GIANTS: Generative Insight Anticipation from Scientific Literature
Abstract: Scientific breakthroughs often emerge from synthesizing prior ideas into novel contributions. While LMs show promise in scientific discovery, their ability to perform this targeted, literature-grounded synthesis remains underexplored. We introduce insight anticipation, a generation task in which a model predicts a downstream paper's core insight from its foundational parent papers. To evaluate this capability, we develop GiantsBench, a benchmark of 17k examples across eight scientific domains, where each example consists of a set of parent papers paired with the core insight of a downstream paper. We evaluate models using an LM judge that scores similarity between generated and ground-truth insights, and show that these similarity scores correlate with expert human ratings. Finally, we present GIANTS-4B, an LM trained via reinforcement learning (RL) to optimize insight anticipation using these similarity scores as a proxy reward. Despite its smaller open-source architecture, GIANTS-4B outperforms proprietary baselines and generalizes to unseen domains, achieving a 34% relative improvement in similarity score over gemini-3-pro. Human evaluations further show that GIANTS-4B produces insights that are more conceptually clear than those of the base model. In addition, SciJudge-30B, a third-party model trained to compare research abstracts by likely citation impact, predicts that insights generated by GIANTS-4B are more likely to lead to higher citations, preferring them over the base model in 68% of pairwise comparisons. We release our code, benchmark, and model to support future research in automated scientific discovery.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but powerful question: if you give an AI the “key ideas” from two earlier research papers, can it guess the main insight of a later paper that built on those two? The authors call this task “insight anticipation.” They also build a big test set (called GiantsBench) and train a new AI model (GIANTS-4B) to get better at this skill.
Think of it like this: two “parent” papers are like two Lego sets. A later “child” paper combines pieces from both to build something new. The AI’s job is to look at the two parent sets and describe what the child built.
What questions did the researchers ask?
- Can an AI read the summaries of two parent papers and predict the core idea (the main contribution) of a later paper that cites and combines them?
- How can we fairly measure whether the AI’s predicted insight matches the real, later paper’s insight?
- Can training the AI with feedback that rewards “good matches” make it better at this task?
- Will a model trained in one field (like language research) still work in other fields (like math or biology)?
How did they do it?
To make this work, the team created a new benchmark and a training approach:
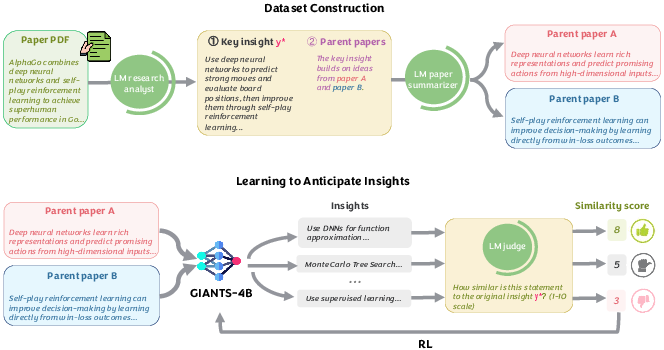
- GiantsBench: a large collection (about 17,000) of examples from eight scientific areas (like computer science, math, physics). Each example includes:
- Summaries of two parent papers.
- The “ground-truth” insight from a real downstream (later) paper that built on those parents.
- Insight: a short, clear sentence that states a paper’s main idea or advance. It’s like the headline result.
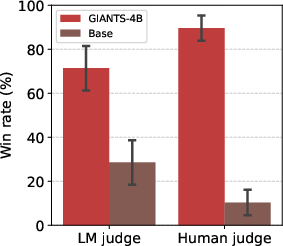
- How they measured success: They used an “AI judge” to compare the AI’s predicted insight with the real one and give a similarity score from 1 to 10. They checked that these AI-judge scores agree with human experts, and found a strong correlation (when humans said two insights were similar, the AI judge usually agreed).
