- The paper demonstrates that supervised fine-tuning can drastically alter the correlation between confidence scores and output quality, often leading to miscalibration.
- It employs a rigorous evaluation pipeline across tasks, model architectures, and confidence metrics to assess the variable impacts of fine-tuning.
- The study highlights that SFT may induce both overconfidence and underconfidence, urging tailored calibration strategies for reliable uncertainty quantification.
Sensitivity of Confidence Scores to Supervised Fine-Tuning in LLMs
Introduction and Motivation
The measurement and utilization of model uncertainty in neural language generation have emerged as critical concerns, particularly as such measures underpin vital downstream tasks—ranging from hallucination detection to selective generation and self-evaluation. The study "Confident in a Confidence Score: Investigating the Sensitivity of Confidence Scores to Supervised Fine-Tuning" (2604.08974) systematically interrogates the robustness of various confidence metrics following supervised fine-tuning (SFT). Contrary to assumptions underpinning several uncertainty quantification (UQ) toolkits, the paper demonstrates that SFT can deeply and heterogeneously affect the correlation between confidence scores and output quality, sometimes resulting in overconfidence or other forms of miscalibration, with direct ramifications for practical deployment.
Experimental Framework
The investigation is anchored in a structured evaluation pipeline, where several families of confidence metrics are computed both before and after SFT across multiple data regimes, model architectures, and tasks:
- Tasks: Machine translation (En-Af), question answering (SQUAD), and mathematical reasoning (GSM8K).
- Models: BART-Base, Flan-T5-Base, Llama 3.1-8B, and Gemma-2-2B.
- Metrics: Probability-based metrics (e.g., average token log probability, average token entropy), self-consistency-based scores (e.g., dropout BLEU variance), and composite metrics (e.g., CoCoA).
Correlation to reference quality is measured using Spearman's correlation, reflecting the monotonic relationship between the confidence score assigned to individual outputs and their actual evaluation.
Impact of SFT on Confidence-Quality Correlation
A central finding is the volatility of correlation between confidence scores and output quality following SFT. For a significant fraction of task-model-metric configurations—33% of 144 configurations—SFT degraded this correlation. Moreover, in the remainder, improvements were not always statistically significant, and even modest changes to SFT parameters (such as the number of epochs or training samples) could drastically shift the observed correlations. This sensitivity undermines assumptions of metric robustness and emphasizes the importance of domain- and setting-specific validation.
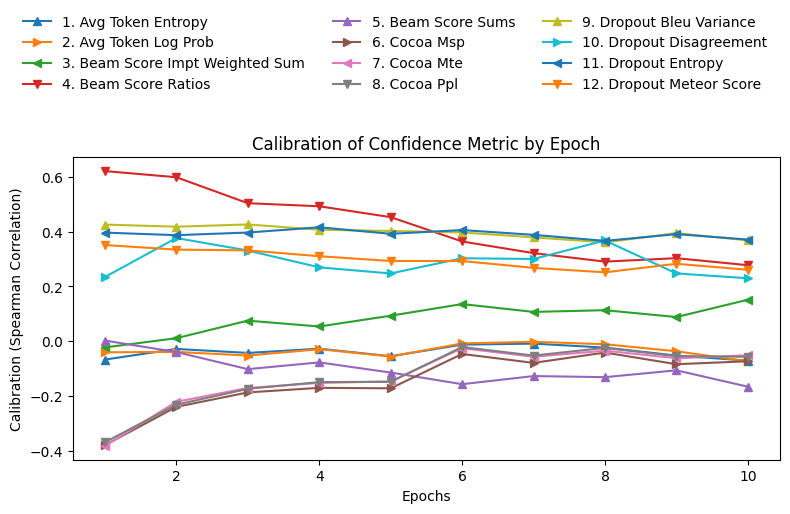
Figure 1: The correlation of various confidence metrics varies with more fine-tuning epochs; Plot shown for 12 confidence metrics, fine-tuned with Flan-T5 on SQUAD.
Additionally, the number of fine-tuning samples was shown to meaningfully impact correlation, even when controlling for the number of training steps (i.e., isolating the effect of data diversity and sample count from iteration count).
