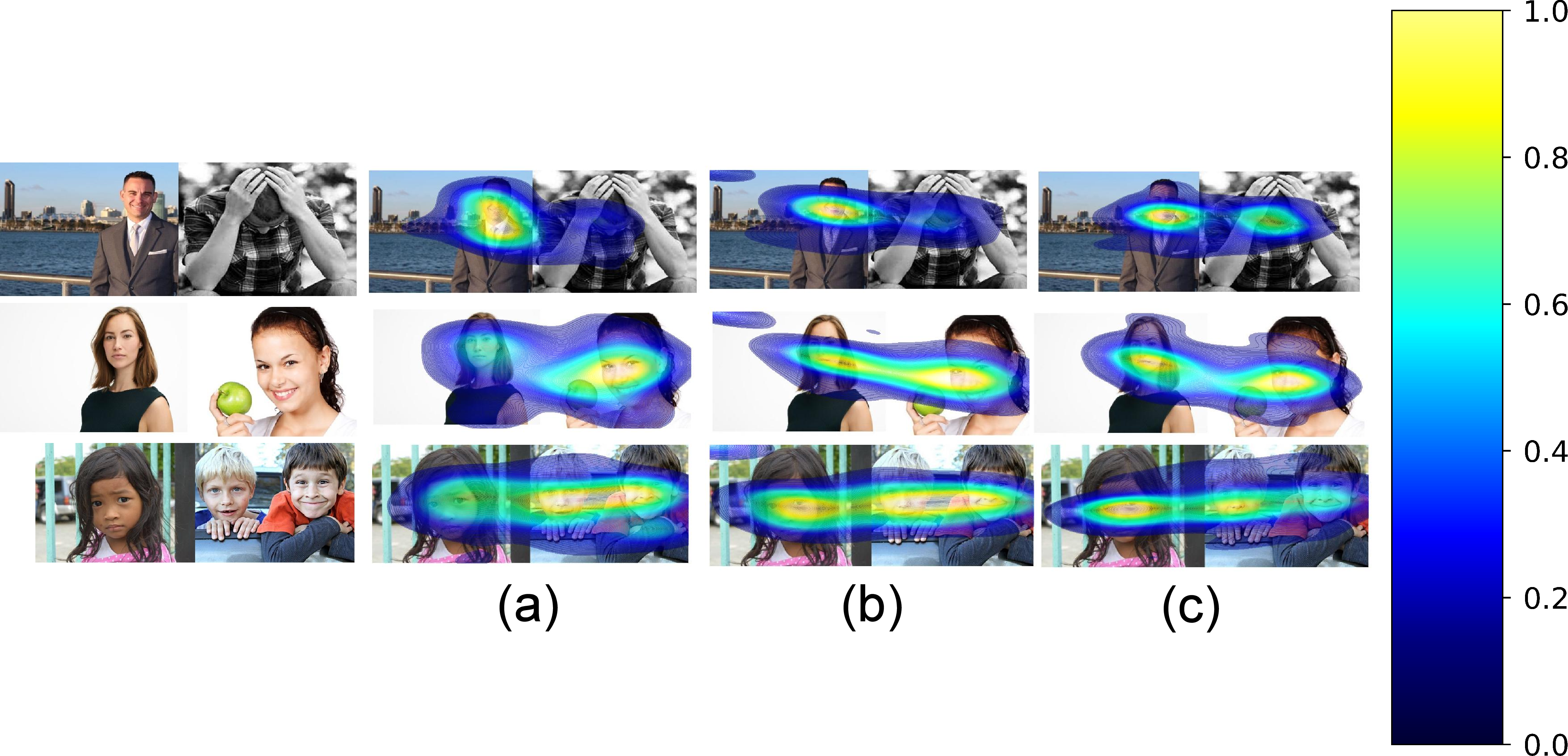
Figure 5: Saliency heatmaps distinguishing gaze fixation patterns across depression severity levels.
Facial Expression:
Automated facial emotion recognition (FER) extracts seven emotional dimensions from video frames using deep neural encoders. The authors report increased anger, fear, and sadness and decreased neutrality with rising depression severity, corroborating psychiatric literature on affective flattening and negative bias in MDD.
