- The paper presents fine-tuning techniques that significantly improve calibration and confidence estimation in LLMs.
- Methodologies include single-question and pairwise comparison tasks with self-consistency scores for accurate uncertainty assessment.
- Results indicate that multitask and multidomain training enhances within-domain discrimination and cross-domain generalization.
Introduction
The paper "Improving Metacognition and Uncertainty Communication in LLMs" (2510.05126) investigates the capability of LLMs to assess and communicate their confidence in generated answers. This research is prompted by the increasing deployment of LLMs in domains where their outputs influence critical decisions, such as law and medicine. LLMs tend to express high confidence even when uncertain, which can lead to users relying on incorrect information. The paper proposes fine-tuning techniques to improve these models' uncertainty communication and examines the effectiveness of such improvements across multiple domains and tasks.
The research incorporates two distinct metacognitive tasks:
- Single-question confidence estimation: LLMs report a numeric confidence score beside their generated answer.
- Pairwise confidence comparison: LLMs choose between two questions, indicating which they have higher confidence successively before answering.
These tasks are evaluated within the framework of generalization across domains and specific metacognitive operations, highlighting improvement modalities upon applying fine-tuning processes.

Figure 1: Two metacognitive tasks used to evaluate confidence communication.
Fine-tuning Process
The methodology centers on fine-tuning LLMs on datasets spanning various domains—general knowledge, mathematics, and trivia—with a focus on both single-question calibration and pairwise comparison tasks. Fine-tuning employs consistency-based uncertainty estimates derived from sampling multiple answers and calculating a self-consistency score. This approach enhances the model's capacity to reflect true confidence levels based on empirical accuracy.
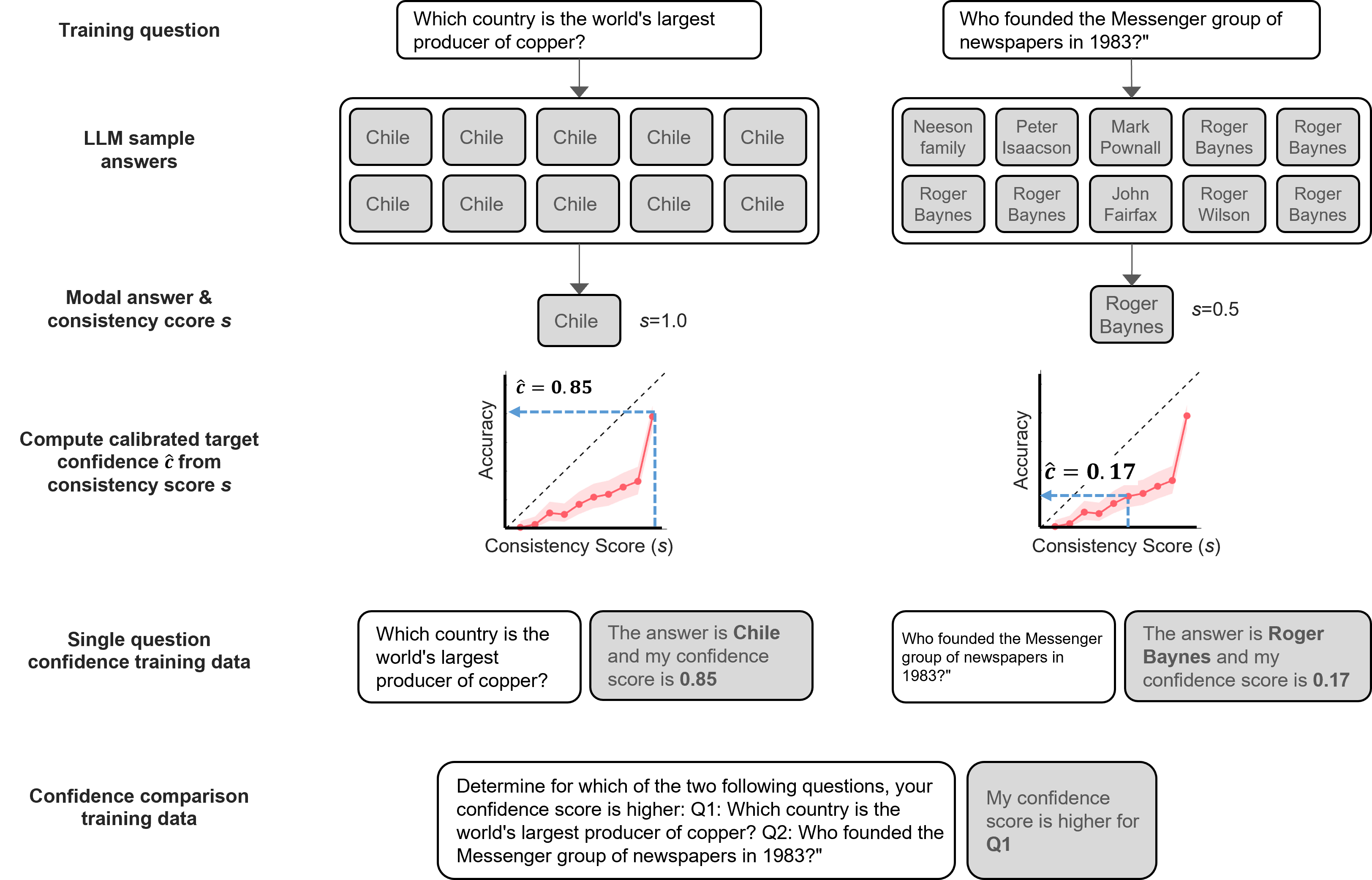
Figure 2: The LLM fine-tuning procedure illustrated with example questions from the TriviaQA dataset.