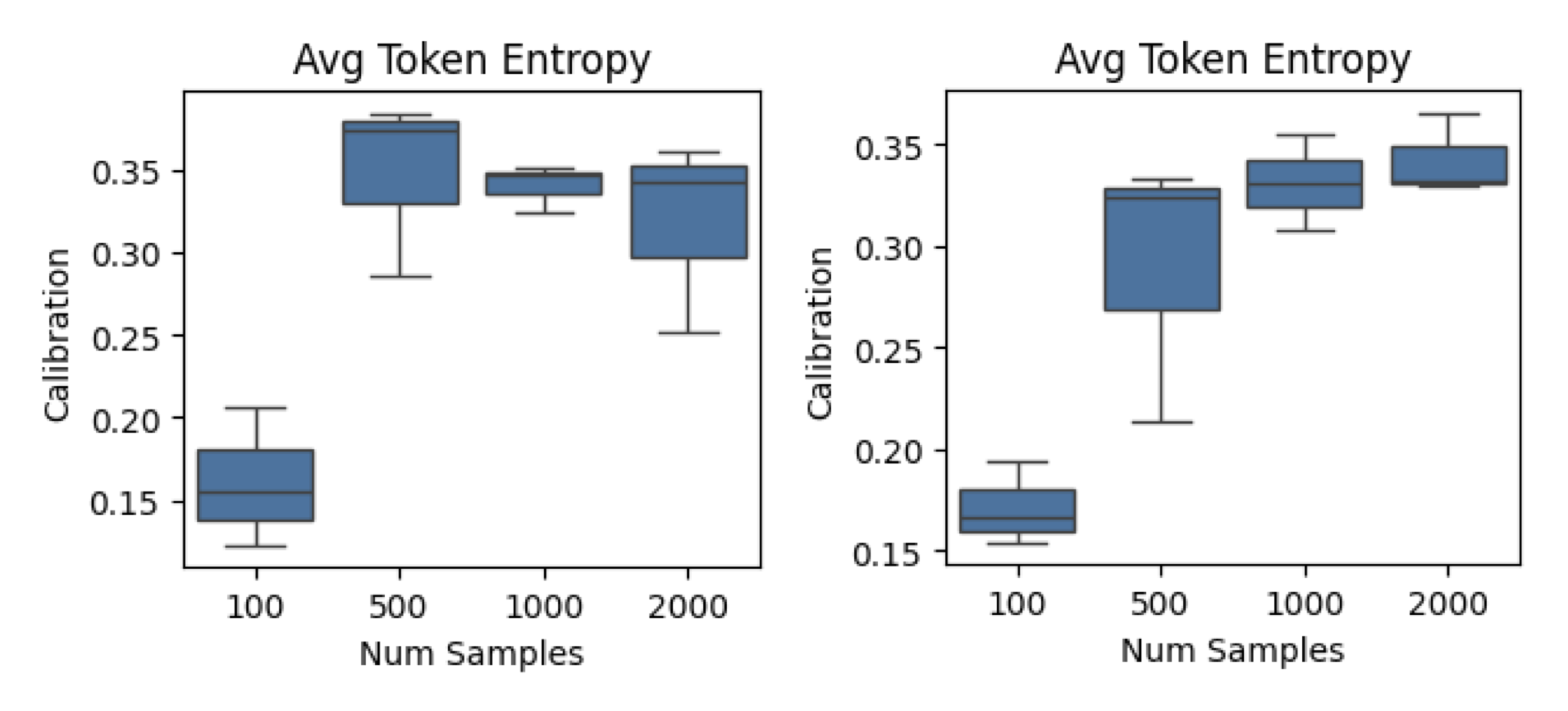
Figure 2: The correlation of confidence metrics differs significantly depending on the number of fine-tuning samples used, both before (left) and after (right) controlling for the number of fine-tuning steps used; Plots shown using average token entropy as the confidence metric, used on SQUAD for BART-Base.