- Training the model (GIANTS-4B):
- First, they tried normal fine-tuning (teaching the model to copy the correct answer from examples), with and without showing step-by-step reasoning.
- Then, they used reinforcement learning (RL), which is like training a player in a video game: the player (the AI) gets a score for its move (the insight it writes), and learns to make moves that earn higher scores next time.
- The “score” here is the similarity score from the AI judge. The training method (GRPO) improves the model by comparing a small group of its own answers and pushing it toward the better ones.
- To keep things fair, they used one AI judge during training and a different one for final evaluation—so the model couldn’t “cheat” by overfitting to a single judge.
- Testing for generalization: They trained on older papers and tested on newer, unseen papers. They also tested on fields the model wasn’t trained on.
What did they find, and why is it important?
Here are the main results:
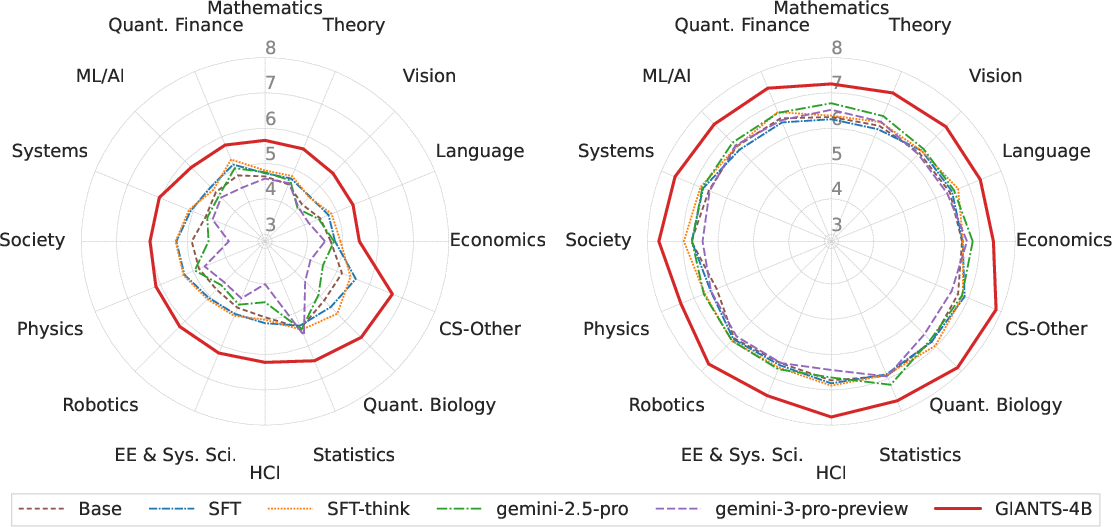
- The task is hard—even for very large, top-tier AI models. Just making a model bigger didn’t automatically make it good at insight anticipation.
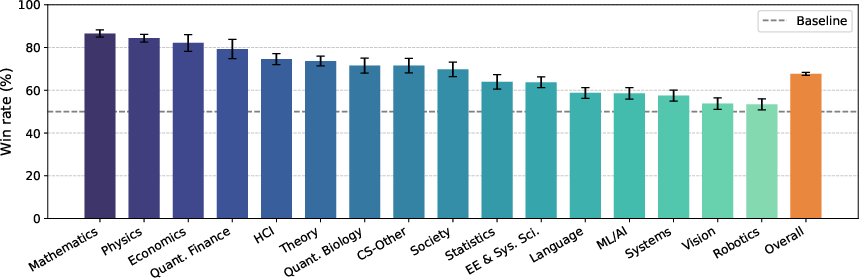
- The new model, GIANTS-4B (which is relatively small), did best. After RL training with the similarity score as feedback, GIANTS-4B beat strong baselines, including big proprietary models. It achieved about a 34–35% relative improvement in similarity scores compared to a leading model.