Acoustic Signal:
Speech is processed for both hand-crafted and deep spectral features. Low-level descriptors are supplemented by time-frequency representations such as chroma, Mel spectrograms, and MFCCs. Statistically significant increases in F0, loudness, HNR, F2, and spectral flux are observed in severely depressed subjects, whereas lower jitter and shimmer indicate a possible compensatory tension in speech production. The feature extraction pipeline is tailored for high-resolution retention suitable for deep learning.
Architecture: MF-GCN with Multi-Frequency Filter-Bank Module (MFFBM)
The proposed pipeline is an end-to-end system (Figure 6) that hierarchically fuses unimodal and cross-modal representations.
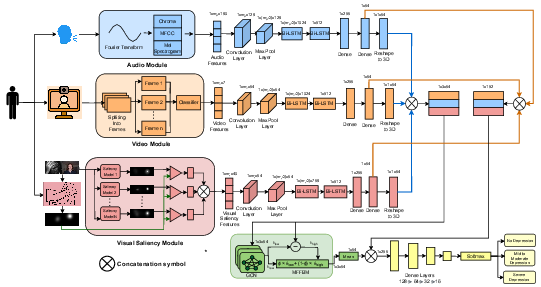
Figure 6: MF-GCN framework for parallel unimodal feature extraction and deep graph-based cross-modal fusion using MFFBM.