Underlying Dynamics of Mis-Correlation
To diagnose how and why SFT reshapes the utility of confidence metrics, the authors investigate score dynamics at the sample level. They introduce a quadrant visualization to classify cases where changes in confidence are concordant or discordant with changes in output quality.
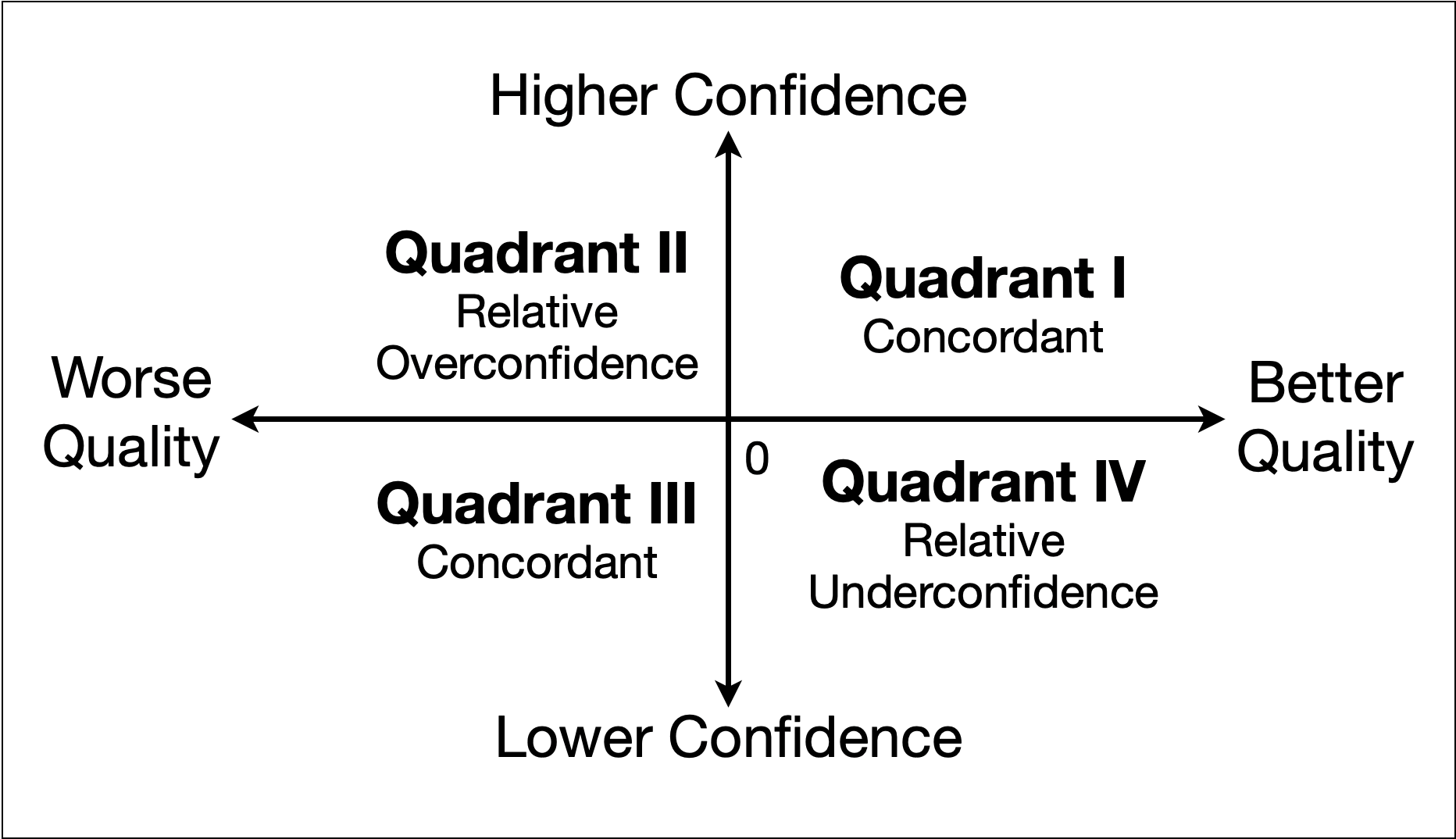
Figure 3: We classify SFT's effect on the correlation of samples using four quadrants.