- It generalizes to new areas. Even though GIANTS-4B was trained on one field, it performed well in other fields like physics and biology, and on parent papers it hadn’t seen before.
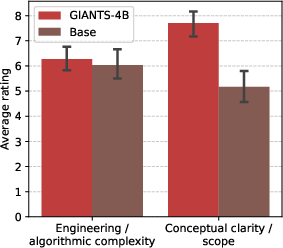
- Humans liked its clarity. In small human studies, people said GIANTS-4B’s insights were clearer and more understandable than those from the base model.
- A third-party “impact judge” preferred GIANTS-4B. Another model (SciJudge-30B), built to compare which abstracts are likely to be more influential (get more citations), preferred GIANTS-4B’s outputs 68% of the time. That suggests the insights it produces might be more promising.
These findings matter because they show that with the right training signal—rewarding meaningful, literature-grounded synthesis—an AI can learn to combine ideas from past work in a useful, human-like way, not just produce vague summaries.
What could this change?
- Helping researchers: An AI that’s good at “insight anticipation” could act like an assistant that reads a few key papers and proposes a plausible next step, speeding up brainstorming and guiding experiments.
- Education and summaries: It could help students and scientists quickly understand how ideas connect and evolve across papers.
- Smarter scientific tools: This approach is a step toward AI systems that don’t just search or summarize, but actually suggest focused, grounded research directions.
Limits and next steps
- Only two parents: The model currently assumes each new idea mainly comes from two prior papers, but real research often draws from many sources.
- Picking the parents: The study focuses on synthesizing given parents, not finding which parents matter. In real life, identifying the right prior works is a big part of research.
- Citations aren’t perfect: Not every influential idea is cited properly, so the links the dataset relies on aren’t always exact.
Future work could:
- Combine parent selection (finding the right papers) and insight generation (synthesizing them) into one system.
- Handle more than two parent papers.
- Evaluate not just “similarity to past insights” but also novelty and usefulness for future work.
- Test in real, human-in-the-loop research settings.
Overall, the paper shows that AIs can learn to stand “on the shoulders of giants” by reading past work and anticipating the next meaningful idea—and that training with the right kind of feedback makes a big difference.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored in the paper, framed to inform actionable follow‑up research.
- Dataset construction reliability: Parent selection, synergy explanations, and ground‑truth insights are LM-generated (gemini-2.5-flash and gemini-3-pro) with minimal human verification; quantify and reduce error/bias introduced by these steps via larger, multi-domain human audits and adjudication.
- Faithfulness of “core insight” targets: Ground-truth insights are rewritten by an LM rather than directly extracted or author-verified; assess alignment with authors’ stated main contributions and measure how rewriting alters meaning, specificity, or novelty.
- Citation-based biases: Using “≥2 citations” and selecting the “most-cited downstream paper” per parent pair may induce survivorship and popularity bias; evaluate alternatives (e.g., time-normalized citations, expert labels, random downstream selection) and effects on training/evaluation.
- Two-parent constraint: The task assumes exactly two parents and uses summaries instead of full text due to context limits; test performance with more parents, ablated parent sets, and full-text or section-level inputs using long-context models or retrieval-augmented compression.
- Parent identification validity: The LM-chosen cited parents may not reflect true conceptual lineage; create a gold-standard subset with expert-validated parent–child triads and compare performance to LM-selected parents.
- Robustness to noisy or mis-specified parents: Evaluate how models behave when given irrelevant, weakly related, or adversarially chosen parents; develop methods to detect and down-weight spurious parents.
- Evaluation dependence on LM judges: Similarity scores rely on proprietary LMs and a 1–10 rubric; expand to multiple open judges, report inter‑judge reliability at scale, and develop task-specific, annotation-based rubrics beyond textual similarity (e.g., concept graph overlap, mechanistic linkage).
- Limited human validation: Correlation to human ratings is based on n=60 samples and two CS PhD raters; broaden to larger, multi-discipline annotator pools, report inter-annotator agreement, and analyze domain-wise discrepancies.
