- The paper introduces an enhanced linear attention mechanism using an affine kernel and L2 normalization to prevent over-smoothing.
- It shows that linear attention scales linearly with sequence length, drastically reducing computational costs compared to quadratic softmax methods.
- Empirical results on ViT models pretrained on LAION-400M reveal that linear attention achieves comparable final accuracy while adhering to established scaling laws.
Introduction
The quadratic complexity of standard softmax-based attention remains a critical bottleneck as multimodal transformers expand in model and data scale, especially for vision-language tasks that necessitate encoding high-dimensional inputs from both modalities. This paper investigates the viability and characteristics of Linear Attention (LA) as a replacement for softmax attention in large-scale multimodal Vision Transformers (ViTs). The analysis leverages pretraining on LAION-400M and zero-shot validation on ImageNet-21K, benchmarking several ViT configurations (ViT-S/16, ViT-B/16, ViT-L/16) to rigorously quantify scalability, expressivity, training dynamics, and accuracy scaling laws of LA as compared to standard attention.
Linear attention, as applied here, substitutes the softmax kernel in the attention function with a decomposable affine kernel f(x)=1+x, conferring computational complexity O(ND2) for sequence length N and head dimension D. To stabilize the kernel and guarantee non-negative attention scores, the query and key vectors are L2-normalized, bounding the attention scores within [−1,1]. The traditional normalization denominator, present in softmax-based and many linear attention variants, is omitted to circumvent attention score decay with increased sequence length—a phenomenon that otherwise induces an over-smoothing effect, reducing model capacity for salient feature identification and precise gradient flow.
As demonstrated in the following visual, this modification results in sharper, more discriminative attention matrices and mitigates the loss of effective expressivity observed with unmodified LA, especially for long-range dependencies.
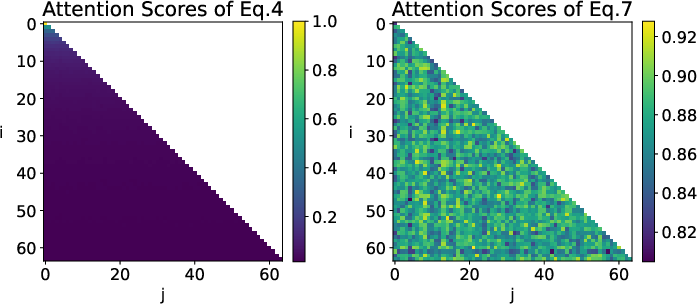
Figure 1: Heatmap visualization of attention scores aij, showing over-smoothing in conventional LA and clear token saliency with the proposed normalization-free variant.
Computational Efficiency and Runtime Scaling
One of LA's principal advantages is its linear time complexity with respect to sequence length, which drastically reduces both forward and backward pass time on modern accelerators. Profiling with H200 GPUs reveals that LA scales as O(N) compared to the O(N2) of standard attention, with savings becoming prominent at sequence lengths ≳103 tokens. At very large sequence lengths (O(ND2)0), LA exhibits up to three orders of magnitude lower runtime compared to optimized quadratic attention (FlashAttention-2), making it viable for extreme-scale multimodal settings.
