- The paper presents a novel human-in-the-loop platform that enables real-time, parallel evaluation of text simplification models using asynchronous architecture and hierarchical semantic alignment.
- The methodology employs a tiered alignment engine combining transformer embeddings, TF-IDF, and positional bias to robustly map source and simplified sentences, enhancing evaluation precision.
- The system offers comprehensive educational diagnostics including readability metrics and customizable annotations, facilitating reproducible research through exportable session data.
MuTSE: A Human-in-the-Loop Multi-Use Evaluator for Systematic Text Simplification Assessment
Introduction and Motivation
Text simplification, as utilized in educational and language-learning platforms, demands robust, multi-faceted evaluation frameworks to ensure outputs generated by LLMs align with varying learner proficiencies and pedagogical needs. Despite the significant progress in LLM-based simplification, the comparative evaluation of multiple models and prompt strategies remains fragmented and operationally inefficient. Existing methodologies, such as EASSE and TS-ANNO, focus on static metric benchmarking or post-hoc manual annotation, lacking true real-time, visual, and human-in-the-loop functionality for concurrent multi-model, multi-prompt analysis.
MuTSE addresses these deficiencies through an interactive platform facilitating real-time, parallelized comparative evaluations of P×M prompt-model pairs, with dense integration of semantic alignment visualizations and educational diagnostics. This approach bridges the gap between purely computational benchmarking and nuanced human-centered qualitative evaluation frameworks.
System Architecture: Asynchronous Concurrency for Throughput
The MuTSE platform embodies a decoupled asynchronous architecture built atop FastAPI (backend) and Vue.js 3 (frontend), orchestrating parallel inferential tasks across locally and remotely hosted LLMs. Each text simplification request is split into independent, distributed processes for every prompt-model permutation, with stringent state isolation to prevent interference or race conditions during concurrent execution. Synchronization overhead is bounded by the slowest process in the batch, optimizing throughput for high-dimensional evaluation matrices. Upon task completion, outputs, alignments, and metrics are aggregated for downstream client visualization.