- Reward hacking and over-optimization: Despite separating training and evaluation judges, the reward is an LM; stress-test with adversarial prompts, perturbation of judge prompts, and counterfactual judges to detect overfitting to judge idiosyncrasies.
- Novelty vs. similarity trade-off: Optimizing similarity may penalize creative but valid insights; design dual-objective rewards incorporating novelty/feasibility and measure whether RL shifts models toward conservative, near-paraphrase outputs.
- External impact proxies: SciJudge-30B preferences are an indirect proxy for impact; calibrate against real-world outcomes (e.g., future citation trajectories, expert panels) and evaluate whether high-similarity insights translate to actionable, high‑value ideas.
- Lack of human upper bound and baselines: There is no benchmark of human-generated insights given the same parents; establish human performance, expert-curated baselines, and ceiling analyses to contextualize model scores.
- Temporal generalization details: Judges and base LMs may have been trained on post-cutoff literature; quantify potential information leakage (e.g., judge familiarity with downstream papers) and replicate with strictly pre-cutoff open judges.
- Domain and language coverage: Data is drawn from arXiv across eight quantitative domains and training is cs.CL-only; evaluate on non-arXiv fields (e.g., biomedical/chemistry with peer review), non-English literature, and practitioner-authored documents.
- End-to-end pipeline integration: The work assumes oracle parent selection; develop and evaluate unified retrieval+synthesis systems and compare to the decoupled setting on the same held-out future literature.
- Mechanism-aware evaluation: Current metric captures semantic similarity, not causal/mechanistic integration across parents; introduce evaluations that score cross-paper mechanism articulation, explicit linking, and evidence grounding.
- Failure-mode analysis: Provide systematic error taxonomy (e.g., hallucinated links, shallow restatements, incorrect technical claims) and targeted training or prompts to mitigate each class.
- Scalability with k and compute fairness: Best-of-k analyses are run on a subset with specific judge/temperatures; formally characterize compute/sample efficiency trade-offs and normalize comparisons across models.
- Model ablations and alternatives: Limited exploration of training choices (e.g., only GRPO with similarity); compare RL algorithms, reward models (novelty/feasibility/consistency), and SFT+RL hybrids; ablate chain-of-thought and base model size.
- Interpretability and controllability: The approach does not expose how the model attributes ideas to parents; develop rationale attribution, citation-style grounding, and controllable generation (e.g., emphasize certain parent sections or constraints).
- Practical utility with researchers: Beyond small-scale human studies, there is no evaluation in real ideation workflows; run user studies where researchers use model suggestions to design experiments or papers, measuring time saved and downstream success.
- Generalization horizons: The task predicts “next” insights; quantify how far ahead in time models can anticipate (lead-time analyses) and how performance degrades as the temporal gap or conceptual distance increases.
- Data and IP considerations: Reliance on proprietary judges for reward/eval limits reproducibility; replicate results with open-weight judges and release a vetted human-labeled subset for benchmarking and future method comparison.
- Safety and misinformation: While risks are noted, there is no systematic measurement of plausible-but-incorrect claims; build automatic and human-in-the-loop verification pipelines to assess factuality and technical correctness of generated insights.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, building directly on the paper’s benchmark (GiantsBench), evaluation approach (LM-as-judge similarity), and model (GIANTS-4B) for literature-grounded synthesis.