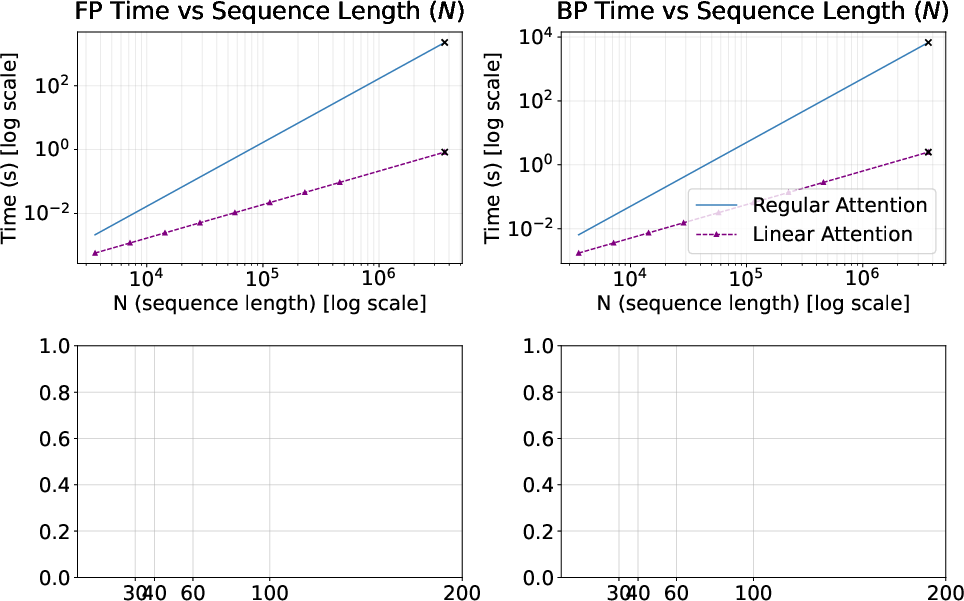
Figure 2: Forward and backward pass time per attention layer—LA achieves O(ND2)1 scaling versus O(ND2)2 for standard attention.
Training Dynamics and Accuracy
Pretraining ViT models with LA on LAION-400M reveals that, despite a slower nominal convergence (i.e., requiring more epochs to reach optimal accuracy), the final achieved performance closely matches that of models trained with softmax attention. This is consistent across model sizes, from ViT-S/16 (22M parameters) to ViT-L/16 (304M parameters). The proposed kernel and normalization improvements directly counteract convergence degradation previously observed with basic LA.
The key observations are:
- Convergence: LA models reach terminal validation accuracy nearly indistinguishable from softmax-based counterparts.
- Expressivity: While early training shows lag, the elimination of normalization-induced decay ensures the model does not suffer fundamental expressivity loss.
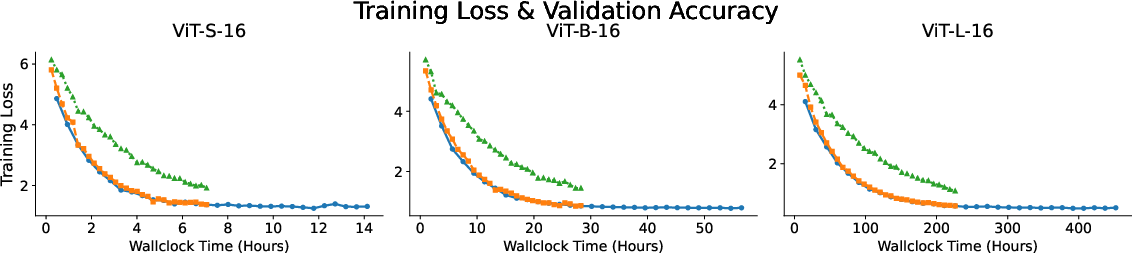
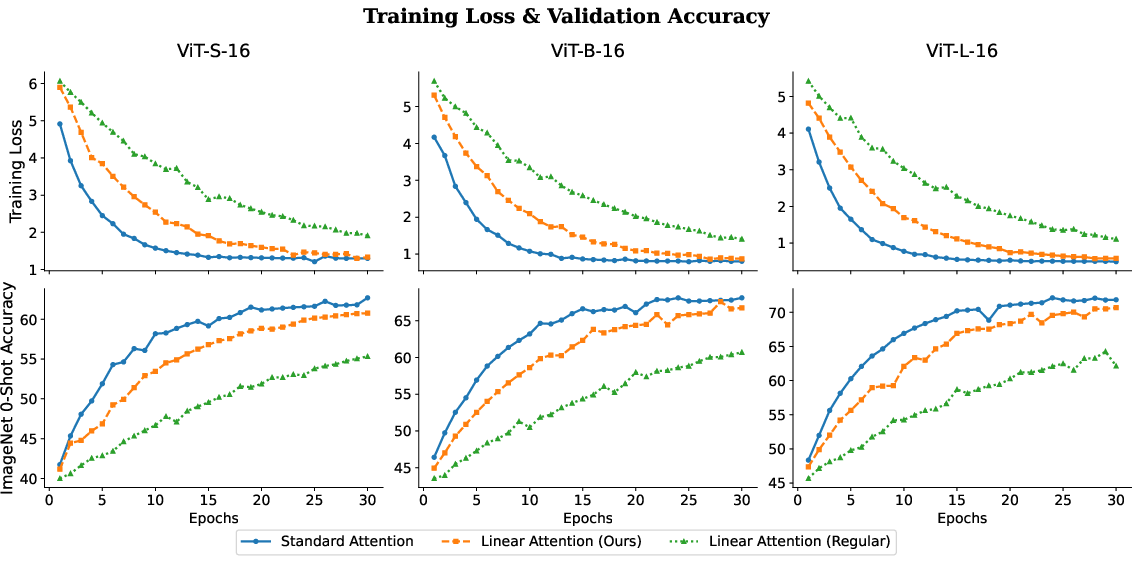
Figure 3: Training curves and per-epoch validation for different ViT variants show LA's comparable final accuracy to standard attention.
