- The paper introduces a binary action space projection method to decouple temporal policy from semantic token generation in full-duplex SLMs.
- It employs rule-based rewards to optimize turn-taking, reducing interruptions and catastrophic repetition while maintaining semantic integrity.
- Experimental results demonstrate stable temporal policy learning with improved response latency and significant redundancy reduction.
ASPIRin: Decoupling Temporal Dynamics from Semantic Generation in Full-Duplex SLMs
Introduction
Full-duplex Speech LLMs (SLMs) have emerged as essential for achieving natural, real-time human-computer spoken interaction. Unlike half-duplex architectures, full-duplex SLMs are designed to process user speech streams and generate system responses simultaneously, thereby enabling interleaved speech, nuanced turn-taking, and low-latency backchannels. However, optimizing temporal behavior in these end-to-end systems presents a unique challenge: standard reinforcement learning (RL) paradigms that operate over fine-grained vocabulary tokens can degrade semantic quality, leading to generative collapse and catastrophic repetition.
ASPIRin ("Action Space Projection for Interactivity-Optimized Reinforcement Learning") (2604.10065) introduces a principled solution to this critical limitation. The framework decouples interaction timing ("when to speak") from semantic generation ("what to say") by projecting the action space from a large token vocabulary to a binary state space (active speech vs. inactive silence). This design isolates temporal policy optimization, resulting in stable, high-quality conversational dynamics without sacrificing semantic richness.
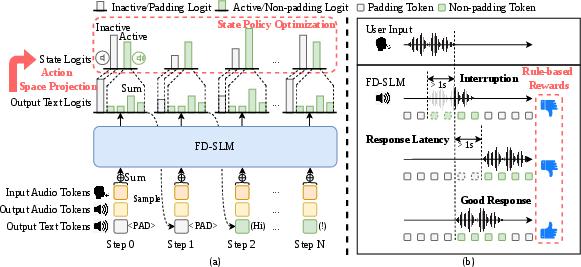
Figure 1: ASPIRin overview. (a) Action Space Projection projects token logits into a coarse binary state for active speech vs. silence, which is explicitly optimized. (b) Rule-based rewards derived from temporal constraints guide the state policy for interruption minimization and prompt responsiveness.
Action Space Projection and State Policy Optimization
The core innovation of ASPIRin is its action space projection mechanism. Within typical token-level RL for SLMs, both temporal and semantic objectives are entangled within the same policy, resulting in antagonistic gradients during optimization. ASPIRin resolves this by mapping each output token to a binary action: either "active speech" (non-padding) or "inactive silence" (padding token). Given a token sequence, the binary state at each timestep indicates the speech activity, agnostic to the precise semantic content.
For policy optimization, ASPIRin aggregates token logits across the two groups (padding/non-padding) to form logit aggregates for both states. These are then used for a binary state policy, optimized using Group Relative Policy Optimization (GRPO) with explicit advantage computation. This separation allows the system to focus all available model capacity on mastering temporal interaction dynamics, while the underlying LLM preserves semantic generation capabilities.
Rule-Based Reward Modeling
Temporal behavior in ASPIRin is guided by rule-based rewards constructed using ASR-aligned voice activity timestamps:
- Interruption Score: Penalizes model speech overlaps with the user, favoring non-interruptive turn-taking. An utterance is scored based on whether its overlap with user speech is below a predefined tolerance threshold.
- Response Score: Favors low-latency replies. The reward is the proportion of system utterances that start within an acceptable delay after the user's turn ends.
The combined reward is the product of the interruption and response components, with per-episode normalization for stability. By structuring rewards in this manner, the optimization targets conversational fluidity: minimizing interruptions and maximizing promptness without direct pressure on token-level semantics.
Experimental Design
ASPIRin and baselines are instantiated atop Moshi, a state-of-the-art full-duplex SLM. Training uses a dual-channel corpus of natural conversational speech, with temporal segmentation performed via highly accurate ASR. Evaluations are conducted on Full-Duplex-Bench, which decomposes interactivity into several dimensions: pause handling, backchanneling, turn-taking, and user interruption.