Strikingly, SFT induces characteristic error modes:
- Probability-based metrics (e.g., avg log probs) exhibit a pronounced tendency towards relative overconfidence: models often increase confidence on outputs whose actual quality fails to improve, occasionally even as it deteriorates. This is made tangible by comparing model behavior pre- and post-SFT, where models sometimes transition from low confidence in correct answers to high confidence in incorrect or lower-quality answers.

Figure 4: Before SFT, a model had a relatively low confidence score in a correct answer, whereas post-SFT, it had a much higher confidence in an incorrect answer, demonstrating a case of relative overconfidence.
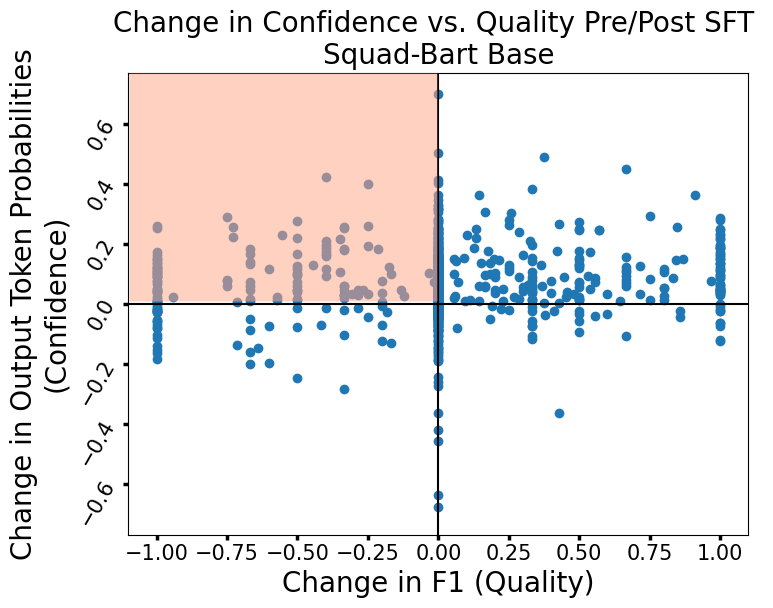
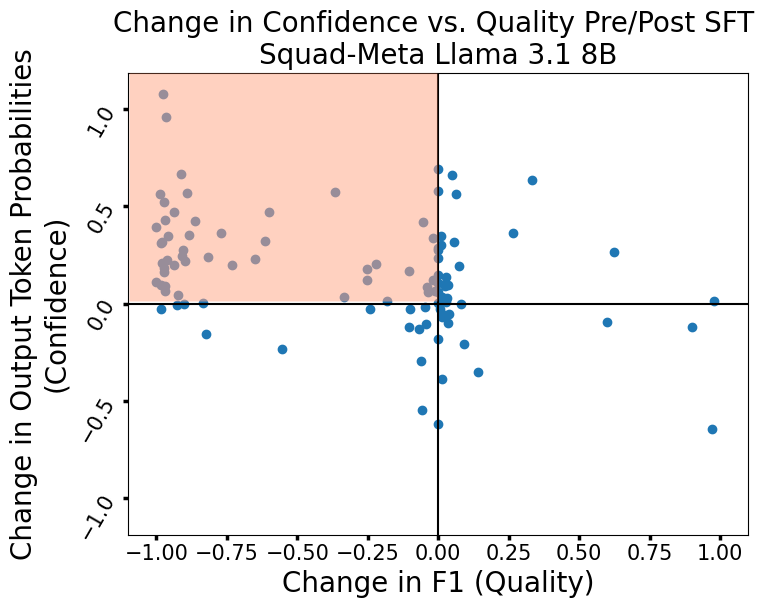
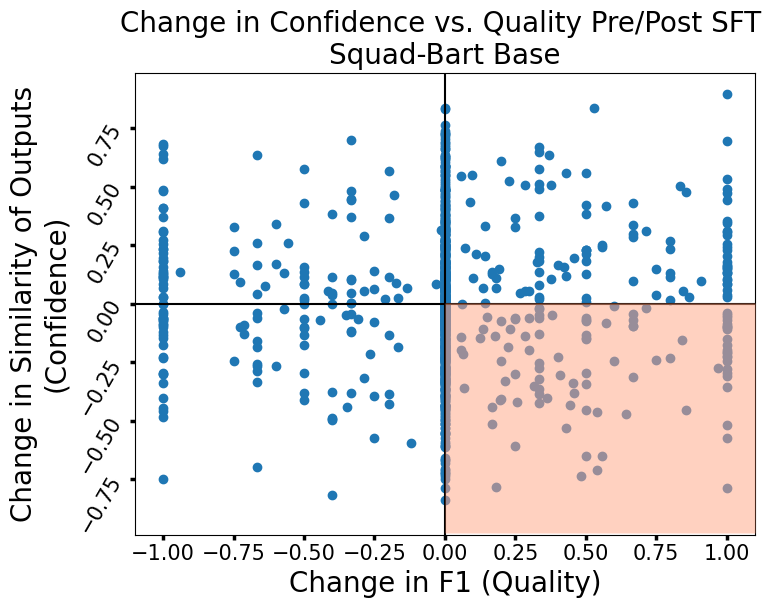
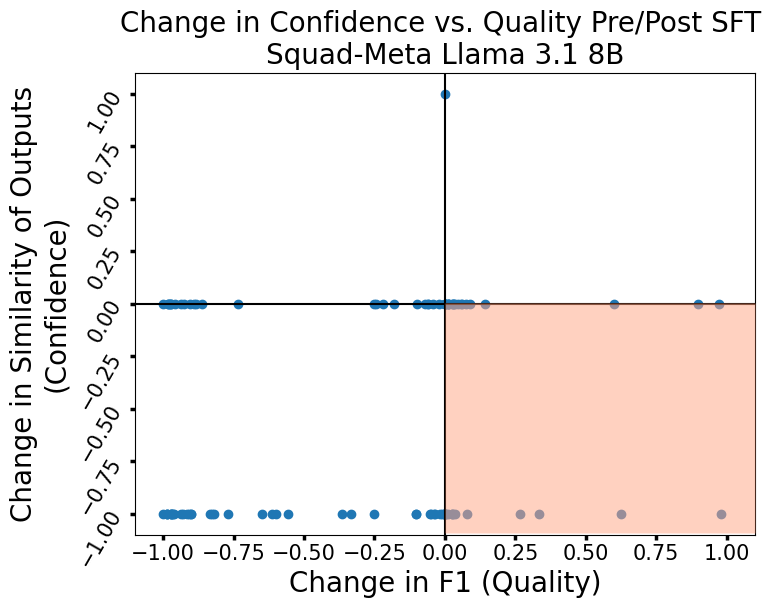
Figure 5: Avg Log Probs, BART (Left) and Llama 3.1 (Right).
- Self-consistency-based metrics (e.g., dropout BLEU variance) are more prone to underconfidence, often not tracking output quality improvements with commensurate increases in confidence.
The increase in average log-probabilities across epochs, even when not strictly accompanied by better outputs, underscores a drift in the internal calibration of the model through SFT.