Scaling Laws: Model Size vs. Loss
A critical test for new attention mechanisms in large-scale modeling is adherence to established scaling laws. Both LA and softmax-based attention demonstrate empirical power-law loss scaling with respect to parameter count, O(ND2)3, with exponents and prefactors statistically similar between the two mechanisms. There is no evidence of loss floor elevation or anomalous scaling in LA, indicating that its use does not impede efficient utilization of additional model capacity.
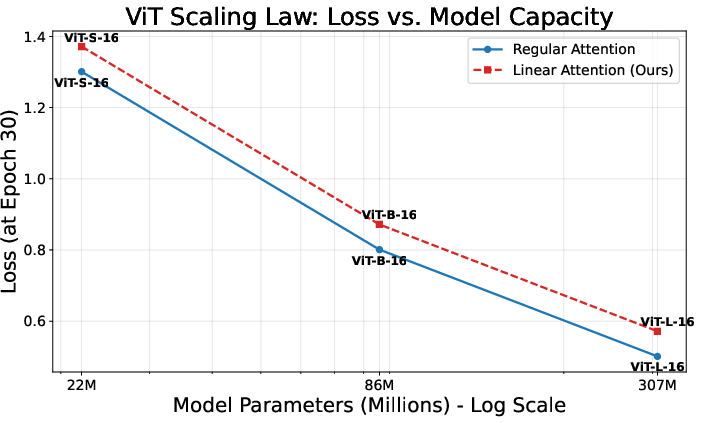
Figure 4: Training loss as a function of ViT model size on LAION-400M for standard and linear attention: both mechanisms follow nearly identical scaling laws.
Implications and Future Outlook
The paper's findings have substantial implications for the design and deployment of large-scale multimodal transformers:
- Practical Efficiency: Linear attention unlocks access to longer visual and textual contexts, previously infeasible under quadratic regimes, without substantive changes to model architecture or final achievable accuracy.
- Expressivity: Careful adjustment of the LA kernel and normalization strategies can prevent expressivity loss, a common concern in prior LA proposals for multimodal setups.
- Resource-Constrained Scaling: These efficiency gains can be directly traded for larger model sizes, finer input granularity, or deployment in latency-/memory-constrained environments, with potentially broader accessibility and application scope.
Theoretical work may further investigate kernel parameterizations that maintain sharp attention weights across modalities and better match softmax's selective focus, while empirical directions should target integration with emergent hardware features and compositional architectures (e.g., mixtures of sparse and linear attention, hierarchical fusion layers).
Conclusion
This study rigorously demonstrates that linear attention, when equipped with appropriate kernel and normalization modifications, can replace softmax attention in large multimodal transformers without sacrificing final performance or scaling efficiency (2604.10064). The effective removal of quadratic bottlenecks has practical and theoretical significance for the next generation of multimodal models, supporting their expansion to new domains and unprecedented input scales.