- Unimodal Stage: Convolutional and Bi-LSTM blocks produce 64-dimensional embeddings per modality (audio, video, visual saliency).
- Multimodal Stage: Modalities are modeled as nodes in a complete graph, with cross-modal interaction learned by a novel GCN block parameterized by the Multi-Frequency Filter-Bank Module (MFFBM). Unlike traditional GCNs, which emphasize low-frequency information, MFFBM fuses low- and high-frequency spectral responses, and theoretical analysis confirms arbitrary spectral filter expressivity.
The output of graph-based fusion is concatenated with unimodal embeddings and fed to a softmax classifier for multi-class depression detection.
Results
Experiments include binary and three-class depression classification tasks. MF-GCN outperforms seven standard machine learning baselines (DT, RF, SVM, XGBoost, KNN, NB, LR) as well as state-of-the-art multimodal deep learning frameworks (IIFDD, Transformer Self/Cross-Attention) on all primary metrics: sensitivity, specificity, F2-score, and precision.
In binary depression classification, MF-GCN achieves 96% sensitivity and 0.94 F2-score, indicating outstanding recall of clinically positive cases and minimal false negatives.
ROC analysis (Figure 7) reveals that MF-GCN achieves higher AUCs across all depression severity classes, with a robust generalization for minority classes and significantly greater discriminative power than competing baselines.
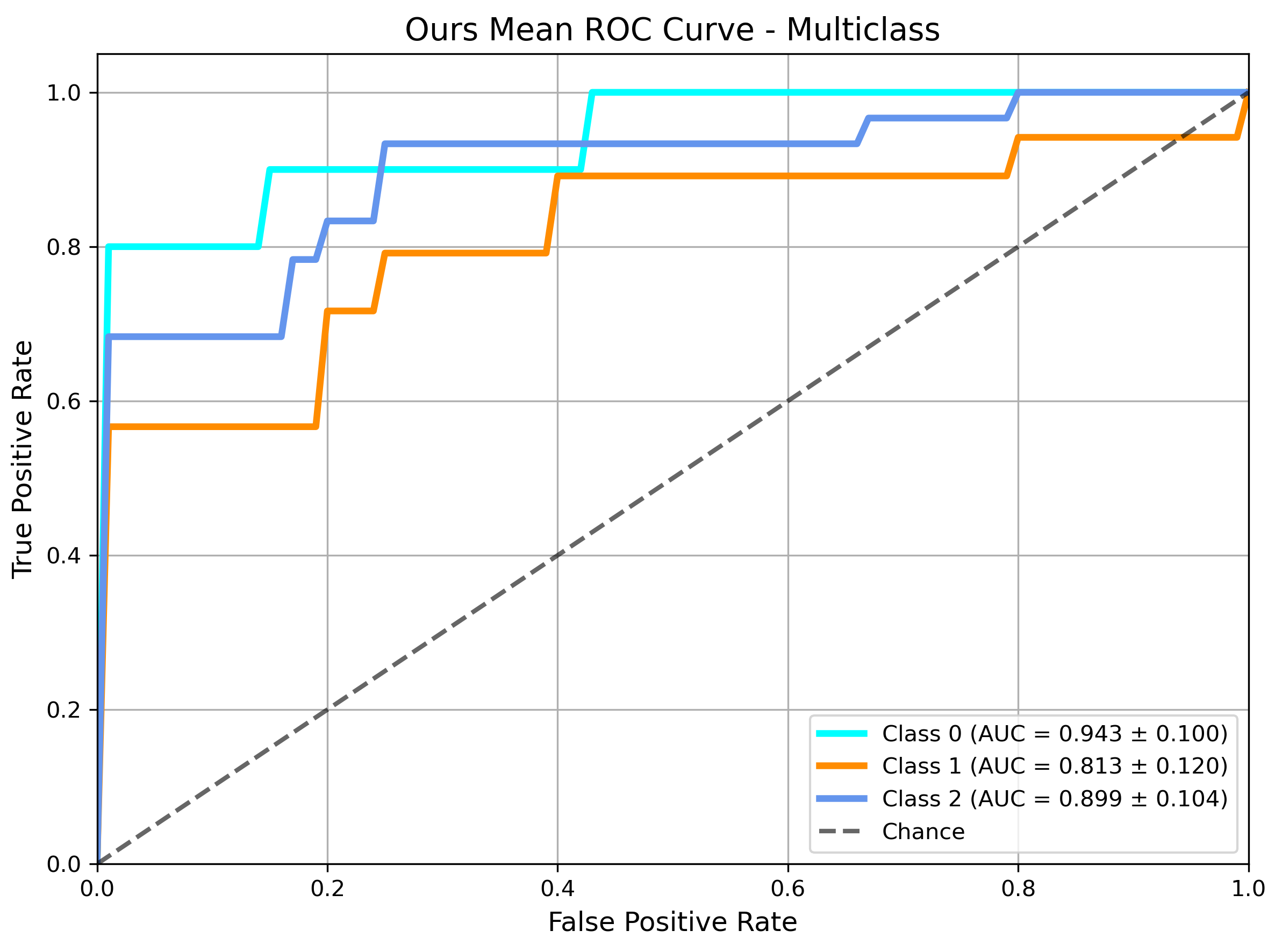
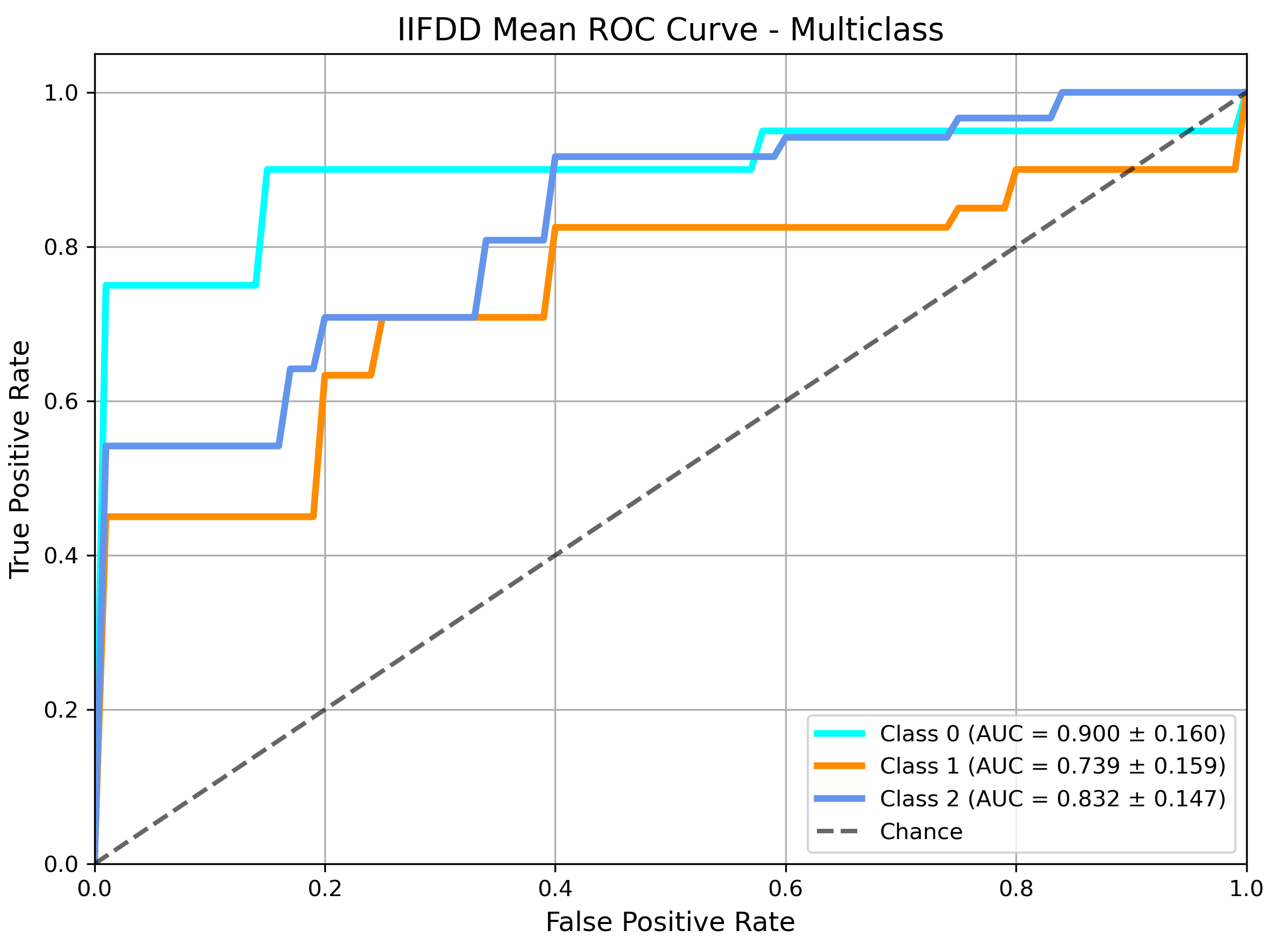
Figure 7: ROC curve analysis for multiclass depression classification using MF-GCN, highlighting discriminative performance.
An ablation study (Figure 8) demonstrates substantial ablation-induced drops in accuracy, recall, and F2 when cross-modal GCN fusion is removed, empirically validating the essential contribution of cross-modal learning and high-frequency spectral modeling.