Tiered Semantic Alignment Engine
A central innovation is MuTSE's hierarchical semantic alignment engine for visually mapping source to simplified sentences. This engine employs a multi-tiered fallback mechanism:
- Semantic Tier: Utilizes paraphrase-multilingual-MiniLM-L12-v2 for dense sentence-embedding and cosine similarity matrices.
- Lexical Tier: Applies TF-IDF (including word and character n-grams) as a fallback when transformer embeddings are unreliable.
- Positional Tier: Falls back to purely positional correspondence when both previous tiers yield indeterminate results.
A key challenge in alignment arises from the high risk of false positives using embedding-based similarity, especially when simplifications are not strictly monotonic. MuTSE introduces a tunable linearity bias (λ), penalizing alignments that violate relative sentence ordering, and thus enforcing near-monotonic correspondences critical for high-precision educational evaluation.
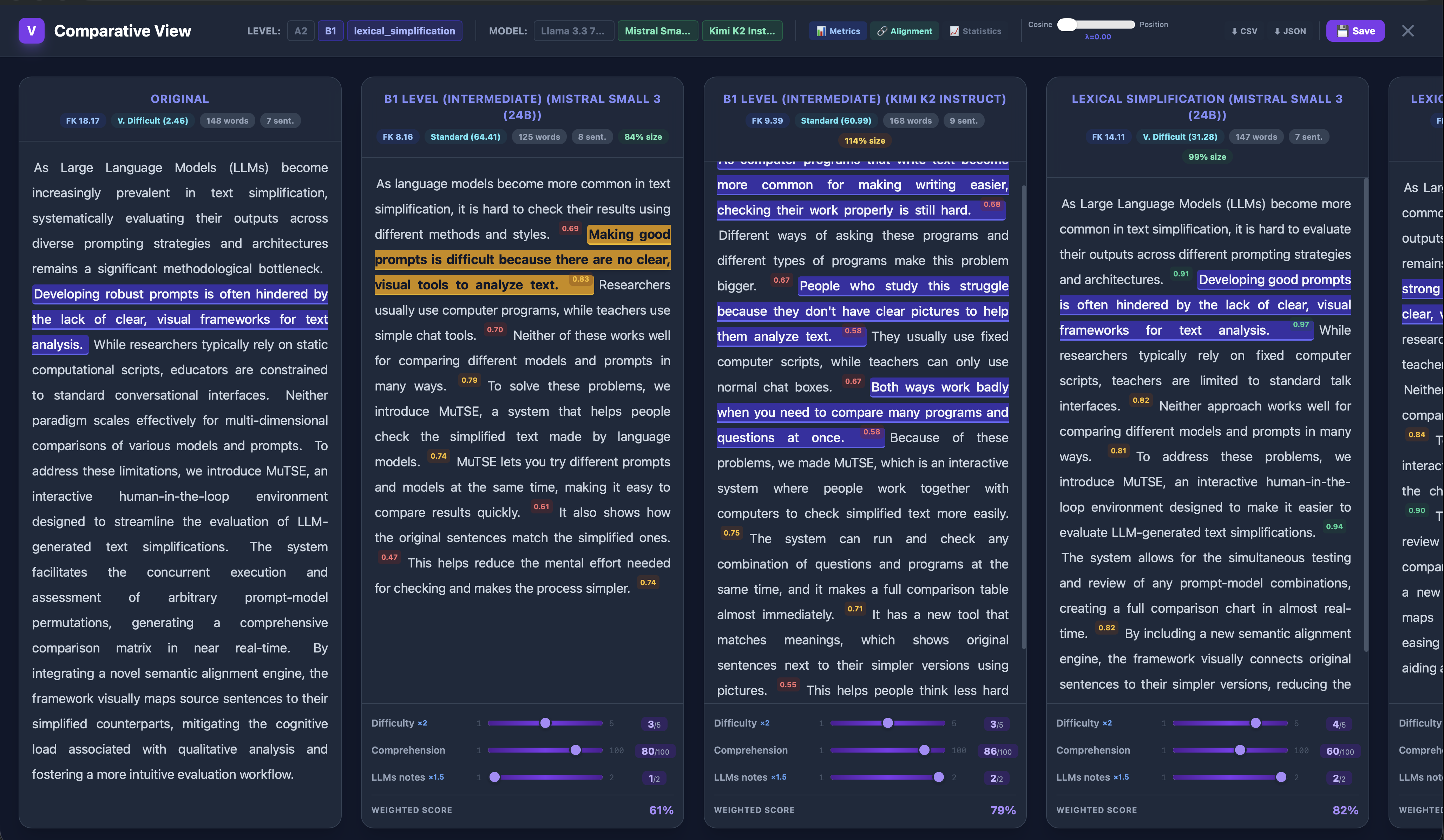
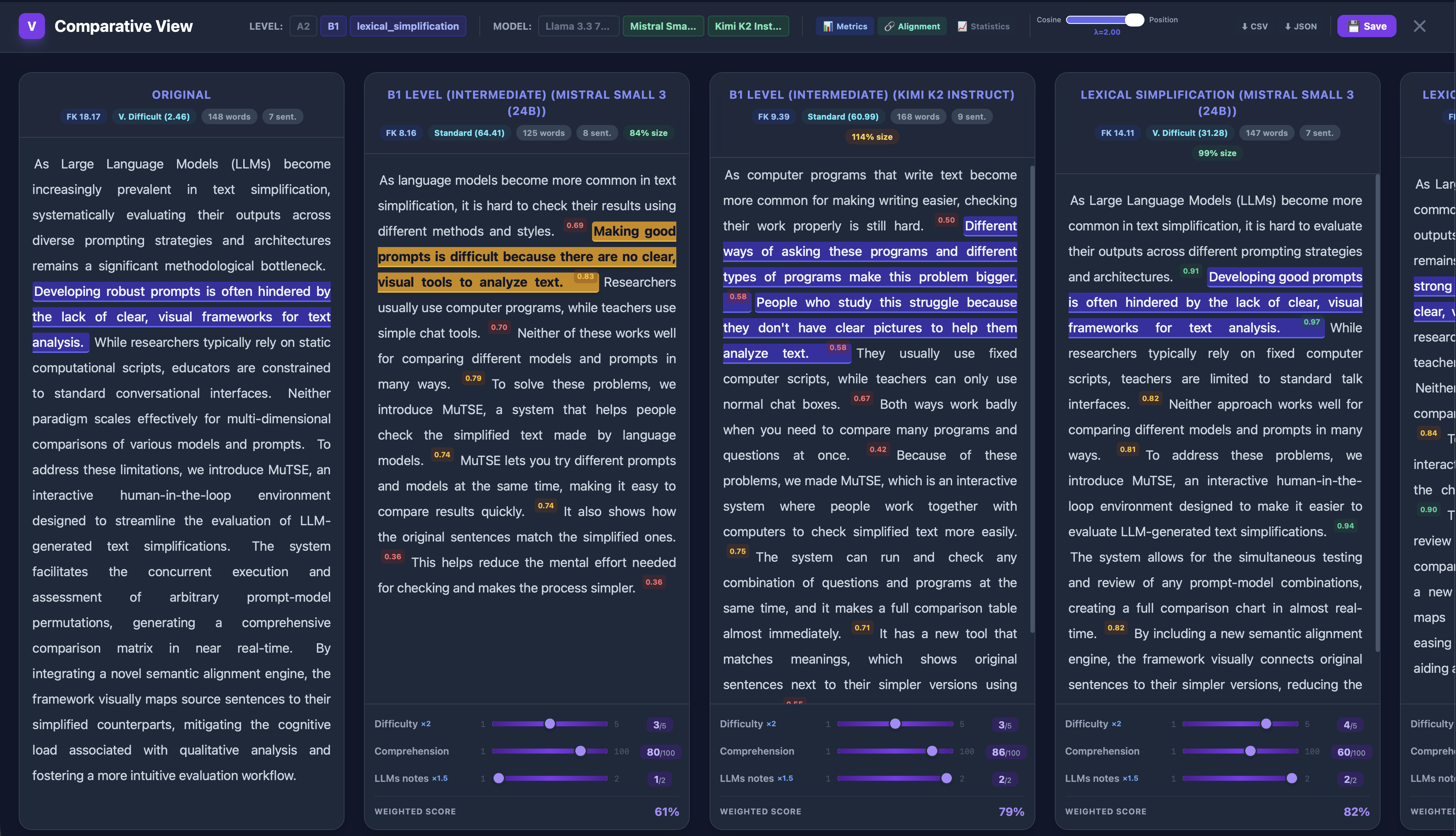
Figure 2: The effect of linearly increasing the positional penalty (λ), revealing how strict linearity resolves semantically spurious cross-alignments and enforces monotonic structure.
Integration of the linearity factor allows robust alignment even with low-dimensional embeddings, significantly reducing computational requirements and enabling efficient client-side recomputation. Alignment matrices with adjustable λ provide analysts immediate, visual control over the trade-off between semantic closeness and structural monotonicity.
Educational Diagnostics, Readability, and Annotation
Beyond alignment, MuTSE incorporates a comprehensive real-time statistics module for linguistic and educational diagnostics. Key features include:
A configurable annotation suite enables practitioners to define arbitrary scoring criteria and scales—ranging from binary, categorical, Likert, to continuous metrics—complete with individually weighted impact on alignment scoring and performance aggregation. This alleviates the lack of standardization in human evaluation protocols identified in recent NLG assessment literature, advancing both reproducibility and evaluator autonomy.
Interactive Visualization and Comparative Workflow
The MuTSE frontend operationalizes multidimensional comparative analysis with a side-by-side visualization interface. Key workflow features:
- Selective Column Filtering: Analysts dynamically toggle prompts and models, reducing cognitive overhead in high-dimensional comparisons.
- Alignment Highlighting: Interactive traversal, where selecting a sentence in any column instantaneously highlights aligned sentences across all active columns, leveraging precomputed semantic correspondence.
- Immediate Metric Feedback: Inline display of alignment scores, readability, and compression metrics per output column.
All evaluation sessions—encompassing the full P×M matrix, alignment graphs, and human annotations—are exportable in structured JSON and CSV formats, supporting downstream corpus building, EDA, and model fine-tuning. This export capability ensures that both qualitative and quantitative data generated during human-in-the-loop evaluations are readily accessible for reproducible NLP research.
Limitations and Perspectives
Key constraints of the current MuTSE deployment include the non-scalability of the local JSON persistence layer for multi-user or institutional environments and the reliance on Python/Node.js for end-user operation. Scaling to lab and classroom scenarios would require database-backed architecture and streamlined deployment pipelines.
The modularity of the MuTSE alignment engine positions it for extensions into cross-lingual and MT evaluation—already supported by multilingual embeddings and n-gram-based lexical fallback. Applying MuTSE’s methodology to machine translation and summarization, with appropriate recalibration of linearity constraints, would further generalize the platform for broader natural language generation assessment.
Conclusion
MuTSE represents a significant methodological advance in text simplification evaluation by uniting asynchronous multi-model inference, hierarchical semantic alignment, granular educational diagnostics, and customizable human annotation in a cohesive, accessible platform. This integration empowers both educators and NLP researchers to conduct reproducible, multidimensional comparative analyses at scale, while offering a foundation for systematic dataset expansion in natural language generation. Adaptability to emerging LLMs, model-agnostic metrics, and exportable session data position MuTSE as a cornerstone infrastructure for future educational and computational research in LLM-based text simplification and beyond.