- Stronger literature-grounded research copilot for hypothesis and contribution writing
- Sectors: academia, software
- Tools/products/workflows: GIANTS-4B-powered “synthesis” mode inside note-taking tools and research IDEs; a “From these two papers, what’s the next core insight?” button in arXiv/Semantic Scholar; contribution-paragraph and “limitations/future work” generators tied to cited works
- Assumptions/dependencies: accurate parent selection/retrieval (paper assumes an oracle); human-in-the-loop vetting to avoid speculative or misleading claims; compliance with citation and attribution norms
- Survey/review drafting assistant that bridges subfields
- Sectors: academia, publishing
- Tools/products/workflows: “bridge paragraphs” that articulate how two strands of literature combine to yield a new angle; editor plug-ins that suggest cross-section synthesis
- Assumptions/dependencies: domain-relevant parent pairs; editorial oversight; avoids overclaiming novelty
- Grant and proposal ideation support
- Sectors: academia, policy/funding agencies
- Tools/products/workflows: “specific aims” reframing from two seminal papers; alternative aims based on multiple parent pairings; auto-rationales connecting prior work to proposed impact using similarity-scored candidates
- Assumptions/dependencies: reviewers remain the arbiters of feasibility; requires domain-specific fine-tuning in highly specialized areas
- Patent landscaping and white-space brainstorming
- Sectors: finance/IP, software
- Tools/products/workflows: given two patents/papers, auto-suggest potential claims or embodiments; structured claim skeletons with references to enabling art
- Assumptions/dependencies: legal and ethical review; not a substitute for patent counsel; must avoid disclosure of confidential material
- Enterprise R&D cross-pollination recommender
- Sectors: robotics, energy, biotech, materials, software
- Tools/products/workflows: internal “insight anticipation” over corporate knowledge bases (papers, design docs, incident reports) to propose next design concepts; idea triage using LM judge similarity + third-party impact predictors
- Assumptions/dependencies: data governance and access; careful scoping to domain-specific terminology; security/privacy controls
- Editorial and peer-review triage signals
- Sectors: publishing, academia
- Tools/products/workflows: similarity-based screens that check whether claimed contributions are a plausible synthesis of cited parents; flags for “just a restatement” vs “non-trivial synthesis”
- Assumptions/dependencies: not a final arbiter of novelty/quality; guardrails against bias toward text similarity; editorial policy alignment
- Reference manager/search-engine augmentation
- Sectors: software, education
- Tools/products/workflows: Zotero/Mendeley/Semantic Scholar plug-ins that surface anticipated insights when a user selects two references; “try these two together” recommendations; saved “insight drafts”
- Assumptions/dependencies: robust PDF-to-summary pipelines; UI for quick human curation of suggestions
- Curriculum and seminar pedagogy enhancer
- Sectors: education
- Tools/products/workflows: assignments that ask students to anticipate the next insight from two readings; automated formative feedback via LM judge scores; instructor dashboards showing class-wide synthesis patterns
- Assumptions/dependencies: alignment with learning objectives; safeguards against students over-relying on AI; transparent grading rubrics
- Horizon scanning and research roadmapping
- Sectors: policy/think tanks, corporate strategy
- Tools/products/workflows: periodic “what’s the next move?” memos for priority topic pairs; heatmaps of anticipated insights across domains using GiantsBench-like pipelines; triage by impact-oriented judges (e.g., SciJudge-style)
- Assumptions/dependencies: expert review to avoid overfitting to textual similarity; scenario analysis to account for uncertainty
- Knowledge graph augmentation with “anticipated” edges
- Sectors: software/data, academia
- Tools/products/workflows: edges labeled “anticipated insight from (A,B)” with confidence scores; researcher UIs to validate or refute suggested connections; provenance back to parent texts
- Assumptions/dependencies: entity disambiguation; maintenance of provenance and uncertainty; human validation loops
- Idea ranking and de-duplication for labs and conferences
- Sectors: academia, publishing
- Tools/products/workflows: batch-generate candidate insights from many parent pairs; rank using LM judge similarity and impact predictors; de-duplicate overlapping pitches before internal reviews or brainstorming sessions
- Assumptions/dependencies: multi-judge evaluations to reduce bias; careful interpretation of “impact” proxies
- Benchmarking and model evaluation services
- Sectors: software/AI tooling
- Tools/products/workflows: GiantsBench-based “insight synthesis score” for internal LLM training; judge separation best practices (train/eval decoupling) to reduce reward hacking; domain add-ons for biomed, materials, etc.