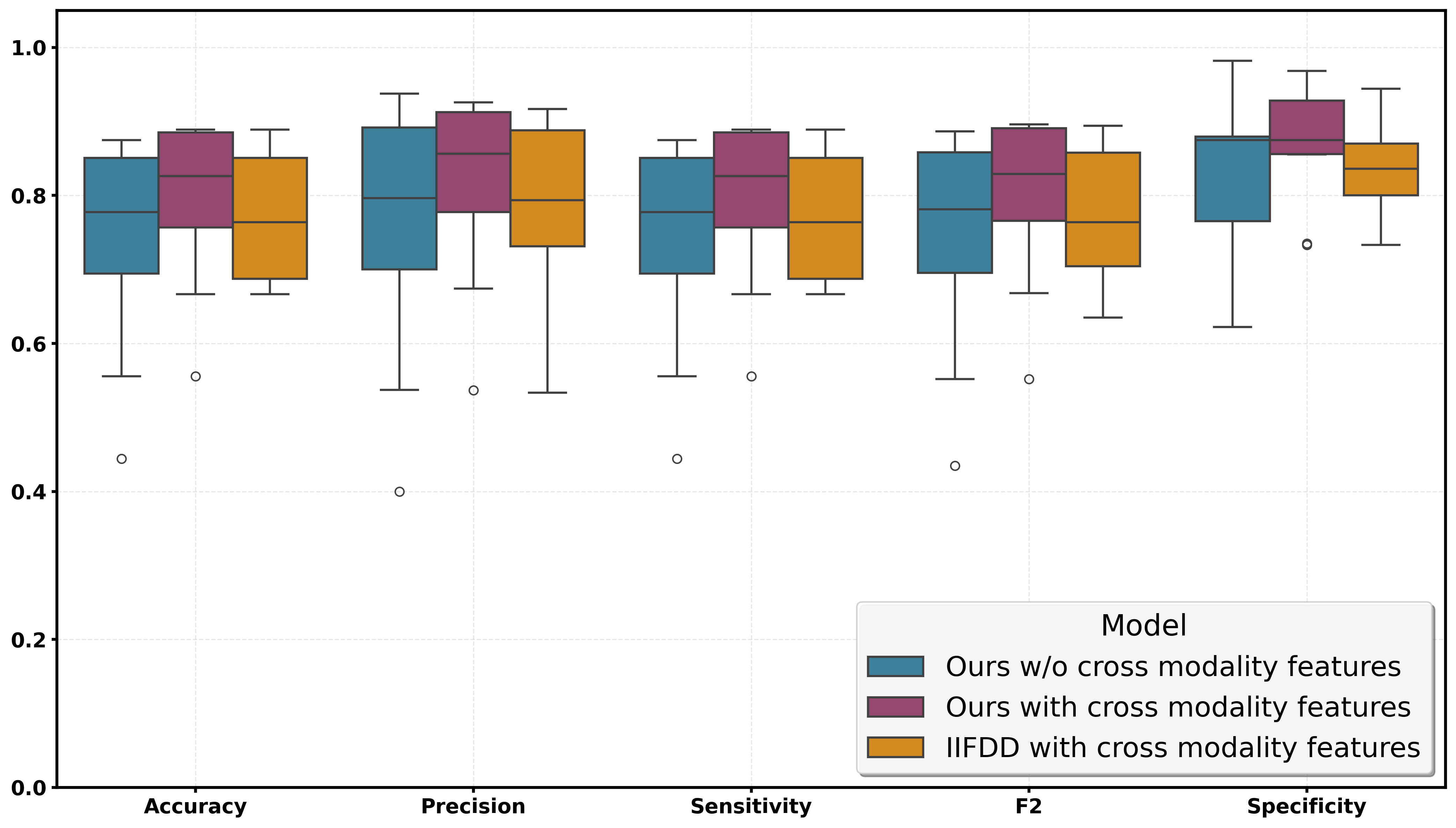
Figure 8: Comparative evaluation of model variants, quantifying the impact of cross-modal feature fusion.
Implications and Future Directions
The primary contributions include: (1) a validated trimodal dataset for depression detection, (2) empirical demonstration of saliency features enhancing multimodal performance by 19% in F2-score over unimodal baselines, and (3) theoretical and practical advances in spectral graph learning for clinical affective computing. The strong numerical results, notably in sensitivity and recall, make MF-GCN suitable for medical triage and mass mental health screening where type II errors carry significant clinical risk.
The proposal to learn arbitrary spectral graph filters has implications well beyond depression detection, suggesting new avenues for multimodal classification in other neuropsychiatric disorders or any domain where cross-modal high-frequency features are diagnostic. Further, integration with naturalistic mobile or wearable data streams, as well as adaptation to cross-cultural data, may yield scalable digital mental health tools.
Conclusion
This paper establishes a rigorous, robust framework for tri-modal depression detection based on spectral graph fusion of eye-tracking, facial, and acoustic features. The MF-GCN model with multi-frequency spectral filtering transcends limitations of conventional architectures and demonstrates superior quantitative performance across all critical severity strata. The methodology, dataset, and theoretical advances presented here form a strong foundation for future research in multimodal affective computing and clinical AI.