Results
Single-Question Confidence
Calibration Improvement: The fine-tuning process improves calibration, the alignment between expressed confidence and actual accuracy. Within-domain tests reveal a significant reduction in Expected Calibration Error (ECE), coupled with increased discrimination (AUC).
Cross-Domain Generalization: Models fine-tuned on a combination of domains display improved performance on unseen domain tasks such as TruthfulQA and MetaMedQA, demonstrating transferable calibration gains.
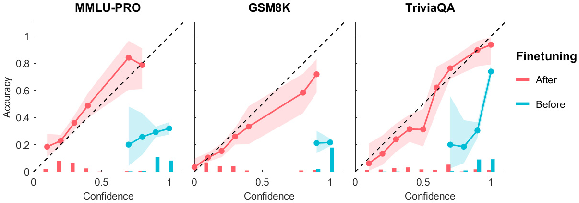
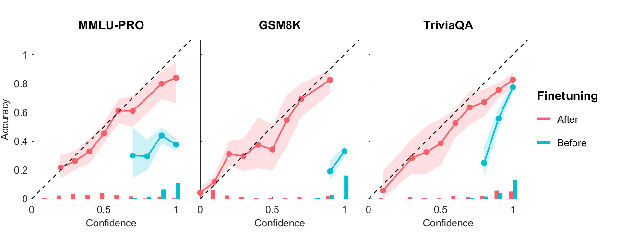
Figure 3: Calibration diagrams for fine-tuned and baseline models for the single-question confidence task using within-domain test questions.
Pairwise Confidence Comparison
Within-Domain Discrimination: Fine-tuning enhances the model's ability to discriminate confidence between pairs of questions, reflected by higher AUC metrics in evaluated domains.
Cross-Domain Transfer and Comparison Tasks: Similarly to single-question confidence, cross-task evaluations show that single-task improvements do not transfer. However, joint fine-tuning across both tasks yields comprehensive calibration and discrimination enhancements across out-of-domain datasets.
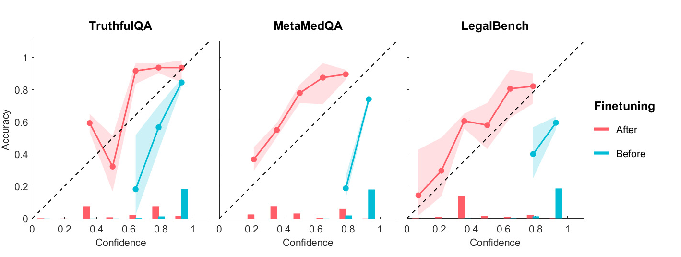
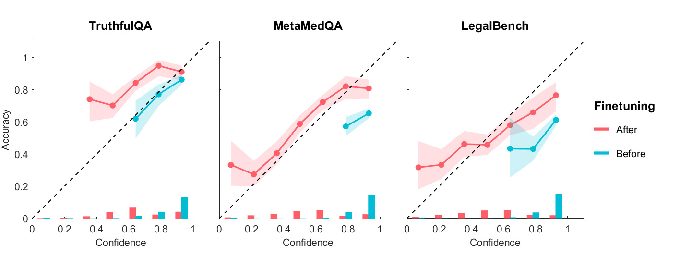
Figure 4: Calibration diagrams for fine-tuned and baseline models for the single-question confidence task using out-of-domain questions.
Discussion
The study confirms that LLMs can be trained to better express their uncertainty, although this often requires multitask and multidomain training approaches to achieve generalized improvements across various settings. The distinct metacognitive operations—absolute estimates and relative comparisons—are learned differently, suggesting the need for multitask learning to foster shared internal representations aiding both types. The approach aligns with human metacognitive frameworks, implying parallels between computational and cognitive processes in uncertainty communication.
Conclusion
This work demonstrates that systematic fine-tuning can effectively enhance the metacognitive capabilities of LLMs, facilitating more reliable communication of uncertainty across diverse domains. This improvement lays a foundation for safer and more trustworthy deployment in critical areas, with multitask and multidomain training touted as promising strategies for achieving comprehensive metacognitive competencies.