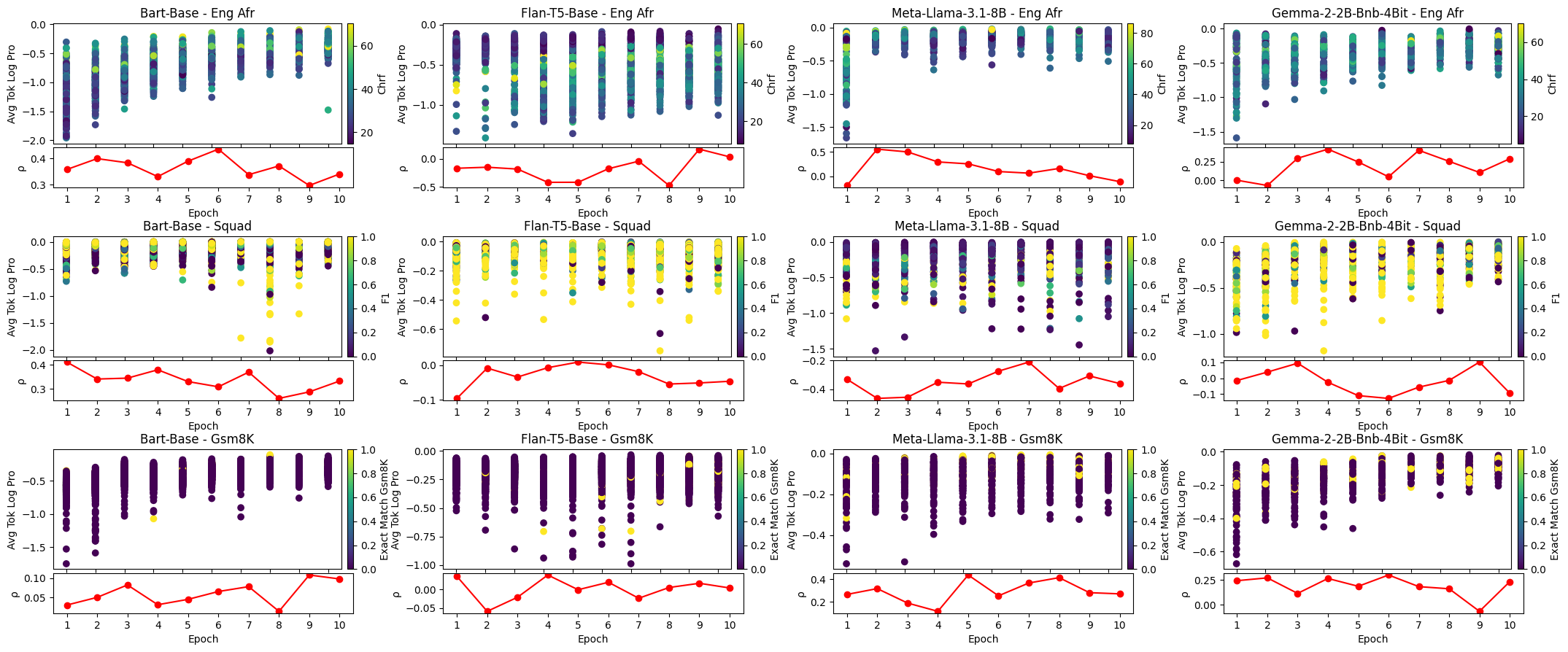
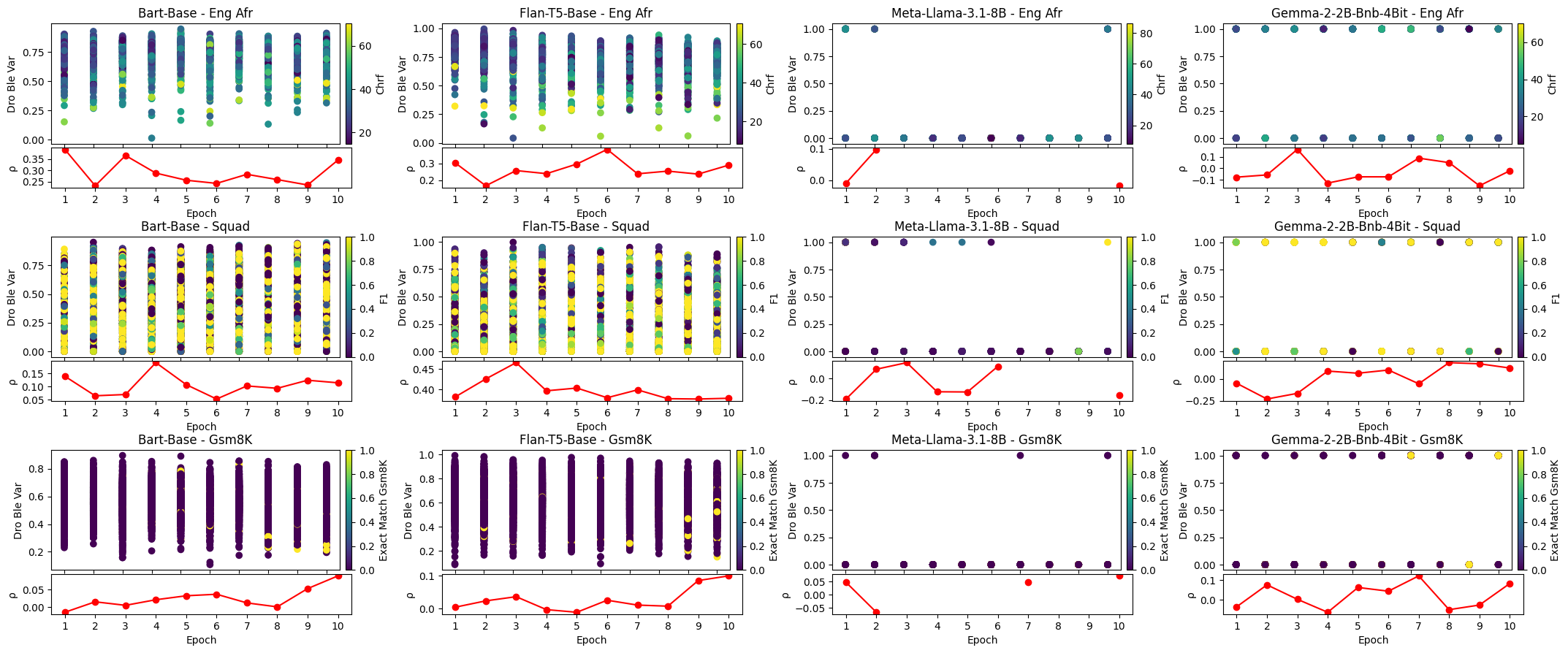
Figure 6: The average log probs across all test set samples generally increase for BART and Llama 3.1 8B (top), which may explain the rel. overconfidence in probability-based metrics, and fluctuations in correlation (bottom).
An additional factor is the influence of sample similarity to the training distribution, which can cause confidence scores to rise for outputs that resemble training data, regardless of their correctness—a confounder that disassociates confidence from problem-specific quality.
Practical Implications and Case Study
To exemplify the real-world consequences of post-SFT miscalibration, the paper presents a case study using TruthfulQA, where confidence scores are deployed to detect answer correctness. In 47% of scenarios, the utility (AUROC for correct answer detection) of these confidence scores actually declines post-SFT. The inability to rely on such metrics for risk-sensitive tasks (e.g., filtering, abstaining, user warning) exposes significant limitations in their off-the-shelf deployment.
Theoretical and Practical Implications
This work challenges the presumption that UQ metrics, whether based on marginal probabilities or output consistency, remain robust under fine-tuning. It establishes that the internal distributions of scores can decouple from underlying task utility or correctness, emphasizing the need for:
- Explicit in-context or post-hoc calibration after (re-)training or domain adaptation.
- Metric designs that explicitly account for or are invariant to distributional similarity effects.
- Task- and domain-specific reporting of confidence metric behavior with corresponding SFT conditions.
The findings highlight that, absent such precautions, integrating confidence metrics naively can not only diminish interpretability but also lead to detrimental operational outcomes in real-world systems.
Directions for Future Research
Robust UQ metrics, by construction or adaptation, must mitigate overconfidence and account for confounding factors like distributional shift and training data similarity. Techniques such as auxiliary OOD detection, entropy regularization, or joint modeling of quality and distributional proximity may offer improvements. Investigation of alternative correlation metrics over Spearman's rho, especially for generation tasks with richer, more nuanced evaluation scales, should also be pursued.
Conclusion
The sensitivity of confidence scores to supervised fine-tuning highlights substantial challenges to reliable UQ in neural language generation. The shift and sometimes degradation in confidence-quality correlation due to SFT are both metric- and regime-dependent, impinging on the dependability of current best-practice approaches. This necessitates critical evaluation and possible redesign of confidence metrics for every SFT setting, and motivates the community to develop novel, more robust measures of model uncertainty that generalize across domains, tasks, and fine-tuning protocols.