- Assumptions/dependencies: fair-use/data licensing of corpora; regularly refreshed temporal holdouts
Long-Term Applications
These opportunities likely require improvements in parent selection/retrieval, multi-source synthesis beyond two papers, domain-specialized modeling, or integration with experimental/validation loops.
- End-to-end “AI scientist” that retrieves parents, anticipates insights, and plans validation
- Sectors: healthcare, materials, energy, robotics, software
- Tools/products/workflows: retrieval + synthesis (GIANTS-like) + experiment/simulation design + active learning; lab-in-the-loop integration with LIMS/ELN for automatic experiment queuing
- Assumptions/dependencies: reliable parent discovery at scale; structured data from instruments; safety and reproducibility protocols
- Domain-tailored discovery agents for biomed/chem with wet-lab coupling
- Sectors: healthcare/biotech
- Tools/products/workflows: integrate molecular property predictors and protocol optimization with literature-grounded synthesis to propose targets, combinations, or mechanisms; closed-loop validation
- Assumptions/dependencies: regulatory oversight; high-quality, curated domain corpora; careful handling of dual-use risks
- Funding portfolio optimization and strategic foresight
- Sectors: policy/funding agencies, finance
- Tools/products/workflows: “anticipated trajectory maps” to identify underfunded but promising syntheses; simulate counterfactual portfolios; early detection of redundant grant aims
- Assumptions/dependencies: transparent criteria; governance for fairness and field diversity; guardrails against popularity bias
- Dynamic peer-review and integrity assistance
- Sectors: publishing
- Tools/products/workflows: AI assists reviewers by highlighting plausible-but-unsupported syntheses and suggesting targeted experiments; detects salami-slicing vs meaningful fusions of prior work
- Assumptions/dependencies: reviewer control; explanations and evidence trails; continual calibration to community standards
- Academic search engines that chart future trajectories
- Sectors: software, academia
- Tools/products/workflows: “research roadmap” views showing probable next insights from clusters of papers; alerts when a predicted synthesis materializes; recommendation of collaborators across clusters
- Assumptions/dependencies: robust clustering and temporal generalization; user consent for profile-driven personalization
- Interdisciplinary collaboration recommender
- Sectors: academia, industry R&D
- Tools/products/workflows: match labs/teams whose works form high-value parent pairs; suggest joint proposals with draft contributions auto-generated via synthesis
- Assumptions/dependencies: accurate author/topic embeddings; privacy-respecting use of unpublished work
- Code/simulation co-generation from anticipated insights
- Sectors: software, robotics, energy
- Tools/products/workflows: translate a synthesized insight into starter code, experiment configs, or simulation blueprints; automated ablation plans to test the proposed mechanism
- Assumptions/dependencies: reliable mapping from textual insight to executable artifacts; reproducibility tooling
- Large-scale IP white-space detection and M&A scouting
- Sectors: finance/IP, corporate strategy
- Tools/products/workflows: macro maps of “likely next claims” across technology areas; target identification for partnerships or acquisitions aligned with anticipated syntheses
- Assumptions/dependencies: legal risk management; strategic use by experts rather than automated decision-making
- Safety and dual-use risk anticipation
- Sectors: policy, biosecurity, cybersecurity
- Tools/products/workflows: proactively surface potentially hazardous syntheses (e.g., combining techniques that could enable misuse); align with red-team frameworks and oversight committees
- Assumptions/dependencies: specialized risk taxonomies; strict access controls; governance and auditing
- Automated curriculum co-design and assessment at program scale
- Sectors: education
- Tools/products/workflows: generate course sequences that scaffold toward milestone syntheses in a field; program-level dashboards showing student progression in synthesis skills
- Assumptions/dependencies: institutional buy-in; validated pedagogy; careful measurement of learning outcomes
Cross-cutting assumptions and dependencies
- Parent selection is pivotal: the paper assumes oracle parent identification; real systems need robust retrieval and disambiguation across large corpora.