Key baselines include:
- Standard SFT: Supervised next-token fine-tuning.
- Standard GRPO: RL applied at the raw token level without action space projection.
- Moshi prompt-delay heuristic: A delayed response mechanism to reduce interruption.
Results
Quantitative evaluations demonstrate several robust findings:
- Superior Interactivity-Timing Tradeoffs: ASPIRin outperforms both SFT and token-level GRPO across diverse full-duplex scenarios, reducing unnecessary takeovers in pause and backchannel tasks and improving takeover rates in turn-taking and interruption settings.
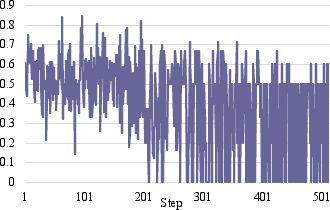
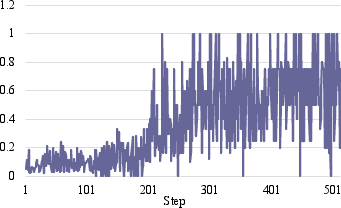
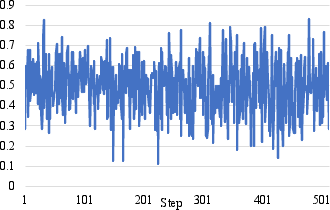
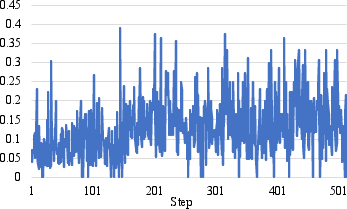
Figure 2: Interruption score trajectories for standard GRPO exhibit instability and decline, whereas ASPIRin maintains stable, high interruption scores throughout training.
- Stability in Temporal Policy Learning: As evidenced in Figure 2, ASPIRin's interruption score trajectory is consistently stable, while GRPO's fluctuates and degrades over time—an indication of reward hacking and degenerative behavior under token-level RL pressure.
- Semantic Integrity: ASPIRin eliminates the catastrophic repetition loops seen in standard GRPO, decreasing duplicate 2-gram and 3-gram occurrences by over 50%. This is reflected both in quantitative metrics (repetition rates, Self-BLEU) and qualitative examples, where ASPIRin-generated outputs remain coherent and contextually grounded, and GRPO/SFT degenerate into either semantic hallucination or meaningless repetition.
- Negligible Trade-offs: There is no significant degradation in GPT-4o-rated semantic quality for ASPIRin compared to the Moshi baseline, while latency and response appropriateness are improved or maintained.
Practical and Theoretical Implications
ASPIRin demonstrates that targeted action space design—transforming a large, entangled policy space into a minimal binary temporal policy—enables reliable and interpretable reinforcement learning for speech interaction timing in full-duplex SLMs. Practically, this implies that future conversational agents can be robustly aligned for real-time interactivity without the risk of semantic breakdown. Theoretically, it opens avenues for multi-factor reinforcement learning in generative systems, with modular policies for orthogonal dimensions (timing, semantics, affect, etc.).
Furthermore, the ASPIRin approach is orthogonal and complementary to advances in speech foundation models, large audio-LLMs, and hybrid preference optimization frameworks. Its composability suggests future research in multi-class or hierarchical projection schemes, permitting finer granularity controls (e.g., explicit backchannel classes, interruption diagnostics) and, potentially, a full orchestration of conversational moves beyond simple activity states.
Conclusion
ASPIRin presents an effective solution to the well-documented tension between temporal optimization and semantic generation in full-duplex SLMs (2604.10065). Through action space projection and targeted temporal reward structuring, it achieves stable, responsive, and semantically coherent conversational behaviors. The results indicate that careful architectural decoupling and reward shaping are essential for safe and effective RL-based alignment in generative dialogue systems. Future work will likely explore richer action projections and more sophisticated temporal-semantics decompositions to further close the gap to human-like conversational fluency.