- Human oversight is non-negotiable: LM-generated insights are not validated facts; expert review, provenance, and uncertainty disclosure are required.
- Evaluation robustness: LM-as-judge should use judge separation and, ideally, multi-judge committees to reduce bias and reward hacking.
- Data quality and licensing: arXiv-derived data and internal corpora must respect licenses, privacy, and attribution; citation counts are imperfect proxies.
- Domain adaptation: specialized fields (biomed, materials) require curated corpora, terminology alignment, and safety controls.
- Ethics and IP: avoid plagiarism, ensure proper attribution, and manage dual-use risks in sensitive domains.
Glossary
- auto-encoding task: An encoding–decoding formulation where a system reconstructs target information from a compressed or lossy representation. Example: "Conceptually, this framework can be viewed as an auto-encoding task~\cite{kingma2022autoencodingvariationalbayes} over the citation graph."
- autoregressive LMs: LLMs that generate tokens sequentially, each conditioned on previously generated tokens. Example: "This process optimizes the standard cross-entropy loss for autoregressive LMs over the paired examples ."
- best-of-k: An inference strategy that generates k candidates and selects the one with the highest score under a chosen metric. Example: "Since best-of- evaluation requires scoring many samples per example, we conduct the inference-time scaling evaluation in Figure~\ref{fig:best_at_k} on a subset of 480 examples sampled from GiantsBench, using gemini-3-flash as the LM judge for cost considerations."
- chain-of-thought reasoning: A prompting and training technique that elicits step-by-step intermediate reasoning before the final answer. Example: "To bridge the logical gap between the source papers and the final insight, we also evaluate an SFT strategy enhanced with chain-of-thought reasoning~\citep{wei2023chainofthoughtpromptingelicitsreasoning}, which we denote as SFT-think."
- citation graph: A directed graph where nodes are papers and edges represent citations among them. Example: "By linearizing the citation graph into input-target pairs, we challenge the model to recreate the conceptual leap required to bridge adjacent nodes."
- citation-preference reward model: A learned model that scores or prefers ideas based on predicted citation impact, used to guide generation. Example: "SciThinker-4B~\citep{tong2026ai}, which is a scientific-ideation model trained using a citation-preference reward model."
- cross-entropy loss: A standard loss function measuring the difference between predicted token distributions and ground-truth tokens. Example: "This process optimizes the standard cross-entropy loss for autoregressive LMs over the paired examples ."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that updates a policy by comparing sampled action groups rather than using a separate value function. Example: "We optimize this reward using Group Relative Policy Optimization (GRPO) \citep{shao2024deepseekmath}."
- hold-out split: A dataset partitioning strategy where certain data (e.g., future or cross-domain subsets) are held out for evaluation only. Example: "using a temporal and cross-domain hold-out split and a human-validated LM judge for scoring."
- human-in-the-loop: A setup where humans are actively involved in evaluation, supervision, or decision-making within the system. Example: "Ultimately, testing these models in active, human-in-the-loop research settings will determine their true potential as catalysts for scientific discovery."
- inference-time scaling: Improving performance by generating and evaluating multiple samples at inference time. Example: "This performance trend remains robust as we increase the number of samples to optimize the similarity score via inference-time scaling, as illustrated in Figure~\ref{fig:best_at_k}."
- LM-as-a-Judge: Using a LLM to evaluate or score outputs according to specified criteria. Example: "where measures the semantic equivalence between the generated insight and downstream paper's insight measured using an LM-as-a-Judge~\citep{gu2025surveyllmasajudge}, matching the evaluation criterion in Section~\ref{sec:dataset_construction}."
- LM judge: A LLM designated to score or compare generated outputs. Example: "We evaluate models using an LM judge that scores similarity between generated and ground-truth insights, and show that these similarity scores correlate with expert human ratings."
- Literature-Based Discovery (LBD): A research area focused on discovering hidden, meaningful connections across disparate literature. Example: "Literature-Based Discovery (LBD) studies how computational methods can uncover hidden links between seemingly unrelated bodies of research to infer novel and potentially useful knowledge"
- min-p threshold: A decoding parameter that filters tokens below a minimum probability during sampling. Example: "temperature , top-p , top-k , and min-p ."
- oracle literature selection criterion: An idealized assumption that relevant parent papers are perfectly provided by an external selector. Example: "We assume that the parent papers are provided by an oracle literature selection criterion and ask a more targeted feasibility question"
- policy (in reinforcement learning): The function or model that maps states to action distributions, here the LM generating candidate insights. Example: "when the downstream insight has low likelihood under the policy, or when the model lacks the capacity to adequately capture the distribution of the parent insight."
- proxy reward: A surrogate reward signal that approximates the true objective for RL training. Example: "using these similarity scores as a proxy reward."
- reinforcement learning (RL): A training paradigm where a policy is optimized to maximize expected reward. Example: "trained via reinforcement learning (RL) to optimize insight anticipation using these similarity scores as a proxy reward."
- reward hacking: The unintended exploitation of flaws in the reward signal that leads to high scores without achieving the true objective. Example: "To mitigate the risk of reward hacking and ensure a rigorous evaluation, we enforce a strict separation between the training and testing judges."
- reward model: A model that assigns reward scores to outputs, guiding RL optimization. Example: "We use gemini-2.5-flash as the active reward model during GRPO training, while reserving the independent gemini-3-pro model exclusively for the final evaluation phase."
- semantic equivalence: The degree to which two texts convey the same meaning regardless of surface form. Example: "where measures the semantic equivalence between the generated insight and downstream paper's insight..."
- Spearman rank correlation: A nonparametric statistic measuring the strength of a monotonic relationship between two ranked variables. Example: "In particular, we observe a Spearman rank correlation of ()."
- Spearman's ρ: The coefficient value for Spearman rank correlation. Example: "Spearman's , "
- supervised fine-tuning (SFT): Fine-tuning a pretrained model on labeled input–output pairs to specialize its behavior. Example: "We explore two training paradigms for insight anticipation: (1) distillation via supervised fine-tuning (SFT), leveraging ground-truth insights and rationalization from target downstream papers, and (2) reinforcement learning (RL) via similarity optimization."
- teacher model: A larger or more capable model used to provide rationales or targets for distillation into a smaller model. Example: "we prompt a high-capacity teacher model (gemini-3-pro) to generate a detailed chain-of-thought that logically deduces the ground-truth insight"
- temperature (decoding): A sampling parameter controlling randomness in token selection; higher values increase diversity. Example: "temperature , top-p , top-k , and min-p ."
- Temporal Hold-Out Evaluation: An evaluation protocol where test data are temporally separated from training data to assess future generalization. Example: "Temporal Hold-Out Evaluation."
- thinking-mode decoding: A decoding configuration designed (here for Qwen) to encourage reasoning-style outputs. Example: "using the recommended Qwen thinking-mode decoding settings: temperature , top-p , top-k , and min-p ."
- top-k sampling: A decoding strategy limiting sampling to the k highest-probability tokens. Example: "top-k "
- top-p sampling: Also known as nucleus sampling; restricts sampling to a smallest set of tokens whose cumulative probability exceeds p. Example: "top-p "
- value function: In RL, a function estimating expected return from a state (or state–action), often used to reduce variance in policy updates. Example: "it avoids the need to train and maintain a separate, memory-intensive value function model"
- zero-shot generalization: The ability to perform well on tasks or domains without task-specific fine-tuning. Example: "generalizes zero-shot to unseen domains"
Collections
Sign up for free to add this paper to one or more collections.

